文章目录
- 一、为什么要求RNN?传统神经网络的痛点
- 二、RNN核心原理:带“记忆”的网络结构
- 1. RNN的根本结构与计算逻辑
- 关键计算步骤(以第1步和第2步为例):
- 重要特点:参数共享
- 2. RNN的输入与输出形式
- 三、RNN的致命局限:长期依赖障碍
- 四、突破局限:LSTM(长短时记忆网络)
- 1. LSTM的核心:3种门控结构
- (1)遗忘门(Forget Gate):决定“忘什么”
- (2)输入门(Input Gate):决定“记什么”
- (3)输出门(Output Gate):决定“输出什么”
- 2. LSTM的优势:解决长期依赖
- 五、RNN与LSTM的应用场景
- 六、总结
在自然语言处理(NLP)中,处理文本、语音等序列数据是核心需求。传统神经网络因无法捕捉数据的顺序关联,难以应对这类任务,而循环神经网络(RNN)凭借“记忆性”特性,成为解决序列问题的关键模型。本文将从RNN的核心原理出发,分析其局限,并详解LSTM如何突破这些局限,最后结合实例帮助理解。
一、为什么需要RNN?传统神经网络的痛点
在处理“我喜欢编程,我最擅长用Python写____”这类序列任务时,传统神经网络存在明显缺陷:
- 无法捕捉顺序依赖:传统模型将输入材料视为独立个体,忽略“编程”“Python”与空缺词之间的逻辑关联,无法根据前文预测后文。
- 输入输出长度固定:传统模型的输入层和输出层维度固定,无法处理文本长度不统一的场景(如短评、长文等)。
为解决这些问题,RNN引入“隐状态(Hidden State)”概念,能保留前文信息并传递到后续计算中,达成对序列数据的动态处理。
二、RNN核心原理:带“记忆”的网络结构
1. RNN的基本结构与计算逻辑
RNN的核心是“循环”——每一步计算都会利用上一步的隐状态,结构可简化为下图: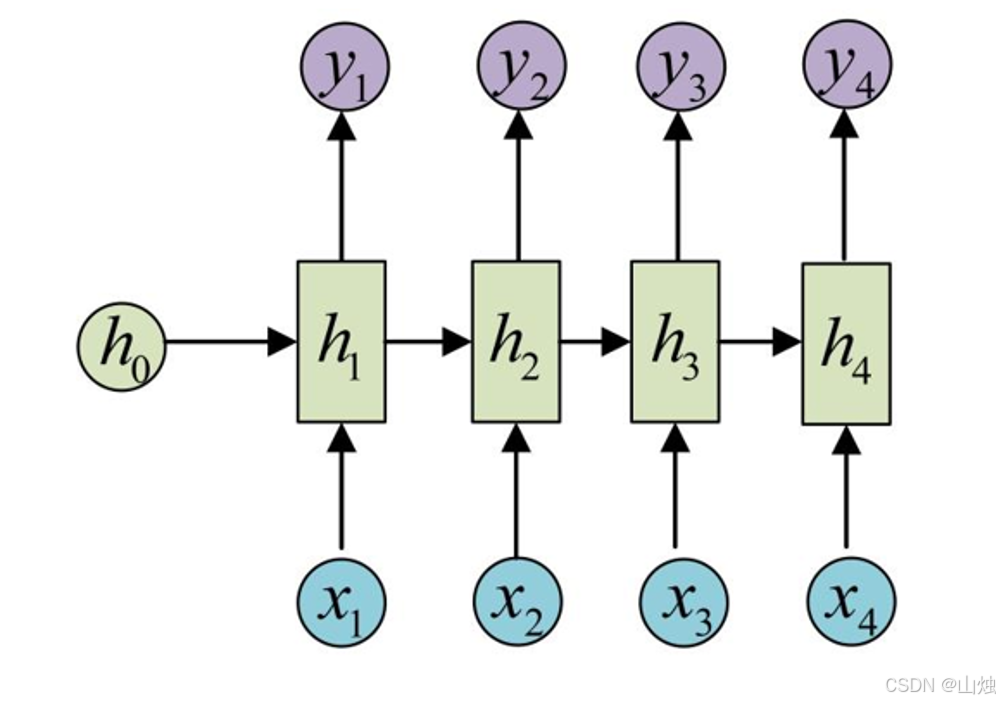
关键计算步骤(以第1步和第2步为例):
初始隐状态:通常设为全0向量
h₀。第1步计算:输入
x₁与上一步隐状态h₀结合,生成当前隐状态h₁,公式为:
h 1 = f ( U x 1 + W h 0 + b ) h_1 = f(Ux_1 + Wh_0 + b)h1=f(Ux1+Wh0+b)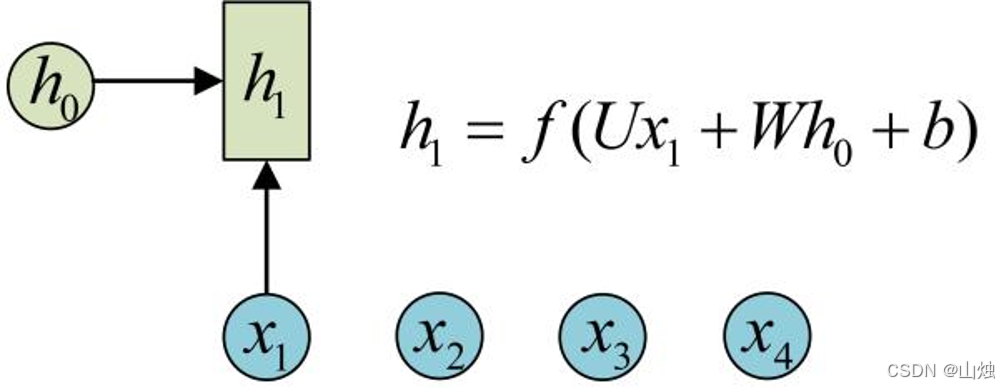
其中,
U(输入到隐层的权重)、W(隐层到隐层的权重)、b(偏置)是模型参数,f为激活函数(常用tanh,确保输出值在-1~1之间,避免梯度爆炸)。第2步计算:复用相同参数
U、W、b,输入x₂与上一步隐状态h₁结合,生成h₂:
h 2 = f ( U x 2 + W h 1 + b ) h_2 = f(Ux_2 + Wh_1 + b)h2=f(Ux2+Wh1+b)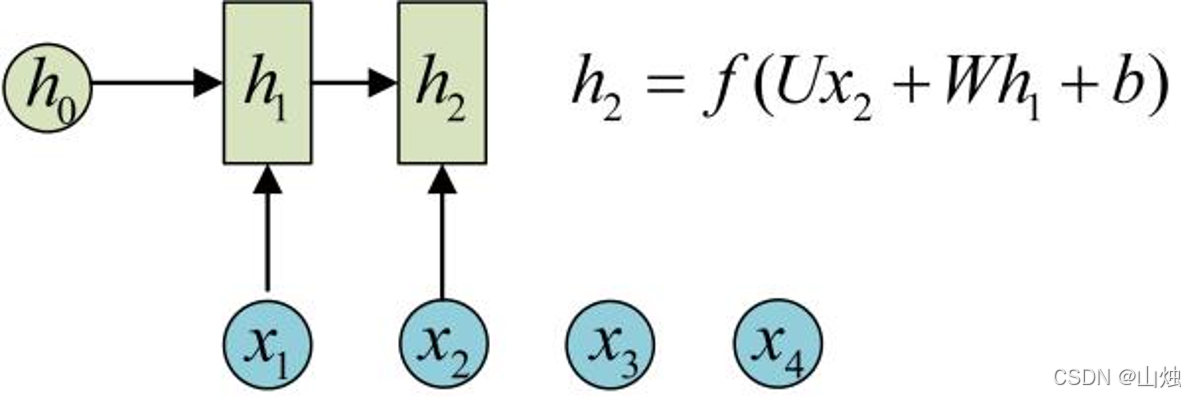
关键特点:参数共享
RNN在每一步使用相同的参数(U、W、b),而非为每个位置单独设置参数。这不仅减少了参数数量,还让模型能泛化到不同长度的序列(如3个词的短句、10个词的长句)。
2. RNN的输入与输出形式
RNN的输入是长度为n的序列[x₁, x₂, ..., xₙ],输出是对应的序列[y₁, y₂, ..., yₙ],即输入输出长度必须相等。输出层通过隐状态计算,公式为:
y 1 = S o f t m a x ( V h 1 + c ) y_1 = Softmax(Vh_1 + c)y1=Softmax(Vh1+c)
其中V(隐层到输出层的权重)、c(输出层偏置)是输出层参数,Softmax函数将输出转为概率分布,用于分类任务(如文本情感判断)。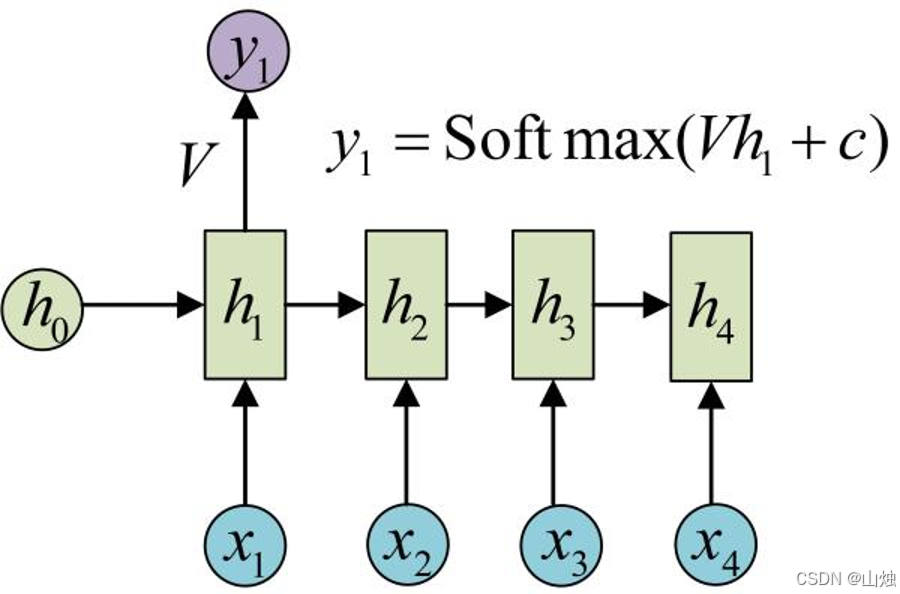
三、RNN的致命局限:长期依赖问题
理论上,RNN能利用远距离的前文信息(如“我的职业是程序员,……,我最擅长的是____”中,“程序员”应关联“编程”“代码”等词),但实际训练中会遇到梯度消失/爆炸问题:
- 梯度消失:当序列过长时,梯度会随着反向传播不断减小,最终趋近于0,导致模型无法更新早期参数,无法学习到远距离依赖。
- 梯度爆炸:少数情况下梯度会急剧增大,超出参数更新范围,导致模型训练崩溃。
简单来说,RNN的“记忆”是短期的,无法记住序列中早期的关键信息,这极大限制了其在长序列任务中的应用。
四、突破局限:LSTM(长短时记忆网络)
为消除RNN的长期依赖问题,研究者提出LSTM(Long Short-Term Memory)。它在RNN基础上增加了门控机制,能自主“记住”重要信息、“遗忘”无关信息,相当于给RNN的“记忆”加了“筛选器”。
1. LSTM的核心:3种门控结构
LSTM借助“遗忘门”“输入门”“输出门”控制信息的流动,结构如下: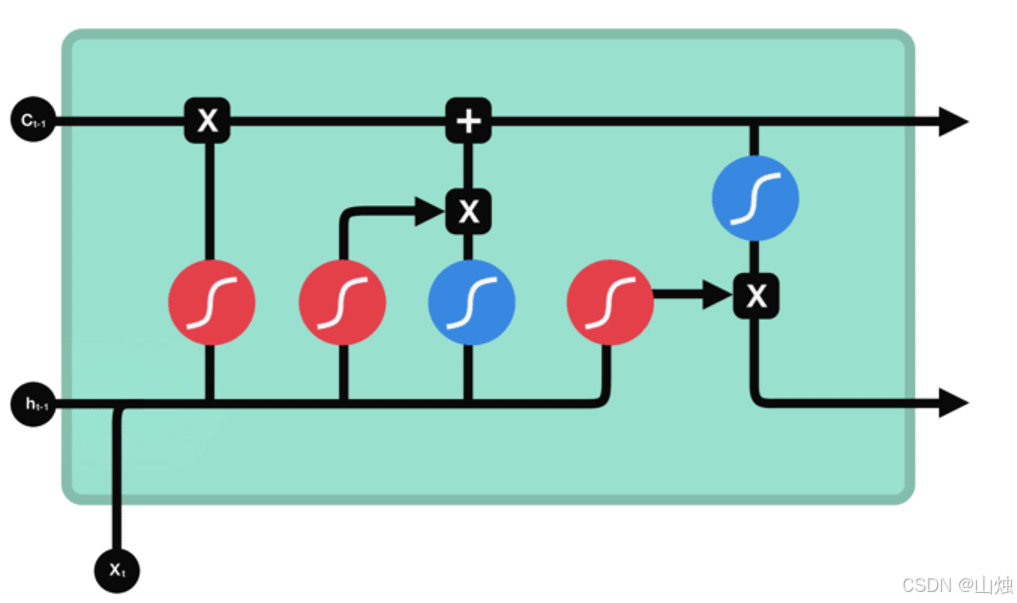
(1)遗忘门(Forget Gate):决定“忘什么”
- 功能:筛选上一步细胞状态(
Cₜ₋₁,LSTM的“长期记忆”载体)中需要保留或丢弃的信息。 - 计算逻辑:
- 输入
xₜ与上一步隐状态hₜ₋₁拼接,传入sigmoid函数; sigmoid输出值在0~1之间:0表示“完全丢弃”,1表示“完全保留”;- 输出值与上一步细胞状态
Cₜ₋₁相乘,完成信息筛选。
- 输入
(2)输入门(Input Gate):决定“记什么”
- 功能:更新细胞状态,将当前输入的重要信息存入“长期记忆”。
- 计算逻辑:
- 第一步:
xₜ与hₜ₋₁拼接后传入sigmoid,输出0~1的“更新权重”,决定哪些信息需要更新; - 第二步:
xₜ与hₜ₋₁拼接后传入tanh,生成-1~1的“候选信息向量”(包含当前输入的关键特征); - 两步结果相乘,得到“待更新信息”,与遗忘门处理后的
Cₜ₋₁相加,生成新的细胞状态Cₜ。
- 第一步:
(3)输出门(Output Gate):决定“输出什么”
- 功能:根据当前细胞状态和输入,生成当前隐状态
hₜ(LSTM的“短期记忆”),传递到下一步。 - 计算逻辑:
xₜ与hₜ₋₁拼接后传入sigmoid,输出“输出权重”;- 新细胞状态
Cₜ传入tanh,将值压缩到-1~1; - 两步结果相乘,得到当前隐状态
hₜ,同时Cₜ作为“长期记忆”传递到下一步。
2. LSTM的优势:解决长期依赖
通过门控机制,LSTM能:
- 长期保留关键信息(如“程序员”这类核心词):遗忘门会给这类信息分配接近1的权重,不轻易丢弃;
- 丢弃无关信息(如“的”“是”这类虚词):遗忘门分配接近0的权重,过滤冗余;
- 避免梯度消失:细胞状态
Cₜ通过“加法”更新(而非RNN的“乘法”),梯度能更稳定地反向传播,支持长序列训练。
五、RNN与LSTM的应用场景
在NLP任务中,RNN和LSTM的应用场景高度重合,但LSTM因性能更优,应用更广泛:
| 任务类型 | 具体场景 | 模型选择建议 |
|---|---|---|
| 文本分类 | 情感分析、垃圾邮件识别 | 短序列用RNN,长序列用LSTM |
| 序列生成 | 机器翻译、文本摘要 | 优先用LSTM(需捕捉长依赖) |
| 时序预测 | 语音识别、股价预测 | 必用LSTM(长序列依赖强) |
六、总结
- RNN通过“隐状态”实现对序列数据的处理,但受限于梯度消失,无法学习长期依赖;
- LSTM利用“遗忘门”“输入门”“输出门”的门控机制,解决了RNN的痛点,能有效捕捉长序列中的关键信息;
- 在实际NLP项目(如本文后续会讲的微博情感分析)中,LSTM是处理长文本的首选模型,而RNN可用于短序列任务以降低计算成本。