numpy模块
- numpy模块的主要作用:
- numpy表示一维或者多维的数组(容器),主要是用来存储和运算数值型数据的。
- 常用属性:
- shape:返回数组的形状
- ndim:返回数组的维度
- size:返回数组元素的个数
- dtype:返回数组元素的数据类型。
- 只可存储相同类型的数据。
- 数组元素类型的修改:
- arr.astype('float'),将arr这个数组的数组元素类型修改为float类型
- 数组级联(concatnate函数):
- 可以将两个或者两个以上的数组进行横向或者纵向的拼接。
- 变形(reshape函数):
- 可以将创建好的数组的形状进行变换。
- 举例:arr是一个3行4列的二维数组,通过reshape函数将arr数组变形成2行6列or1行12列...
- 注意:数组变形前和变形后数组的容量不可以发生变化。
- 统计函数:
- std():标准差
- var():方差
- median():中位数
- 。。。
- 索引和切片:
- 通过索引和切片的机制可以定位捕获到数组中任意指定的相关元素。
- 索引操作:
- arr[index]:取出index表示的行
- arr[:,col]:取出col表示的列
- arr[index,col]:取出index行和col列对应的相关元素
- 切片操作:
- arr[index1:indexn]:切行
- arr[:,col1:coln]:切列
pandas模块
- pandas模块中两个常用的类:
- Series:一维结构
- DataFrame:二维表格结构
- 多个Series可以组成一个DataFrame
- Series常用操作:
- isnull():可以判定Series中的每一个元素是否为空,如果为空则返回一个True,否则返回False
- notnull():可以判定Series中的每一个元素是否为非空,如果为非空则返回True,否则返回False
- 布尔值是可以作为Series的索引来使用的。True对应的元素会被保留,False对应的元素会被忽略
- s = Series([1,2,3])使用布尔值作为s的索引s[[True,False,True]]取出的元素为[1,3]
- unique():可以对Series中存储的元素进行去重操作,返回去重后的结果。
- nunique():可以返回对Series元素进行去重后的元素个数
- value_counts():可以对Series中的每一个元素出现的次数进行统计。
- DataFrame常用操作:
- 索引操作:
- 索引取单列:df[col]取出col表示的一列数据
- 索引取多列:df[[col1,col2]]取出col1和col2两列数据
- 索引取单行:df.iloc/loc[index]取出index表示的一行数据
- 索引取多行:df.iloc/loc[[index1,index2]]取出index1和index2两行数据
- 索引取元素:df.iloc/loc[index,col]取出index行col列对应的相关元素
- 切片操作
- 切行:df[index1:indexn]
- 切列:df.iloc/loc[:,col1:coln]
- 时间类型的转换:
- pd.to_datetime(df[col])可以将df的col列的数据类型转换成时间类型
- 将指定的一列作为源数据的行索引
- df.set_index('col_name'):可以将df中的col_name这一列作为df的行索引来使用
- df的数据加载
- pd.read_xxx():read_csv(),read_sql(),read_excel()
- df的数据保存
- df.to_xxx():to_csv(),to_excel()
- 指定数据的删除:
- df.drop(index,columns):可以将index表示的行或者columns表示的列在df表格中进行删除
- 排序:
- sort_index():根据索引排序
- sort_values():根据值排序
- 级联操作concat:对两个或者多个df进行横向或者纵向的拼接
- 可以将两个或者df表格进行横向或者纵向拼接
- 合并操作merge:对两个df中的数据进行合并
- 替换操作replace:
- 可以将df表格中的指定元素进行替换操作
- map函数:只可以被Series调用
- 映射:df['name'].map(dic)可以使用dic表示的映射关系表对df的name列的每一个元素进行映射操作
- 充当运算工具:df['salary'].map(func)可以使用func这个自定义函数对df中salary列的每一个元素进行运算操作。
- 分组操作:groupby
- 高级分组聚合:
- 自定义分组后的聚合函数,可以通过apply函数在分组后使用自定义的函数对分组结果进行聚合操作
- agg:可以将分组结果进行多种不同形式的聚合操作
- df.groupby(by='item')['price'].agg(['max','sum'])
- 透视表:pivot_table
- index
- values
- aggfunc
- columns
- df.apply(func,axis):
- 可以对df这个表格中的行或者列进行func形式的处理和运算
- df.applymap(func):
- 可以对df这个表格中的每一个元素进行处理和运算
- 索引操作:
matplotlib
- 折线图
- plt.plot(x,y)
- 柱状图
- plt.bar(x,hight)
- 直方图
- plt.hist(x)
- 饼图
- plt.pie(x)
- 散点图
- ple.scanter(x,y)
深入理解机器学习:
-
算法模型对象:
- 一种特殊的对象,特殊之处在于,该对象内部集成/封装了某种形式的算法/方程。该算法/方程用于找寻数据间的规律。假设某一个模型内部封装的算法/方程如下:
- y = w * x + b,这是一个还没有求出解的方程式。
- 一种特殊的对象,特殊之处在于,该对象内部集成/封装了某种形式的算法/方程。该算法/方程用于找寻数据间的规律。假设某一个模型内部封装的算法/方程如下:
-
样本数据:
- 特征数据:自变量(一个样本的描述信息)
- 标签数据:因变量(一个样本数据的结果)

-
模型的训练:
- 将样本数据带入到算法模型对象内部的算法/方程中,对算法/方程进行求解操作。
- 在该算法/方程中 y = w * x + b,如果求出了w和b则方程就可有解。
- 模型训练就是在使用算法/方程找寻样本数据之间的规律。
-
模型的作用:
- 对未知样本实现预测、分类或者决策。
- 算法/方程的解就是模型实现分类或者预测的结果。
-
算法模型的分类:
- 有监督类别:
- 有监督学习是指使用带有标签的样本数据来训练模型
- 无监督类别:
- 无监督学习是指使用没有标签的样本的数据训练模型
- 有监督类别:
KNN分类算法原理
简单地说,KNN算法是采用测量不同特征值之间的距离方法进行分类。大家可以类别:近朱者赤近墨者黑这句话进行理解。
下面,我们就详细来理解下KNN的分类原理,先看下图:w1(猫)、w2(狗)和w3(兔子)是三个已知类群,X则是一个未知类别的图片样本,现在要基于KNN算法将X样本分到w1、w2和w3其中的一个类别中,以确定X图片中的动物到底是猫、狗还是兔子。

根据我们的直接感受,应该是衡量X样本距离w1、w2和w3哪个类群最近,则X样本就应该被分到哪个类别中。这个是不是就好比与:近朱者赤近墨者黑呢。那么,KNN究竟是如何实现的分类呢?
实现步骤:
- 算距离:KNN算法会计算X样本到其余所有样本之间的距离。(有几个其余样本就会计算几次距离)
- 找近邻:定义一个k值,找出离X最近的k个样本最为X最近的k个邻居。注意,k值是需要认为定义的一个数值。
- 投票:根据k个最近的邻居样本的类别标签进行投票,哪个类别的标签得票最多(在k个样本中哪个类别样本数量最多),则X样本就归属到该类别中。
注意:不同的k,可能会造成不同的分类结果
在下图中,如果k为3则小球的分类结果为三角形,k为5则分类结果为正方形。因此,k值的最优选择在KNN中是比较重要的一个环节,稍后会详细进行讲解说明。

距离计算方式:
可以是欧式距离、曼卡顿距离或者闵可夫斯基距离等方式。

电影分类
众所周知,电影可以按照题材分类,然而题材本身是如何定义的?由谁来判定某部电影属于哪个题材?也就是说同一题材的电影具有哪些公共特征?这些都是在进行电影分类时必须要考虑的问题。下面我们就一起来探究下电影如何实现分类?
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| California Man | 3 | 104 | 爱情片 |
| He Not Really into Dudes | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped 2 | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
采集到了一组电影的样本数据,每一个电影样本有两个特征维度:打斗镜头和接吻镜头,电影类型为目标数据,有爱情和动作两种类别。其中有一部未知类别的电影"?",并且提取到了该电影的打斗和接吻镜头的数量。接下来,使用KNN来计算电影 “?” 的特征到其他已知类型电影特征之间的距离。
下面可以,观测下具体的距离显示:

根据欧式距离,进行距离计算结果如下:
| 电影名称 | 与未知类型电影“?”的距离 |
|---|---|
| California Man | 20.5 |
| He Not Really into Dudes | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped 2 | 118.9 |
制定k的值,找到电影 “ ?”周围最近的k个邻居,假定k的值为3,则离其最近的3个邻居是:
| 电影名称 | 电影类型 |
|---|---|
| California Man | 爱情片 |
| He Not Really into Dudes | 爱情片 |
| Beautiful Woman | 爱情片 |
投票:最近的3个邻居种,爱情类别的得票最多,因此 “ ?”电影的类别被KNN划分到了爱情片类别。
何为回归?
- 回归问题判定:
- 回归问题对应的样本数据的标签数据是连续性的值,而分类问题对应的是离散型的值。
- 在社会中产生的数据必然是离散型或者是连续型的数据,那么企业针对数据所产生的需求也无非是分类问题或者回归问题。
- 常见的回归问题:
- 预测房价
- 销售额的预测
- 贷款额度指定
- ......
线性回归在生活中的映射
- 学生期末成绩制定
- 总成绩 = 0.7 * 考试成绩 + 0.3 * 平时成绩
- 则该例子中,特征值为考试成绩和平时成绩,目标值为总成绩。从此案例中大概可以感受到
- 回归算法预测出来的结果其实就是经过相关的算法计算出来的结果值!
- 每一个特征需要有一个权重的占比,这个权重的占比明确后,则就可以得到最终的计算结果,也就是获取了最终预测的结果了。
- 那么这个特征对应的权重如何获取或者如何制定呢?
现在有一组售房数据:
| 面积 | 售价 |
|---|---|
| 55 | 110 |
| 76 | 152 |
| 80 | 160 |
| 100 | 200 |
| 120 | 240 |
| 150 | 300 |
对售房数据的分布情况进行展示

问题:假如现在有一套房子,面积为76.8平米,那么这套房子应该卖多少钱呢?也就是如何预测该套房子的价钱呢?上图中散点的分布情况就是面积和价钱这两个值之间的关系,那么如果该关系可以用一种分布趋势来表示的话,那么是不是就可以通过这分布趋势预测出新房子的价格呢?
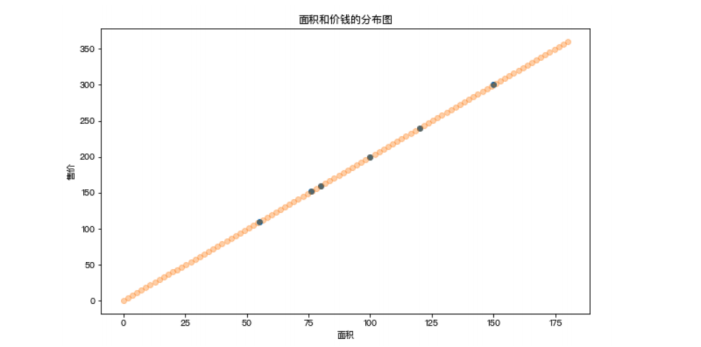
在上图中使用了一条直线来表示了房子的价格和面积对应的分布趋势,那么该趋势找到后,就可以基于该趋势根据新房子的面积预测出新房子的价格。
线性回归的作用:找出特征和目标之间存在的某种趋势,在二维平面中,该种趋势可以用一条线段来表示,该条线段用一元一次线性方程来表示:y = w * x + b。
将上述的售房数据,带入到线性方程中,经过求解,w和b变为了已知,现在方程为:y = 2 * x + 0。则发现,在上述售房数据中,面积和价格之间的关系是二倍的关系,其实就可以映射成:价格 = 2 * 面积 ,这个方程就是价格和面积的分布趋势,也就是说根据该方程就可以进行新房子价格的预测。
损失函数
如果在房价预测案例中,房子的面积和价格的分布规律如下图所示(非线性的分布),那是否还可以使用一条直线表示特征和目标之间的趋势呢?

可以,只要保证直线距离所有的散点距离最近,则该直线还是可以在一定程度上表示非线性分布散点之间的分布规律。但是该规律进行的预测会存在一定的误差/损失!
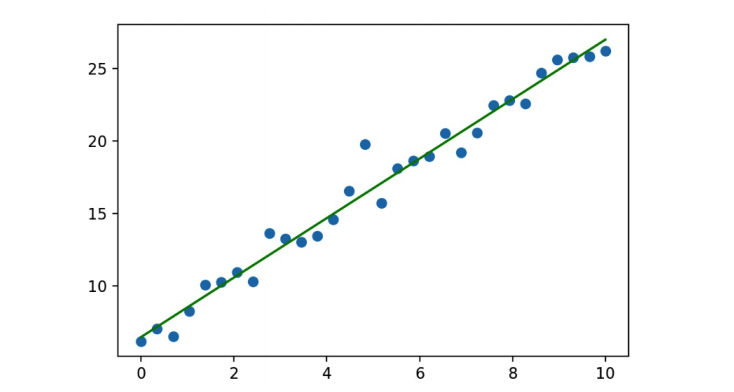
在多数的预测场景中,预测结果和真实结果之间都会存在一定的误差,那么误差存在,我们应该如何处理损失/误差呢?
量化损失/损失函数:真实结果y和预测结果(xw)差异平方的累加和(误差平方和/残差平方和):
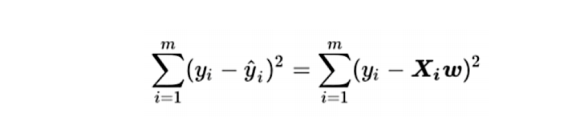
提问:损失函数公式中,误差的大小和哪个系数有直系的关联呢?
答案:和权重系数w是有直系关联。也就是说w的不同会导致误差大小的不同,那么线性回归算法迭代训练过程中最终的问题就转化成了如何去求解线性方程中的w使得误差可以最小。
无监督学习与聚类算法
-
概述
- 在此之前我们所学习到的算法模型都是属于有监督学习的模型算法,即模型需要的样本数据既需要有特征矩阵X,也需要有真实的标签y。那么在机器学习中也有一部分的算法模型是属于无监督学习分类的,所谓的无监督学习是指模型只需要使用特征矩阵X即可,不需要真实的标签y。那么聚类算法就是无监督学习中的代表之一。
-
聚类算法
-
聚类算法其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务 需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量 的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动。

-
KMeans算法原理阐述
-
簇与质心:
- 簇:KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一个又一个聚集在一起的数 据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
- 质心:簇中所有数据的均值u通常被称为这个簇的“质心”(centroids)。
- 在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
- 质心的个数也聚类后的类别数是一致的
-
在KMeans算法中,簇的个数K是一个超参数,需要我们人为输入来确定。KMeans的核心任务就是根据我们设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下:

- 那什么情况下,质心的位置会不再变化呢?当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了。
-
这个过程在可以由下图来显示,我们规定,将数据分为4簇(K=4),其中白色X代表质心的位置:

-
聚类算法聚出的类有什么含义呢?这些类有什么样的性质?
- 我们认为,被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的,当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的商业或者科技策略。
- 聚类算法追求“簇内差异小,簇外差异 大”:
- 而这个“差异“,由样本点到其所在簇的质心的距离来衡量。
-
对于一个簇来说,所有样本点到质心的距离之和越小,我们就认为这个簇中的样本越相似,簇内差异就越小。而距离的衡量方法有多种,令x表示簇中的一个样本点,u表示该簇中的质心,n表示每个样本点中的特征数目,i表示组成点的每个特征,则该样本点到质心的距离可以由以下距离来度量:

轮廓系数
-
在99%的情况下,我们是对没有真实标签的数据进行探索,也就是对不知道真正答案的数据进行聚类。这样的聚 类,是完全依赖于评价簇内的稠密程度(簇内差异小)和簇间的离散程度(簇外差异大)来评估聚类的效果。其中 轮廓系数是最常用的聚类算法的评价指标。它是对每个样本来定义的,它能够同时衡量:
- 1)样本与其自身所在的簇中的其他样本的相似度a,等于样本与同一簇中所有其他点之间的平均距离
- 2)样本与其他簇中的样本的相似度b,等于样本与下一个最近的簇中的所有点之间的平均距离 根据聚类的要求”簇内差异小,簇外差异大“,我们希望b永远大于a,并且大得越多越好。
- 单个样本的轮廓系数计算为:
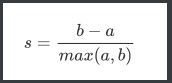
-
很容易理解轮廓系数范围是(-1,1):
- 其中值越接近1表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。
- 当轮廓系数为0时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。可以总结为轮廓系数越接近于1越好,负数则表示聚类效果非常差。
-
如果一个簇中的大多数样本具有比较高的轮廓系数,则簇会有较高的总轮廓系数,则整个数据集的平均轮廓系数越高,则聚类是合适的:
- 如果许多样本点具有低轮廓系数甚至负值,则聚类是不合适的,聚类的超参数K可能设定得 太大或者太小。