
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@Jerry fong,@鲍勃
01 有话题的技术
1、Gemini CLI Extensions 框架正式发布:AI 融入开发者工具链
谷歌正式推出了 Gemini CLI Extensions 框架,旨在构建一个开放的生态系统,让开发者能够通过 预打包、即装即用 的扩展程序,将 AI 驱动的 Gemini CLI(命令行界面) 无缝集成到日常开发工具链中。
-
Playbook 核心:实现 AI 与外部工具的零配置集成
这些扩展以独特的 「Playbook」 为核心,其中预置了 MCP 服务器 、上下文指令、自定义命令以及工具禁用规则。这一设计使用户无需进行复杂的配置,即可让 AI 快速掌握外部服务的使用方式 。开发者只需通过简单命令,就能安装来自谷歌、行业巨头(如 Figma、Stripe、Shopify、Snyk)及开源社区的扩展,涵盖数据库、CI/CD、API 管理、设计系统、安全检测与云服务等关键领域,从而显著提升开发效率与智能化水平。
-
谷歌自研扩展与 Genkit 的深度集成
作为生态系统的核心推动力,谷歌同步发布了一系列自研扩展,覆盖云原生 (Cloud Run、GKE、gcloud) 、应用开发 (Firebase、Flutter、Chrome DevTools) 和生成式 AI (Genkit、Looker、Data Cloud) 等关键场景。
其中,Genkit Extension for Gemini CLI 尤为关键。它通过深度集成 Genkit 的 MCP 服务器与上下文文件,赋予 CLI 理解 Genkit 架构、执行流、调试跟踪及 SDK 最佳实践的能力,实现了 从终端直接构建、测试和迭代 AI 应用 的革命性工作流。
-
优化体验,推动 AI Agent 融入现代开发
为全面优化开发者体验,谷歌同步上线了 geminicli.com 官方网站和专属的扩展目录,并在 v0.8.0 版本中增强了非交互模式支持与终端状态实时显示功能。这一系列举措旨在推动 AI Agent 真正融入现代开发工作流程。
相关链接:https://geminicli.com/(@橘鸭 Juya)
2、腾讯上线 Hunyuan-Vision-1.5 模型:Mamba-Transformer 混合架构
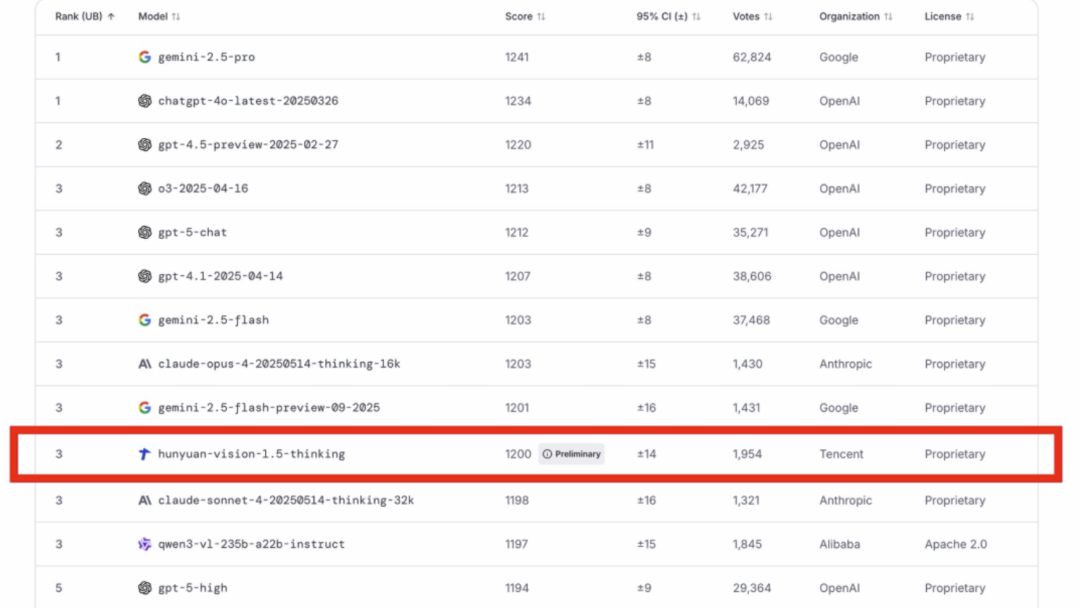
腾讯混元团队正式推出 Hunyuan-Vision-1.5,这是一款采用创新的 Mamba-Transformer 混合架构 的先进多模态视觉语言模型。该模型在权威的 LMArena 视觉排行榜中并列全球第三,超越了 Qwen3-VL,成为 中国表现最佳的模型。
Hunyuan-Vision-1.5 具备强大的 「Thinking-on-Image」 推理能力,支持 图像/视频理解、OCR(光学字符识别)、图表分析、视觉推理 与 3D 空间感知 等多项功能,并天然兼容多语言场景。通过引入 动态图像编辑(如裁剪、标注)和 网络搜索增强推理机制,模型的性能取得了显著提升。
目前,用户可通过 腾讯云 API 以及 LMArena Direct Chat 试用该模型,其中备受关注的「Thinking on Images」功能即将上线。
混元团队同时宣布了后续开源计划,包括发布模型权重(A56B, 4B)、Hunyuan-ViT-V1 权重和技术报告,以及对 TRT/VLLM 推理的支持。
Github:https://github.com/Tencent-Hunyuan/HunyuanVision
相关链接:https://cloud.tencent.com/document/product/1729/104753
(@橘鸭Juya)
3、ElevenLabs 推出 ElevenLabs UI——专为 AI 音频和语音智能体设计的开源组件
ElevenLabs 开源了 ElevenLabs UI,一个专为 AI 音频和语音智能体设计的组件。包括 22 个用于聊天界面、转录、音乐等场景的组件和示例,完全可定制并采用 MIT 许可证。
ElevenLabs UI 提供了预构建、可定制的 React 组件,专门为智能体和音频应用程序设计,包括球体、波形、语音智能体、音频播放器等。CLI 使将这些组件添加到 Next.js 项目变得轻而易举。
Demo:https://ui.elevenlabs.io/
Github:https://github.com/elevenlabs/ui
( @ElevenLabs)
4、Deepgram 发布「对话式语音识别」模型「Flux」,将语音转录和轮次检测集成在同一模型
Deepgram 近日发布了其全新的「Flux」模型,号称业界首款生产级的「对话式语音识别」(Conversational Speech Recognition, CSR)模型。该模型通过将高精度转录与上下文感知的「轮次检测」(turn detection)融合进单一 API,旨在从根本上解决语音「智能体」开发中最大的痛点——尴尬的打断与延迟,从而大幅简化开发流程。
-
一体化对话模型:「Flux」的核心突破在于其「融合」架构,将语音转录和轮次检测在同一个模型中完成。它能基于语义和声学线索理解对话何时自然结束,而不是像传统方案那样依赖简单的静音检测,从而将误打断率降低约 30%。
-
极致简化的开发体验: 开发者不再需要拼凑复杂的 ASR + VAD + 端点判断管道。Flux 提供了一个简单的 API,通过StartOfTurn和EndOfTurn等对话原生事件,让开发者能专注于「智能体」的业务逻辑,而非底层基础设施的调试。
-
高性能与高精度兼得: 「Flux」在大幅优化对话流畅性的同时,其转录准确率与 Deepgram 旗舰模型「Nova-3」持平。基准测试显示,与传统方案相比,它能将「智能体」的响应延迟降低 200-600 毫秒,同时保持极低的词错率(WER)。
-
为高级工作流设计: 针对对延迟极度敏感的应用,「Flux」引入了 EagerEndOfTurn(预判轮次结束)事件。这允许「智能体」进行推测性响应生成(例如提前调用 LLM),进一步压缩交互延迟。
「Flux」现已通过 Deepgram API 全面提供。为庆祝发布,Deepgram 推出了「OktoberFLUX」活动,整个十月期间可免费使用,并提供最高 50 个并发连接。 首批集成合作伙伴包括 Cloudflare、LiveKit、Vapi、Pipecat 和 Jambonz。
相关链接:https://deepgram.com/learn/introducing-flux-conversational-speech-recognition
( @deepgram 官网)
5、OpenAI 推出 gpt-realtime-mini,成本比 gpt−realtime 低 70%
OpenAI 推出了「gpt-realtime-mini」,一个旨在提供更低成本的实时 AI 解决方案。该模型支持音频、图像和文本输入,音频和文本输出;可通过 WebRTC、WebSocket 或 SIP 连接进行实时交互。该模型进一步降低了其高性能「gpt-realtime」的门槛,使更多开发者和企业能够构建实时 AI 应用。
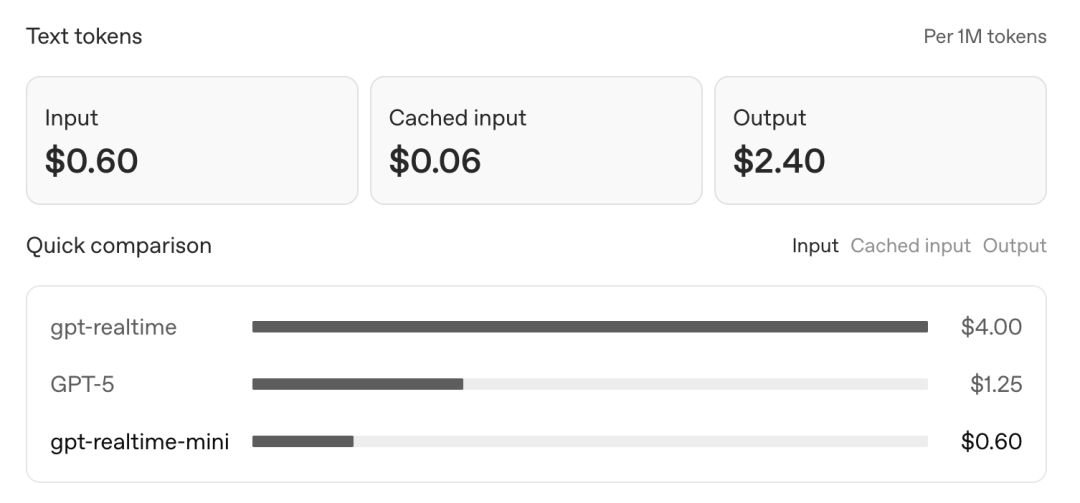
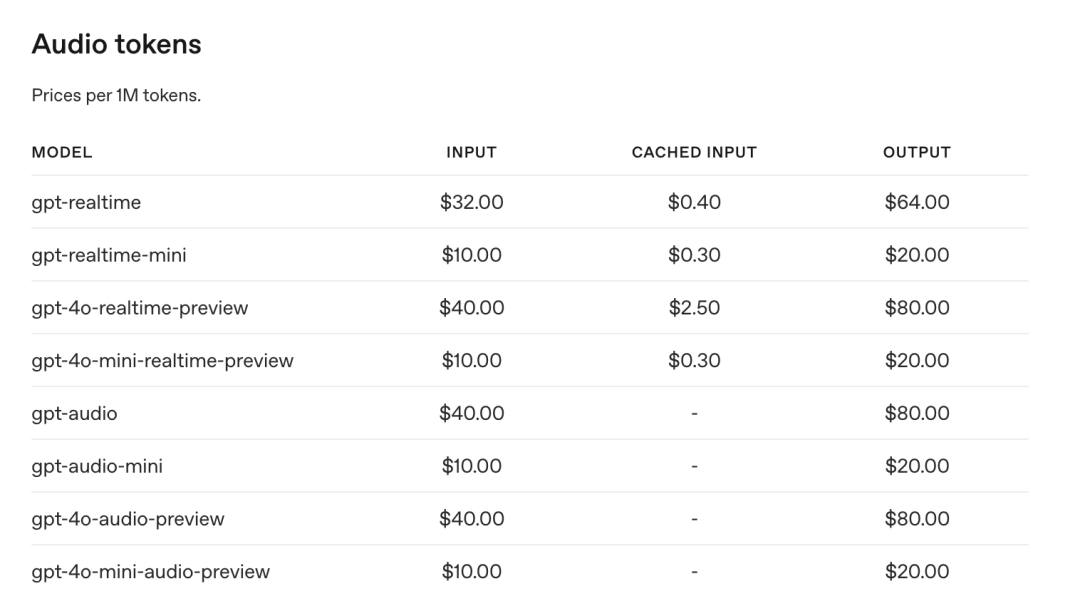
「gpt-realtime-mini」的文本输入 Token 价格仅为 0.6 美元每百万 token,远低于「gpt−realtime」的 4 美元每百万 token。音频输入为 10 美元每百万 token,也低于「gpt−realtime」的 32 美元。
相关链接:https://platform.openai.com/docs/models/gpt-realtime-mini
(@OpenAI 官网)
02 有亮点的产品
1、Google AI Studio 「build」模块新增语音输入功能
Google AI Studio 在其「build」模块中新增了语音转文本输入功能,允许用户通过语音进行代码编写、功能添加或应用描述,该功能能够智能地自动移除冗余词和错误,生成清晰的提示。该功能暂不支持普通话。
( @Google Blog)
2、Grok 为语音模式上线更多音色
Grok 的语音模式现已开放 12 种可选的人格音色,用户可以在 Settings 菜单中直接进行切换。已确认上线的音色包括 Assistant、Romantic、Therapist、Grok Doc、Unhinged、Meditation、Motivation、Conspiracy、Storyteller、Kids 以及 Argumentative。每种人格均配套了多组不同的声线,支持用户即时试听与一键启用。
相关链接:https://x.com/cb_doge/status/1974469592765608120
( @Doge Designer@X)
03 有态度的观点
1、Cursor 创始人:AI 编程处于漫长复杂的「中间阶段」
9 月,AI 编程平台 Cursor 的联合创始人兼 CEO Michael Truell 接受了 Y Combinator 的一次深度访谈,其在节目中分享了 Cursor 的部分发展之路以及个人对行业的见解。在正式创立 Cursor 之前,Truell 的团队经历了数次代价高昂的失败,如耗时六个月,为机械工程师打造 CAD 领域的「Copilot」,以及端到端加密通信系统,但最终都因缺乏领域热情、用户反馈寥寥而宣告失败。
「那种『无奈感』反而帮助我们明晰了自己真正关心和追求的方向,」Truell 坦言。正是这些失败,让团队意识到他们内心真正的热情在于「编码的未来」。
当时的他们坚信,「在未来五年里,整个编码领域都有可能发生改变,所有软件开发都可能通过模型来完成」,而现有玩家并未全力朝这个方向迈进。
对于 AI 将如何重塑编程,Truell 认为行业正处在一个漫长而复杂的「中间阶段」。「AI 会越来越像你的同事,或者一个非常高级的编译器,但你仍然需要阅读逻辑、进行审查和编辑。」
对话中,Truell 还向年轻一代的开发者和创业者给出了自己的建议:
我觉得最重要的是去做你真正感兴趣的事情,并且和那些你既喜欢相处又非常尊重的人一起去做,而且要非常认真地对待。避免为了完成任务而去「打勾」,应专注于能够长期积累、真正构建你感兴趣的东西。
(@ APPSO)


阅读更多 Voice Agent 学习笔记:了解最懂 AI 语音的头脑都在思考什么
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻