作者:桂楚
随着 LLM 服务广泛部署,服务的可用性和流量治理面临新的可靠性要求。由于 LLM 服务参数量级限制,其服务部署和重启时间较长,如果服务因为过载而故障,则重启时间达到分钟级,对服务可用性影响极大。
阿里云 AI 网关提供了多来源 LLM 服务的代理功能,不仅可以通过简单易用的配置对 LLM 服务进行代理,同时提供了丰富的 LLM 服务入口流量治理功能,提高 LLM 服务的可观测性和可用性。对于自部署的 LLM 服务,传统网关的检测和过载保护机制往往滞后,阿里云 AI 网关提供了一系列如被动健康检测、首包超时和 fallback 等高可用机制,通过合理配置,能够实现对LLM服务的过载状态实时检测和及时保护。
问题场景
用户流量具有突发性和不确定性特点,若用户流量激增产生流量尖峰,会对 LLM 服务产生的可用性造成较大影响,例如,LLM 服务同时处理大量请求造成生成响应时间过长,造成用户体验降低,甚至因为 LLM 服务显存受限,在同时处理大量请求时,会因为显存被打满而挂掉。
如下图所示,这里模型类别选择 DeepSeek-R1-Distill-Qwen-7B,资源类型选择 ml.gu7i.c8m30.1-gu30,具有 24G 显存。
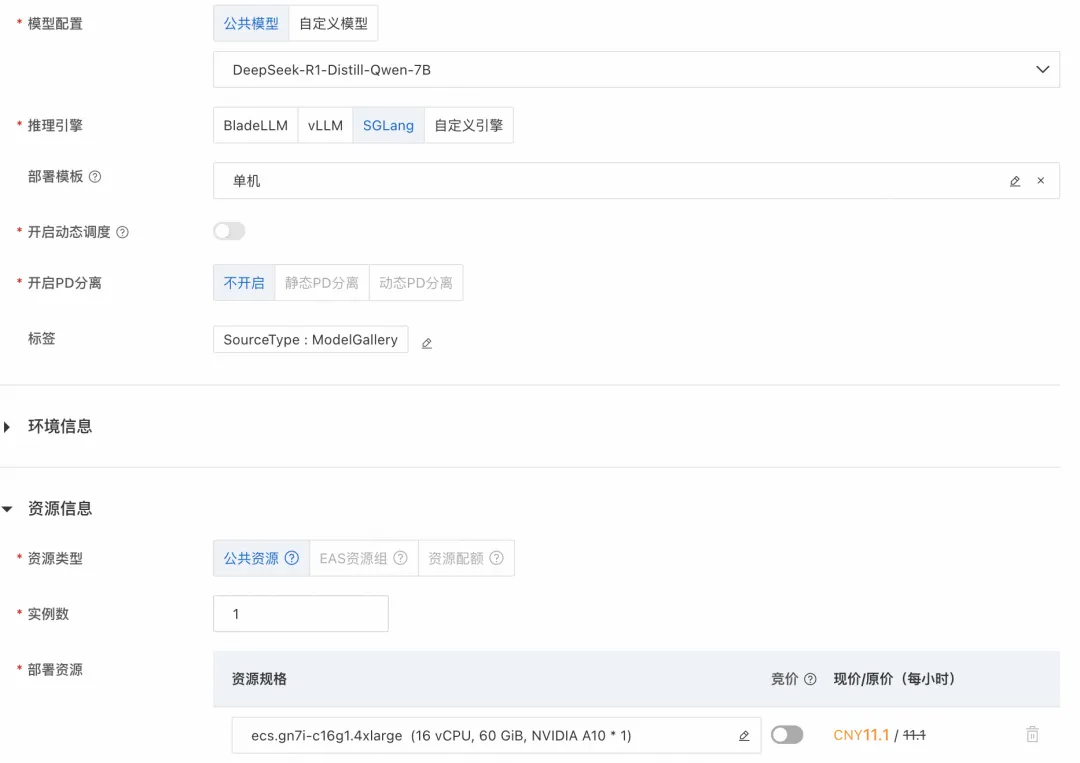
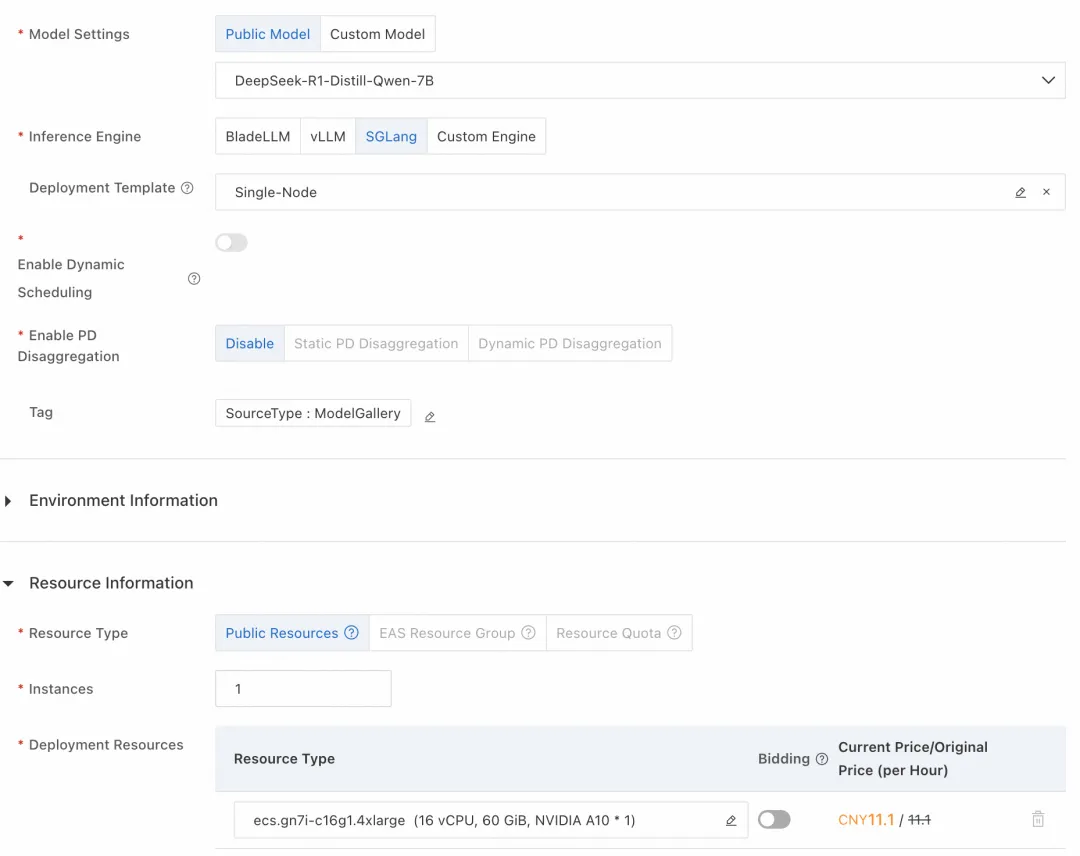
图 1

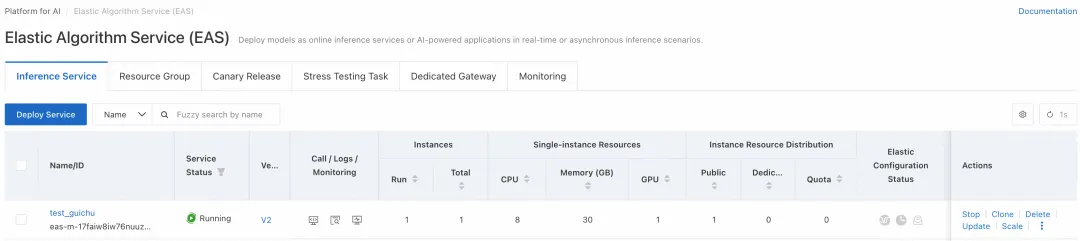
图 2
查看部署的 LLM 服务 GPU 占用率,已经达到 99%。
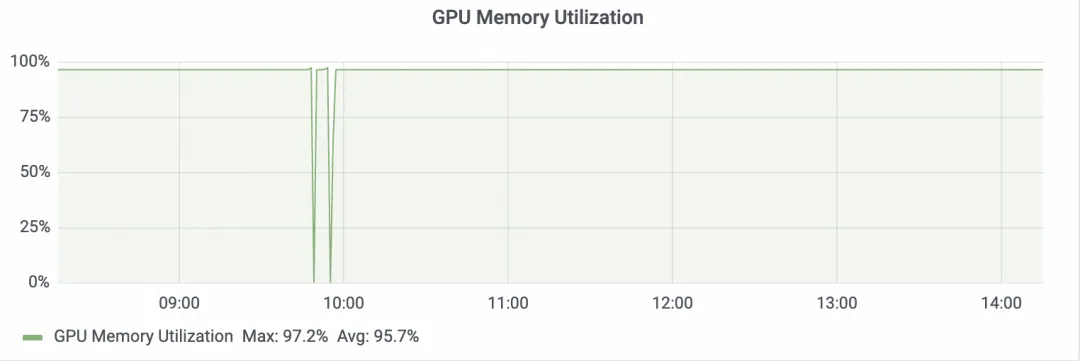
图 3
用户请求激增时,可以看到首包 RT 随者请求数而增加,说明 LLM 服务的负载压力也在逐渐增加。

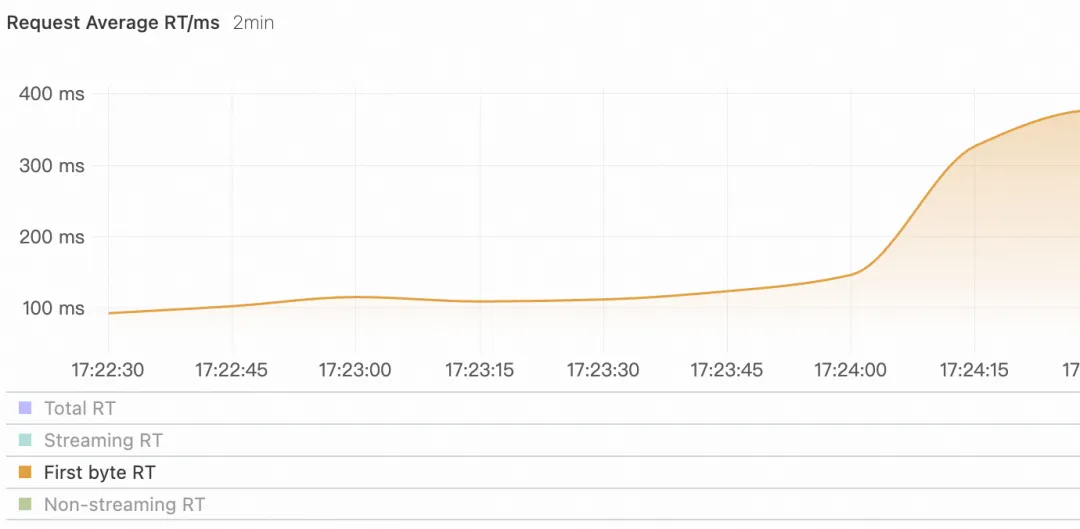
图 4
在没有开启相关 LLM 高可用能力情况下,用户并发流量最终超出 LLM 服务可承受能力而挂掉,重启时间在 3 分钟左右,此时间段内都无法提供服务。


图 5
阿里云 AI 网关 LLM 服务高可用保障
Fallback 机制
基于 Fallback 机制,实现当主用 LLM 服务不可用时兜底到备用 LLM 服务,是 AI 网关上做 LLM 服务高可用方案最基础的方式。下面以一个 AI 网关客户中最常见的用例举例:当在阿里云上自建 LLM 模型不可用时基于 AI 网关的 Fallback 机制 兜底到阿里云百炼。
在阿里云 AI 网关新建自己的网关实例,进入服务选项卡,点击创建服务按钮,服务来源选择 AI 服务,大模型供应商选择 PAI-EAS,然后 AI 网关能够自动识别已创建的 PAI-EAS 服务,通过选择工作空间和指定的 EAS 服务,LLM API-KEY 会自动从 PAI 获取,点击确定后服务创建成功。
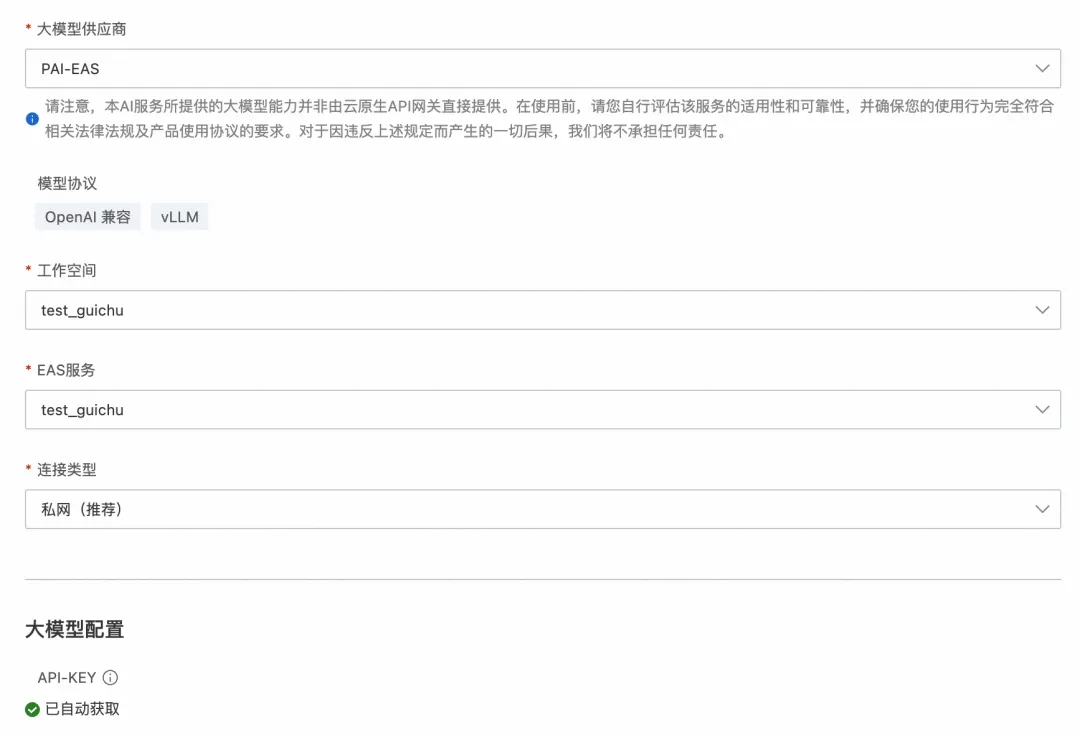

图 6
然后选择 LLM API 选项卡,点击创建 LLM API 按钮,LLM 服务-服务列表选中刚刚创建的服务,填写基本信息,并开启 fallback,选择百炼作为 fallback 备用服务,点击确定后 LLM API 创建成功。
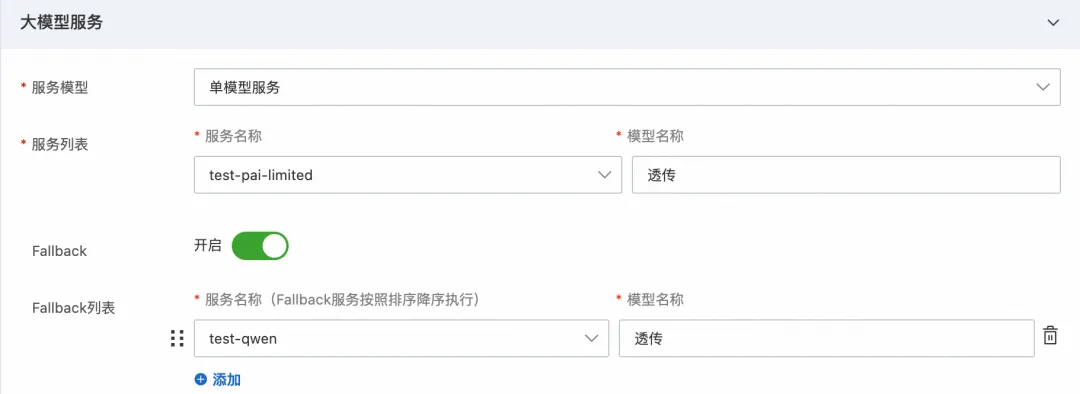
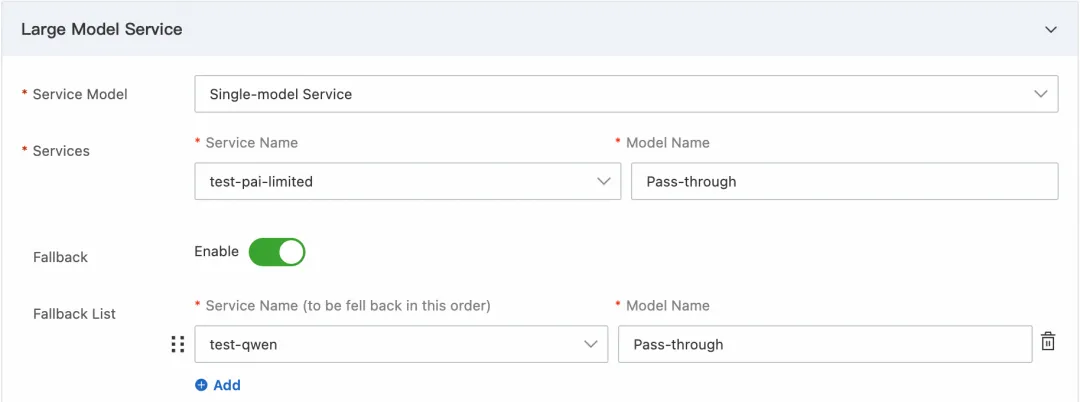
图 7
点击 LLM API 操作选项中调试,可以在 AI 网关上快速开启对话,响应正常从 AI 网关到达后端 PAI-EAS 服务,并返回响应。
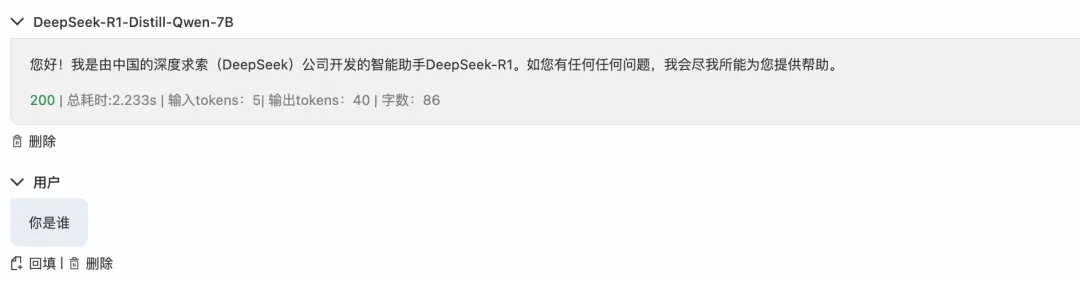
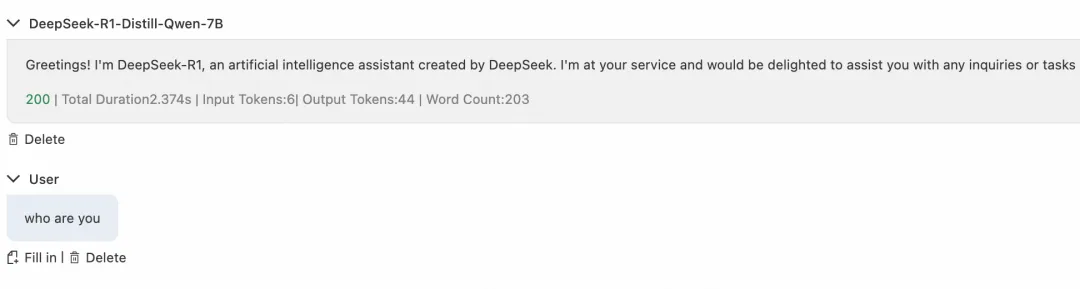
图 8
然后在 PAI-EAS 中选择中止流量,可以模拟后端服务异常情况。


图 9
此时用户发送对话请求,由于 PAI-EAS 上部署的主服务不可用,请求自动 fallback 到备用服务百炼,返回响应中说明处理模型为 qwen,保障了服务可用性。
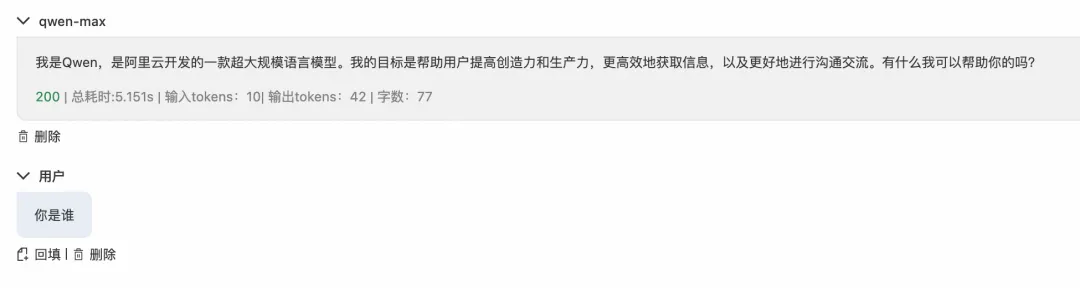
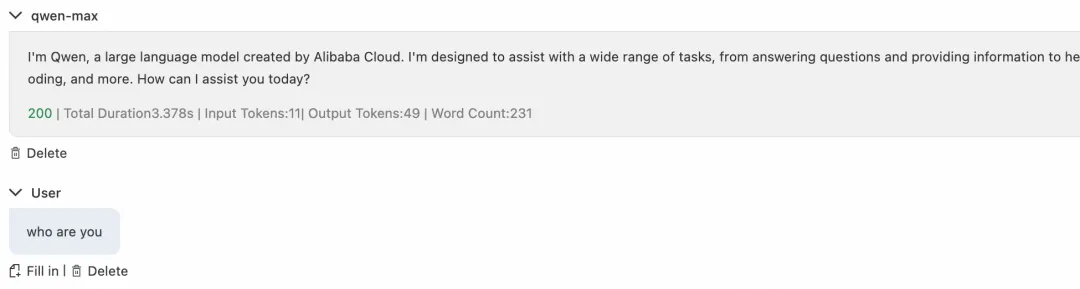
图 10
被动健康检测和首包超时
对于自建 LLM 的场景来说,在流量突增场景下,因为资源不足,GPU 瞬间打满的情况,仅使用 LLM 服务的 fallback 机制做事后防护是不够的。这种场景一方面可以使用 AI 网关的并发和限流防护,另一方面可以结合被动健康监测和首包超时机制,进行事前防护。
服务响应时间能够反映大模型此时负载情况,即通过首包超时配置,能够在首包响应时间过长时候让用户请求快速失败快速重试,同时保障用户体验;而当请求失败率过高时候,会触发被动健康检查及时移除后端服务节点,对 LLM 服务进行过载保护;当服务节点被全部移除,则可以将请求 fallback 到备用服务实现服务持续可用。
下面的用例展示了在用户流量突增场景下,阿里云 AI 网关保障了 LLM 服务的可用性。
首先在刚刚创建的服务选择健康检查配置,选择开启被动健康检查,然后将失败率阈值配置为 50,表示服务节点请求失败率达到 50% 会被标记为故障节点并移除,检测间隔时间配置为 1s,表示每1s计算一次请求失败率,基础弹出时间配置为 30s,表示节点被移除的基础时间为 30s。
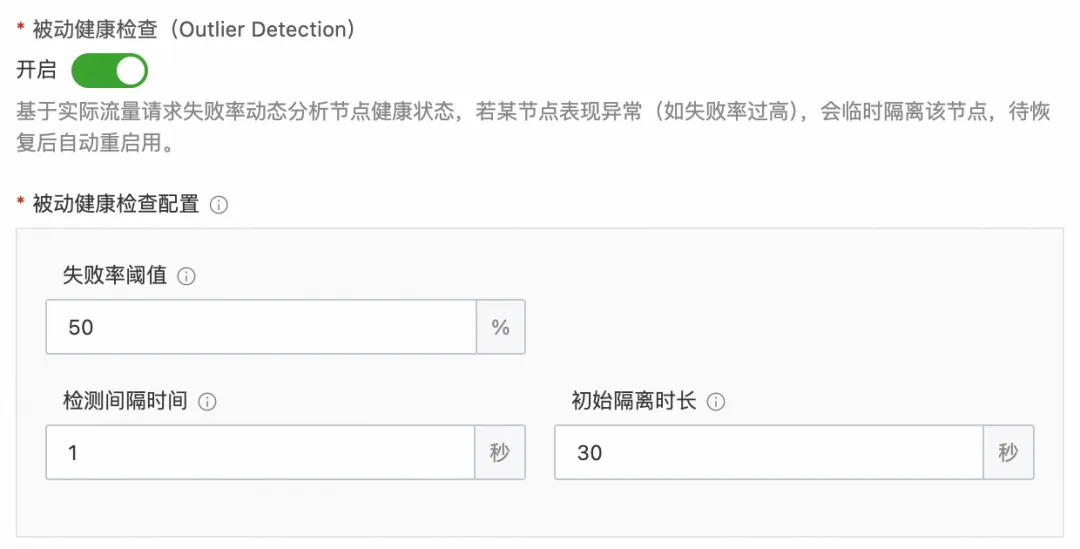
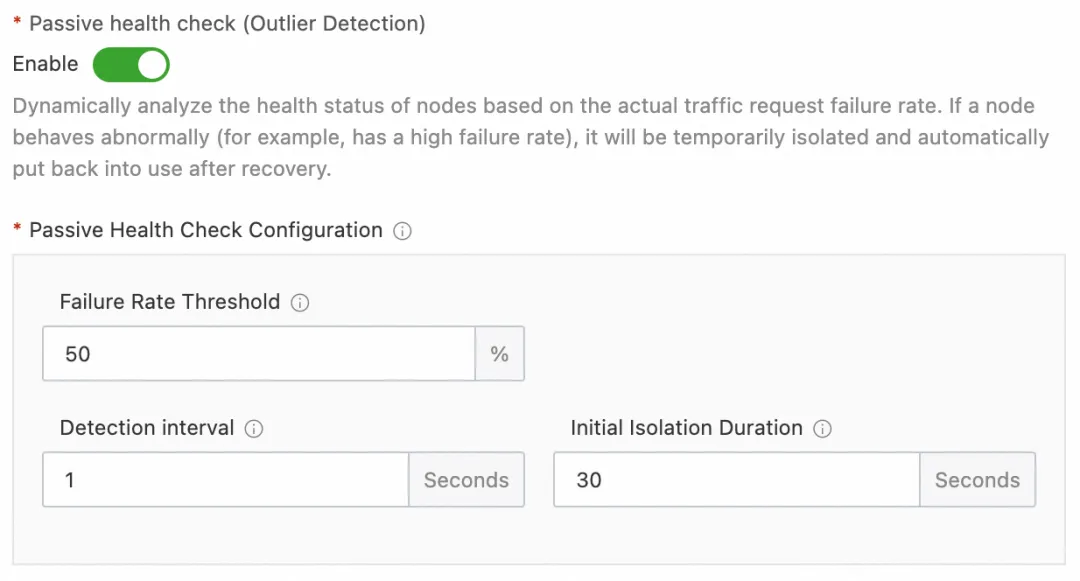
图 11
在刚刚创建的 Model API 点击编辑,在大模型服务配置最下面配置首包超时时间为 200ms,表示首包时间超过 200ms 时会触发超时,并返回请求失败。
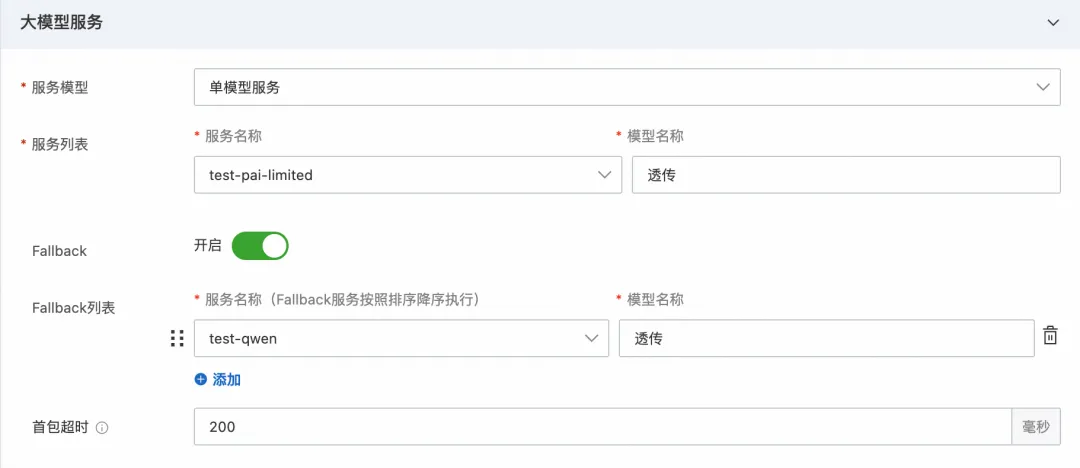
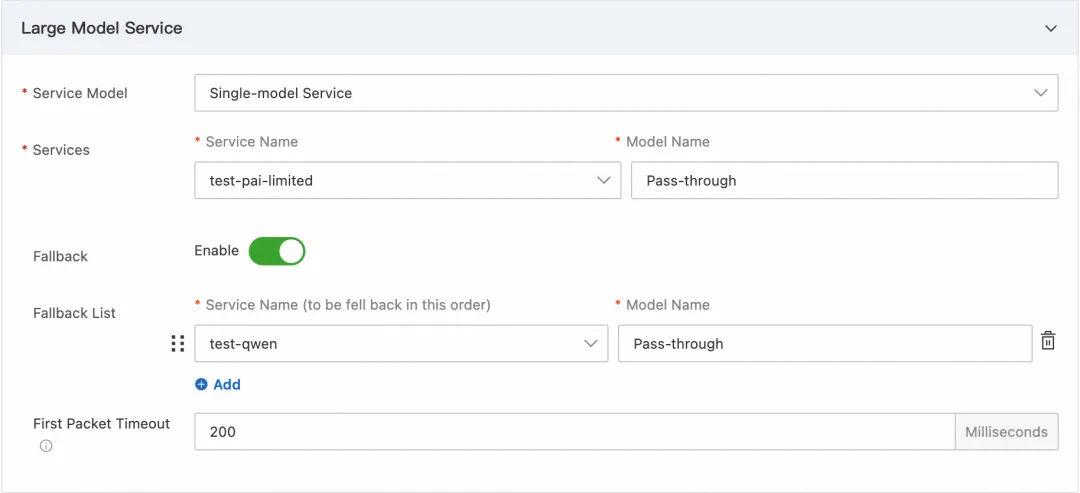
图 12
具体配置和含义见下表。
| 配置名 | 配置值 | 字段含义 |
|---|---|---|
| 失败率阈值 | 50 | 当某节点失败请求占比达到此阈值,系统将触发该节点的弹出机制。 |
| 检测间隔时间 | 1s | 每隔指定时间(如 30 秒)计算节点的请求失败率。 |
| 基础间隔时间 | 30s | 节点被弹出后的初始隔离时长(如 30 秒)。隔离时间计算公式:k * base_ejection_time(k 初始值为1),每次弹出会延长隔离时间(k 加一),若连续检测正常则逐步缩短隔离时间(k 减一)。 |
| 首包超时 | 200ms | 首个数据包响应时间超过指定时间触发超时,请求失败。 |
开启被动健康检测和首包超时相关后,在流量激增时候,可以发现由于 LLM 过载导致首包时间过长,用户请求大量失败,失败率超过被动健康检查阈值,最后主服务节点(PAI-EAS)由于过载被移除,此时请求被全部转发到备用服务(通义千问)进行处理,在一段时间后,主服务恢复健康重新加入提供服务,在此过程中,首包 RT 在持续增长后达到高峰,之后主服务过载而处于不健康状态,在主服务重新提供正常服务后,首包 RT 下降并维持稳定,主服务持续存活。
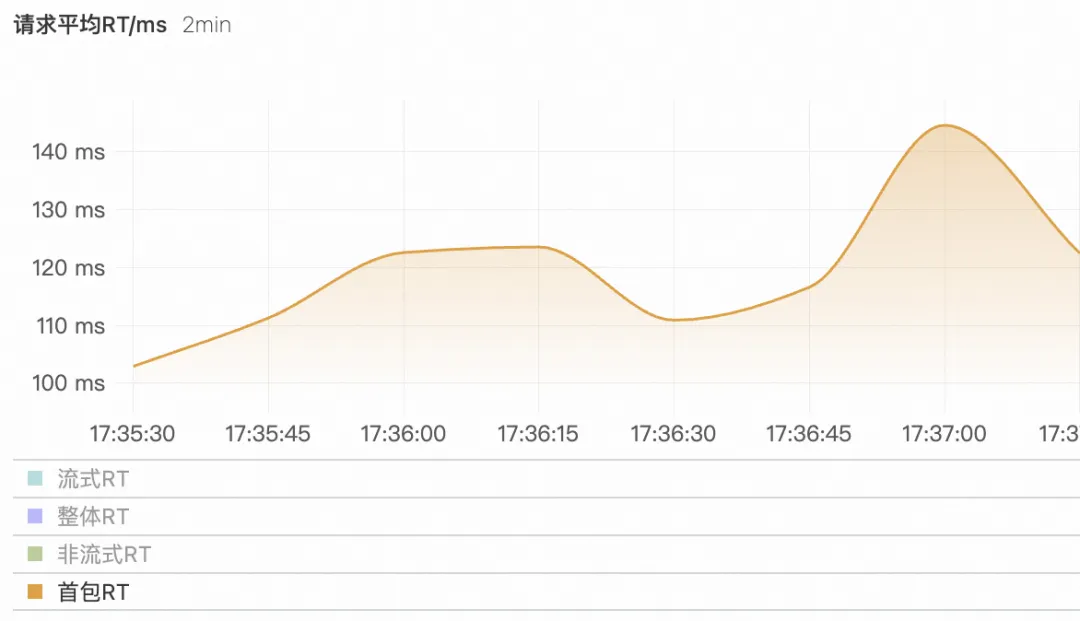
图 13
关于 Higress AI 网关的更多信息,欢迎参加云栖大会第三天 AI 中间件分论坛,D1-3。