一、基础知识
1. 倒排索引和正向索引的区别
-
正向索引:
ForwardIndex- 按文档ID组织数据,每个文档包含其所有字段内容。
- 查询时需遍历所有文档,效率较低,适用于全文检索场景较少。
-
倒排索引:
InvertedIndex- 按关键词组织数据,记录每个词在哪些文档中出现及其位置。
- 查询时直接定位到相关文档,效率高,是搜索引擎的核心技术。
| 对比项 | 正向索引 | 倒排索引 |
|---|---|---|
| 组织方式 | 文档 → 内容 | 关键词 → 文档列表 |
| 查询效率 | 低(需扫描全部文档) | 高(直接跳转到相关文档) |
| 适用场景 | 数据库主键查询 | 全文检索、快速搜索 |
2. Elasticsearch(ES)的基本介绍
(1)定义
Elasticsearch 是一个基于 Apache Lucene 的开源分布式搜索和分析引擎,支持实时搜索、日志分析、全文检索等功能。
(2)优点
- 高性能:支持近实时搜索,毫秒级响应。
- 分布式架构:可水平扩展,支持多节点集群部署。
- 全文检索:内置强大的文本分析能力,支持模糊匹配、同义词等。
- RESTful API:通过 HTTP 接口操作,易于集成。
- 高可用性:支持副本机制,保障数据安全与服务连续性。
(3)缺点
- 资源消耗大:内存占用较高,尤其在处理大量数据时。
- 复杂度高:配置调优较复杂,需要一定经验。
- 不适合事务性操作:不支持强一致性事务,适合最终一致性场景。
(3)作用
- 实现高效的全文检索功能。
- 构建日志分析系统(如 ELK Stack)。
- 支持实时数据分析与监控。
- 提供地理空间搜索能力。
3. Elasticsearch 的基本概念
-
Cluster(集群):
Cluster
一组协同工作的Node节点集合,共同存储数据并提供搜索功能。 -
Node(节点):
Node
集群中的单个服务器实例,可以是主节点或数据节点。 -
Index(索引):
Index
类似于数据库中的“表”,用于存储具有相似特征的文档集合。 -
Document(文档):
Document
最小的数据单位,通常是一个 JSON 对象,代表一条记录。 -
Shard(分片):
Shard
将索引拆分为多个逻辑部分,支持横向扩展和并行处理。 -
Replica(副本):
Replica
每个分片的复制,用于提高可用性和读取性能。 -
Mapping(映射):
Mapping
定义索引中字段的数据类型及分析规则,类似于数据库的 Schema。 -
Query DSL:
Query DSL
Elasticsearch 提供的基于 JSON 的查询语言,用于构建复杂的查询条件。 -
Refresh(刷新):
Refresh
默认每 1 秒执行一次,使新写入的数据对搜索可见,实现近实时搜索。 -
Segment(段):
Segment
分片的底层存储单元,由 Lucene 管理,支持高效搜索和合并。
这些核心概念构成了 Elasticsearch 的基础架构,理解它们有助于更好地设计和优化搜索系统。
4. Elasticsearch索引的基本维护(增删改查)
(1)增加索引(Create Index)
通过 PUT 请求创建索引,可定义 mapping 和设置分片副本数。
PUT /my_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"title": { "type": "text" },"content": { "type": "text" }}}
}
说明:
number_of_shards定义主分片数量,number_of_replicas定义副本数量。
(2)删除索引(Delete Index)
使用 DELETE 请求删除指定索引。
DELETE /my_index
注意:删除操作不可逆,请谨慎执行。
(3)修改索引(Update Index)
Elasticsearch 不支持直接修改索引结构,但可通过以下方式间接实现:
-
更新设置(Settings):
PUT /my_index/_settings {"index.number_of_replicas": 2 } -
重建索引(Reindex):
使用_reindexAPI 将旧索引数据迁移到新索引中,适用于更改mapping或设置。POST _reindex {"source": {"index": "old_index"},"dest": {"index": "new_index"} }
(4)查询索引(Get Index Info)
获取索引信息,包括设置和映射。
GET /my_index
或查询特定字段信息:
GET /my_index/_mapping
说明:可用于查看当前索引的
mapping结构和配置。
5.Elasticsearch文档的基本维护(增删改查)
(1)添加文档(Create Document)
使用 PUT 或 POST 请求向索引添加文档。
PUT /my_index/_doc/1
{"title": "Elasticsearch 入门","content": "学习 Elasticsearch 的基础知识..."
}
或使用 POST 自动分配 ID:
POST /my_index/_doc/
{"title": "Elasticsearch 实战","content": "实战案例分享..."
}
(2)删除文档(Delete Document)
通过文档 ID 删除指定文档。
DELETE /my_index/_doc/1
(3)更新文档(Update Document)
使用 UPDATE API 修改文档内容。
POST /my_index/_update/1
{"doc": {"title": "Elasticsearch 深入解析","content": "深入讲解核心机制..."}
}
说明:
_update会先获取文档,然后应用修改并重新索引。
(4)查询文档(Get Document)
根据文档 ID 获取单个文档。
GET /my_index/_doc/1
或进行全文搜索:
GET /my_index/_search
{"query": {"match": {"content": "Elasticsearch"}}
}
说明:
_search支持复杂查询,如布尔查询、范围查询等。
| 操作 | 索引级别 | 文档级别 |
|---|---|---|
| 创建 | PUT /index |
PUT /index/_doc/id |
| 删除 | DELETE /index |
DELETE /index/_doc/id |
| 更新 | 间接通过 _reindex |
POST /index/_update/id |
| 查询 | GET /index |
GET /index/_doc/id |
这些操作构成了 Elasticsearch 日常运维的核心能力,结合 RESTful API 可高效完成数据管理任务。
6.Elasticsearch的分词器(analyzer)
(1)分类
standard analyzer:默认分词器,按空格和标点符号分割,适用于英文文本。whitespace analyzer:仅按空白字符分割,不进行小写转换。simple analyzer:将所有非字母字符替换为空格,再按空格分割。keyword analyzer:不进行分词,将整个字段作为单一词项处理。pattern analyzer:使用正则表达式进行分词,可自定义分割规则。
(2)分词机制
- Tokenization:将文本切分为词项(tokens)。
- Lowercasing:将词项转为小写,提高匹配率。
- Stop Words Filtering:移除常见无意义词汇(如 "the", "and")。
- Stemming:提取词干,支持变体匹配(如 "running" → "run")。
(3)使用场景
- 全文检索:使用
standard analyzer处理用户输入查询。 - 精确匹配:使用
keyword analyzer处理 ID 或枚举值。 - 多语言支持:结合语言特定分词器(如中文
ik分词器)。 - 自定义规则:使用
pattern analyzer按业务需求分割文本。
示例:
PUT /my_index
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"type": "custom","tokenizer": "my_tokenizer"}},"tokenizer": {"my_tokenizer": {"type": "pattern","pattern": "\\W+"}}}}
}
7.Elasticsearch的推荐器(suggester)
(1)分类
term suggester:基于词频建议最可能的完整词项。phrase suggester:基于上下文建议短语组合。completion suggester:用于自动补全,支持前缀匹配。context suggester:结合上下文信息提供个性化建议。
(2)作用
- 提高搜索效率,减少用户输入错误。
- 支持智能提示,提升用户体验。
- 实现自动补全功能(如搜索框下拉建议)。
(3)使用场景
- 搜索框自动补全:使用
completion suggester快速响应用户输入。 - 拼写纠错:使用
term suggester建议正确拼写。 - 智能推荐:结合用户行为数据,提供个性化建议。
- 多语言支持:支持不同语言的建议逻辑。
示例:自动补全
POST /my_index/_search
{"suggest": {"autocomplete": {"prefix": "elasticsearch","completion": {"field": "suggest_field"}}}
}
示例:拼写纠错
POST /my_index/_search
{"suggest": {"term_suggest": {"text": "elasricsearch","term": {"field": "title"}}}
}
8.ES计算得分算法有哪些?BM25排序?
(1)ES计算得分算法
Elasticsearch 使用多种算法计算文档与查询的相关性得分,主要包含以下几种:
-
TF-IDF(Term Frequency-Inverse Document Frequency)- 基于词频和逆文档频率计算相关性。
- 公式:
score = tf * idf - 适用场景:基础的文本匹配,适用于简单查询。
-
BM25(Best Match 25)-
改进的 TF-IDF 算法,考虑了文档长度归一化和词频饱和效应。
-
公式:
score(q,d) = \sum_{t \in q} IDF(t) \cdot \frac{f(t,d) \cdot (k_1 + 1)}{f(t,d) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{avgdl})} -
参数说明:
f(t,d):词项 [t](file://E:\CodeProgramAll\smart_customer\smart_customer_service\customer-common\target\maven-status\maven-compiler-plugin\compile\default-compile\inputFiles.lst) 在文档d中的频率。IDF(t):词项 [t](file://E:\CodeProgramAll\smart_customer\smart_customer_service\customer-common\target\maven-status\maven-compiler-plugin\compile\default-compile\inputFiles.lst) 的逆文档频率。k1:控制词频饱和的参数,默认为 1.2。b:控制文档长度归一化的参数,默认为 0.75。|d|:文档长度。avgdl:平均文档长度。
-
-
TF-IDFvsBM25特性 TF-IDF BM25 文档长度影响 忽略 考虑文档长度归一化 词频饱和 不处理 处理词频饱和效应 性能 较快 稍慢但更准确
(2)BM25 排序机制
BM25 是 Elasticsearch 默认的评分算法,其核心思想是:
- 词频(TF):词在文档中出现越频繁,相关性越高,但存在饱和效应。
- 逆文档频率(IDF):词在更多文档中出现,相关性越低。
- 文档长度归一化:长文档更容易匹配到关键词,需进行归一化处理。
示例:
查询"Elasticsearch",文档 A 包含 3 次该词,文档 B 包含 1 次。
BM25 会根据文档长度和词频饱和调整得分,避免长文档因词频高而被过度推荐。
(3)实际应用
GET /my_index/_search
{"query": {"match": {"content": "Elasticsearch"}},"explain": true
}
返回结果中的
explain字段会展示每个文档的得分计算过程,包括:
tf:词频因子idf:逆文档频率field_norm:字段规范因子score:最终得分
优化建议
- 调整
k1和b参数:通过index.search.slow_log.threshold.query.warn配置日志级别,观察性能影响。 - 使用
script_score自定义打分:结合业务逻辑调整得分权重。 - 启用
profile分析查询执行计划:优化查询性能。
BM25 作为现代搜索引擎的核心算法,显著提升了搜索结果的相关性和准确性,尤其适合中文等语言的全文检索场景。
9.ES常用分析和优化等维护命令
(1)索引健康状态检查
GET /_cat/health?v
- 作用:查看集群整体健康状态(green/yellow/red)
- 关键字段:
status:集群状态number_of_shards:总分片数number_of_replicas:副本数
(2)节点状态监控
GET /_cat/nodes?v
- 作用:查看所有节点的运行状态
- 关键字段:
name:节点名称status:节点状态heap.percent:堆内存使用率
(3)索引统计信息
GET /_cat/indices?v
- 作用:查看所有索引的状态和统计信息
- 关键字段:
index:索引名称status:索引状态docs.count:文档数量store.size:存储大小
(4)分片分配情况
GET /_cat/shards?v
- 作用:查看分片的分配情况
- 关键字段:
index:索引名称shard:分片编号pri.rep:主分片或副本state:分片状态
(5)查询性能分析
GET /my_index/_search?explain=true
- 作用:获取查询执行的详细解释
- 关键字段:
score:文档得分explain:得分计算过程
(6)慢查询日志
PUT /_cluster/settings
{"transient": {"indices.indexing.slow_log.level": "TRACE","indices.indexing.slow_log.threshold.index.warn": "10s","indices.indexing.slow_log.threshold.index.info": "5s","indices.indexing.slow_log.threshold.index.debug": "2s","indices.indexing.slow_log.threshold.index.trace": "500ms"}
}
- 作用:开启慢查询日志,便于性能调优
(7)内存和GC监控
GET /_cat/thread_pool?v
- 作用:查看线程池使用情况
- 关键字段:
thread_pool:线程池名称active:活跃线程数queue:队列长度
(8)数据库优化建议
- 调整分片数量:避免单个分片过大
- 合理设置副本数:平衡可用性和性能
- 定期合并段:减少段数量,提高搜索性能
- 使用压缩:减少存储空间占用
这些命令和优化策略有助于提升 Elasticsearch 的稳定性和性能表现。
(9)POST _analyze 命令
命令用途
POST /_analyze
- 作用:分析文本如何被分词器处理,用于调试和验证分词逻辑。
- 适用场景:检查自定义分词器效果、验证文本分割结果。
请求格式
POST /_analyze
{"analyzer": "standard","text": "Elasticsearch is powerful"
}
参数说明
analyzer:指定使用的分词器名称(如standard,ik_max_word)。text:待分析的文本内容。tokenizer:可选,直接指定分词器(不使用完整 analyzer)。char_filter:可选,指定字符过滤器。filter:可选,指定词项过滤器。
返回结果示例
{"tokens": [{"token": "elasticsearch","start_offset": 0,"end_offset": 13,"type": "<ALPHANUM>","position": 0},{"token": "is","start_offset": 14,"end_offset": 16,"type": "<ALPHANUM>","position": 1},{"token": "powerful","start_offset": 17,"end_offset": 25,"type": "<ALPHANUM>","position": 2}]
}
使用场景
- 调试分词器:确认文本是否按预期分割。
- 优化搜索:调整分词策略以提高匹配准确率。
- 多语言支持:测试不同语言的分词效果。
提示:可通过
GET /_cat/indices?v查看索引的默认分词器配置。
10.介绍一下ES的过滤器?索引结构里的filter跟查询结构里的filter有什么不一样?
(1)mapping 中的 filter 字段
- 位置:在
analyzer的定义中,作为分词器处理流程的一部分 - 作用:对分词后的词项进行后处理,如小写转换、去除停用词等
- 关键参数:
lowercase:将所有词转换为小写,实现不区分大小写的搜索stop:移除常见无意义词汇(如 "the", "and")stemmer:提取词干,支持变体匹配(如 "running" → "run")
- 示例:
PUT /my_index
{"settings": {"analysis": {"analyzer": {"english_analyzer": {"tokenizer": "standard","filter": ["lowercase", "stop"]}}}}
}
(2)查询语句中的 filter 字段
- 位置:在查询结构中,如
bool查询的filter子句 - 作用:在搜索时应用筛选条件,不参与相关性评分计算
- 特点:
- 结果可缓存,提升重复查询性能
- 不影响文档得分
- 示例:
GET /my_index/_search
{"query": {"bool": {"must": {"match": {"title": "Elasticsearch"}},"filter": [{ "term": { "status": "active" } },{ "range": { "created_at": { "gte": "2023-01-01" } } }]}}
}
(3)主要区别
| 对比项 | mapping 中的 filter |
查询语句中的 filter |
|---|---|---|
| 作用阶段 | 索引创建时,处理文本分词 | 查询执行时,筛选文档 |
| 影响范围 | 分词器级别,影响所有文本 | 查询级别,影响特定查询结果 |
| 性能优化 | 提高搜索匹配准确性 | 结果缓存,提升查询速度 |
| 灵活性 | 固定配置,需重建索引修改 | 动态调整,无需重建索引 |
总结:
mapping中的filter是分词过程中的文本处理步骤,用于优化文本分析;查询语句中的filter是运行时的筛选条件,用于高效过滤结果。两者分别作用于索引构建和查询执行阶段,共同提升搜索系统的性能和准确性。
11.Completion suggester 和 MySQL的左匹配(有模糊)查询有什么差别?
(1)Completion Suggester
POST /my_index/_search
{"suggest": {"autocomplete": {"prefix": "elasticsearch","completion": {"field": "suggest_field"}}}
}
- 机制:基于前缀匹配,使用倒排索引加速
- 特点:
- 高性能:O(1) 时间复杂度
- 支持自动补全
- 适用于搜索框提示
- 适用场景:实时建议、自动补全
(2)MySQL 左匹配查询
SELECT * FROM products WHERE name LIKE 'elasticsearch%';
- 机制:使用 B+ 树索引进行前缀匹配
- 特点:
- 性能受索引影响
- 支持模糊匹配
- 适用于精确查找
- 适用场景:数据检索、报表查询
| 对比项 | Completion Suggester | MySQL 左匹配 |
|---|---|---|
| 数据结构 | 倒排索引 | B+ 树索引 |
| 性能 | 极高(毫秒级) | 较高(依赖索引) |
| 功能 | 自动补全、智能推荐 | 精确匹配、模糊查询 |
| 使用场景 | 搜索框提示 | 数据查询 |
| 扩展性 | 支持上下文建议 | 有限 |
总结:
Completion Suggester更适合实时交互场景,而 MySQL 左匹配更适合数据查询场景。
二、需求背景
1.功能性需求
在智能客服系统中,我们希望在用户端,可以实现用户在输入框输入内容时,支持实时联想,即弹出与输入相关性最高的几项问题内容列表,提供给用户选择。以此来帮助用户快速输入,引导用户提出其真正希望询问的内容,从而提升用户的体验感。另外,需要考虑支持多语言的问题联想,例如:英文、法语、阿拉伯语、中文等。
2.性能需求
在非功能需求层面,希望能最大程度做到近实时、响应快,但又不影响系统的稳定性。
注:用户问题联想 ≈ 实时预测用户输入意图并推荐相似的历史问题。
三、实现方案
1.基本思路
(1) 用户连续输入时,前端监听,只在最后一次停止输入后的一定时间内(例如设置为 300ms)向后台发起联想请求;
注:增加了防抖机制,避免用户请求过于频繁,影响系统的稳定性。
(2) 后台接收到请求后,基于联想的实现机制进行处理;
(3) 后台返回相关性最高的≤n条问题;
(4) 前端接收响应后,弹出问题列表,将接收到的问题内容显示在列表中。
2.方案选型
(1)方案一:关键词前缀匹配(搜索引擎式联想)
适用场景:
- 小型系统、FAQ 较少(< 万级)
- 实时性要求高
实现方式:
- 建一个 trie 树(前缀树)
- 数据库 LIKE 查询
- Elasticsearch 的 completion suggester
(2)方案二:关键词匹配(倒排索引)+ BM25
适用场景:
- 考虑多关键词计算得分和排序
- 命中率比前缀匹配高
实现方式:
- ES的match或multi_match(会对输入内容进行分词) + BM25 相关性得分排序
(3)方案三:语义向量匹配(Embedding 检索)
适用场景:
- 有较强语义匹配需求
- 用户输入和历史问题不完全一致
实现方式:
- 使用语义模型将 FAQ 和用户输入转成向量(比如 BERT、SimCSE、Sbert、ernie)
- 向量存储:Faiss / Milvus / ElasticSearch dense_vector
- 使用余弦相似度、内积等方式查询
(4)分析与结论
方案一的优点是查询速度快,但是对输入内容较苛刻,可能命中率较低;方案二的优点是命中率高,但不如前缀匹配快;方案三的优点是支持语义匹配,缺点是实现复杂度和成本较高。基于此,最终选择方案一和方案二的综合方案,具体方案设计如下:
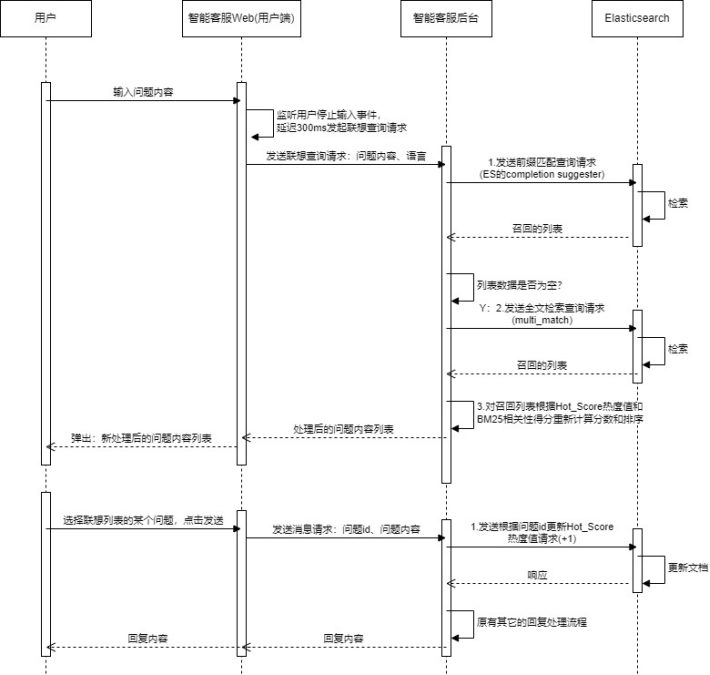
(1)为避免短时间内频繁的联想请求影响系统稳定性,前端需增加防抖机制即在用户停止输入后需延迟300ms(可根据实际效果调优);
(2)参照京东、百度的联想搜索效果,考虑先接入ES的completion suggester来实现前缀匹配效果(另外部分语言还考虑了支持容错效果,即个别字符差异也能召回相关数据),优势是性能高、响应快、支持容错;
(3)由于前缀匹配也存在弊端即随着输入内容越多,意味着匹配要求更精准和苛刻,则文档召回率可能比较低甚至无数据,所以此处考虑接入ES的multi_match来实现查询词分词,进行内容相关性匹配(另外中文还考虑了支持拼音检索即输入拼音也能查询对应的中文内容),以此作为兜底的方案,优势是能把高相关性的内容召回,缺点是全文检索不如前缀匹配效率高;
(4)最后为了提高搜索内容的相关性,此处引入了热度的机制,即用户提问的问题内容出现次数越多,则代表热度越高,越应该优先推荐给用户选择,这里使用的方案是新增热度字段的维护,最后搜索列表基于该文档热度和BM25(ES侧内部计算的相关性得分)进行排序。
3.方案实践
ES的安装和部署不再赘述,此处重点讲解如何基于ES的suggester和multi_match实现问题联想的功能效果。
(1)创建索引
PUT /faq_questions_multilang{"aliases": {// 给索引定义别名,代码统一使用索引别名进行操作,以便于后续需调整映射结构时支持零停机索引重建"faq_questions_alias": {}},"settings": {"analysis": {"filter": {"spanish_stemmer": {"type": "stemmer","language": "spanish"},"french_elision": {"type": "elision","articles": ["l", "m", "t", "qu", "n", "s", "j", "d"],"articles_case": true},"french_stem": {"type": "stemmer","language": "light_french"},"my_pinyin_filter": {"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": true,"limit_first_letter_length": 16,"remove_duplicated_term": true}},"analyzer": { // 中文分词器(需安装 IK 插件) "chinese_analyzer": { "tokenizer": "ik_max_word" // 使用最大化切词策略,适合搜索召回,例:“退款”会切出“退”、“款”、“退款” }, // 中文拼音分词器 "chinese_pinyin_analyzer": { "tokenizer": "ik_smart" , "filter": ["my_pinyin_filter"] }, // 英文分词器 "english_analyzer": { "tokenizer": "standard", // 默认标准分词器:按空格、标点等分词,保留完整英文单词 "filter": ["lowercase"] // 将所有词转换为小写,保证查询时不区分大小写 }, // 法语分词器(带词干还原和省略冠词) "french_analyzer": { "tokenizer": "standard", "filter": [ "lowercase", // 小写处理 "french_elision", // 去除常见的冠词缩写(如 l', d', j')避免误匹配 "french_stem" // 使用法语词干提取(如 "remboursement" → "rembours") ] }, // 阿拉伯语分词器(包含正则归一化) "arabic_analyzer": { "tokenizer": "standard", "filter": [ "lowercase", // 小写处理 "arabic_normalization" // 阿拉伯语正则归一化(如不同形式的 alef 合并) ] }, // 德语分词器(支持复合词处理) "german_analyzer": { "tokenizer": "standard", "filter": [ "lowercase", // 小写处理 "german_normalization", // 替换变形字符,例如 ß → ss "german_stem" // 提取词干,例如 “Kinder” → “Kind” ] }, // 西班牙语分词器(带词干处理) "spanish_analyzer": { "tokenizer": "standard", "filter": [ "lowercase", // 小写 "spanish_stem" // 提取词干,如 “preguntando” → “pregunt” ] }, // 日语分词器(需安装 kuromoji 插件,但 ES 6.0+ 通常已内置) "japanese_analyzer": { "type": "custom", // 明确声明为自定义 analyzer(非默认 standard) "tokenizer": "kuromoji_tokenizer" // 日语专用分词器,支持片假名、复合词、连词等 }, // 韩语分词器(需安装 nori 插件,但 ES 6.0+ 通常已内置) "korean_analyzer": { "tokenizer": "nori_tokenizer" // 韩语分词器,支持音节/词干识别、复合词分析 }}}},"mappings": {"properties": {"question_id": { "type": "keyword" // 问题唯一标识符,适合用于精确查找或业务主键},"language": { "type": "keyword" // 标记语言类型,例如 "zh"、"en"、"fr" 等,用于查询路由或聚合统计},"question_text": { "type": "text", // 问题主字段,子字段用于多语言分词和查询 "fields": { "zh": { "type": "text", "analyzer": "chinese_analyzer" // 中文查询使用 IK 分词器 }, "zh_pinyin": { "type": "text", "analyzer": "chinese_pinyin_analyzer" // 中文拼音查询 }, "en": { "type": "text", "analyzer": "english_analyzer" // 英文标准分词 + 小写处理 }, "fr": { "type": "text", "analyzer": "french_analyzer" // 法语专用分词 }, "ar": { "type": "text", "analyzer": "arabic_analyzer" // 阿拉伯语专用分词 }, "de": { "type": "text", "analyzer": "german_analyzer" // 德语专用分词 }, "es": { "type": "text", "analyzer": "spanish_analyzer" // 西班牙语专用分词 }, "jp": { "type": "text", "analyzer": "japanese_analyzer" // 日语专用分词 }, "ko": { "type": "text", "analyzer": "korean_analyzer" // 韩语专用分词 } }}}}}
(2)基于ES的completion suggester实现前缀查询
/*** 基于ES completion实现前缀匹配搜索,返回实体对象列表* @param indexName 索引名称* @param fieldName 建议字段名(格式:field.suggest)* @param prefix 前缀匹配字符串* @param size 返回建议数量* @param fuzziness 可编辑距离* @param prefixLength 必须前缀匹配的长度* @param minLength 最小匹配长度* @param transFunction true-支持字符调换,false-不支持* @param clazz 实体类Class对象* @param <T> 实体类型* @param preTags 高亮标签头* @param postTags 高亮标签尾* @return 匹配的实体对象列表*/public <T> List<T> getSuggestionsByPrefix(String indexName, String fieldName, String prefix, int size, int fuzziness,int prefixLength, int minLength, boolean transFunction, Class<T> clazz, String preTags, String postTags) throws Exception {try {SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 构建suggest查询FuzzyOptions.Builder fuzzyOptionsBuilder = new FuzzyOptions.Builder().setFuzziness(org.elasticsearch.common.unit.Fuzziness.fromEdits(fuzziness)).setFuzzyPrefixLength(prefixLength).setFuzzyMinLength(minLength).setTranspositions(transFunction);SuggestBuilder suggestBuilder = new SuggestBuilder();CompletionSuggestionBuilder completionSuggestionBuilder = SuggestBuilders.completionSuggestion(fieldName).prefix(prefix, fuzzyOptionsBuilder.build()).size(size).skipDuplicates(true);suggestBuilder.addSuggestion("faq_suggest", completionSuggestionBuilder);searchSourceBuilder.suggest(suggestBuilder);searchRequest.source(searchSourceBuilder);// 执行查询SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 解析结果Suggest suggest = searchResponse.getSuggest();CompletionSuggestion completionSuggestion = suggest.getSuggestion("faq_suggest");List<T> suggestions = new ArrayList<>();for (CompletionSuggestion.Entry entry : completionSuggestion.getEntries()) {for (CompletionSuggestion.Entry.Option option : entry) {// 输入内容未达到开启模糊的长度,则要求必须满足前缀匹配String text = option.getText().string();// regionMatches进行忽略大小写的前缀匹配boolean isPrefixMatch = prefix.length()>=minLength || text.regionMatches(true, 0, prefix, 0, prefix.length());;if (isPrefixMatch) {// 获取建议项的源数据并转换为实体对象Map<String, Object> sourceMap = option.getHit().getSourceAsMap();Float score = option.getScore();sourceMap.put("_score", score);// 设置高亮String highlightText = highlightTextIgnoreCase(sourceMap.get("question_text").toString(), prefix, preTags, postTags);sourceMap.put("highLightText", highlightText);T entity = JsonUtil.fromJson(JsonUtil.mapToJsonStr(sourceMap), clazz);if (entity != null) {suggestions.add(entity);}}}}return suggestions;} catch (Exception e) {Log.error("cmd=getSuggestionsByPrefix, msg=", e);throw e;}}/*** 忽略大小写的文本高亮方法* @param text 原始文本* @param prefix 需要高亮的前缀* @param preTags 高亮开始标签* @param postTags 高亮结束标签* @return 高亮后的文本*/private String highlightTextIgnoreCase(String text, String prefix, String preTags, String postTags) {if (text == null || prefix == null || prefix.isEmpty()) {return text;}// 查找匹配位置(忽略大小写)int startIndex = -1;String lowerText = text.toLowerCase();String lowerPrefix = prefix.toLowerCase();// 查找第一个匹配位置startIndex = lowerText.indexOf(lowerPrefix);// 如果找到匹配项,则在原始文本中进行高亮处理if (startIndex != -1) {StringBuilder result = new StringBuilder();// 添加匹配前的部分result.append(text, 0, startIndex);// 添加高亮标签result.append(preTags);// 添加原始大小写的匹配部分result.append(text, startIndex, startIndex + prefix.length());// 添加结束高亮标签result.append(postTags);// 添加匹配后的部分result.append(text.substring(startIndex + prefix.length()));return result.toString();}else {// 使用正则表达式进行忽略大小写的匹配和替换return text.replaceAll("(?i)" + java.util.regex.Pattern.quote(prefix),preTags + prefix + postTags);}}
(3)基于ES的multi_match实现分词查询
/*** 基于分词的全文检索方法* @param indexName 索引名称* @param queryText 查询文本* @param fields 搜索字段数组* @param operator 操作符("and" 或 "or")* @param size 返回结果数量* @param language 过滤语言* @param thresholdScore 最小得分阈值* @param clazz 实体类Class对象* @param <T> 实体类型* @param preTags 高亮标签头* @param postTags 高亮标签尾* @return 匹配的文档列表*/public <T> List<T> searchByMultiMatch(String indexName, String queryText, String[] fields, String operator, int size,String language, Float thresholdScore, Class<T> clazz, String preTags, String postTags) throws Exception{List<T> result = new ArrayList<>();try {// 创建搜索请求SearchRequest searchRequest = new SearchRequest(indexName);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 添加高亮设置HighlightBuilder highlightBuilder = new HighlightBuilder();boolean isContainPinyin = false;String pinyinField = "question_text.zh_pinyin";for (String field : fields) {highlightBuilder.field(field);highlightBuilder.preTags(preTags);highlightBuilder.postTags(postTags);// 要求高亮匹配必须在指定的字段中发生highlightBuilder.requireFieldMatch(true);if (pinyinField.equals(field)){isContainPinyin = true;}}searchSourceBuilder.highlighter(highlightBuilder);// 构建multi_match查询QueryBuilder multiMatchQuery = null;if (isContainPinyin) {// 拼音检索,保证拼音全称分词连续性及缩写完整的,相关性效果会更佳multiMatchQuery = getQueryBuilderByPinyin(queryText, fields, operator);}else {// 其它语言检索multiMatchQuery = QueryBuilders.multiMatchQuery(queryText, fields).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));}// 如果有语言参数,则添加语言等值判断条件if (StringUtil.isNotEmpty(language)) {BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().must(multiMatchQuery).filter(QueryBuilders.termQuery("language", language));searchSourceBuilder.query(boolQuery);} else {searchSourceBuilder.query(multiMatchQuery);}// 设置返回数量searchSourceBuilder.size(size);// 设置搜索请求searchRequest.source(searchSourceBuilder);// 执行搜索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 解析结果SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {Float score = hit.getScore();// 如果得分低于阈值,则跳过if (thresholdScore != null && score < thresholdScore) {continue;};// 获取高亮内容Map<String, HighlightField> highlightFields = hit.getHighlightFields();// 将高亮内容添加到返回结果中int index = highlightFields.get(fields[0])!=null?0:1;String highLightText = highlightFields.get(fields[index]).getFragments()[0].string();Map<String, Object> sourceMap = hit.getSourceAsMap();sourceMap.put("_score", score);sourceMap.put("highLightText", highLightText);T entity = JsonUtil.fromJson(JsonUtil.mapToJsonStr(sourceMap), clazz);if (entity != null) {result.add(entity);}}} catch (Exception e) {Log.error("cmd=searchByMultiMatch, msg=", e);throw e;}return result;}/*** 构建拼音检索的查询条件* @param queryText* @param fields* @param operator* @return*/private QueryBuilder getQueryBuilderByPinyin(String queryText, String[] fields, String operator) {// 组合查询:同时支持全拼和缩写BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 方式1:分词查询(支持全拼)QueryBuilder phraseQuery = QueryBuilders.multiMatchQuery(queryText, fields).type(MultiMatchQueryBuilder.Type.PHRASE).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));// 方式2:不分词查询(支持缩写)QueryBuilder keywordQuery = QueryBuilders.multiMatchQuery(queryText, fields).analyzer("keyword").operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));// 使用should组合,满足任一条件即可boolQuery.should(phraseQuery).should(keywordQuery);return boolQuery;}
四、FAQ
1.拼音搜索时,高亮会带上其它不相关词语?
问题现象
输入:
yinxiang
输出:
<span style='color:red;'>音响</span>一边<span style='color:red;'>没声音</span>;
问题描述:
yinxiang拼音对应命中的中文内容应该是“音响”,但是“没声音”这几个字符也被命中和高亮了
问题分析
1.确认“yinxiang”查询词的分词情况
yin、xiang
2.查看“一边音响没有声音”内容的分词情况
POST _analyze
{"tokenizer": "ik_smart","filter": [{"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": true,"limit_first_letter_length": 16,"remove_duplicated_term": true}],"text": "一边音响没声音" # ES存储的文本数据,按照上述的拼音分词机制得到以下的拼音分词
}
{"tokens" : [{"token" : "yi","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "yb","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "bian","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 1},{"token" : "yin", # 命中输入词“yinxiang”的分词“yin”,ES会对2-4位置内容(音响)进行高亮"start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 2},{"token" : "xiang", # 命中输入词“yinxiang”的分词“xiang”,ES会对2-4位置内容(音响)进行高亮"start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "yx","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 3},{"token" : "mei","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "sheng","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 5},{"token" : "yin", # 命中输入词“yinxiang”的分词“yin”,ES会对4-7位置内容(没声音)进行高亮"start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 6},{"token" : "msy","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 6}]
}
3.确认原因根据上述分析过程可以知道出现该问题的原因为:由于multi_match会对输入内容进行分词,所以当输入yinxiang时,输入词变成了yin和xiang,而ES文档里“一边音响没声音”经过拼音分词器分词会出现“yin”,其中一个对应位置为4-7,所以命中的该位置的“没声音”会被高亮。
解决方法
核心思想:在拼音检索时,不对输入的拼音内容进行分词,保证其在ES的文档分词内容里出现的连续性(例如,ES里的"yin"和"xiang"两个分词是连续的,同样会命中该输入词"yinxiang",最终会被召回)
解决方案:
方法一>>>>> 弊端:PHRASE查询虽然能保证输入内容分词的连续性,但是由于它依然会分词,所以在拼音缩写场景会召回失败(全拼效果可以)if (isContainPinyin) {// 拼音检索,使用短语查询,相关性效果会更佳multiMatchQuery = QueryBuilders.multiMatchQuery(queryText, fields).type(MultiMatchQueryBuilder.Type.PHRASE).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));}else {// 其它语言检索multiMatchQuery = QueryBuilders.multiMatchQuery(queryText, fields).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));}
方法二>>>>> 对查询词使用keyword,从而保证不会对其进行分词
if (isContainPinyin) {// 拼音检索,不对查询词分词(保证拼音全称或缩写均是完整的),相关性效果会更佳multiMatchQuery = QueryBuilders.multiMatchQuery(queryText, fields).analyzer("keyword").operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));}else {// 其它语言检索multiMatchQuery = QueryBuilders.multiMatchQuery(queryText, fields).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));}
方法三>>>>> 对上述两种方法进行整合,通过两种查询条件取或,保证拼音全拼或缩写均能成功召回
private QueryBuilder getQueryBuilderByPinyin(String queryText, String[] fields, String operator) {// 组合查询:同时支持全拼和缩写BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 方式1:分词查询(支持全拼)QueryBuilder phraseQuery = QueryBuilders.multiMatchQuery(queryText, fields).type(MultiMatchQueryBuilder.Type.PHRASE).operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));// 方式2:不分词查询(支持缩写)QueryBuilder keywordQuery = QueryBuilders.multiMatchQuery(queryText, fields).analyzer("keyword").operator(org.elasticsearch.index.query.Operator.valueOf(operator.toUpperCase()));// 使用should组合,满足任一条件即可boolQuery.should(phraseQuery).should(keywordQuery);return boolQuery;}解决效果
优化成果:输入yinxiang拼音全拼 或 yx拼音缩写,均能成功召回
{"code": 200,"message": "操作成功","data": {"preTags": "<span style='color:red;'>","postTags": "</span>","questionList": [{"questionId": "10092","content": "有源<span style='color:red;'>音响</span>与电脑<span style='color:red;'>音响</span>区","finalScore": 5.7144947,"hotScore": 10,"bmScore": 7.734992}]},"timestamp": 1759049396469,"requestId": null,"handleTime": null
}