IK分词器介绍
在ElasticSearch中默认使用的分词器为Standard分词器,该分词器对中文不友好,对中文的处理方式是按单个汉字分词,无法识别中文里的词语、短语等语义单元。例如对于 "汉朝" 这个词,默认分词器会将其拆分为 ["汉", "朝"] 两个独立字符,match查询会匹配所有包含 "汉"或"朝" 字符的文档,这意味着不仅会匹配 "汉朝",还会匹配包含 "汉"(如 "汉景帝"、"汉武帝")或 "朝"(如 "唐朝"、"明朝")的任何文档。
IK 分词器(IK Analyzer for Elasticsearch) 正是为解决中文分词痛点而生的开源分词插件,它专为中文文本优化,能精准识别中文词语,是 ES 生态中最主流的中文分词解决方案。
核心分词模式
在IK分词器中,有两种分词模式,分别是ik_smart、ik_max_word,可根据业务场景灵活切换:
- ik_smart(智能分词)
- 特点:采用最少切分策略,会做最粗粒度的拆分。
- 示例:对于 "中华人民共和国国歌",会拆分为 ["中华人民共和国", "国歌"]
- 适用场景:需要快速分词且希望词语颗粒度较大的场景,如标题检索、简单匹配等
- ik_max_word(最大分词)
- 特点:采用最细粒度切分策略,会穷尽所有可能的词语组合。
- 示例:对于 "中华人民共和国国歌",会拆分为 ["中华人民共和国", "中华人民", "中华", "华人", "人民共和国", "人民", "人", "民", "共和国", "共和", "国", "国歌"]
- 适用场景:需要全面细致分词的场景,如全文检索、深度语义分析等,能提高召回率
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。
不使用ik分词器,使用es的默认分词模式:会把这五个字拆分成五个独立的字。

使用ik分词器的ik_smart分词模式拆分后
使用ik分词器的ik_max_word分词模式拆分后

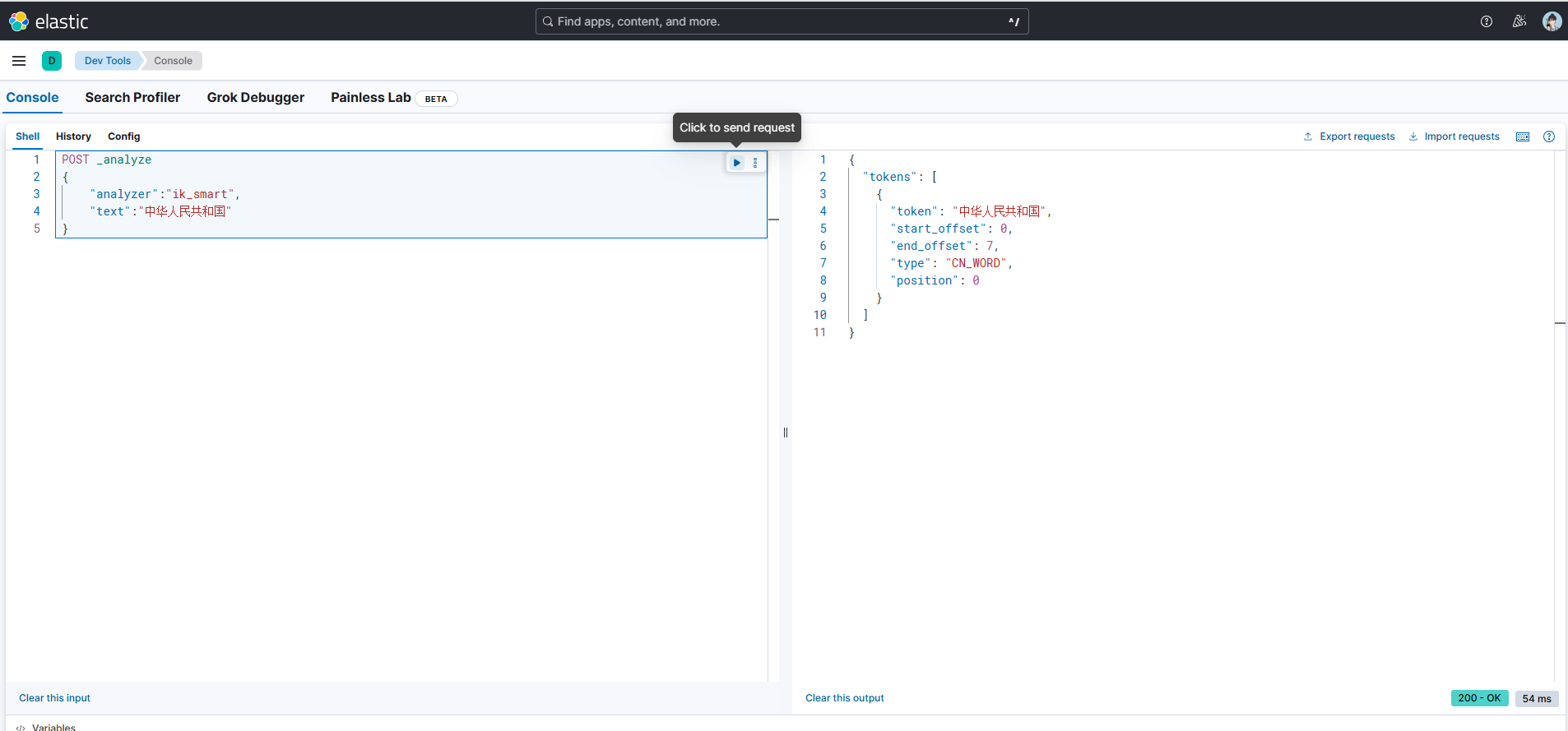
再以“中华人民共和国”这个文本进行举例。这里使用的是POST方式,这也是官方API推荐的方法,虽然使用GET也行,但不符合严格的HTTP规范。
ik_smart
POST _analyze
{"analyzer":"ik_smart","text":"中华人民共和国"
}
ik_max_word
POST _analyze
{"analyzer":"ik_max_word","text":"中华人民共和国"
}

工作原理
IK 分词器的分词流程分为 3 个核心步骤:
- 字符过滤:去除特殊字符(如标点、空格),统一大小写。
- 分词处理:基于词典匹配(正向 / 反向最大匹配算法)拆分文本,优先匹配最长词,再递归拆分剩余部分。
- 词过滤:过滤停用词、标点,输出最终分词结果。
应用场景
- 中文全文检索:电商商品标题 / 详情搜索、新闻资讯检索、企业文档检索等。
- 中文文本分析:用户评论情感分析、关键词提取、内容分类等。
- 多语言混合场景:支持中英文混合文本分词(如 “iPhone 17 发布会” → [iPhone, 17, 发布会])。
优缺点
| 优点 | 缺点 |
|---|---|
| 中文分词精度高,适配语义 | 词库需定期维护(新增行业词、网络热词) |
| 支持两种分词模式,灵活适配索引 / 搜索 | 分词速度略低于默认单字分词(但满足绝大多数场景) |
| 自定义词库配置简单,支持远程更新 | 对生僻词、未登录词(如网络新词)拆分效果依赖词库 |
| 社区活跃,更新及时(适配 ES 最新版本) | 不支持分词歧义消解(如 “苹果” 既指水果也指品牌) |
windows系统安装与配置IK
- 下载
官网下载地址:https://github.com/infinilabs/analysis-ik
可用的下载地址:https://release.infinilabs.com/analysis-ik/stable/
注意:下载的版本必须和es的版本保持一致。

- 解压
在es的plugins文件夹下创建ik文件夹,然后将下载好的压缩包解压到该目录中。

验证安装是否生效
对指定文本进行分析并返回文本经过分析器处理后的的详细结果。
当未安装IK分词器时,Elasticsearch 会使用默认分析器(standard 分析器),对于中文文本,标准分析器会将每个汉字拆分为独立的词元。
GET _analyze
{"text":"我不喜欢你"
}
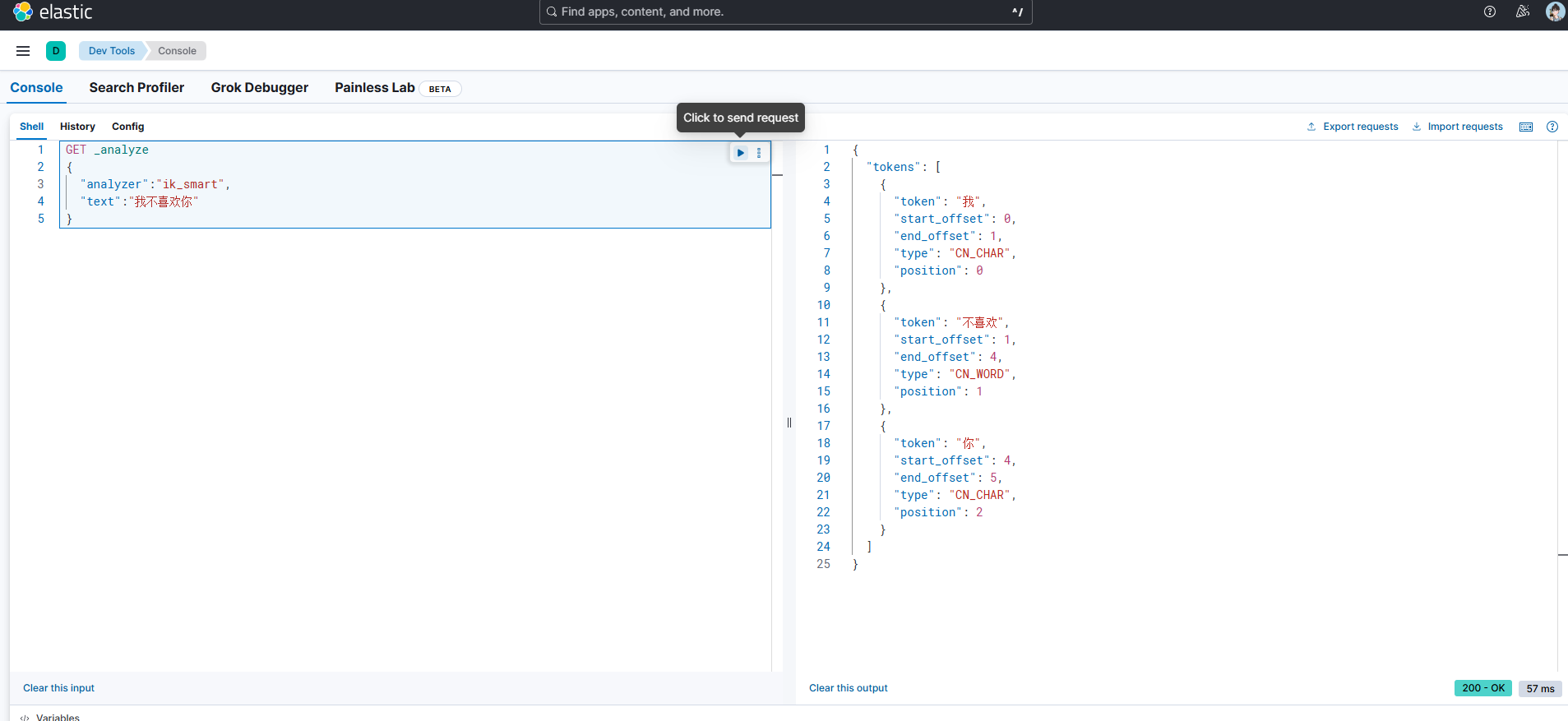
例如对于文本 "我不喜欢你",默认分析的结果会将其拆分为以下形式。
{"tokens": [{"token": "我", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>", "position": 0},{"token": "不", "start_offset": 1, "end_offset": 2, "type": "<IDEOGRAPHIC>", "position": 1},{"token": "喜", "start_offset": 2, "end_offset": 3, "type": "<IDEOGRAPHIC>", "position": 2},{"token": "欢", "start_offset": 3, "end_offset": 4, "type": "<IDEOGRAPHIC>", "position": 3},{"token": "你", "start_offset": 4, "end_offset": 5, "type": "<IDEOGRAPHIC>", "position": 4}]
}
当已安装IK分词器时,ES查询的时候默认不会自动使用IK,需要在请求中明确指定IK分词器才能生效,如下所示,分别采用两种分词模式进行拆分查询。
GET _analyze
{"analyzer":"ik_smart","text":"我不喜欢你"
}

GET _analyze
{"analyzer":"ik_max_word","text":"我不喜欢你"
}

索引配置映射
创建 emperor 索引及文档。
POST /emperor/_doc
{"name":"李世民","dynasty":"唐朝","age":51
}POST /emperor/_doc
{"name":"刘邦","dynasty":["秦朝","汉朝"],"age":61
}POST /emperor/_doc
{"name":"朱元璋","dynasty":"明朝","age":70
}POST /emperor/_doc
{"name":"乾隆","dynasty":"清朝","age":89
}
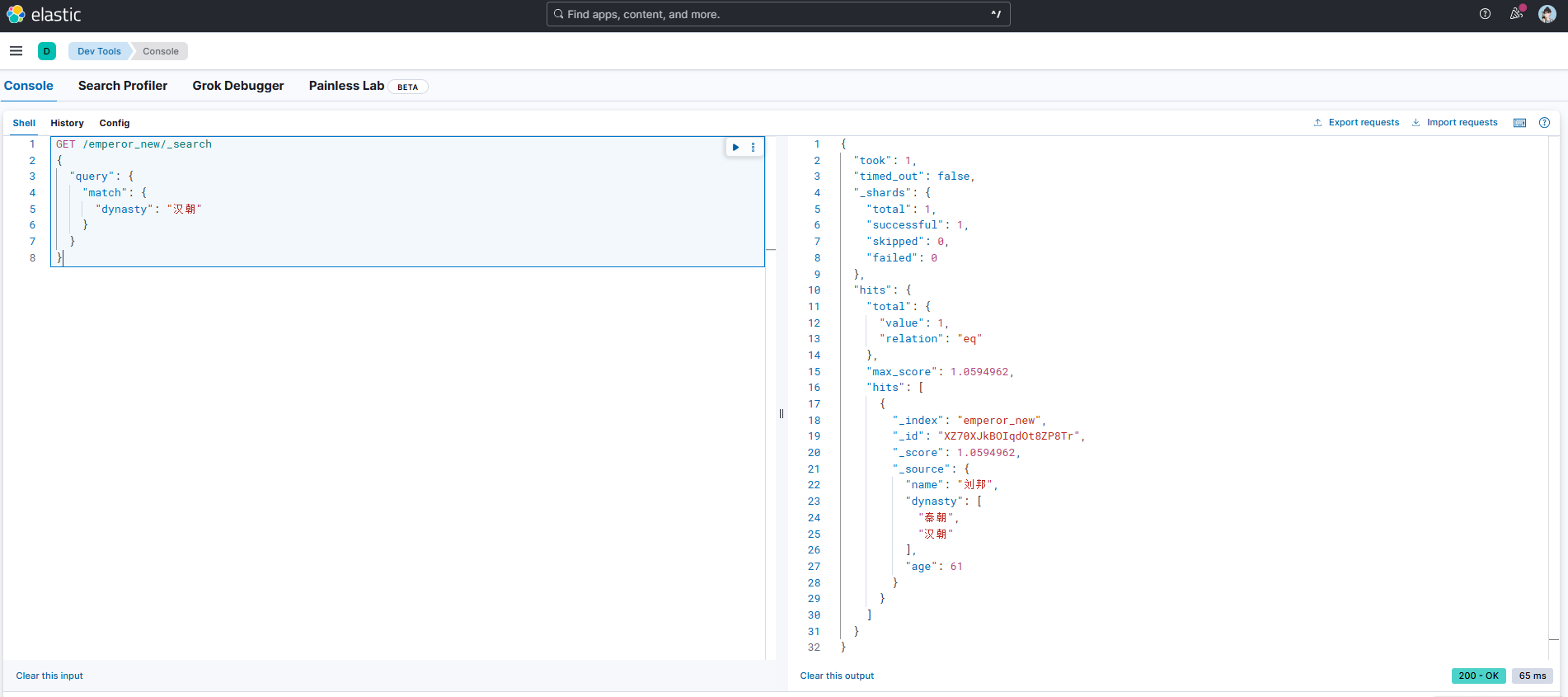
下面将使用match匹配汉朝数据,可以看到由于ES采用的是默认Standard分词模式,匹配的数据并不是我们想要的数据。虽然我们已经安装了IK分词器。
GET /emperor/_search
{"query": {"match": {"dynasty": "汉朝"}}
}

如果想要精准匹配,可以使用以下两种方式,这两种方式与安不安装IK分词器没关系,都能实现精准匹配。
方式一
GET /emperor/_search
{"query": {"match": {"dynasty.keyword": "汉朝"}}
}

方式二
GET /emperor/_search
{"query": {"term": {"dynasty.keyword": "汉朝"}}
}

如果我们不想使用keyword,也不想使用term,还是想通过match去实现精准匹配,可以在创建索引的时候配置映射,若索引已存在,则需重建索引。
- 创建索引的同时配置映射
#这里只对dynasty做了映射处理,如果其它字段也要处理可以继续添加
PUT /emperor
{"mappings": {"properties": {"dynasty": { "type": "text","analyzer": "ik_smart", # 使用IK分词器(智能分词,适合精确匹配)"search_analyzer": "ik_smart"}}}
}
- 若索引已存在,则需要通过重建索引修改映射,因为Elasticsearch 不允许直接修改已存在索引的映射(因为映射定义了数据的存储结构,直接修改可能导致数据不一致)。
#创建新索引(如emperor_new),配置目标映射
PUT /emperor_new
{"mappings": {"properties": {"dynasty": { "type": "text","analyzer": "ik_smart", "search_analyzer": "ik_smart"}}}
}

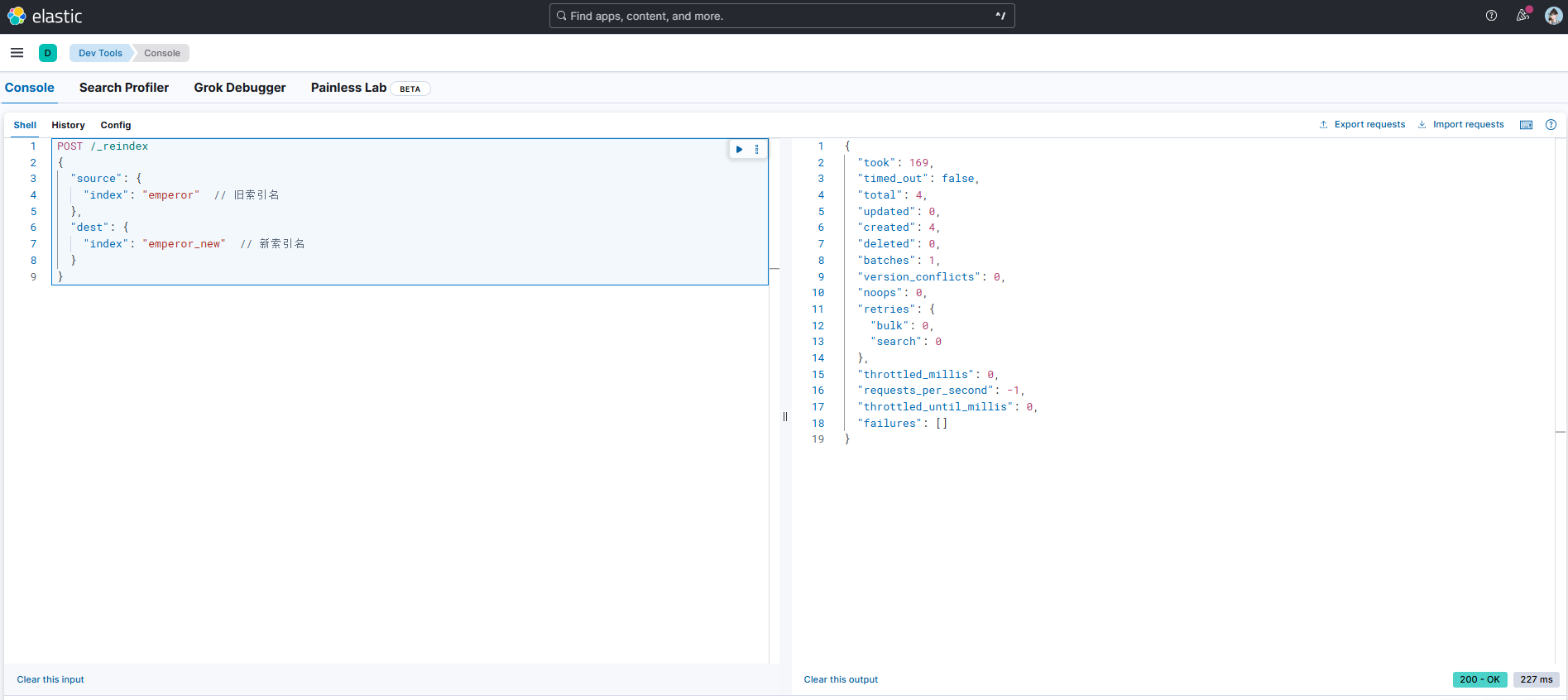
# 使用_reindex API迁移数据
POST /_reindex
{"source": {"index": "emperor" // 旧索引名},"dest": {"index": "emperor_new" // 新索引名}
}
# 删除旧索引
DELETE /emperor

此时通过新创建的新索引使用match查询可以实现精准匹配。
GET /emperor_new/_search
{"query": {"match": {"dynasty": "汉朝"}}
}
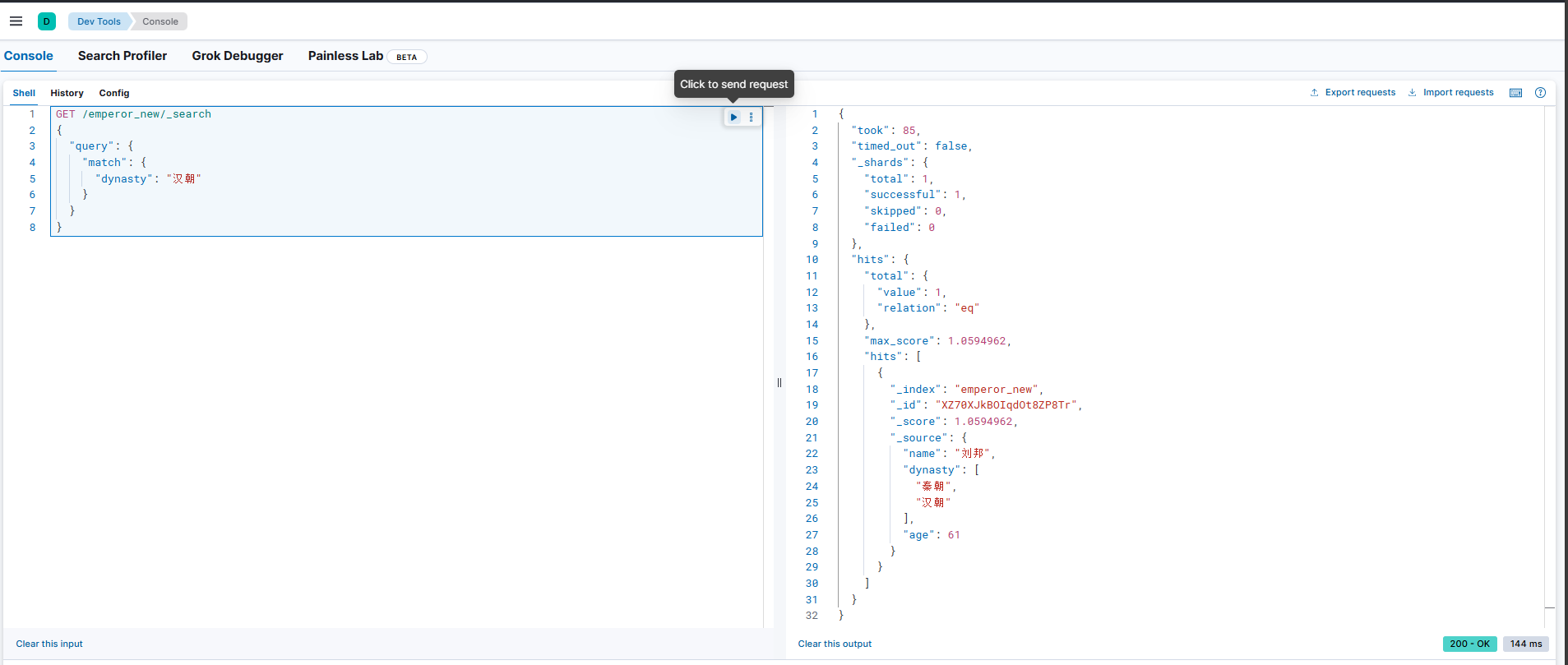
但是如果还想要用原来旧的索引名查询,可以执行以下命令去给新索引创建别名,执行之后即可以用新索引查询,也可以用旧索引查询。但要注意实际上只有新索引。
# 为新索引创建别名(保持查询接口不变)
POST /_aliases
{"actions": [{"add": {"index": "emperor_new","alias": "emperor" }}]
}