1、第一页
密集视觉预测任务受到对预定义类别的依赖的限制,限制了它们在真实世界场景中的实用性。
视觉语言模型在开放词汇任务中显示出良好前景,但它们直接应用于密集预测任务往往性能不佳。
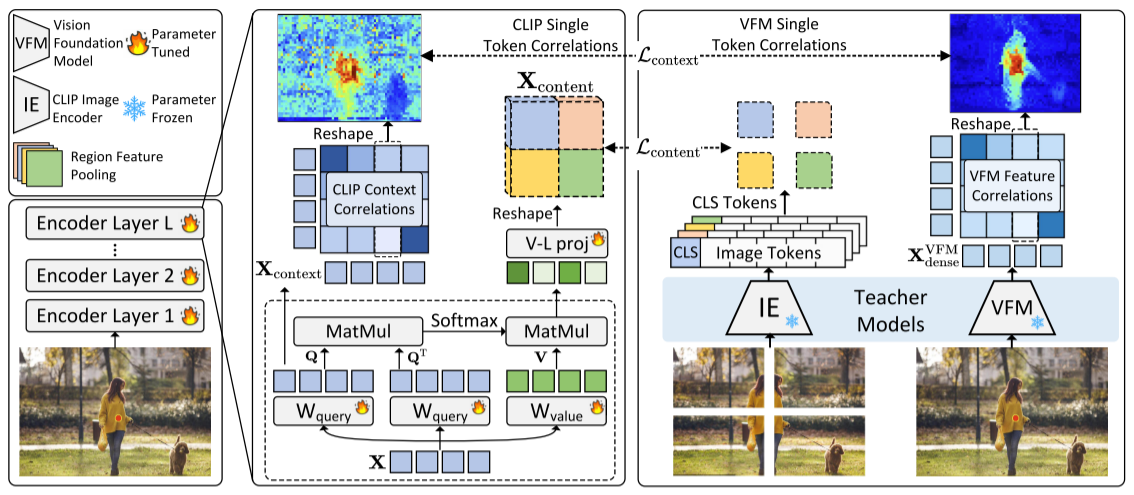
CLIP的图像token难以有效聚集来自空间或语义相关区域的信息(注意力偏移问题),导致特征缺乏局部可区分性和空间一致性。原因是:CLIP的CLS token会干扰其他图像token之间的相关性。
2、第二三页
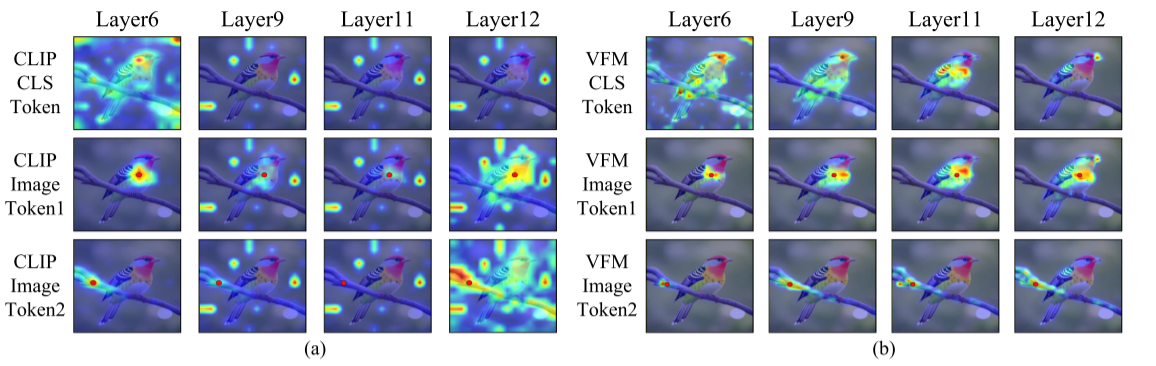
观察到CLIP中更深层中CLS token将焦点从图像内的主要对象移开,而高度关注某些背景token,图像token也表现出类似的行为。也就是说,CLIP的图像token难以有效聚集来自空间或语义相关区域的信息(注意力偏移问题),导致特征缺乏局部可区分性和空间一致性。
提出了DeCLIP旨在提高CLIP局部特征的可区分性和空间一致性。DeCLIP将自我注意模块功能分为“Content”和“Context”组件,Content负责局部可区分性,Context负责空间一致性。
本文研究的CLIP是:视觉编码器为VIT,文本编码器为Transformer。它的CLS token用来表示图像的核心信息整体特征。CLIP 的视觉 - 语言对齐,本质是通过 “奖惩机制” 训练两个编码器:让匹配的 “图像 [CLS] 特征” 和 “文本特征” 越来越像(余弦相似度大),让不匹配的越来越不像(余弦相似度小),最终学会 “看图识文、看文找图” 的能力。
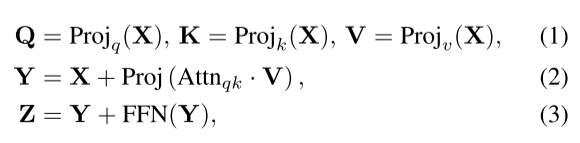
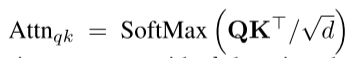
3、第四页
这些背景token会用作CLS token的代理,这些代理会对图像token之间的特征相关性产生负面影响。VFM可以很好的解决代理token现象。
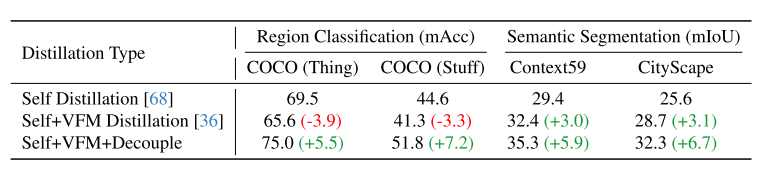
但是,同时进行自蒸馏+VFM蒸馏会导致区域分类性能降低(table 1),是因为空间特征相关性(我们现在正在优化的)和视觉语言对齐具有不同优化重点,从而优化冲突。于是我们解耦。
4、第五页
上面的公式,从Q和K导出的Attnqk对V进行指导和加权求和,该Attnqk定义了图像token之间的空间和语义关系,所以可以用来提高空间一致性。
[38,59,63,71]证明Xdense可以直接用于像素分类的语义分割,说明Xdense的每个像素包含独立的语义信息,所以可以用来提高局部区分度。
最新的OVS使我们可以不关注K,只关注Q来简化局部特征一致性的优化。
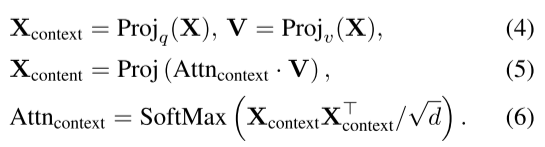
5、第六页



6、模型的效果以及和其他模型的比较。
(1)开放词汇目标检测
这部分验证 DeCLIP 在 “检测未知类别” 任务中的性能,重点看 “Novel 类”(训练未见过的类别)和 “Rare 类”(样本极少的类别)的提升,数据集用OV-COCO、OV-LVIS,与F-ViT、OV-DQUO目标检测模型比较。
(2)开放词汇语义分割
分割任务对空间一致性要求更高,更能体现 DeCLIP 的优势。mIoU可以作为评估指标。
(3)基于VLM特征的分割
(4)区域分类
区域分类是对 “局部判别性” 的直接验证。Top1 mAcc作为评估指标。
7、消融实验
(1)选择哪个 VFM 作为上下文蒸馏的教师
DINO:分割性能中等,区域分类差;
SAM:区域分类好,分割差;
DINOv2:两者平衡。最终选择 DINOv2 作为默认 VFM。
创新点:
(1)首次揭示 CLIP 的 “代理令牌” 现象,明确了 CLIP 在密集任务中性能差的根源。
(2)提出 “解耦注意力 + 双蒸馏” 框架,优雅解决优化冲突。面对 “判别性” 与 “一致性” 的优化冲突,既保留了 CLIP 的跨模态能力,又融入了 VFM 的空间关联能力。
下面补一下基础:
OV-COCO、OV-LVIS:用于评估开放词汇模型的数据集。
F-ViT、OV-DQUO:目标检测模型
CAT-Seg:分割模型
mIoU:是图像分割任务中用于评估模型性能的指标
Top1 mAcc:是区域分类中的评估指标,Thing 类 和 Stuff 类