1 前言
1.1 简介
在人工智能的浪潮中,自动语音识别(Automatic Speech Recognition, ASR)技术已成为连接人机交互、赋能各行各业的关键桥梁。从智能客服、会议纪要到实时字幕、车载助手,ASR的应用场景日益丰富,对识别的准确率、实时性和部署便捷性也提出了前所未有的高要求。在这样的背景下,FunASR应运而生。FunASR是由阿里巴巴达摩院语音实验室倾力打造,依托于ModelScope(魔搭)开源社区,面向开发者和企业的新一代工业级语音识别开源工具套件。作为一个基础语音识别工具包,它提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。FunASR还提供了便捷的脚本和教程,支持预训练好的模型的推理与微调。
1.2 环境准备与安装
1. 准备环境
这里使用Conda创建虚拟环境来安装FunASR及其依赖,这可以有效避免与系统中已有的Python库产生版本冲突,保证项目的纯净和可复现性。官网推荐如下安装环境:
python>=3.8 torch>=1.13 torchaudio
这里沿用之前安装Whisper时的python版本3.10,使用如下命令创建并激活python环境:
conda create -n funasr python=3.10 conda activate funasr
为了更好利用GPU这里使用显卡版本torch库,CUDA驱动如下:

根据环境信息去PyTorch官网获取安装命令,如图所示
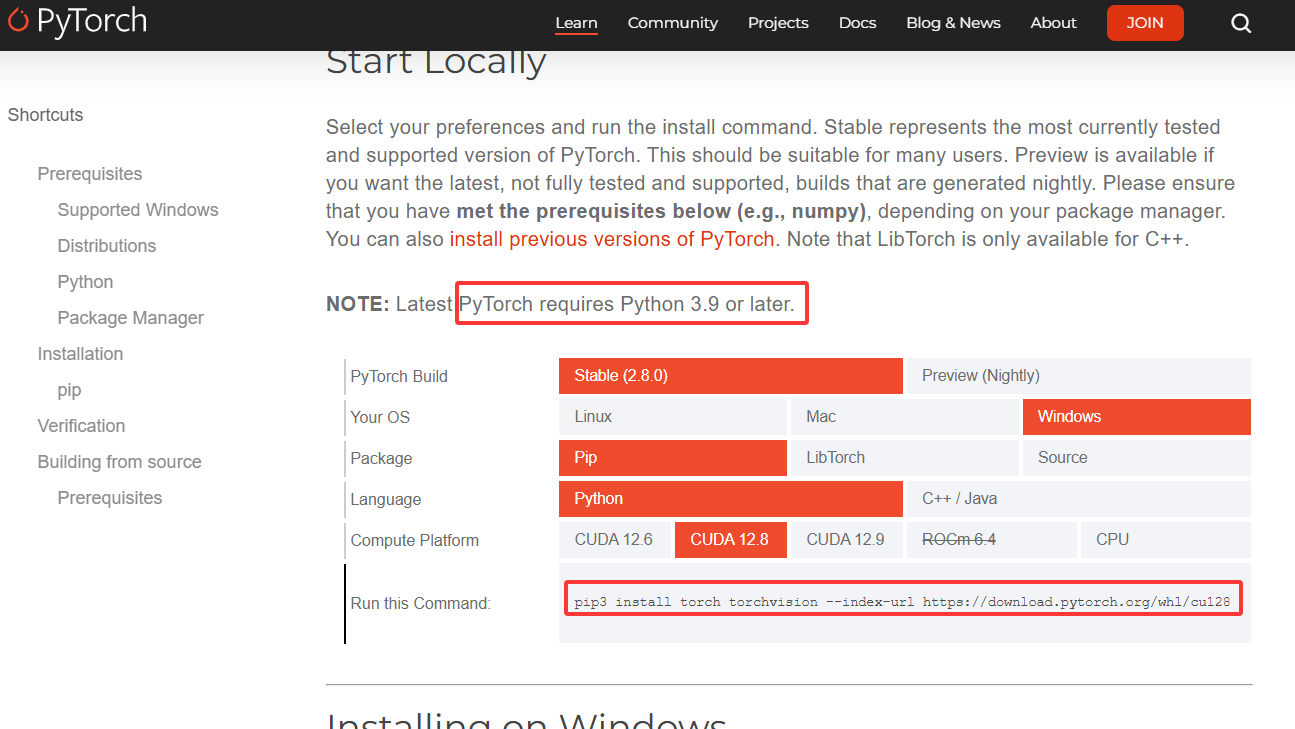
官网上也有提示最新版本PyTorch需要Python 3.9及以上版本,所以之前安装的python 3.10是满足要求的,开源项目最头疼的问题就是各种库版本依赖,所以进行安装时尤其要提前考虑各个库版本可能存在的冲突问题,这里在官网命令中增加torchaudio,一并进行安装:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
安装需要下载3个多G数据,需耐心等待,安装完成后各个库版本如下所示:

2. 安装FunASR
1)pip安装
pip3 install -U funasr
2)源码安装
git clone https://github.com/modelscope/FunASR.git && cd FunASR pip3 install -e ./
这里的-e参数代表“editable”(可编辑),它不会将代码复制到Python的site-packages目录,而是创建一个链接,这意味着对本地FunASR源码所做的任何修改,都会立刻在当前环境中生效,无需重新安装,这对于开发和调试极为便利。之后还可以按照官方建议安装以下两个库,以方便下载、上传和管理模型、数据集等资源。
pip3 install -U modelscope huggingface_hub
安装完成后,会在相应的conda环境目录下产生funasr相关可执行工具,在安装成功后运行funasr时,如果提示为找见funasr命令,可以尝试对当前funasr环境deactivate,然后再重新activate。
可以下载官网提供的示例音频,然后运行相应的命令检查funasr是否安装成功。

命令各部分解析如下:
funasr:是FunASR工具包的主程序入口,用于启动语音识别相关的推理流程。
++model=paraformer-zh:指定使用的语音识别模型为paraformer-zh(达摩院开发的中文 Paraformer 模型),负责将音频中的语音转换为文本。Paraformer是高效的非自回归模型,支持实时语音识别,中文识别准确率高。
++vad_model="fsmn-vad":指定语音活动检测模型为fsmn-vad,用于检测音频中“有语音”和“无语音”的片段,实现自动断句或去除静音,避免将静音部分误识别为文本,提升识别结果的连贯性。
++punc_model="ct-punc":指定标点预测模型为ct-punc,用于给识别出的文本自动添加标点符号(逗号、句号、问号等),解决语音识别默认输出无标点的问题,让文本更易读。
++input=asr_example_zh.wav:指定输入的音频文件路径为asr_example_zh.wav(需是中文语音的语音文件)。
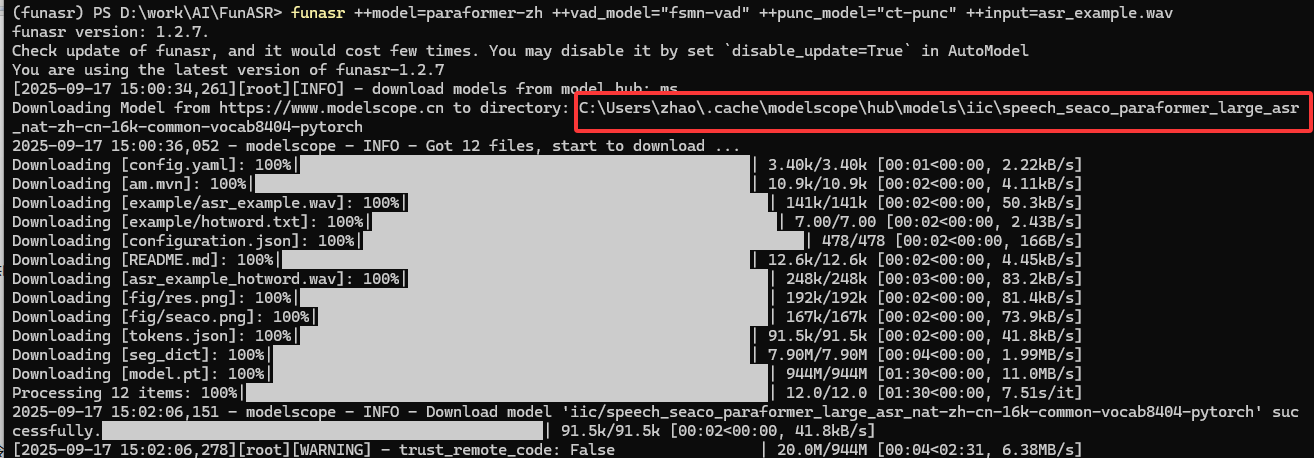
运行该命令后,FunASR 会对asr_example_zh.wav音频执行以下操作:用fsmn-vad检测音频中的有效语音片段(过滤静音),用paraformer-zh将有效语音转换为中文文本,用ct-punc为文本添加标点符号,最终输出带标点的完整中文识别结果(如“你好,请问今天天气怎么样?”)。官网给出了各个模型的详情介绍:

运行funasr时,如果缺少相应的模型,它会自动下载相应的模型文件到本地:
2 应用
2.1 Speech Recognition(语音识别)
1. 非流式
先看示例代码:
from funasr import AutoModel from funasr.utils.postprocess_utils import rich_transcription_postprocessmodel_dir = "iic/SenseVoiceSmall"model = AutoModel(model=model_dir,vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},device="cuda:0", )# en res = model.generate(input=f"{model.model_path}/example/en.mp3",cache={},language="auto", # "zn", "en", "yue", "ja", "ko", "nospeech"use_itn=True,batch_size_s=60,merge_vad=True, # merge_length_s=15, ) text = rich_transcription_postprocess(res[0]["text"]) print(text)
程序中首先导入了两个必要模块
AutoModel:FunASR 提供的自动加载模型的类
rich_transcription_postprocess:用于对识别结果进行后处理的工具函数
在进行模型加载时,model参数指定了要使用的模型,这里使用的是清华大学智能信息处理实验室开放的SenseVoiceSmall模型;vad_model指定使用的语音活动检测模型;vad_kwargs给出模型参数,这里给出的参数是最大单段时长参数,为30000毫秒;device指定使用第一块GPU进行计算,如果没有GPU可以改为“cpu”。
在进行语音识别model.generate时,input参数是输入的音频文件路径;cache是缓存字典,用于存储中间结果;language指定自动检测语言,这里也可以指定如“zn”(中文)、“en”(英文)等;use_itn用于是否使用逆文本标准化(将口语化表达转为书面化);batch_size_s指定批处理的音频长度(秒),进行音频处理时,模型通常会将长音频分割成多个片段批量处理,该参数定义了每个批次包含的音频时长上限;merge_vad是否合并VAD检测到的语音片段;merge_length_s合并片段的长度阈值(秒)。
之后调用rich_transcription_postprocess对识别结果进行后处理,使其格式更规范,最后打印处理后的识别文本。
2. 流式
流式识别的特点是可以边接收音频边处理,不需要等完整音频输入就能返回中间结果,非常适合实时对话、语音助手等场景。示例代码如下:
1 from funasr import AutoModel 2 3 chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms 4 encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention 5 decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention 6 7 model = AutoModel(model="paraformer-zh-streaming", disable_update=True) 8 9 import soundfile 10 import os 11 12 wav_file = os.path.join(model.model_path, "example/asr_example.wav") 13 speech, sample_rate = soundfile.read(wav_file) 14 chunk_stride = int(chunk_size[1] * sample_rate * 0.06) 15 16 cache = {} 17 total_chunk_num = int(len((speech)-1)/chunk_stride+1) 18 for i in range(total_chunk_num): 19 speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride] 20 is_final = i == total_chunk_num - 1 21 res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back) 22 print(res)
3~5行是流式识别的核心配置,用于控制音频分块方式和模型注意力范围,平衡实时性和识别准确性,chunk_size = [0, 10, 5]中的数值是以 60ms 为单位的时间片段参数,0表示0ms的前瞻,10表示10*60ms=600ms当前块,5表示5*60ms=300ms历史回溯;encoder_chunk_look_back表示编码器自注意机制需要回溯的块数量;decoder_chunk_look_back表示解码器交叉注意力机制需要回溯的编码器块数量。之后第7行加载“paraformer-zh-streaming”模型,该模型专门用于实时语音识别场景。接下来第12行获取示例音频文件路径,第13行读取音频文件,返回音频数据(speech)和采样率(sample_rate),14行对chunk_stride(块步长)进行复制,它是控制音频分块滑动距离的关键参数,直接影响流式处理的实时性和连续性,表示相邻两个音频块之间的重叠或间隔距离(以采样点数为单位),以语音识别模型通常使用16000Hz采样率(即每秒采集 16000 个音频样本)为例,60ms对应的采样点数 = 16000 × 0.06s = 960个样本,最终chunk_stride = 10 × 960 = 9600 个采样点,对应时间长度为 600ms,与current块的时间长度相同,这意味着相邻两个音频块是连续且无重叠的,这种设置的好处是处理效率高(无重复计算),适合对实时性要求高的场景,反之,如果chunk_stride小于current 块长度(即块之间有重叠),可以利用更多上下文信息提升准确性,但会增加计算量(重复处理重叠部分),例如,如果chunk_stride = 5 × 60ms = 300ms(4800 采样点),假设处理一段 1800ms 的音频,分块结果如下:
| 块序号 | 时间范围(ms) | 采样点范围 | 与前一块的重叠区域(ms) |
|---|---|---|---|
| 第 1 块 | 0 ~ 600 | 0 ~ 9600 | 无(第一块) |
| 第 2 块 | 300 ~ 900 | 4800 ~ 14400 | 300ms(300~600) |
| 第 3 块 | 600 ~ 1200 | 9600 ~ 19200 | 300ms(600~900) |
| 第 4 块 | 900 ~ 1500 | 14400 ~ 24000 | 300ms(900~1200) |
| 第 5 块 | 1200 ~ 1800 | 19200 ~ 28800 | 300ms(1200~1500) |
每个块与前一块重叠300ms,这部分音频会被重复处理,例如第 2 块不仅包含新的 300~900ms 音频,还包含第 1 块中 300~600ms 的内容。另外需要说明的是,chunk_size中的回溯参数(第三个值,如 [0, 10, 5] 中的 5)和chunk_stride看似都与 “历史信息利用” 相关,但它们解决的是流式语音识别中两个完全不同的问题,作用层面和目标也截然不同。具体来说:
chunk_size 的回溯参数(right):是模型逻辑层面的上下文参考,用于告诉模型 “在处理当前块时,需要从历史计算结果中读取多少信息”(如注意力机制需要回溯的历史编码结果)。它不改变音频的物理分块方式,仅影响模型内部的计算逻辑。
chunk_stride:是音频物理层面的分块滑动距离,用于决定 “下一个音频块从哪里开始截取”。它直接改变音频在时间轴上的分块方式(是否重叠、重叠多少),是控制 “原始音频如何被切割成连续块” 的物理参数。
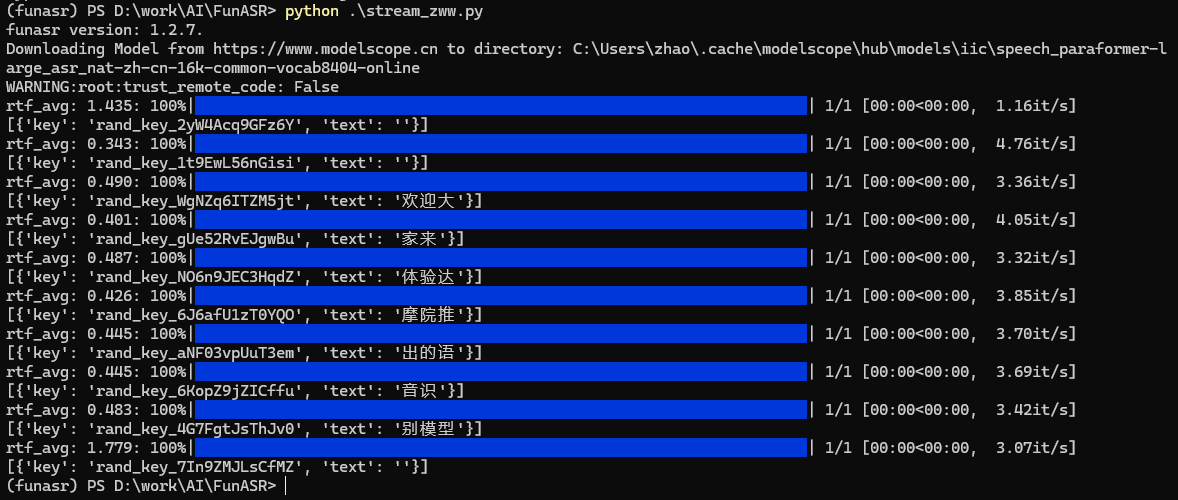
接着分析源码,17行根据chunk_stride计算整个音频文件可以分成total_chunk_num个块;19~22行根据chunk个数依次对取每个块儿数据,并调用模型进行语音识别,并输出相应结果,整个程序运行过程如下:
2.2 Voice Activity Detection(VAD,语音活动检测)
1. 非流式
以下是github上示例代码:
from funasr import AutoModelmodel = AutoModel(model="fsmn-vad", disable_update=True) wav_file = f"{model.model_path}/example/vad_example.wav" res = model.generate(input=wav_file) print(res)
其运行结果如下:

输出的核心部分是value数组,它包含了多个子数组,每个子数组代表一个检测到的语音片段,格式为[开始时间,结束时间],时间单位是毫秒,例如[70, 2340]表示从第70毫秒到第2340毫秒是一段语音,[2620, 6200]表示接下来从2620毫秒到6200毫秒又是一段语音,两个语音片段之间的时间(如2340~2620毫秒)是静音或非语音区域。这些结果可以用于后续处理,如:截取音频中的有效语音片段,计算语音总时长,分析说话停顿模式等。
2. 流式
首先给出源码:
from funasr import AutoModelchunk_size = 200 # ms model = AutoModel(model="fsmn-vad", disable_update=True)import soundfilewav_file = f"{model.model_path}/example/vad_example.wav" speech, sample_rate = soundfile.read(wav_file) chunk_stride = int(chunk_size * sample_rate / 1000)cache = {} total_chunk_num = int(len((speech)-1)/chunk_stride+1) for i in range(total_chunk_num):speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]is_final = i == total_chunk_num - 1res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)if len(res[0]["value"]):print(res)
程序运行结果如下:
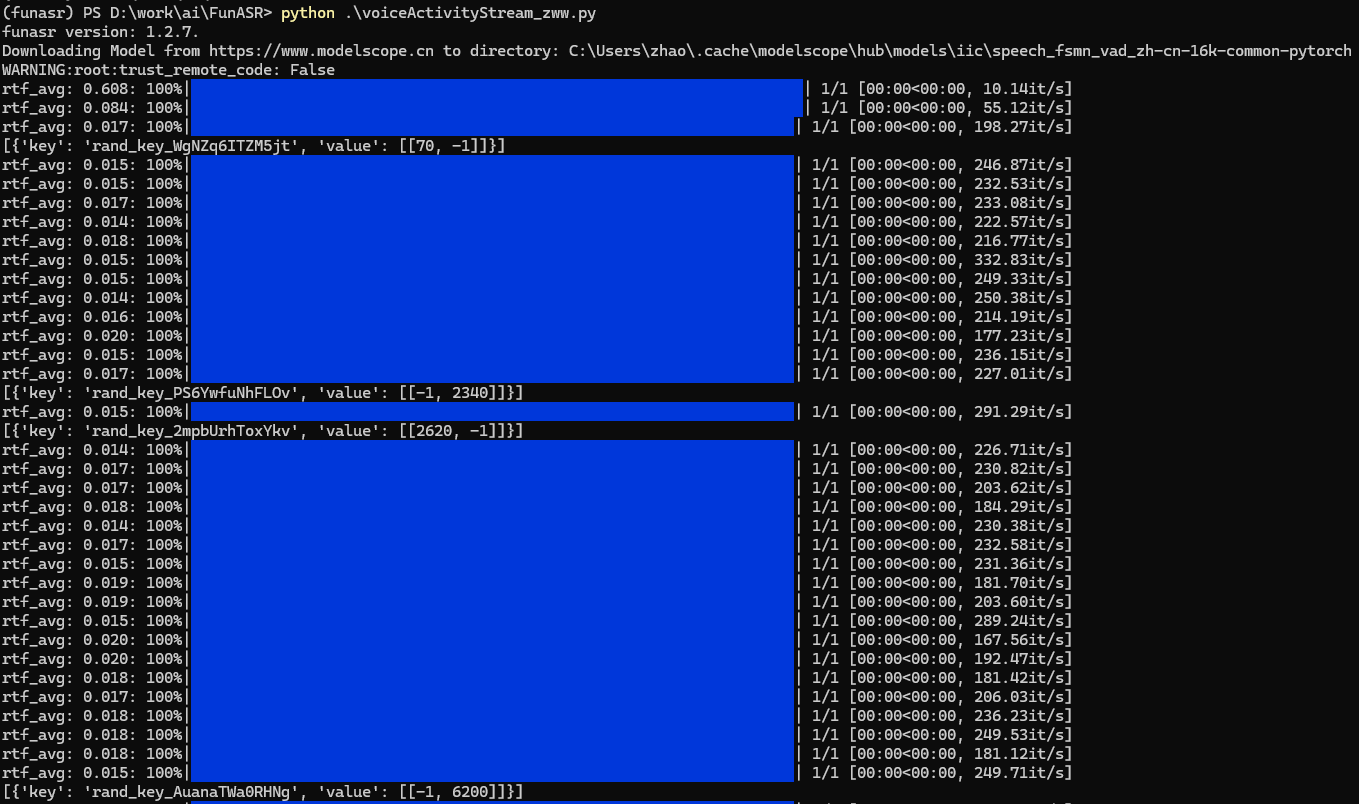
流式VAD是分块处理音频(每次处理一小段),并逐步确定 “语音的起始 / 结束时间”,由于是 “流式”,模型无法一次性看到完整音频,所以会先 “暂定” 边界,后续块处理时再 “修正”。结果里的-1表示:当前块处理后,“起始”或“结束”时间点“暂未确定”,例如图中[[70, -1]],模型检测到“70ms可能是语音的起始点”,但结束点暂未确定(因为后续块还没有处理到“结束”的位置),[[-1, 2340]],模型检测到“2340ms可能是语音的结束点”,但起始点暂未确定(因为前面的块没有处理到“起始”位置)。简单来说,这种包含-1的结果,是流式处理“逐步探索、修正边界”的中间状态,最终所有-1要被替换成确定的时间,得到完整的“语音起始-结束”区间。
2.3 标点恢复(Punctuation Restoration)
标点恢复,又称标点补全或标点插入,是自然语言处理(NLP)领域的一项基础任务。其核心目标是为缺失标点或标点错误的文本,自动补充或修正符合语言习惯的标点符号(如逗号、句号、问号、感叹号、分号等),让文本结构更清晰、语义更明确,更贴近人类自然的语言表达。
目前标点恢复的技术路线主要分为 “规则驱动” 和 “数据驱动” 两类,各有适用场景:
1. 基于规则的方法(Rule-Based)
通过人工定义 “标点使用规则” 来判断标点位置,例如:
优点:逻辑透明、无需训练数据,适合简单场景(如固定格式的文本);
缺点:适应性差,无法覆盖口语化、个性化文本,规则维护成本高。
2. 基于统计与神经网络的方法(Data-Driven)
通过 “大规模带标点语料” 训练模型,让模型学习标点使用的规律,属于目前的主流方案。常见技术路径包括:
优点:泛化能力强,能适应口语、书面语、专业文本等多种场景,标点预测准确率高;
缺点:需要大规模高质量带标点语料,模型训练和推理需要一定的计算资源。
以下给出示例程序:
from funasr import AutoModelmodel = AutoModel(model="ct-punc") res = model.generate(input="那今天的会就到这里吧 happy new year 明年见") print(res)
代码输出结果如下:

从结果可见已在输入文本中添加了合适的标点符号。
2.4 Timestamp Prediction(时间戳预测)
时间戳预测是自然语言处理、语音处理等领域的一项任务,旨在为文本、语音等内容中的特定元素(如单词、短语、语音片段等)预测出对应的时间戳信息。
典型应用场景
1)语音与文本同步:在语音转文字(ASR)后,需要知道每个文字或短语在语音中对应的起始和结束时间,方便后续的字幕生成、语音内容定位等。例如,将一段演讲的语音转换为文字后,为每一句话标注出在音频中从第几秒开始,到第几秒结束。
2)视频内容分析:对于包含语音的视频,预测文本内容(如台词、解说词)在视频时间轴上的对应时间,有助于视频内容的检索、片段提取等。比如,要找到视频中某个人物说话的片段,通过时间戳可以快速定位。
3)多模态内容处理:在结合文本、语音、图像等多种模态的应用中,时间戳预测能帮助将不同模态的内容在时间维度上进行对齐。例如,在一个带有语音解说的动画视频中,让动画画面的变化与解说词的时间相匹配。
示例程序:
from funasr import AutoModelmodel = AutoModel(model="fa-zh", disable_update=True) wav_file = f"{model.model_path}/example/asr_example.wav" text_file = f"{model.model_path}/example/text.txt" res = model.generate(input=(wav_file, text_file), data_type=("sound", "text")) print(res)
运行结果如下:

可以看出,结果中已经给出了每个字的时间戳信息。
2.5 Speech Emotion Recognition(SER 语音情感识别)
语音情感识别是语音信号处理与情感计算交叉领域的核心任务,旨在通过分析人类语音中的声学特征(如音调、语速、音量)和语言内容,自动识别出说话人所表达的情感状态(如开心、愤怒、悲伤、中性等),实现 “听懂语音背后的情绪”。语音情感识别的核心是让机器突破 “仅理解语音文字内容” 的局限,进一步感知人类的情感意图,其应用覆盖人机交互、服务、安防等多个领域。语音情感识别的流程本质是 “特征提取→模型分类”,核心是从语音中挖掘出能反映情感的关键信息,再通过模型学习情感与特征的关联。
1. 关键特征提取
情感会直接影响人说话的 “声学特性”,这些特性是 SER 的核心分析对象,主要分为三类:
| 特征类别 | 具体指标 | 情感关联示例 |
|---|---|---|
| 韵律特征 | 基音频率(F0,音调高低)、语速(每秒音节数)、音量(响度)、停顿时长 | - 愤怒:F0 升高、音量增大、语速变快;
|
| 频谱特征 | 频谱重心(反映声音的 “明亮度”)、频谱带宽、梅尔频率倒谱系数(MFCC,语音核心特征) | - 开心:频谱重心偏高(声音更明亮);
|
| 语音质量特征 | 抖动(基音频率的微小波动)、 shimmer(音量的微小波动) | - 紧张 / 焦虑:抖动、shimmer 值增大(声音更不稳定);
|
此外,若结合文本内容(如通过 ASR 将语音转文字),还能补充 “语义情感特征”(如 “讨厌”“难过” 等词汇),进一步提升识别准确率(例如 “我赢了!” 的文本 + 欢快的语音,更易判断为 “开心”)。
2. 主流模型与技术路线
SER 的模型发展从 “传统机器学习” 过渡到 “深度学习”,目前后者因更强的特征学习能力成为主流:
1)传统机器学习方法(早期方案)
基于 “人工提取特征 + 浅层分类器”,核心是依赖领域知识设计特征,再用分类器学习映射关系:
2)深度学习方法(当前主流)
通过神经网络自动学习语音中的情感特征,无需人工设计,能捕捉更复杂的情感关联:
3. 核心挑战
尽管 SER 技术已取得显著进展,但仍面临以下关键问题:
情感的 “主观性” 与 “多样性”:同一语音可能被不同人标注为不同情感(如 “语气严肃” 可能被标为 “中性” 或 “不满”);不同文化、语言的情感表达习惯差异大(如西方 “开心” 的语音更夸张,东方更含蓄)。
“情境干扰” 与 “情感混淆”:背景噪音(如公共场所的杂音)会掩盖情感特征;相似情感(如 “愤怒” 与 “烦躁”、“悲伤” 与 “疲惫”)的语音特征差异小,易误判。
“个体差异”:不同人的基础声学特征不同(如有人天生音调高、有人天生音调低),同一情感在不同人身上的语音表现可能不同(如 A 开心时语速变快,B 开心时音调升高)。
以下是FunASR对应的示例程序:
from funasr import AutoModelmodel = AutoModel(model="emotion2vec_plus_large", disable_update=True) wav_file = f"{model.model_path}/example/test.wav" res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False) print(res)
运行结果如下:

可见最终情绪识别后,判断该音频表达的情感为 “生气(angry)”,且置信度很高(得分 1.0),而属于其他情感类别的可能性极小。
3 综合实例
在本节使用生产者-消费者模型基于多线程给出一个实时录音并识别的程序,生产者线程负责从麦克风读取音频数据并放入队列,消费者线程从队列中取出音频数据进行识别处理,完整源码如下:
import pyaudio import numpy as np import time import queue import threading import torch from funasr import AutoModel# 音频参数(必须与模型要求一致) FORMAT = pyaudio.paInt16 CHANNELS = 1 RATE = 16000 # 16kHz是多数语音模型的标准采样率 CHUNK = 1600 # 每次读取100ms音频(16000*0.1=1600) RECORD_DURATION = 3 #5 # 每5秒处理一次(可调整) AUDIO_QUEUE_MAX_SIZE = 10 # 音频队列最大长度def producer(audio_queue):"""生产者线程:从麦克风读取音频数据并放入队列"""p = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("生产者线程:开始读取音频...")audio_buffer = []try:while True:# 读取音频数据data = stream.read(CHUNK, exception_on_overflow=False)audio_data = np.frombuffer(data, dtype=np.int16)audio_buffer.append(audio_data)# 每积累一定时长的音频就放入队列if len(audio_buffer) * CHUNK / RATE >= RECORD_DURATION:full_audio = np.concatenate(audio_buffer)audio_float32 = full_audio.astype(np.float32) / 32768.0 # 归一化到[-1, 1] audio_queue.put(audio_float32)audio_buffer = []except Exception as e:print(f"生产者线程异常: {e}")finally:stream.stop_stream()stream.close()p.terminate()def consumer(audio_queue, model):"""消费者线程:从队列取出音频数据进行识别"""print("消费者线程:准备进行识别...")while True:try:if not audio_queue.empty():audio_float32 = audio_queue.get()print(f"\n--- 处理 {RECORD_DURATION} 秒音频 ---")# 调试:检查音频数据是否有效print(f"音频数据范围: {audio_float32.min()} ~ {audio_float32.max()}")if audio_float32.max() < 0.01: # 阈值可调整print("警告:未检测到有效音频输入(可能麦克风未工作)")# 进行识别start_time = time.time()res = model.generate(input=audio_float32)end_time = time.time()# 输出结果if res and len(res) > 0:print(f"识别结果: {res[0]['text']}")else:print("未识别到内容")print(f"处理耗时: {end_time - start_time:.2f}秒")audio_queue.task_done()else:time.sleep(0.1) # 队列为空时,短暂休眠except Exception as e:print(f"消费者线程异常: {e}")def main():print("初始化模型...")# 尝试使用基础模型,确保模型能正常工作model = AutoModel(model="paraformer-zh", # 非流式基础模型,稳定性更好vad_model="fsmn-vad",punc_model="ct-punc",device="cuda:0" if torch.cuda.is_available() else "cpu",disable_update=True)print("模型初始化完成")# 创建音频队列audio_queue = queue.Queue(maxsize=AUDIO_QUEUE_MAX_SIZE)# 创建并启动生产者线程producer_thread = threading.Thread(target=producer, args=(audio_queue,), daemon=True)producer_thread.start()# 创建并启动消费者线程consumer_thread = threading.Thread(target=consumer, args=(audio_queue, model), daemon=True)consumer_thread.start()try:print("开始录音(按Ctrl+C停止)...")# 主线程保持运行while True:time.sleep(1)except KeyboardInterrupt:print("\n用户终止程序")finally:print("程序结束")if __name__ == "__main__":# 确保依赖正确安装# pip install pyaudio numpy funasr modelscope torchmain()
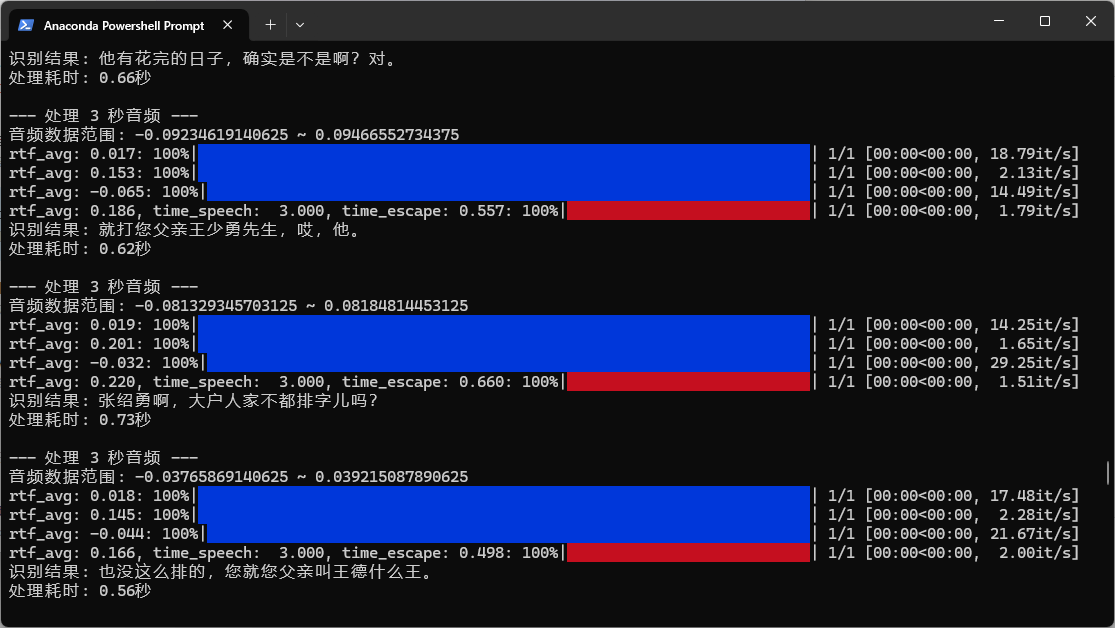
由于代码流程很清晰这里不再进行详细解析,运行效果如下图:
参考:
1. https://github.com/modelscope/FunASR/blob/main/README_zh.md
2. https://blog.csdn.net/qq_34717531/article/details/141159210