目录
- Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
- TL;DR
- Method
- Naive Dynamic Resolution
- Multimodal Rotary Position Embedding (M-RoPE)
- Unified Image and Video Understanding
- Training
- Experiment
- Q&A
- 总结与思考
- 相关链接
Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
link
时间:24.09
单位:Qween
作者:Peng Wang
相关领域:多模态理解
被引次数:1527
项目主页:
https://github.com/QwenLM/Qwen2.5-VL
TL;DR
Qween2-VL相对于上一代:
- 支持原生动态图片分辨率输入
- 使用M-RoPE更高效将位置信息融合至多模态输入中
- 构建统一架构将图像、视频融入模型中
- 多尺寸模型:2B、8B、72B
Method
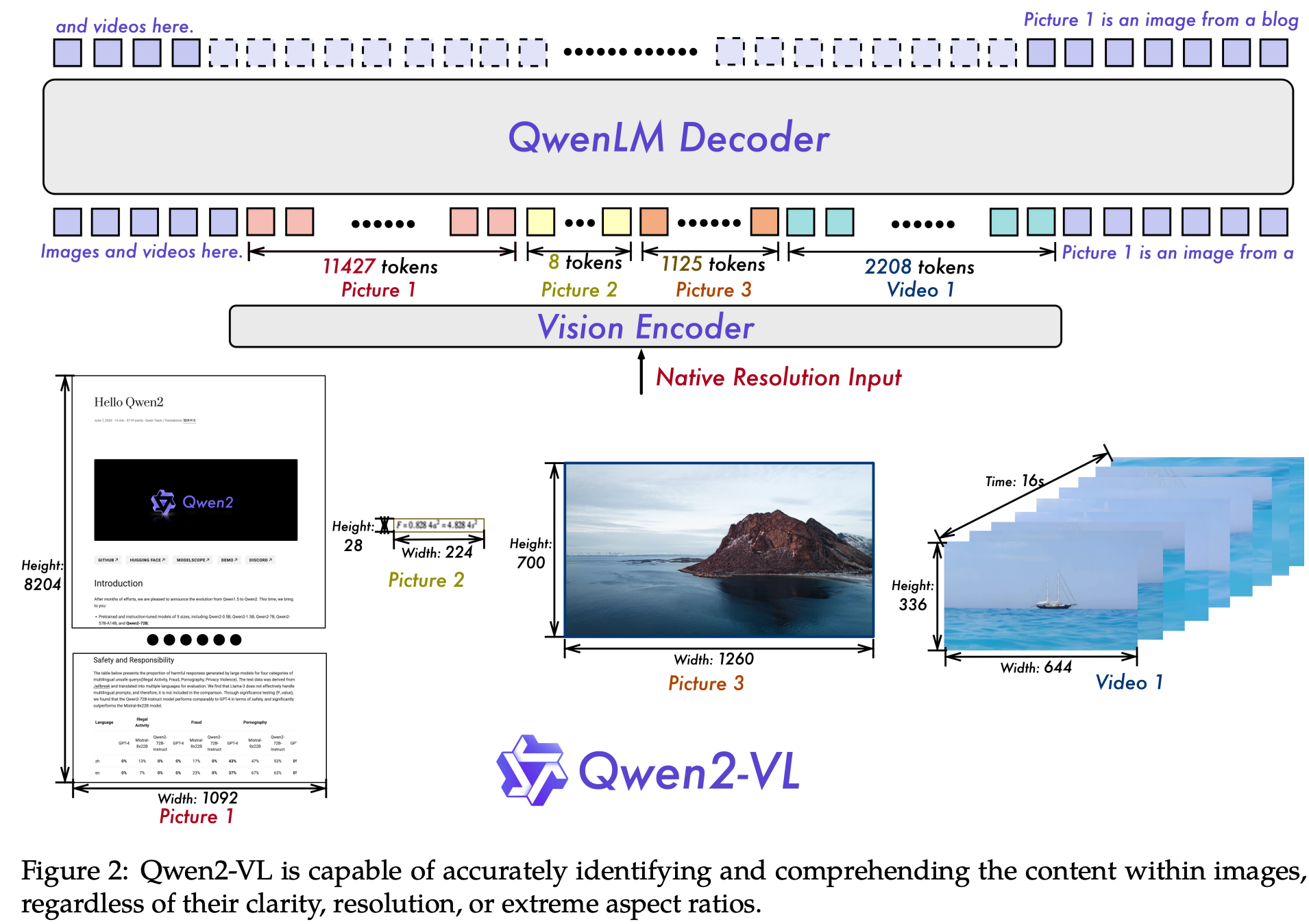
Naive Dynamic Resolution
固定patch_size的分辨率,根据输入图像动态分辨率,动态计算出token sequence,再增加vision_start与vision_end的两个特殊token,例如,分辨率为224x224的图像对应66 tokens,计算方式如下:
\(224 / 14 = 16\)
\(16 / 2\) x \(16 / 2 + 2 = 66\)
Multimodal Rotary Position Embedding (M-RoPE)
将位置编码按照(temporal, height, width)三种ID来表示,若是text模态则三者一样,若是图像模态 temporal ID保持固定,height与width随图像不同位置变化,若是视频模态,则不同帧temporal ID也随之变化。

Unified Image and Video Understanding
- 采样:以2FPS的速率从视频中抽取帧序列。
- 统一表示:将每张静态图像视为一个只有2帧的“微视频”,这两帧是完全相同的图像。
- 3D建模:使用轻量级3D卷积ViT处理立方体,生成融合了时空信息的视觉token序列。
- 令牌长度限制:将每个视频输入的总token数上限设置为 16,384。
Training
与Qween的三阶段训练策略一致,只不过使用的数据量不一样:
- Vision Encoder训练
- 全参数微调
- 指令微调
Experiment
能力展示
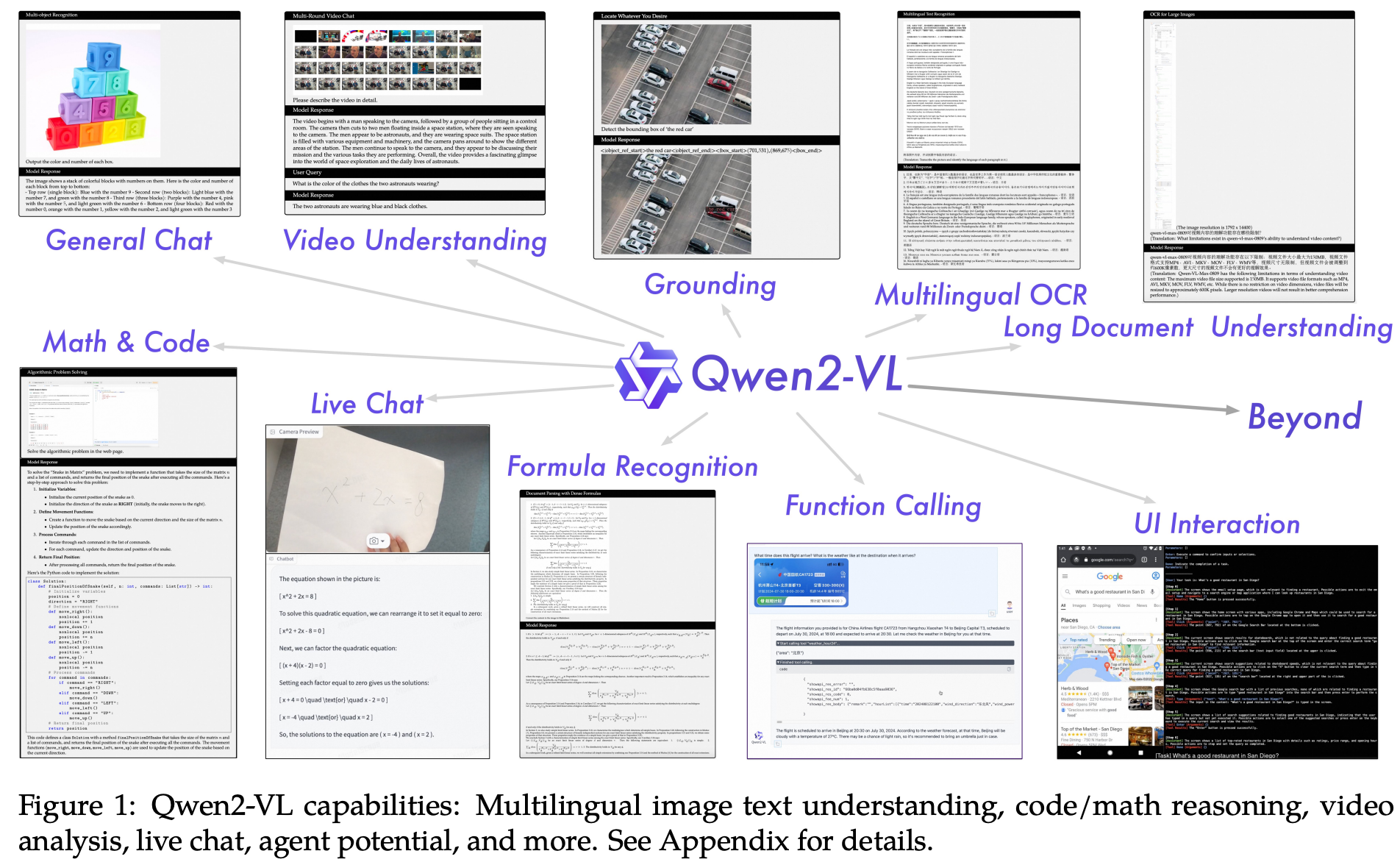
全家桶
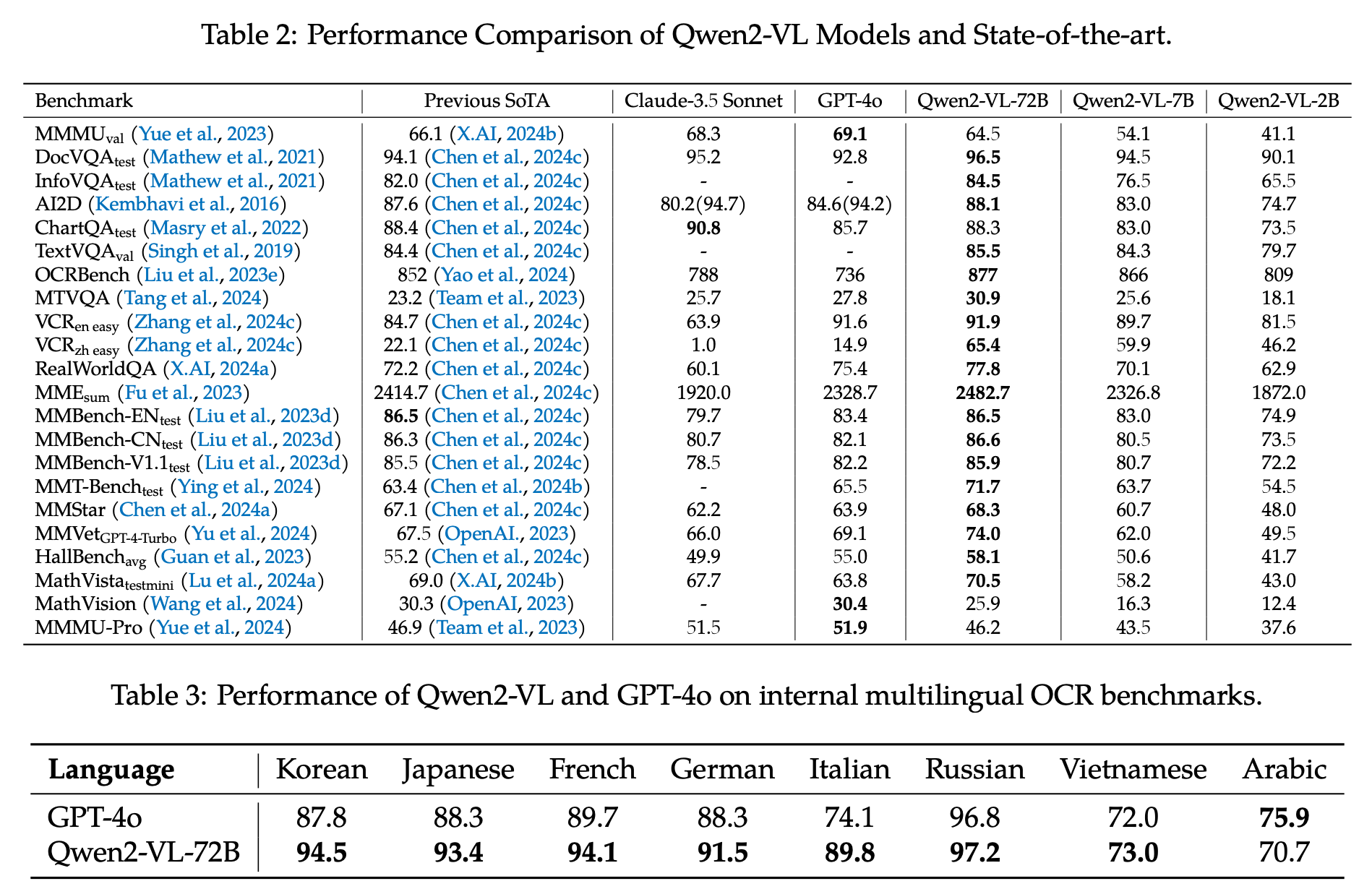
与SOTA对比
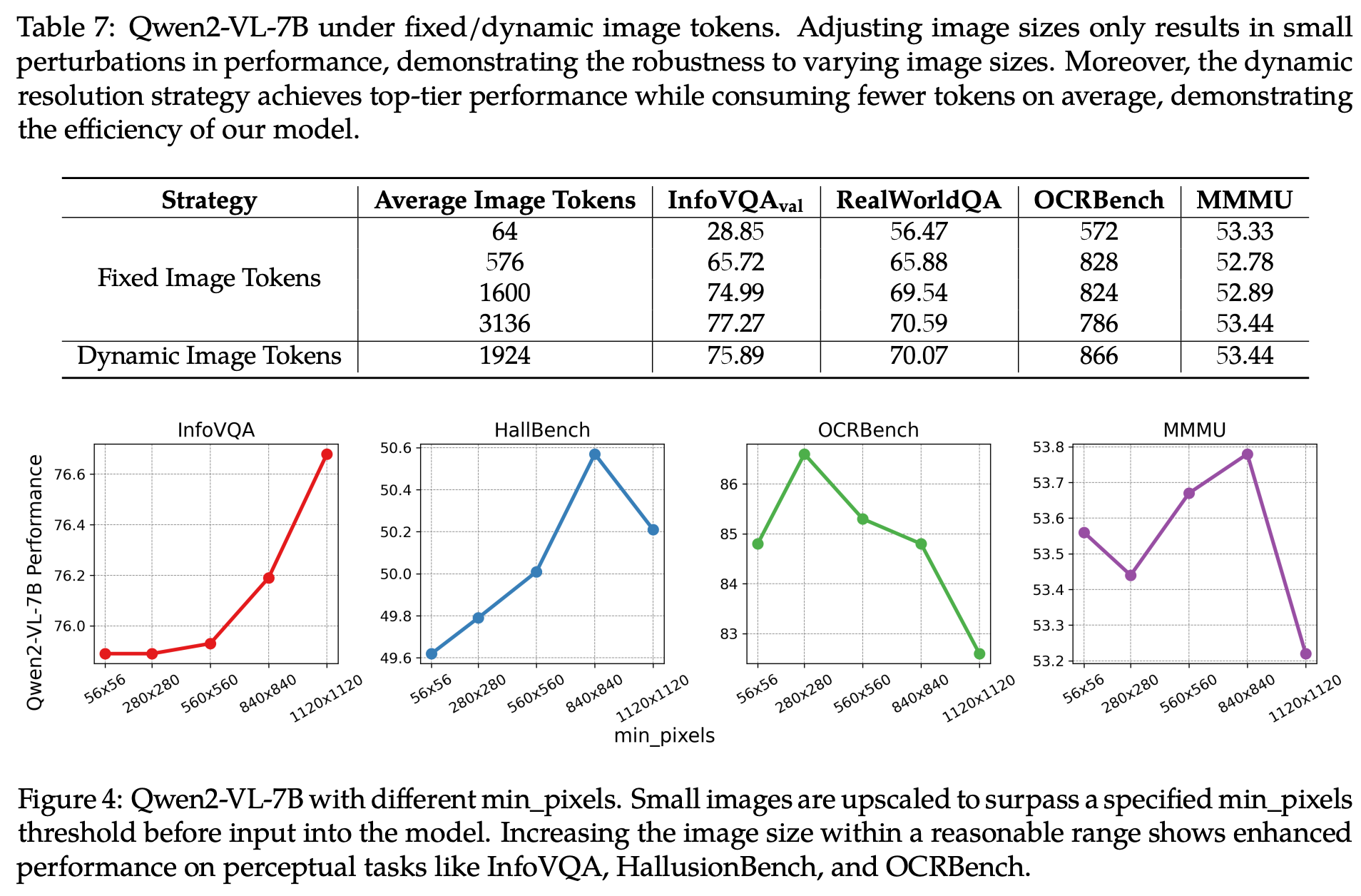
分辨率
归功于“Naive Dynamic Resolution”训练,Qween2-VL受分辨率影响不大
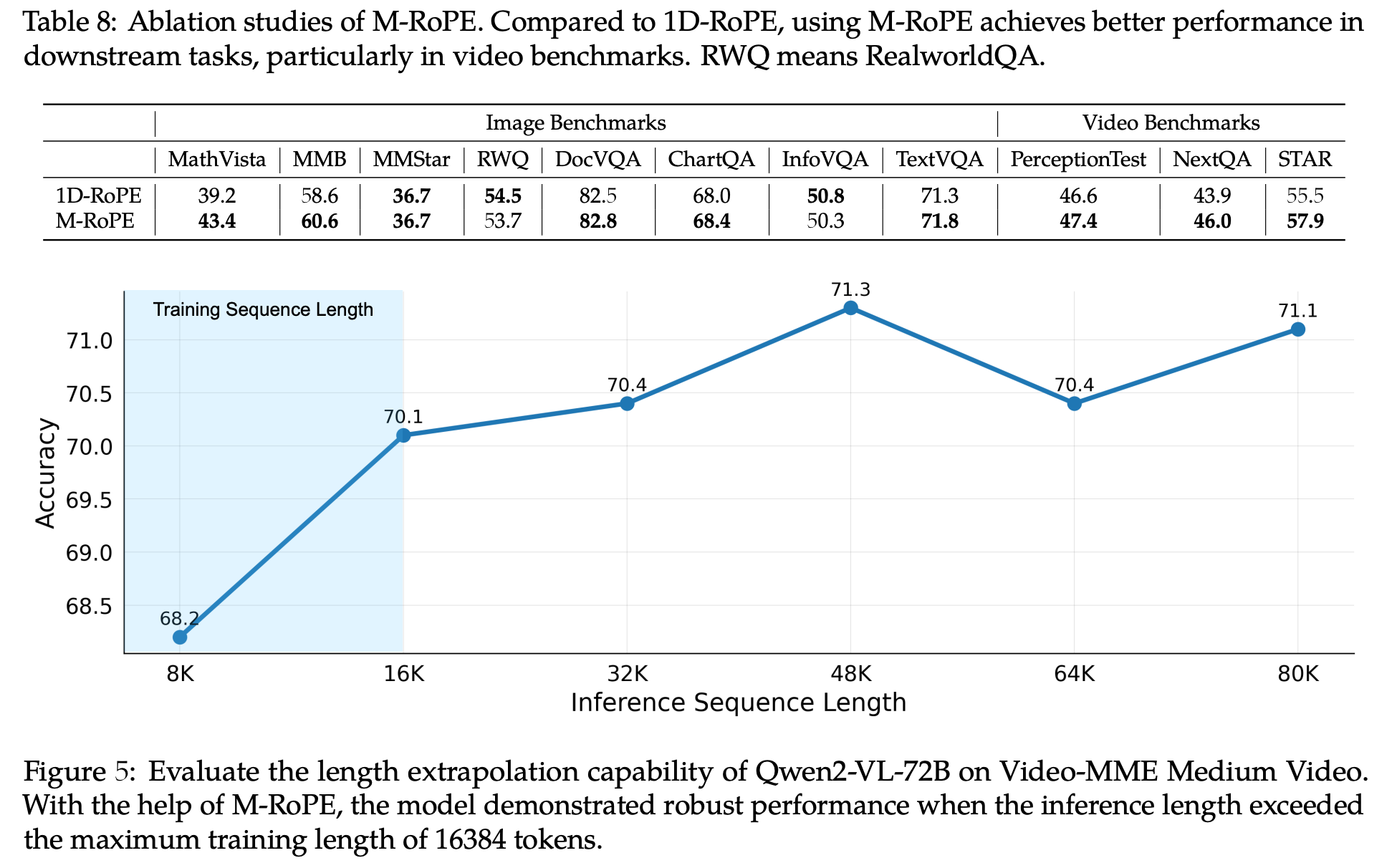
M-RoPE
优势:
- 对于长度外推有好处
- Image/Video Benchmarks上比1D-RoPE更好
![image]()
Q&A
Q:相对于上一代QweenVL有多大提升?
未对比
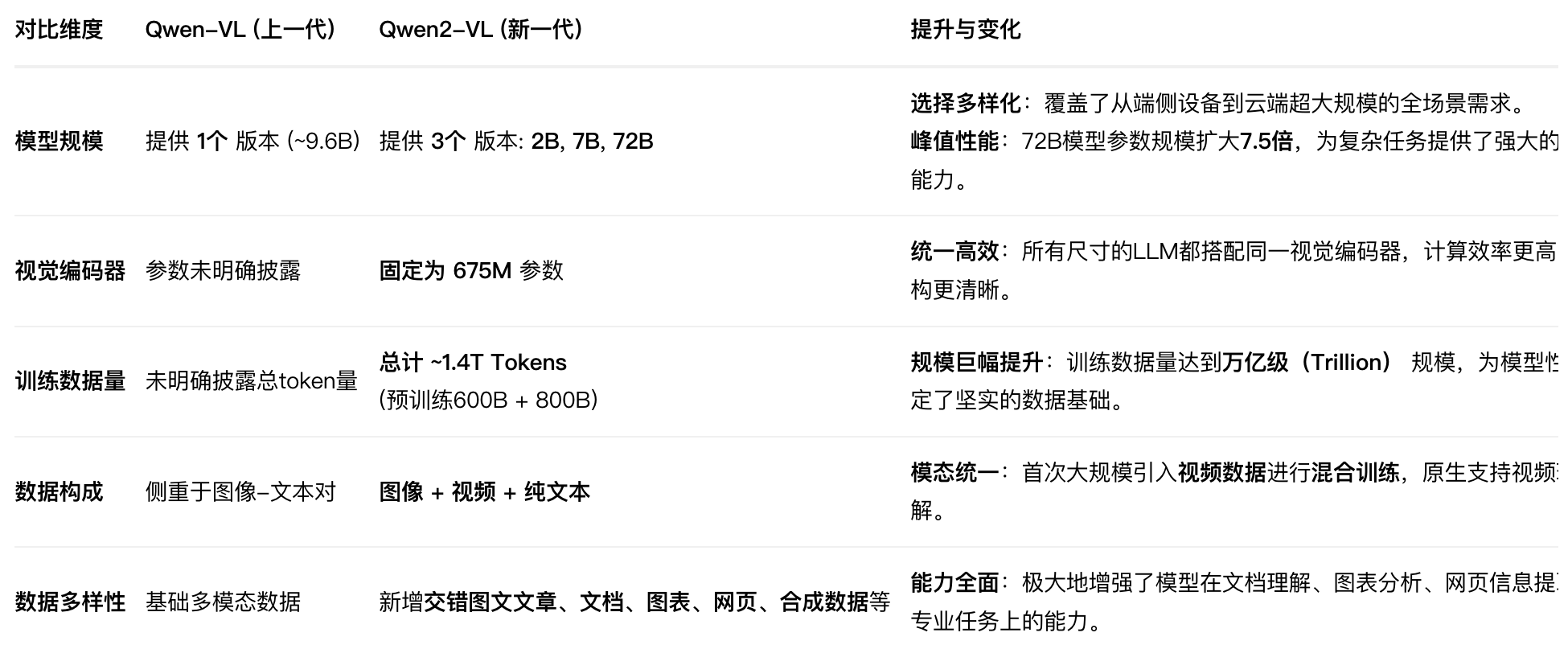
Q:相对于上一代模型尺寸、训练数据量变化?
Q:为什么M-RoPE会对长度外推有好处?
长度外推是指模型在推理时处理比训练时见过的更长的序列的能力。这是一个极具挑战性的任务,因为模型必须理解训练数据中未曾出现过的位置关系。
- 维度解耦:将不同模态的位置信息分离到时间、高、宽三个独立维度,避免了单一序列中外推时不同模态位置信息的冲突与混淆,这是其最核心的贡献。
- 相对位置感知:继承了RoPE的优良特性,使模型专注于学习相对位置关系而非绝对位置,从而能更好地泛化到更长的序列。
- 数值平滑稳定:基于旋转正弦余弦函数的编码方式确保了外推时数值计算的稳定性和可预测性,避免了数值异常。
总结与思考
无
相关链接
https://zhuanlan.zhihu.com/p/1944799681357017732