作业一
1.用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
为了完成这个作业,我们要先明白各个库的作用是什么
(1)requests库来获取网页的html文档,代码与书上的代码大致相同
def fetch_university_ranking(url):"""获取网页HTML"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}print(f"正在获取页面: {url}")response = requests.get(url, headers=headers, timeout=10)response.encoding = 'utf-8'return response.text
(2)BS库的作用是提取html文档中的信息
那么要提取的话我们就要先看html的结构大致是什么样的,F12查看html文档的结构,查看我们需要的学校名称,省市,学校类型,总分等信息
通过查看html文档我们可以画出文档树
由文档树可知,我们要找到tbody元素,再获取tbody下的所有tr元素,再获取tr元素下的所有td元素
代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
使用 requests 和 BeautifulSoup 爬取中国大学排名(表格打印版)
目标网址: http://www.shanghairanking.cn/rankings/bcur/2020
"""import requests
from bs4 import BeautifulSoupdef fetch_university_ranking(url):"""获取网页HTML"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}print(f"正在获取页面: {url}")response = requests.get(url, headers=headers, timeout=10)response.encoding = 'utf-8'return response.textdef parse_ranking_data(html):"""解析大学排名数据"""soup = BeautifulSoup(html, 'lxml')rankings = []tbody = soup.find('tbody')if not tbody:print("未找到排名表格")return rankingsrows = tbody.find_all('tr')print(f"找到 {len(rows)} 条排名记录\n")for row in rows:cols = row.find_all('td')if len(cols) >= 5:rank = cols[0].get_text(strip=True)school_name_tag = cols[1].find('span', class_='name-cn')school_name = school_name_tag.get_text(strip=True) if school_name_tag else ''province = cols[2].get_text(strip=True)school_type = cols[3].get_text(strip=True)score = cols[4].get_text(strip=True)rankings.append({'rank': rank,'school_name': school_name,'province': province,'school_type': school_type,'score': score})return rankingsdef main():"""主函数"""url = "http://www.shanghairanking.cn/rankings/bcur/2020"html = fetch_university_ranking(url)rankings = parse_ranking_data(html)if not rankings:print("没有获取到数据")return# 打印表头print(f"{'排名':<6}{'学校名称':<15}{'省市':<8}{'学校类型':<10}{'总分':<6}")print("-" * 50)# 打印每条数据for item in rankings:print(f"{item['rank']:<6}{item['school_name']:<15}{item['province']:<8}{item['school_type']:<10}{item['score']:<6}")if __name__ == "__main__":main()
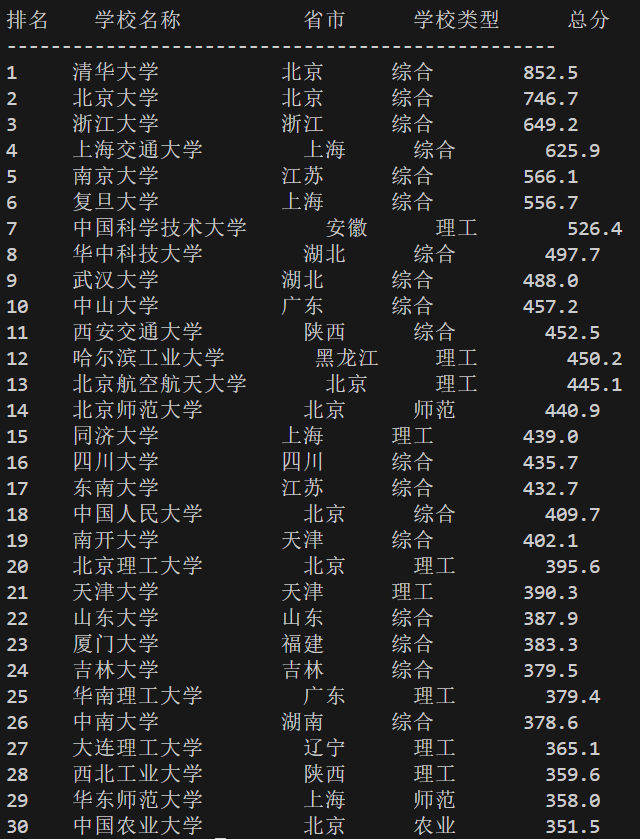
运行结果如下
2.心得体会
BS库实质就是将html库看是是树,将BS库的各种操作看成是对树的操作可以帮助我们更好的理解这个库的应用
作业二
1.用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
同作业一一样我们先来大致看下各个库的应用
(1)requests同作业一相同
(2)re库的作用就是将html文档看成是一个长字符串,然后从字符串中提取出我们想要的信息,同样的我们也需要先详细看看html文档,才能确认我们需要的信息的字符串的特点来写出我们的re字符串匹配
F12查看网站的html文档。网站url为"https://search.bl.com/k%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-%u4E66%u5305-_5#"
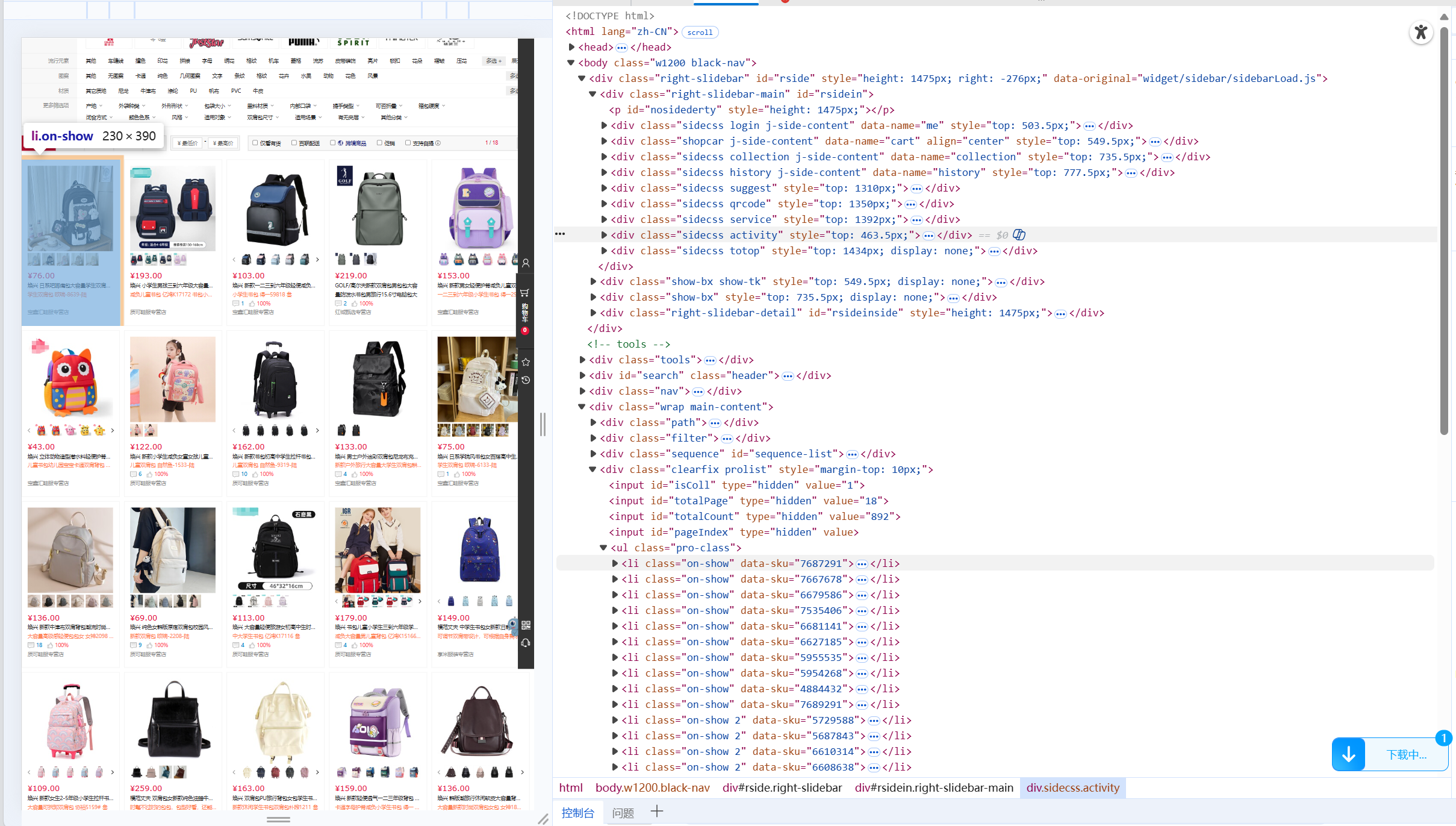
通过访问html文档我们可以知道所用商品在类名为"pro-class"的ul元素下的li元素下,
并且价格的字符串对应的形式为
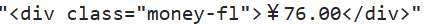
名称对应的形式为
那么我们可以这样按照以下步骤完成我们的任务
<1>提取ul元素下的所有li元素构成一个列表
本质上为一个字符串列表
<2>从li元素中提取我们需要的价格以及名称
其中价格为¥后方紧跟的数(这里要注意数字的格式),名称为target="_blank"的a元素的title的值
<3>输出我们需要的数
由此我们可以得到我们代码
# 抓取 bl.com 搜索结果:商品名称 + 价格(requests + re),并保存为 CSV(修复价格为空/为0问题)
import requests
import re
import csv
import osurl = "https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.9","Referer": "https://search.bl.com/",
}resp = requests.get(url, headers=headers, timeout=12)
resp.encoding = resp.apparent_encoding
html = resp.textitem_blocks = re.findall(r'<li[^>]*class="[^"]*on-show[^"]*"[^>]*>(.*?)</li>', html, flags=re.I|re.S)# 2) 在每个字符串里提取:价格与商品名
name_text_re = re.compile(r'<a[^>]*target="_blank"[^>]*title="(.*?)"[^>]*>',re.I | re.S
)price_in_moneyfl_re = re.compile(r'¥\s*([0-9]+(?:\.[0-9]+)?)',
)# 去标签results = []
for blk in item_blocks:# 名称m_name = name_text_re.search(blk)name = m_name.group(1).strip() if m_name else ""m_price = price_in_moneyfl_re.search(blk)price = m_price.group(1).strip() if m_price else ""if name or price:results.append((name, price))# 3) 按“序号 价格 商品名”打印
print("序号\t价格\t商品名")
cnt=0
for (name, price) in results:cnt+=1print(f"{cnt}\t{price}\t{name}")
上述代码的运行结果如下

2.心得体会
运行结果并不如意,仅仅爬取了10个书包的信息,但页面完全加载完后,不只10个书包,通过询问AI后,得知
requests请求获取的是静态html,而现代浏览器并不是一次性将所有数据都写死在HTML中,而是先加载一个大致的HTML框架再用JavaScript(一种浏览器脚本语言)向服务器发送请求,再将数据动态的写入html文档中。
简而言之,我们用requests所获得的只是一个"空壳HTML"
我们可以使用selenium库来解决,代码如下将requests部分改为selenium,re部分不变
此处代码不符合题目要求但可作为拓展
import time
import re
from selenium import webdriverdriver = webdriver.Edge()# 打开目标页面
url = "https://search.bl.com/k-%25E4%25B9%25A6%25E5%258C%2585.html?bl_ad=P668822_-_%u4E66%u5305_-_5"
driver.get(url)# 等待页面加载完成
time.sleep(60)# 获取页面源码
html = driver.page_source# 1) 切分每个商品块(li.on-show)
item_blocks = re.findall(r'<li[^>]*class="[^"]*on-show[^"]*"[^>]*>(.*?)</li>', html, flags=re.I|re.S)# 2) 在每个块里提取:价格与商品名
name_text_re = re.compile(r'<a[^>]*target="_blank"[^>]*title="(.*?)"[^>]*>',re.I | re.S
)price_in_moneyfl_re = re.compile(r'¥\s*([0-9]+(?:\.[0-9]+)?)',
)results = []
for blk in item_blocks:# 名称m_name = name_text_re.search(blk)name = m_name.group(1).strip() if m_name else ""m_price = price_in_moneyfl_re.search(blk)price = m_price.group(1).strip() if m_price else ""if name or price:results.append((name, price))# 3) 按“序号 价格 商品名”打印
print("序号\t价格\t商品名")
cnt=0
for (name, price) in results:cnt+=1print(f"{cnt}\t{price}\t{name}")# 关闭浏览器
driver.quit()部分结果如下

作业三
1.爬取一个给定网页或者自选网页的所有JPEG、JPG或PNG格式图片文件
思路同作业2大体相同
(1)通过F12查看html文档确认我们要寻找的元素
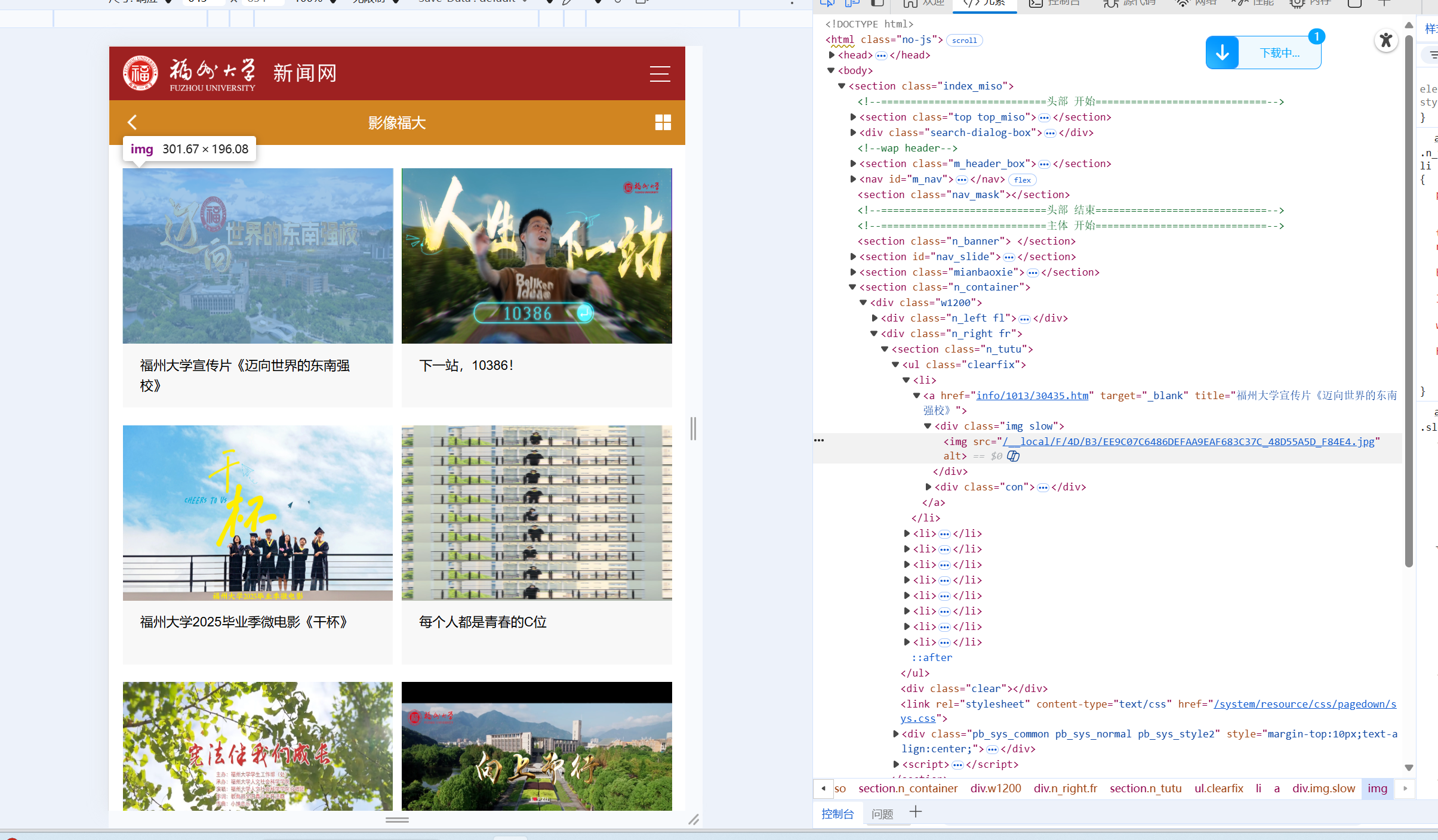
通过查看html我们再画出html树

由于我们要获取的是图片,所以我们要将url与img元素的src进行拼接获取图片的地址

也就上图的《当前源》,再从图片的url下载图片
代码如下
import requests
from bs4 import BeautifulSoup
import os
import urllib
url="https://news.fzu.edu.cn/yxfd.htm"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.9","Referer": "https://search.bl.com/",
}#从网络上随便找一个请求头
if not os.path.exists("download"):os.mkdir("download")#创建一个文件夹用来存放下载的图片
resp=requests.get(url,headers=headers)
resp.encoding=resp.apparent_encoding#编码方式根据实际的编码来处理
soup=BeautifulSoup(resp.text,'lxml')
n_container=soup.find(name="section",attrs={"class":"n_container"})#找到n_container这个标签
clearfix=n_container.find(name="ul",attrs={"class":"clearfix"})#在n_container标签下找到ul标签,class属性为clearfix
imgs=clearfix.find_all(name="img")
cnt=0
for img in imgs:#src=urllib.parse.urljoin(url,img['src'])#获取图片来源的地址resp=requests.get(src,headers=headers)#获取图片内容with open(f"download/{cnt}.jpg","wb") as f:#写入文件夹f.write(resp.content)cnt+=1
2.心得体会
再巩固一下requests,BS库的使用,知道了图片的下载方式