引言
在当今数据爆炸的时代,企业面临着前所未有的数据处理挑战——如何同时满足海量历史数据的批处理分析需求和实时数据的低延迟查询需求?2014年,Storm的作者Nathan Marz提出了一种革命性的架构模式——Lambda架构,为解决这一矛盾提供了优雅的解决方案。
Lambda架构通过巧妙地将数据处理分解为批处理层(Batch Layer)、加速层(Speed Layer)和服务层(Serving Layer),实现了兼具高容错性、低延迟和可扩展性的大数据处理系统。本文将深入剖析Lambda架构的设计理念、核心组件、实现方式及应用场景,为大数据架构师提供一份全面的技术指南。
Lambda架构核心思想
Lambda架构的设计目标是提供一个能满足大数据系统关键特性的通用架构,包括高容错、低延迟、可扩展等核心要素。其核心创新在于整合离线计算与实时计算,融合不变性、读写分离和复杂性隔离等设计原则,可无缝集成Hadoop、Kafka、Spark、Storm等各类大数据组件。
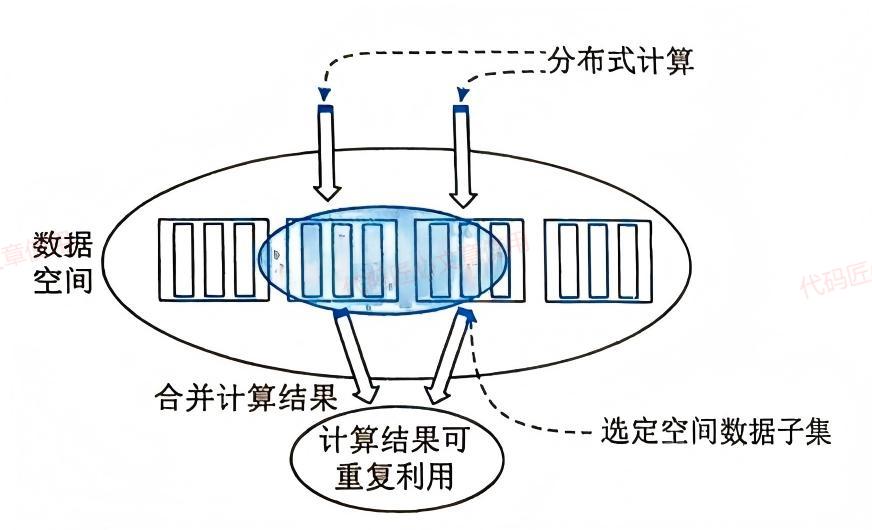
Lambda架构对大数据处理系统有以下独到理解:
- 数据不变性: 所有原始数据都被永久保存,任何数据处理都不会修改原始数据,而是生成新的衍生数据
- 读写分离: 数据写入和查询采用不同的优化策略
- 复杂性隔离: 将复杂的实时处理逻辑与批处理逻辑分离
- 最终一致性: 通过批处理校正实时处理结果,实现系统的最终一致性
Lambda架构三层详解
批处理层(Batch Layer)
批处理层是Lambda架构的基础,负责存储完整的数据集并预先计算查询函数,构建对应的视图(View)。
批处理层核心功能
- 存储主数据集: 负责管理全量原始数据,这些数据具有三个关键属性:原始性、不变性和真实性
- 生成批处理视图: 在完整数据集上预先计算查询函数,生成Batch View
批处理层最适合处理离线数据,但对于不断实时生成且需要实时查询处理的数据,单独依赖批处理层则无法满足低延迟需求。
Monoid特性在批处理中的应用
批处理层的高效运作依赖于一类称为Monoid特性的函数。Monoid特性源于范畴论,指满足结合律的函数,如整数加法就是典型的Monoid特性函数。
Monoid特性在分布式计算中非常重要:
- 满足Monoid特性意味着可以将计算分解到多台机器并行运算
- 然后合并各自的部分运算结果得到最终结果
- 部分运算结果可以被保存并共享利用,减少重复计算
这一特性使得批处理层能够高效处理海量数据,通过预计算查询结果,显著提升查询性能。
典型技术实现
Hadoop生态系统是批处理层的理想选择:
- HDFS: 提供高容错性的分布式存储
- MapReduce/Spark: 负责在数据集上构建查询视图
- Hive: 创建可查询的视图
加速层(Speed Layer)
加速层(又称流处理层)专门处理增量实时数据流,弥补批处理层在实时性方面的不足。
加速层与批处理层的对比
| 特性 | 批处理层 | 加速层 |
|---|---|---|
| 处理数据范围 | 全体数据集 | 最近的增量数据流 |
| 处理方式 | 全量计算生成Batch View | 增量计算不断更新Real-time View |
| 设计目标 | 准确性 | 低延迟 |
| 复杂度 | 相对简单可控 | 较高 |
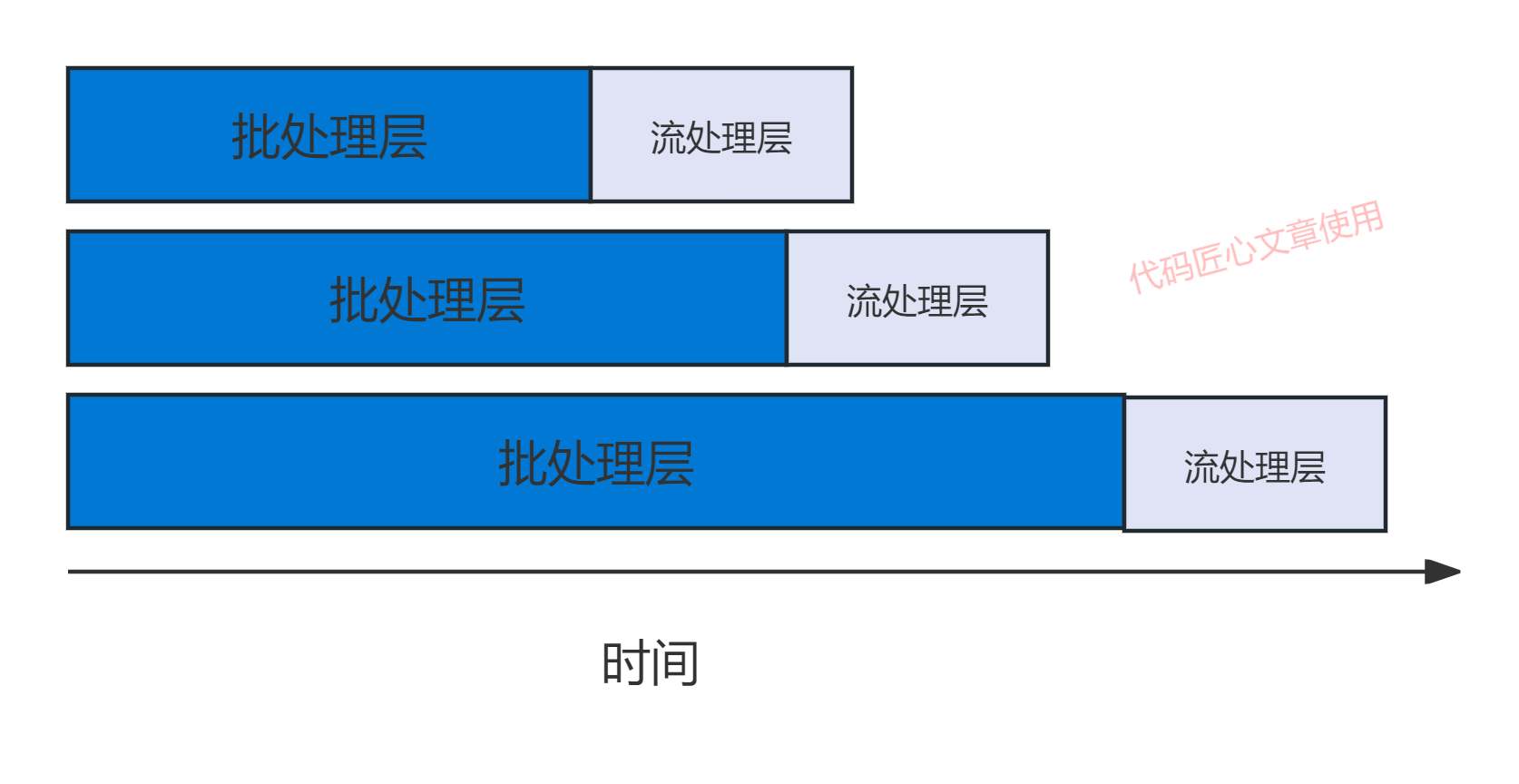
加速层核心优势
- 容错性: Speed Layer中引入的错误,在Batch Layer重新计算时可以得到修正,体现了CAP理论中的最终一致性
- 复杂性隔离: 将复杂的实时处理逻辑隔离在Speed Layer,提高整个系统的鲁棒性
- 可扩展性: 支持横向扩展,通过增加机器资源维持性能。。
典型技术实现
- Spark Streaming: 微批处理实时数据
- Storm/Flink: 流处理框架
- Kafka: 高吞吐量的消息系统,用于数据接入
服务层(Serving Layer)
服务层是Lambda架构的统一查询入口,负责合并Batch View和Real-time View中的结果数据集,提供低延迟的查询服务。
数据合并策略
服务层如何合并批处理视图和实时视图取决于查询函数的特性:
- 满足Monoid特性: 直接合并两个视图的结果
- 不满足Monoid特性: 需要将查询函数转换为多个满足Monoid特性的函数运算,或根据业务规则合并
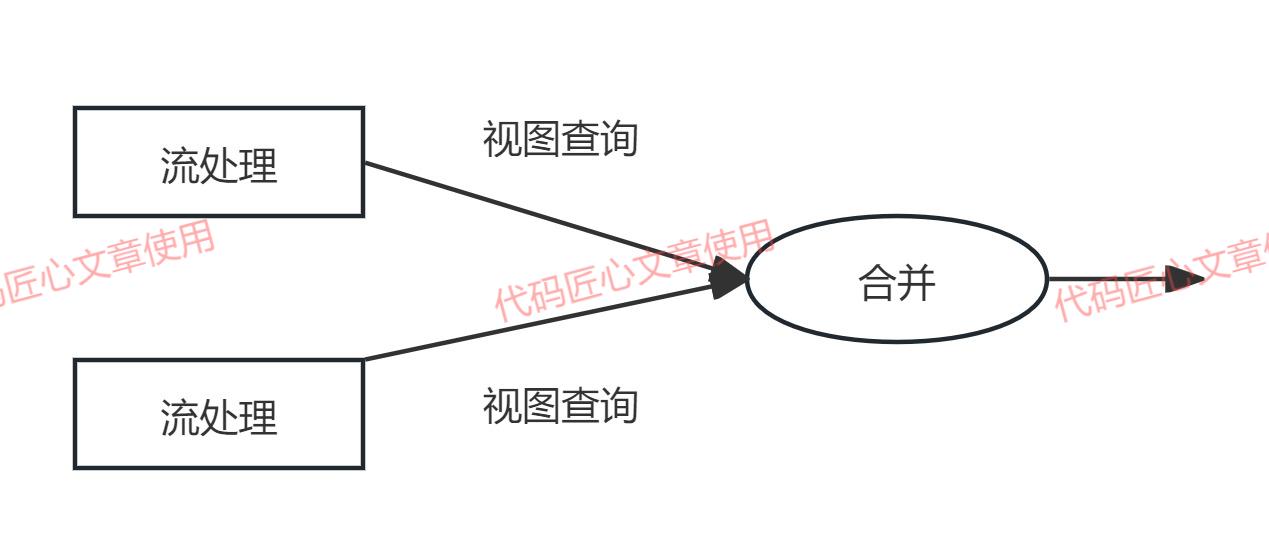
服务层典型技术实现
- HBase/Cassandra: 提供随机读写能力和批处理写入能力
- Redis: 作为缓存层提升查询性能
- Elasticsearch: 提供全文检索能力
Lambda架构完整实现
一个完整的Lambda架构实现通常整合以下技术组件:
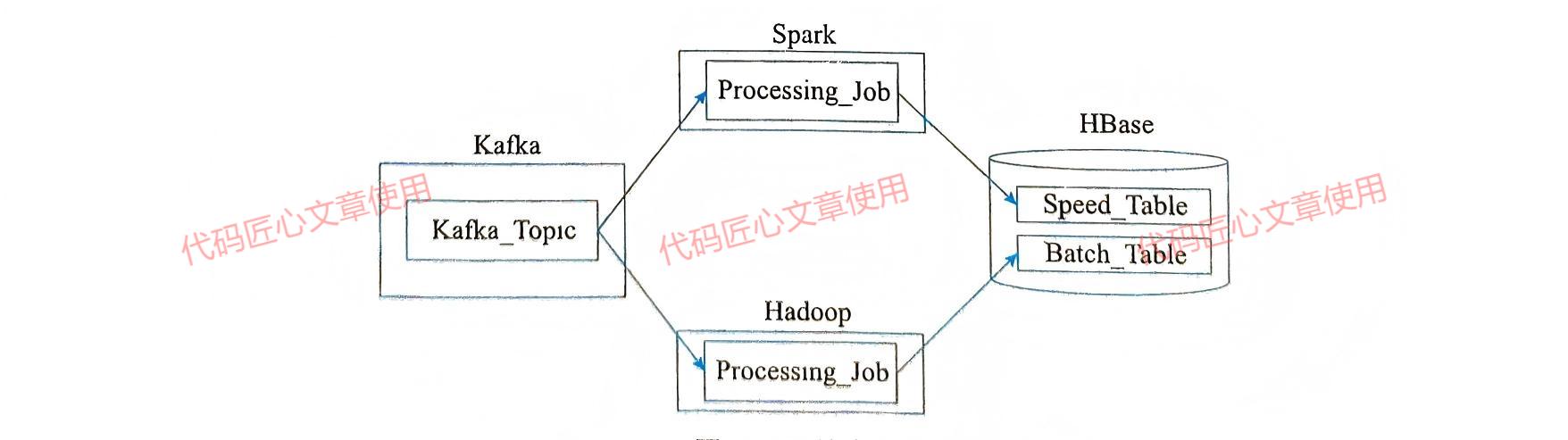
- 数据存储: Hadoop HDFS存储主数据集
- 批处理计算: MapReduce负责批处理层
- 流处理计算: Spark(或Storm)构成速度层(Speed Layer)
- 查询服务: HBase(或Cassandra)作为服务层
- 查询视图: 由Hive创建可查询的视图
关键技术组件解析
Hadoop生态系统
Hadoop是被设计成适合运行在通用硬件上的分布式文件系统(DistributedFileSystem)。它和现有的分布式文件系统有很大的共同点,但同时,它和其他分布式文件系统的区别也很明显:
- HDFS: HDFS是一个具有高度容错性的系统,能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一些约束,以达到流式读取文件系统数据的目的。
- MapReduce: 分布式计算框架,擅长批处理任务
Spark
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMPLab所开源的类Hadoop MapReduce的通用并行处理框架,具有以下特点:
- Spark拥有Hadoop MapReduce所具有的优点
- 不同于Map Reduce的是,Job中间输出结果可以保存在内存中,从而不再需要读写HDFS
- 因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce算法
HBase
HBase-Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统:
- 利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
- 支持随机读写、批量写入
- 具备良好的伸缩性和容错能力
- 作为服务层提供高效查询能力
Lambda架构应用场景
Lambda架构适用于需要同时处理历史数据和实时数据的场景:
机器学习平台
在机器学习领域,数据量越多通常意味着模型效果越好。Lambda架构构建的数据系统可以为机器学习算法提供全面的数据支持,帮助算法通过历史数据构建模型,并通过实时数据不断优化模型。
物联网数据处理
物联网设备(如智能汽车、工业传感器)会产生海量实时数据流:
- 位置信息
- 传感器数据
- 运行状态
Lambda架构可以同时处理历史数据(用于趋势分析)和实时数据(用于即时响应)。
用户行为分析
互联网平台需要分析用户行为以提供个性化服务:
- 批处理层分析历史行为数据,构建用户画像
- 加速层处理实时行为数据,实现实时推荐
金融风控系统
金融领域需要实时监控交易风险:
- 批处理层分析历史交易数据,识别长期风险模式
- 加速层实时监控交易行为,检测异常交易
Lambda架构的挑战与解决方案
尽管Lambda架构优势显著,但在实际应用中仍面临一些挑战:
数据一致性挑战
问题: 批处理视图和实时视图可能存在不一致。
解决方案:
- 接受最终一致性模型
- 设计合理的批处理更新周期
- 使用版本控制明确标记不同时期的视图
系统复杂性挑战
问题: 维护两套处理系统(Batch+Speed)增加了开发和运维复杂度。
解决方案:
- 引入统一编程模型
- 构建抽象层封装底层复杂性
- 自动化部署和监控
资源消耗挑战
问题: 两套计算系统导致资源消耗增加。
解决方案:
- 合理规划计算资源
- 非高峰时段运行批处理任务
- 动态调整资源分配
Lambda架构的演进与替代方案
随着大数据技术的发展,Lambda架构也在不断演进,出现了一些替代方案:
Kappa架构
Kappa架构由LinkedIn工程师Jay Kreps提出,它简化了Lambda架构,仅保留流处理层:
- 通过重新处理流数据来生成批处理结果
- 适合可以接受重新处理历史数据的场景
- 显著降低了系统复杂性
混合架构
许多企业采用混合架构,结合Lambda和Kappa的优点:
- 核心场景保留Lambda架构的稳定性
- 非核心场景采用Kappa架构简化实现
总结
Lambda架构通过巧妙的分层设计,完美融合了批处理和流处理的优势,提供了一个兼顾高容错性、低延迟和可扩展性的大数据处理框架。
Lambda架构核心价值
- 数据完整性: 通过批处理层保证全量数据的准确处理
- 实时响应能力: 通过加速层满足实时数据处理需求
- 系统鲁棒性: 通过分层设计隔离复杂性
- 查询灵活性: 服务层提供统一高效的查询接口
实践建议
- 不是所有场景都需要完整的Lambda架构,评估业务需求后再决定
- 优先解决核心问题,再考虑架构完善
- 关注新兴技术发展,适时引入更优解决方案
- 重视监控和运维,确保各层协同工作
Lambda架构虽然增加了一定的系统复杂性,但其带来的数据处理能力和灵活性使其成为处理复杂大数据场景的理想选择。随着技术的不断进步,我们有理由相信Lambda架构及其演进形式将在大数据领域继续发挥重要作用。
原文来自:http://blog.daimajiangxin.com.cn
