自编码器这类模型有下面几个:
自编码器(AE):目标是压缩与重建。它是一个判别模型,目标是学习数据的高效表示,主要用于降维、去噪和数据压缩,而不是生成新数据。
变分自编码器(VAE): 学习数据的概率分布并生成。它是一个生成模型。它的关键突破是让隐变量 z 服从一个标准的概率分布(通常是高斯分布),从而使得隐空间是规则且连续的,可以用于生成新数据。
条件变分自编码器(CVAE): 在特定条件下生成数据。它是 VAE 的扩展,让整个生成过程条件于某个额外的信息 c(如图像的标签、一段文本、另一张图片等)。
它们的关系是:
AE(学习表示)-> VAE(学会生成)-> CVAE(学会按指令生成)
CVAE模型结构如下:
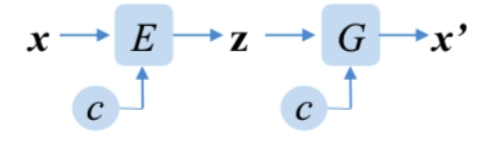
x是原始输入数据,x'是生成数据,c是标签数据,z是隐变量,E是编码器模型,G是解码器模型。
下面以生成MNIST数据为例,可以和之前的VAE做个对比,代码如下:
import torch import torch.nn as nn import torch.optim as optim import torchvision import torch.nn.functional as F from torchvision.utils import save_image from torchvision import datasets from sklearn.preprocessing import LabelBinarizerlatent_size = 64 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 条件变分自编码器 class CVAE(nn.Module):def __init__(self):super(CVAE, self).__init__()# 编码器层self.fc1 = nn.Linear(794, 512) self.fc2 = nn.Linear(512, latent_size)self.fc3 = nn.Linear(512, latent_size)# 解码器层self.fc4 = nn.Linear(latent_size+10, 512) self.fc5 = nn.Linear(512, 794) self.lb = LabelBinarizer()def to_categrical(self, y: torch.FloatTensor):y_n = y.numpy()self.lb.fit(list(range(0,10)))y_one_hot = self.lb.transform(y_n)floatTensor = torch.FloatTensor(y_one_hot).to(device)return floatTensor# 编码器部分def encode(self, x,y):y_c = self.to_categrical(y)x = torch.cat((x, y_c), 1)x = F.relu(self.fc1(x)) # 编码器的隐藏表示mu = self.fc2(x) # 潜在空间均值log_var = self.fc3(x) # 潜在空间对数方差return mu, log_var# 重参数化技巧def reparameterize(self, mu, log_var): # 从编码器输出的均值和对数方差中采样得到潜在变量zstd = torch.exp(0.5 * log_var) # 计算标准差eps = torch.randn_like(std) # 从标准正态分布中采样得到随机噪声return mu + eps * std # 根据重参数化公式计算潜在变量z# 解码器部分def decode(self, z, y):y_c = self.to_categrical(y)#解码器的输入:将z和y的one-hot向量连接z = torch.cat((z, y_c), 1)z = F.relu(self.fc4(z)) # 将潜在变量 z 解码为重构图像return torch.sigmoid(self.fc5(z)) # 将隐藏表示映射回输入图像大小,并应用 sigmoid 激活函数,以产生重构图像# 前向传播def forward(self, x, y): # 输入图像 x 通过编码器和解码器,得到重构图像和潜在变量的均值和对数方差mu, log_var = self.encode(x.view(-1, 784),y)z = self.reparameterize(mu, log_var)return self.decode(z, y), mu, log_var# 使用重构损失和 KL 散度作为损失函数 def loss_function(recon_x, x, mu, log_var): # 参数:重构的图像、原始图像、潜在变量的均值、潜在变量的对数方差MSE = F.mse_loss(recon_x, x.view(-1, 794), reduction='sum') # 计算重构图像 recon_x 和原始图像 x 之间的均方误差KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp()) # 计算潜在变量的KL散度return MSE + KLD # 返回二进制交叉熵损失和 KLD 损失的总和作为最终的损失值def sample_images(epoch):with torch.no_grad(): # 上下文管理器,确保在该上下文中不会进行梯度计算。因为在这里只是生成样本而不需要梯度number = 80sample = torch.randn(number, latent_size).to(device) # 生成一个形状为 (80, latent_size) 的张量,其中包含从标准正态分布中采样的随机数values = torch.arange(10) # tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])c = values.repeat_interleave(8)sample = model.decode(sample,c).cpu() # 将随机样本输入到解码器中,解码器将其映射为图像sample = sample[:,0:784]save_image(sample.view(number, 1, 28, 28), f'sample{epoch}.png') # 将生成的图像保存为文件if __name__ == '__main__':batch_size = 512 epochs = 100 sample_interval = 5 learning_rate = 0.001 # 载入 MNIST 数据集中的图片进行训练transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) mnist_train = datasets.MNIST('mnist', train=True, transform=transform, download=True)train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)model = CVAE().to(device)optimizer = optim.Adam(model.parameters(), lr=learning_rate)for epoch in range(epochs):train_loss = 0for batch_idx, (data, label) in enumerate(train_loader):data = data.to(device) optimizer.zero_grad() # 重构图像 recon_batch、潜在变量的均值 mu 和对数方差 log_varrecon_batch, mu, log_var = model(data,label)flat_data = data.view(-1, data.shape[2]*data.shape[3])y_condition = model.to_categrical(label)con = torch.cat((flat_data, y_condition), 1)loss = loss_function(recon_batch, con, mu, log_var) loss.backward() train_loss += loss.item()optimizer.step() train_loss = train_loss / len(train_loader) print('Epoch [{}/{}], Loss: {:.3f}'.format(epoch + 1, epochs, train_loss))# # 每10次保存图像if (epoch + 1) % sample_interval == 0:sample_images(epoch + 1)# # 每训练10次保存模型# if (epoch + 1) % sample_interval == 0:# torch.save(model.state_dict(), f'vae{epoch + 1}.pth')
结果如下:
