个人编程作业
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | [软件工程](首页 - 计科23级12班 - 广东工业大学 - 班级博客 - 博客园) |
| 这个作业要求在哪里 | [作业要求](个人项目 - 作业 - 计科23级12班 - 班级博客 - 博客园) |
| 这个作业的目标 | 训练个人项目软件开发能力,学会使用性能测试工具和实现单元测试优化程序 |
代码仓库: https://github.com/maple525866/3123004566-PaperplagiarismCheck/tree/master
PSP2表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | 200 | 220 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 40 |
| Design Spec | 生成技术文档 | 30 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 150 | 250 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 100 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 60 | 45 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 40 | 30 |
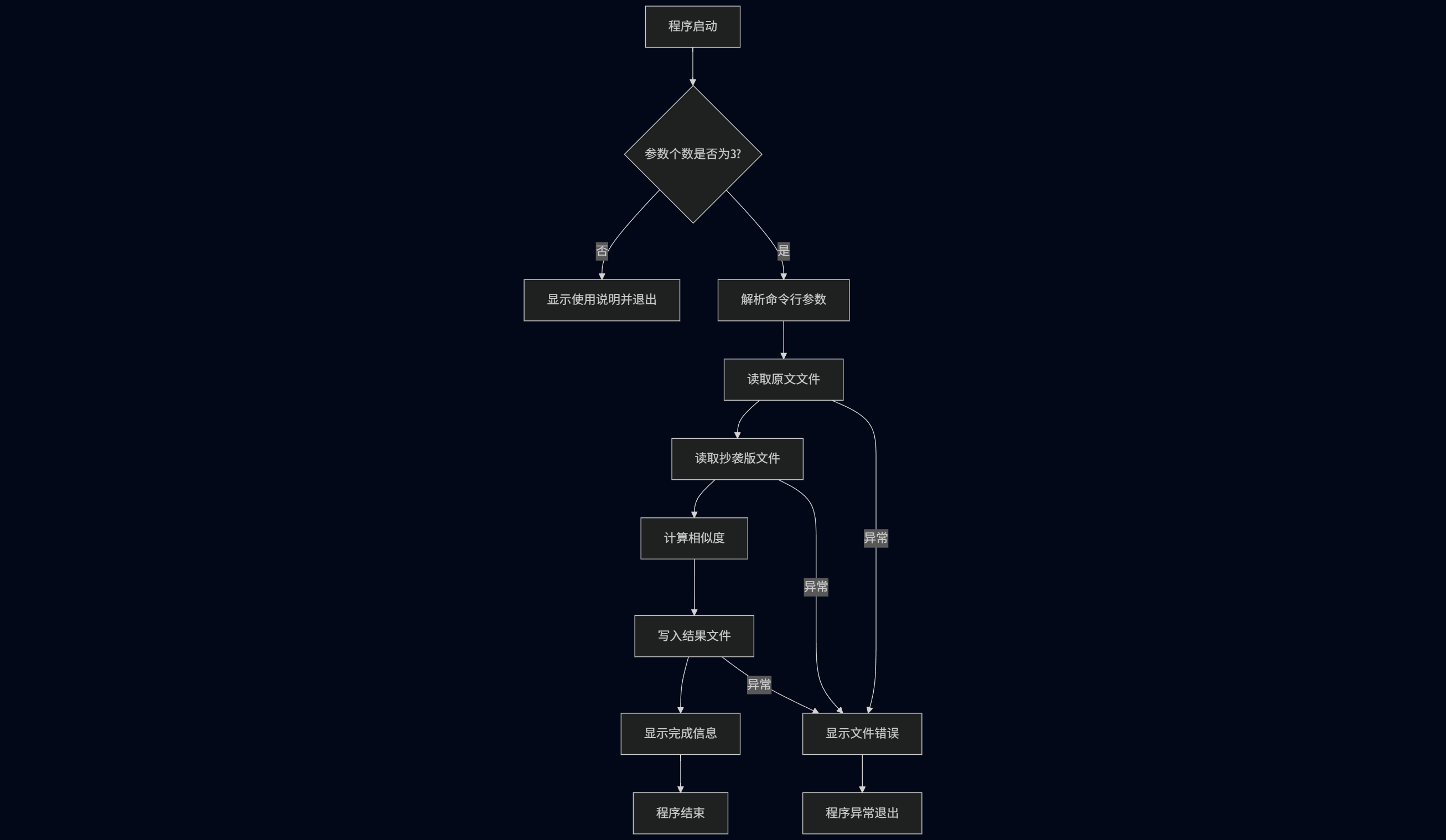
计算模块接口的设计与实现过程
代码组织结构设计
1.1 类结构设计
目前系统采用单一主类设计模式,所有核心功能集中在PlagiarismChecker类中:
PlagiarismChecker (主类)
├── main() # 程序入口,处理命令行参数
├── readFile() # 文件读取模块
├── writeResult() # 结果输出模块
├── calculateSimilarity() # 相似度计算核心算法
└── longestCommonSubsequence() # LCS算法实现
1.2 函数关系层次
Level 1: main()
├── 参数验证
└── 异常处理框架
Level 2: readFile() + calculateSimilarity() + writeResult()
├── 文件I/O操作
├── 核心算法逻辑
└── 格式化输出
Level 3: longestCommonSubsequence()
└── 底层算法实现
1.3 模块职责分离
- 输入模块:readFile() - 负责UTF-8文件读取和内容处理
- 计算模块:calculateSimilarity() + longestCommonSubsequence() - 核心算法逻辑
- 输出模块:writeResult() - 结果格式化和文件写入
- 控制模块:main() - 流程控制和异常处理
关键函数流程图
2.1 主程序流程
2.2 相似度计算流程
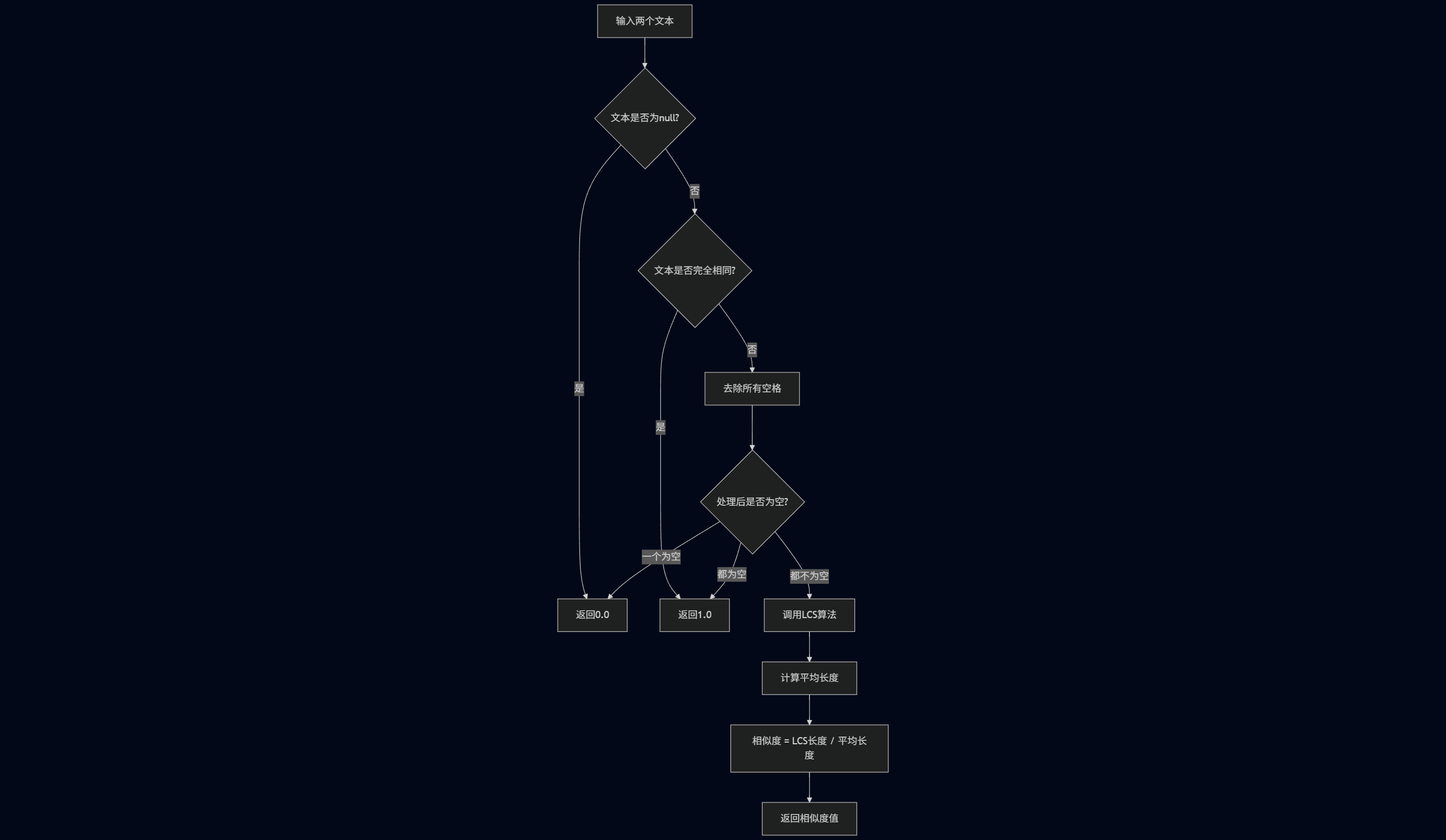
算法设计
3.1.核心算法设计 - LCS(最长公共子序列)
选择理由:
- 顺序保持:LCS算法保持字符的相对顺序,更符合文本相似性判断
- 容错性强:对文本中的插入、删除、替换操作具有很好的容错能力
- 语义保持:即使有词汇替换,核心语义结构仍能被识别
3.2.独到之处
- 对称性:交换两个文本位置,结果不变
- 归一化:结果范围固定在[0, 1]
- 平衡性:考虑两个文本的平均长度,避免长度偏差
3.3 文本预处理策略
智能空格处理:
- 消除格式影响:不同的空格、换行、制表符不影响相似度
- 专注内容:只关注实际文字内容的相似性
- 中文友好:适合中文文本的特点(词汇间不需要空格分隔)
3.4 性能优化考量
动态规划优化:
- 时间复杂度:O(m×n),其中m、n为文本长度
- 空间复杂度:O(m×n),使用二维DP表
- 实际优化:可进一步优化为O(min(m,n))空间复杂度
内存友好: - 使用StringBuilder进行文件读取,避免字符串频繁拼接
- DP表按需创建,处理完成后自动回收
单测代码
package com.code;import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.io.TempDir;import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;import static org.junit.jupiter.api.Assertions.*;/*** 论文查重系统单元测试类* 覆盖各种边界情况和正常情况,确保程序稳定性*/
public class PlagiarismCheckerTest {@TempDirPath tempDir;@Test@DisplayName("测试1: 完全相同的文本应该返回100%相似度")void testIdenticalTexts() {String text1 = "今天是星期天,天气晴,今天晚上我要去看电影。";String text2 = "今天是星期天,天气晴,今天晚上我要去看电影。";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertEquals(1.0, similarity, 0.01, "完全相同的文本相似度应该为1.0");}@Test@DisplayName("测试2: 完全不同的文本应该返回较低相似度")void testCompletelyDifferentTexts() {String text1 = "今天天气很好";String text2 = "明年计划去旅行";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertTrue(similarity < 0.3, "完全不同的文本相似度应该很低");}@Test@DisplayName("测试3: 部分相似文本的相似度计算")void testPartiallySimilarTexts() {String text1 = "今天是星期天,天气晴,今天晚上我要去看电影。";String text2 = "今天是周天,天气晴朗,我晚上要去看电影。";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertTrue(similarity > 0.5 && similarity < 1.0, "部分相似文本的相似度应该在0.5-1.0之间,实际值: " + similarity);}@Test@DisplayName("测试4: 空字符串处理")void testEmptyStrings() {// 两个都为空double similarity1 = PlagiarismChecker.calculateSimilarity("", "");assertEquals(1.0, similarity1, 0.01, "两个空字符串应该相似度为1.0");// 一个为空,一个不为空double similarity2 = PlagiarismChecker.calculateSimilarity("", "测试文本");assertEquals(0.0, similarity2, 0.01, "空字符串和非空字符串相似度应该为0.0");double similarity3 = PlagiarismChecker.calculateSimilarity("测试文本", "");assertEquals(0.0, similarity3, 0.01, "非空字符串和空字符串相似度应该为0.0");}@Test@DisplayName("测试5: null值处理")void testNullValues() {double similarity1 = PlagiarismChecker.calculateSimilarity(null, null);assertEquals(0.0, similarity1, 0.01, "两个null值应该返回0.0");double similarity2 = PlagiarismChecker.calculateSimilarity(null, "测试文本");assertEquals(0.0, similarity2, 0.01, "null和文本应该返回0.0");double similarity3 = PlagiarismChecker.calculateSimilarity("测试文本", null);assertEquals(0.0, similarity3, 0.01, "文本和null应该返回0.0");}@Test@DisplayName("测试6: 只包含空格的字符串")void testWhitespaceOnlyStrings() {String text1 = " ";String text2 = " \t ";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertEquals(1.0, similarity, 0.01, "只有空格的字符串应该被认为相同");String text3 = " 测试 ";String text4 = "测试";double similarity2 = PlagiarismChecker.calculateSimilarity(text3, text4);assertEquals(1.0, similarity2, 0.01, "去除空格后相同的文本应该相似度为1.0");}@Test@DisplayName("测试7: 单字符文本")void testSingleCharacterTexts() {double similarity1 = PlagiarismChecker.calculateSimilarity("a", "a");assertEquals(1.0, similarity1, 0.01, "相同单字符相似度应该为1.0");double similarity2 = PlagiarismChecker.calculateSimilarity("a", "b");assertEquals(0.0, similarity2, 0.01, "不同单字符相似度应该为0.0");}@Test@DisplayName("测试8: 包含特殊字符的文本")void testTextsWithSpecialCharacters() {String text1 = "Hello, World! @#$%^&*()";String text2 = "Hello, World! @#$%^&*()";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertEquals(1.0, similarity, 0.01, "包含特殊字符的相同文本相似度应该为1.0");String text3 = "测试:文本!?";String text4 = "测试:文档!?";double similarity2 = PlagiarismChecker.calculateSimilarity(text3, text4);assertTrue(similarity2 > 0.7, "包含特殊字符的部分相似文本相似度应该较高");}@Test@DisplayName("测试9: 中英文混合文本")void testMixedChineseEnglishTexts() {String text1 = "今天我要学习Java编程language";String text2 = "今天我要学习Python编程language";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertTrue(similarity > 0.7, "中英文混合的相似文本相似度应该较高,实际值: " + similarity);}@Test@DisplayName("测试10: 数字和文字混合")void testTextsWithNumbers() {String text1 = "版本1.0发布于2023年";String text2 = "版本2.0发布于2024年";double similarity = PlagiarismChecker.calculateSimilarity(text1, text2);assertTrue(similarity > 0.5, "包含数字的相似文本相似度应该合理,实际值: " + similarity);}@Test@DisplayName("测试11: 长文本性能测试")void testLongTextPerformance() {StringBuilder longText1 = new StringBuilder();StringBuilder longText2 = new StringBuilder();String baseText = "这是一个测试文本段落。";for (int i = 0; i < 100; i++) {longText1.append(baseText).append("第").append(i).append("段。");longText2.append(baseText).append("第").append(i).append("节。");}long startTime = System.currentTimeMillis();double similarity = PlagiarismChecker.calculateSimilarity(longText1.toString(), longText2.toString());long endTime = System.currentTimeMillis();assertTrue(similarity > 0.8, "长文本相似度计算应该正确,实际值: " + similarity);assertTrue(endTime - startTime < 5000, "长文本处理时间应该在合理范围内: " + (endTime - startTime) + "ms");}@Test@DisplayName("测试12: LCS算法基本功能")void testLCSAlgorithm() {int lcs1 = PlagiarismChecker.longestCommonSubsequence("ABCDGH", "AEDFHR");assertEquals(3, lcs1, "ABCDGH和AEDFHR的LCS长度应该为3(ADH)");int lcs2 = PlagiarismChecker.longestCommonSubsequence("AGGTAB", "GXTXAYB");assertEquals(4, lcs2, "AGGTAB和GXTXAYB的LCS长度应该为4(GTAB)");int lcs3 = PlagiarismChecker.longestCommonSubsequence("", "ABC");assertEquals(0, lcs3, "空字符串的LCS长度应该为0");int lcs4 = PlagiarismChecker.longestCommonSubsequence("ABC", "ABC");assertEquals(3, lcs4, "相同字符串的LCS长度应该等于字符串长度");}@Test@DisplayName("测试13: 文件读写功能")void testFileOperations() throws IOException {// 测试文件写入和读取Path testFile = tempDir.resolve("test_output.txt");String filePath = testFile.toString();// 测试写入结果PlagiarismChecker.writeResult(filePath, 0.856);// 验证写入的内容String content = Files.readString(testFile, StandardCharsets.UTF_8);assertEquals("85.60%", content, "写入的百分比格式应该正确");// 测试读取功能Path inputFile = tempDir.resolve("input.txt");Files.writeString(inputFile, "测试文本内容", StandardCharsets.UTF_8);String readContent = PlagiarismChecker.readFile(inputFile.toString());assertEquals("测试文本内容", readContent, "读取的文件内容应该正确");}@Test@DisplayName("测试14: 边界相似度值格式化")void testSimilarityFormatting() throws IOException {Path testFile = tempDir.resolve("format_test.txt");// 测试0%PlagiarismChecker.writeResult(testFile.toString(), 0.0);String content1 = Files.readString(testFile, StandardCharsets.UTF_8);assertEquals("0.00%", content1, "0%应该格式化为0.00%");// 测试100%PlagiarismChecker.writeResult(testFile.toString(), 1.0);String content2 = Files.readString(testFile, StandardCharsets.UTF_8);assertEquals("100.00%", content2, "100%应该格式化为100.00%");// 测试小数PlagiarismChecker.writeResult(testFile.toString(), 0.12345);String content3 = Files.readString(testFile, StandardCharsets.UTF_8);assertEquals("12.35%", content3, "小数应该正确舍入到两位");}@Test@DisplayName("测试15: 文件不存在异常处理")void testFileNotFoundException() {String nonExistentFile = tempDir.resolve("non_existent.txt").toString();assertThrows(IOException.class, () -> {PlagiarismChecker.readFile(nonExistentFile);}, "读取不存在的文件应该抛出IOException");}
}
代码运行命令
java -jar target/main.jar orig.txt orig_0.8_add.txt result.txt