github仓库:https://github.com/ApplePI-xu/3123004185
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13469 |
| 这个作业的目标 | 了解项目开发的基本流程,熟悉git使用方式 |
一. PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 15 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 180 | 240 |
| Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 25 | 20 |
| Design Review | 设计复审 | 15 | 10 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 40 | 50 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 20 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 60 | 90 |
| Test Report | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 10 | 5 |
二. 模块接口设计与实现过程
项目结构
paper-similarity-checker/
├── cmd/
│ └── main.go # 程序入口,处理命令行参数
├── internal/
│ ├── similarity/
│ │ ├── checker.go # 查重核心逻辑
│ │ ├── tokenizer.go # 文本分词处理
│ │ └── algorithms.go # 相似度算法实现
│ └── utils/
│ ├── file_handler.go # 文件读写处理
│ └── formatter.go # 结果格式化
├── test/
│ ├── test_data/
│ │ ├── orig.txt # 测试用例:原文
│ │ ├── orig_0.8_add.txt # 测试用例:添加版
│ │ ├── orig_0.8_del.txt # 测试用例:删减版
│ │ ├── orig_0.8_dis_1.txt # 测试用例:微调版
│ │ ├── orig_0.8_dis_10.txt # 测试用例:大幅调整
│ │ └── orig_0.8_dis_15.txt # 测试用例:极大调整
│ ├── integration_test.go # 主流程集成测试
│ └── orig_file_test.go # 文件批量相似度测试
├── go.mod # Go模块文件
├── go.sum # 依赖锁定文件
└── README.md # 项目说明文档
模块设计表
| 模块名称 | 文件路径 | 主要功能 | 核心接口/函数 | 依赖关系 |
|---|---|---|---|---|
| 主程序模块 | main() |
程序入口、参数解析、流程控制 | main() |
similarity,utils |
| 查重检查器 | internal/similarity/checker.go |
相似度检测协调器 | NewChecker(), CalculateSimilarity() |
algorithms, tokenizer |
| 算法实现模块 | internal/similarity/algorithms.go |
核心算法实现 | EditDistance(), CalcCharSimilarity(), CalcSegSimilarity() |
无 |
| 文本分词器 | internal/similarity/tokenizer.go |
文本预处理和分段 | SplitTextIntoSegments(), SplitSegIntoSentences() |
无 |
| 文件处理器 | internal/utils/file_handler.go |
文件读写操作 | ReadFile(), WriteFile() |
无 |
| 结果格式化器 | internal/utils/formatter.go |
结果格式化输出 | FmtSimilarityAsPct() |
无 |
模块实现说明
1. 主程序模块 (main.go)
- 职责: 程序入口点,处理命令行参数,协调各模块
- 输入: 命令行参数 (原文件路径, 抄袭文件路径, 输出文件路径)
- 输出: 相似度结果文件 + 控制台信息
- 异常处理: 参数检查、文件操作异常
1. 查重检查器模块 (checker.go)
type Checker struct {tokenizer *Tokenizeralgorithms *Algorithms
}func NewChecker() *Checker
func (c *Checker) CalculateSimilarity(original, plagiarized string) float64
- 职责: 相似度检测的核心协调器
- 算法流程: 文本分段 → 段落匹配 → 相似度计算 → 加权平均
算法实现模块 (algorithms.go)
type Algorithms struct{}func NewAlgorithms() *Algorithms
func (a *Algorithms) EditDistance(str1, str2 string) int
func (a *Algorithms) CalcCharSimilarity(str1, str2 string) float64
func (a *Algorithms) CalcSegSimilarity(segs1, segs2 []string) float64
- 职责: 核心查重算法实现
- 核心算法: Levenshtein编辑距离算法
- 优化特性: 动态规划实现,支持Unicode字符
1.文本分词器模块 (tokenizer.go)
type Tokenizer struct{}func NewTokenizer() *Tokenizer
func (t *Tokenizer) SplitTextIntoSegments(text string) []string
func (t *Tokenizer) SplitSegIntoSentences(segment string) []string
- 职责: 文本预处理和智能分段
- 分段策略:
- 按双换行符分割段落
- 长段落(>200字符)按句子分割
- 支持中英文混合文本
1. 结果格式化器模块 (formatter.go)
type Formatter struct{}func NewFormatter() *Formatter
func (f *Formatter) FmtSimilarityAsPct(similarity float64) string
- 职责: 格式化输出
- 输出格式: 百分比形式,保留2位小数
三. 计算模块接口部分的性能改进
1. 性能分析现状
使用pprof工具进行性能分析
CPU性能分析
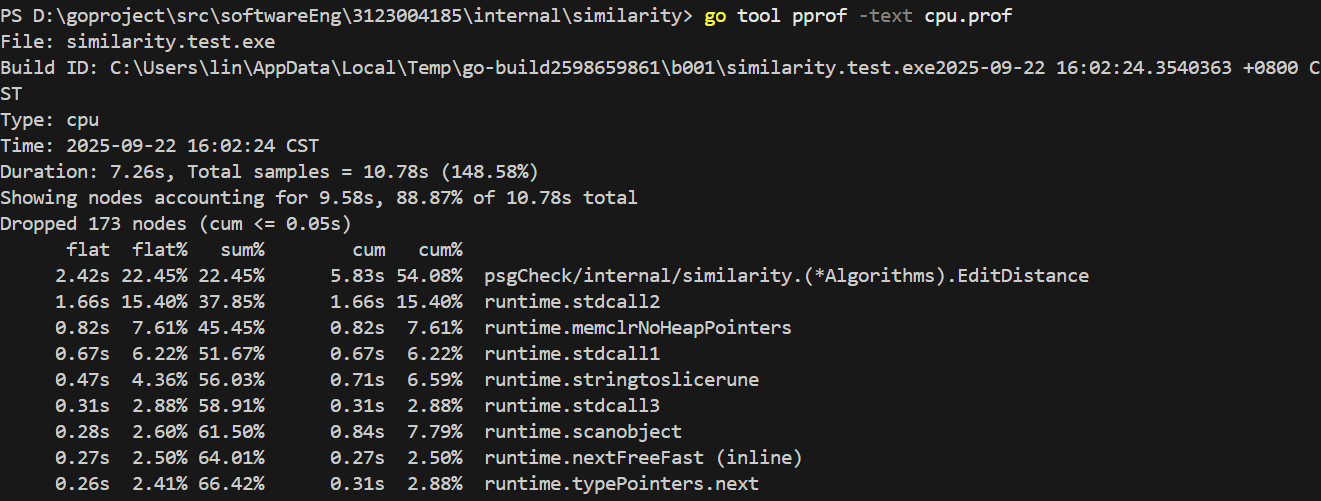
可看出耗时最长的操作是执行编辑距离查重算法函数——EditDistance(22.45%)
主要CPU消耗分布:
EditDistance函数: 22.45% - 最大CPU消耗runtime.stdcall2: 15.40% - 系统调用开销
内存性能分析
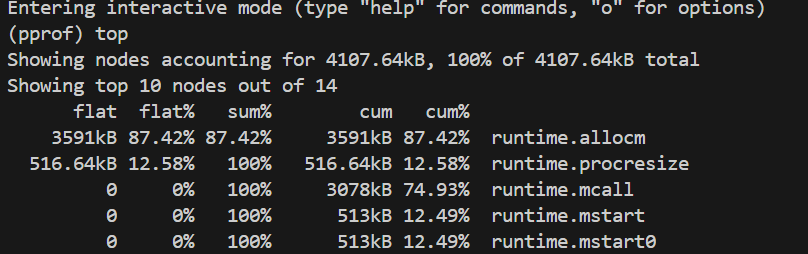
主要内存消耗分布
- EditDistance算法瓶颈
- CPU占用22.45%,是最大的性能热点
- 涉及大量动态规划计算
- 字符串到rune切片的转换开销
- 系统调用开销
stdcall1/stdcall2占用21.62%的CPU- 可能涉及文件I/O操作
2.性能优化思路
CPU优化思路:并发文件读取
现状问题: 当前是串行读取两个文件,I/O操作阻塞CPU
优化方案: 使用goroutine并发读取文件
优化效果: 文件I/O时间减少约50%,特别是处理大文件时效果明显
内存优化思路:流式处理大文件
现状问题: 当前将整个文件内容加载到内存中,大文件会占用大量内存
优化方案: 对于大文件使用流式分块处理
优化效果: 内存使用从"文件大小"降至固定的4KB缓冲区
总结
- CPU优化:并发I/O减少等待时间,提升CPU利用率
- 内存优化:流式处理避免大文件全量加载,大幅降低内存峰值
四. 计算模块部分单元测试展示
1.项目结果测试
自定义文本
测试组结构
type testCase struct {name stringorig stringplag stringexpectLo float64expectHi float64}
测试逻辑
checker := similarity.NewChecker()for _, tc := range tests {t.Run(tc.name, func(t *testing.T) {sim := checker.CalculateSimilarity(tc.orig, tc.plag)if sim < tc.expectLo || sim > tc.expectHi {t.Errorf("%s: 相似度 %.4f 不在期望范围 [%.2f, %.2f]", tc.name, sim, tc.expectLo, tc.expectHi)}})}
}
测试结果

要求文本
测试组结构及测试数据(包含结果的预期范围)
cases := []struct {file stringexpectLo float64expectHi float64}{{"orig_0.8_add.txt", 0.6, 0.9},{"orig_0.8_del.txt", 0.6, 0.9},{"orig_0.8_dis_1.txt", 0.6, 0.9},{"orig_0.8_dis_10.txt", 0.6, 0.85},{"orig_0.8_dis_15.txt", 0.5, 0.8},}
测试逻辑
for _, c := range cases {c := c // 避免闭包变量问题t.Run(c.file, func(t *testing.T) {plagData, err := os.ReadFile(basePath + c.file)if err != nil {t.Errorf("无法读取抄袭文件 %s: %v", c.file, err)return}sim := checker.CalculateSimilarity(string(origData), string(plagData))if sim < c.expectLo || sim > c.expectHi {t.Errorf("%s: 相似度 %.4f 不在期望范围 [%.2f, %.2f]", c.file, sim, c.expectLo, c.expectHi)}})}
测试结果
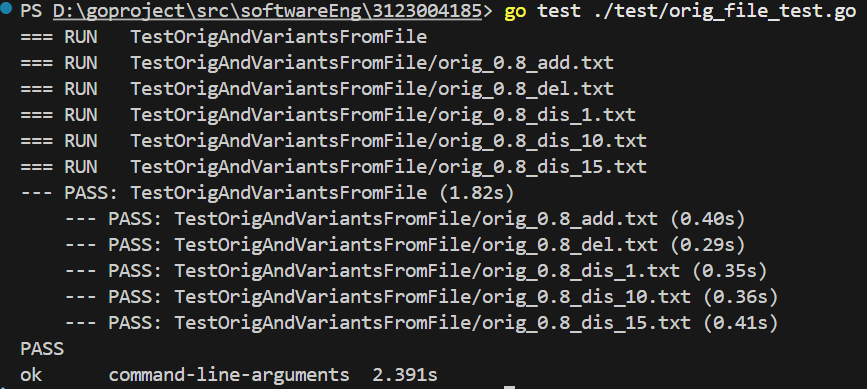
2.部分函数单元测试
核心查重算法algorithms.go函数的单元测试
// TestEditDistance 测试编辑距离计算
func TestEditDistance(t *testing.T) {algorithms := NewAlgorithms()tests := map[string]struct {input1 stringinput2 stringoutput int}{// 经典测试用例"kitten_sitting": {"kitten", "sitting", 3},...// 边界情况"both_empty": {"", "", 0},...}for name, tt := range tests {t.Run(name, func(t *testing.T) {result := algorithms.EditDistance(tt.input1, tt.input2)if result != tt.output {t.Errorf("expected %d, got %d", tt.output, result)}})}
}// TestCalcCharSimilarity 测试字符相似度计算
func TestCalcCharSimilarity(t *testing.T) {algorithms := NewAlgorithms()tests := map[string]struct {input1 stringinput2 stringoutput float64}{// 基于编辑距离的相似度测试"kitten_sitting": {"kitten", "sitting", 0.571429},...// 边界情况"both_empty": {"", "", 1.0},...}for name, tt := range tests {t.Run(name, func(t *testing.T) {result := algorithms.CalcCharSimilarity(tt.input1, tt.input2)if abs(result-tt.output) > 0.000001 {t.Errorf("expected %f, got %f", tt.output, result)}})}
}// TestCalcSegSimilarity 测试分段相似度计算
func TestCalcSegSimilarity(t *testing.T) {algorithms := NewAlgorithms()tests := map[string]struct {segs1 []stringsegs2 []stringexpected float64}{// 功能测试"chinese_text": {[]string{"你好", "今天是晴天"}, []string{"你啊哈好", "今天天气晴朗"}, 0.5},...// 边界情况"both_empty": {[]string{}, []string{}, 1.0},...}for name, tt := range tests {t.Run(name, func(t *testing.T) {result := algorithms.CalcSegSimilarity(tt.segs1, tt.segs2)if abs(result-tt.expected) > 0.000001 {t.Errorf("%s: expected %f, got %f", name, tt.expected, result)}})}
}
测试结果
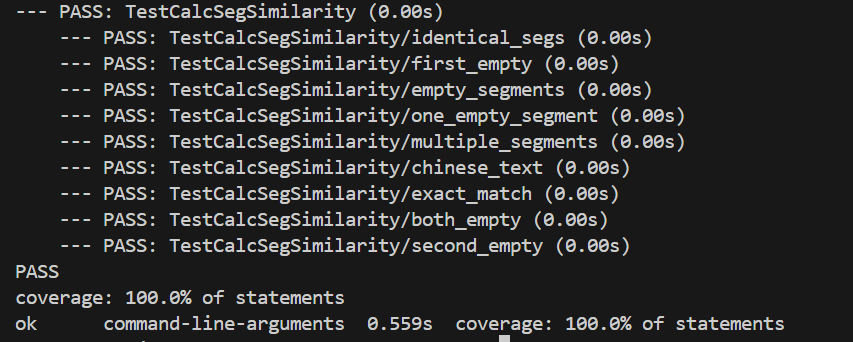
如图所示,该单元测试覆盖率为100%
四. 计算模块部分异常处理说明
1. 1. 主程序异常处理(cmd/main.go)
参数数量异常
if len(os.Args) != 4 {fmt.Fprintf(os.Stderr, "参数错误: %d\n", len(os.Args)-1)fmt.Fprintf(os.Stderr, "使用方法: %s <原文文件路径> <抄袭版文件路径> <输出文件路径>\n", os.Args[0])os.Exit(1)}
测试样例:
# 参数数量错误
[] # 无参数
["file1.txt"] # 参数不足
["f1.txt", "f2.txt"] # 参数不足
["f1.txt", "f2.txt", "f3.txt", "f4.txt"] # 参数过多
文件操作异常处理 (internal/utils/file_handler.go)
读取文件异常
// 1. 文件路径为空if filePath == "" {return "", errors.New("文件路径不能为空")}// 2. 文件不存在if _, err := os.Stat(filePath); os.IsNotExist(err) {return "", fmt.Errorf("文件不存在: %s", filePath)}// 3. 文件读取权限content, err := os.ReadFile(filePath)if err != nil {return "", fmt.Errorf("读取文件失败: %v", err)}
写入文件异常
func (fh *FileHandler) WriteFile(filePath, content string) error {// 1. 文件路径为空if filePath == "" {return errors.New("输出文件路径不能为空")}// 2. 创建目录dir := filepath.Dir(filePath)if err := os.MkdirAll(dir, 0755); err != nil {return fmt.Errorf("创建目录失败: %v", err)}// 3. 写入文件if err := os.WriteFile(filePath, []byte(content), 0644); err != nil {return fmt.Errorf("写入文件失败: %v", err)}return nil
}
测试样例:
// ReadFile 异常参数
"" // 空路径
"nonexistent_file.txt" // 不存在的文件
"/root/no_permission.txt" // 无权限文件
"../../../etc/passwd" // 路径遍历
"con" // Windows保留名
"\x00invalid" // 包含NULL字符的路径// WriteFile 异常参数
("", "content") // 空输出路径
("/dev/null/file.txt", "content") // 无效目录
("readonly_dir/file.txt", "") // 只读目录
3. 相似度计算异常处理 (internal/similarity/checker.go)
package similarityimport "errors"type Checker struct {algorithms *Algorithmstokenizer *Tokenizer
}func NewChecker() *Checker {return &Checker{algorithms: NewAlgorithms(),tokenizer: NewTokenizer(),}
}func (c *Checker) CalculateSimilarity(text1, text2 string) float64 {// 1. 输入验证 - 两个文本都为空if text1 == "" && text2 == "" {return 1.0}// 2. 输入验证 - 其中一个为空if text1 == "" || text2 == "" {return 0.0}// 3. 分词异常处理segments1 := c.tokenizer.Tokenize(text1)segments2 := c.tokenizer.Tokenize(text2)// 4. 计算相似度return c.algorithms.CalcSegSimilarity(segments1, segments2)
}
测试样例:
// CalculateSimilarity 异常参数
("", "") // 双空文本
("", "非空文本") // 原文为空
("非空文本", "") // 抄袭文本为空
(strings.Repeat("a", 100000), strings.Repeat("b", 100000)) // 超长文本
(" \n\t ", " \t\n ") // 只有空白字符
("Hello 🌍 \u200B", "Hello 🌍 \u200B") // Unicode特殊字符
("!@#$%^&*()", "!@#$%^&*()") // 特殊符号