此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第一课第二周的课程习题部分的讲解。
1.理论习题
【中英】【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验
这是本周理论部分的习题和相应解析,博主已经做好了翻译和解析工作,因此便不再重复,但有一题涉及到代码中矩阵的两种乘法,我们把这道题单独拿出看一下:
看一下下面的代码:
a = np.random.randn(3, 3)
b = np.random.randn(3, 1)
c = a * b
请问c的维度会是多少?
这便是这道题的内容,按照我们的学习的线代知识,我们应该会得到结果为 \((3,1)\) ,但实际上这道题的答案是 \((3,3)\)
这便涉及到在python代码中对矩阵的两类乘法,以题里的量为例:
c = a * b #Hadamard积(逐元素积)
c = a @ b #内积
这是两种不同的乘法,也会带来不同结果,我们用实际代码证明一下:
import numpy as np
# 定义矩阵 a 和列向量 b
a = np.array([[1, 1, 1],[1, 1, 1],[1, 1, 1]])
b = np.array([[1],[2],[3]])
# 逐元素乘法 (Hadamard积)
c_hadamard = a * b
print("Hadamard积结果 (a * b):")
print(c_hadamard)
print("Hadamard积的维度:", c_hadamard.shape)
# 矩阵乘法 (内积)
c_dot = a @ b
print("\n矩阵乘法结果 (a @ b):")
print(c_dot)
print("矩阵乘法的维度:", c_dot.shape)
直接看结果:
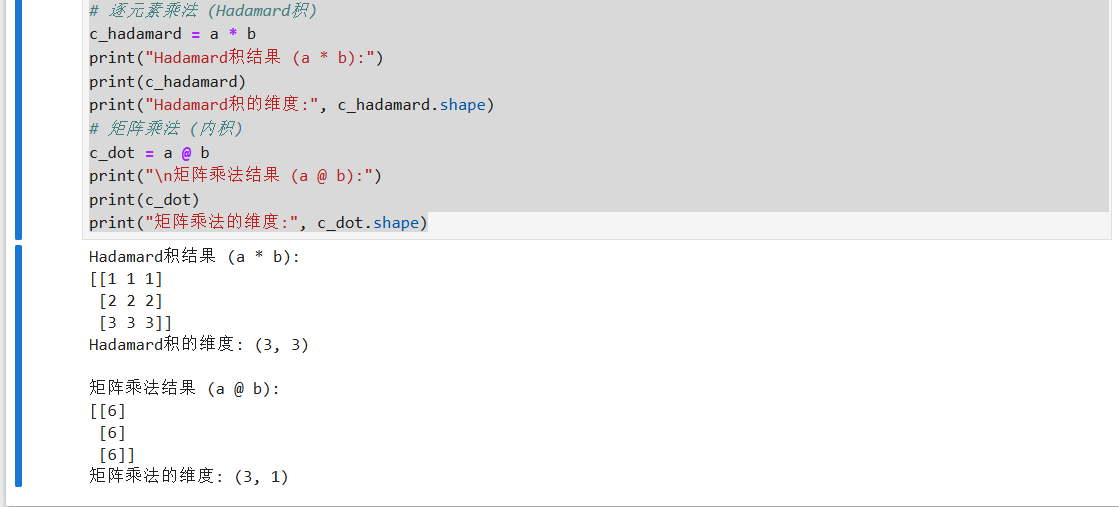
现在来解释一下,我们可以通过结果得知,我们在线代中学习的内积运算在代码中被定义为 \(@\)
而直接使用 \(*\) 符号来运算,实际上是对 \(*\) 前的矩阵的每个元素分别做乘法。
结合广播机制,我们可以知道 \(c = a * b\) 的实际运算过程是这样的:
- 经过广播机制, \(b\) 的内容以相同的形式向下复制两行,让维度和 \(a\) 一样变为 \((3,3)\)
- \(a和b\) 的相同位置相乘得到结果放入 \(c\) 的相同位置,用公式来说就是:
现在我们可以总结一下两种乘法的区别如下:
- \(@\) 是线代中的内积乘法,当两个矩阵的维度为\((m,n),(n,k)\) 即前一矩阵的列数等于后一矩阵的行数时才可进行运算,内积会改变矩阵的维度,结果矩阵的维度为 \((m,k)\)
- \(*\) 是逐个乘法,实际上是对 \(*\) 前的矩阵的每个元素分别做乘法,当两个矩阵使用逐个乘法运算时,python会自动将后一矩阵广播至前一矩阵大小,Hadamard积不会改变矩阵维度大小,结果矩阵和前一矩阵维度相同。
2.编程题:实现具有神经网络思维的Logistic回归
【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业
同样,这是整理了课程习题的博主的编码答案,其思路逻辑和可视化部分都非常完美,在不借助很多现在流行框架的情况下手动构建线性组合,激活函数等实现逻辑回归。
因此我便不再重复,这里给出我的另一个版本以供参考,会更偏向于使用目前普遍使用的框架和内置函数来构建模型,偏向展示一个较为通用的模型训练流程。
本次构建我们使用比较普遍的pytorch框架来实现这个模型,而配置pytorch环境在不熟悉的情况下可能会比较困难且繁琐,如果希望动手实操但还没有配置相关环境,这里我推荐按下面这位up主的视频过程配置pytorch环境来进行练习:
【2025年最新版】手把手教你安装PyTorch,用最简单的方式教你安装PyTorch_哔哩哔哩_bilibili
后面的课程笔记部分还会再介绍另一个主流框架:tensorflow
2.1 数据准备
使用猫狗二分类数据集,其下载地址为:猫狗图像分类数据集
数据集共2400幅图像,其优点为猫狗各1200幅,做到了样本均衡。
但缺点也存在,数据规模不大,且每幅图像大小不一,需要我们进行一定的预处理。
我们便以此数据集训练一个可以分类猫狗的Logistic回归模型。
2.2 代码逻辑
完整的代码会附在文末
2.2.1 导入所需库
我们来一个个看一看所需的库,并介绍它们所起的作用。
(1)torch
import torch # PyTorch 主库,提供张量计算和自动求导的核心功能
import torch.nn as nn # 神经网络模块,包含各种层和激活函数
import torch.optim as optim # 优化器模块,用于参数更新
from torch.utils.data import DataLoader, random_split #数据加载与划分工具
当我们看到这个导入格式时,可能会产生这样一个疑问:
既然已经在第一行已经导入了torch库,为什么我们还要再显式地导入torch的子模块?
对于这个问题,我们先简单解释一下python的导库语法。
- 直接导入库
import torch #import 库名:直接导入所需库
#这样导入后,我们就可以直接使用 torch.方法名(方法参数)来直接调用torch的方法。
x = torch.tensor([1, 2, 3]) #创建一个张量,张量同样是库定义的一种容纳矩阵等内容的数据结构,类似之前的numpy库。#同时,如果torch存在子模块,我们也可以用 torch.子模块名.子模块方法名(方法参数)的形式调用。
y = torch.nn.Sigmoid() #创建一个 Sigmoid 激活函数层,并把它赋值给变量 `y`。
- 逐层导入库的子模块
# 这种形式实际上是为了简化代码,先继续看上部分:
import torch
y = torch.nn.Sigmoid() #这是直接导入的调用方式import torch.nn as nn # import 库.模块名 as 别名
y = nn.Sigmoid() #这是导入子模块后的调用方式
#我们可以直接用 as 后我们为这个模块起的别名直接调用其方法。#!注意,如果不使用 as 即:
import torch.nn #这种方法和 import torch 的调用方式上没任何区别,相当于直接导入子模块。
y = torch.nn.Sigmoid()
- 直接导入库的子模块或方法
#这样其实也是进一步简化代码,也涉及打包时的优化
#按照之前的格式,我们先进行下面的导入
import torch.utils.data as data
loader = data.DataLoader(dataset, batch_size=32)
# DataLoader是 PyTorch 中用来加载数据的一个类,它能够高效地处理数据集的批次(batch)加载,并且支持多种数据加载策略
# DataLoader(数据集,批次大小):会根据数据集 `dataset` 和指定的 `batch_size` 来加载数据,并返回一个可迭代的对象#现在我们想进一步简化,就是这种形式:
from torch.utils.data import DataLoader
# from 上层模块 import 类或方法名
# 现在我们使用DataLoader的格式就是:
loader = DataLoader(dataset, batch_size=32)
以这样的几种导入格式,可以帮助我们实现较为精准的导入使用的模块或方法,实际上,这也是目前普遍的使用方法,甚至官方文档中使用的也是这种格式而非直接导入整个库。
(2)torchvision
from torchvision import datasets, transforms
# torchvision是一个与PyTorch配合使用的开源计算机视觉工具库,常用于计算机视觉领域的任务,如图像分类、目标检测、图像分割等
# datasets模块,包含了多种常用的计算机视觉数据集,自动下载并加载常见的数据集,并将其转换为torch.utils.data.Dataset格式
# transforms用于对图像进行预处理和数据增强。它提供了很多常见的图像转换操作,如缩放、裁剪、归一化、旋转等
(3)matplotlib
import matplotlib.pyplot as plt
# matplotlib是一个强大的绘图库,用于创建静态、动态和交互式的可视化图表。
(4) sklearn
from sklearn.metrics import accuracy_score
# sklearn 是进行机器学习任务时非常基础且实用的库。它支持从数据预处理到模型评估的全流程,涵盖了各种机器学习任务。
# metrics这个模块提供了许多用于评估机器学习模型性能的函数,特别是在分类任务中。
# accuracy_score用于计算分类模型的准确率(Accuracy),即正确预测的样本占所有样本的比例。
2.2.2 数据集预处理和划分
如果把训练完整的模型比作做菜,在导入所有所需库后,我们已经具备了构建模型的所有“厨具”。
而数据集,就相当于我们的“原料”。
这里也补充一下划分数据集的种类,一般,我们会把数据集划分为以下三部分:
- 训练集:用来训练模型的数据,帮助模型学习和调整参数。
- 验证集:用来调整模型超参数和优化模型的性能。
- 测试集:用来最终评估模型表现的数据,检查模型的泛化能力和真实世界的适应性。
注意,这里出现了一个之前没有提到过的概念:超参数
超参数是指在模型训练开始之前由人工设定的、用于控制模型结构或学习过程的参数。与通过反向传播算法自动学习得到的模型参数(如权重、偏置)不同,超参数不会在训练过程中被更新,而是由研究者或工程师在实验中通过经验、搜索或验证集性能调优得到。
常见的超参数包括学习率、批大小、训练轮数、网络层数、正则化系数、激活函数类型等,这些我们定义的量是通过在验证集上的结果来不断调优的。
继续用做菜的例子来说的话,训练集让模型“学会做菜”, 验证集让模型“做得更好吃”, 测试集让我们知道“这道菜到底好不好吃”。
补充了一些基础知识后,我们现在继续实操部分,先看一下数据集的存储结构:
可以看到,我只是用两个文件夹分别存放两类的图像,并没有在这里就划分训练集,验证集和测试集。
而且还有一个问题,那就是图片的大小不一,深度学习模型要求每个输入样本的尺寸、通道数完全一致,如果输入图片大小不一致,很多操作无法统一处理,导致特征提取混乱。
网上对构建模型有这样一个戏称:赛博接水管,不无道理,我们在输入前,一定要对样本进行预处理,处理完的样本要和“输入水管”的管口严丝合缝,不能大也不能小,而具体训练过程中也有其他体现。
Pytorch自然提供了相应方法:
# transforms.Compose的作用是将多个图像变换操作串联起来,形成一个“流水线”,这样每张图片在被加载时会依次执行这些操作。
transform = transforms.Compose([ transforms.Resize((128, 128)), # 统一图片尺寸为(128,128) transforms.ToTensor() # 转为Tensor张量 [通道数,高,宽]transforms.Normalize((0.5,), (0.5,)) # 标准化,把像素映射到(-1,1)防止梯度消失
])
#我们可以把transforms.Compose的返回值transform看作一个函数,输入图片,输出图片经过这些处理后的结果。
# ToTensor()这一步不能省略,因为pytorch框架只接受它定义的张量结构作为输入,我们要初步使用框架,就要遵守它定义的规则。
#没有 Normalize,输入在 [0,1],非常大(120000 维每维 0~1)累加后,Linear 输出可能很大导致输出接近于1,从而让梯度消失。
这样,我们就完成了预处理部分。要说明的是,这里我们仅做了一个大小统一,转化为张量的操作,在实际训练中,可能还有更多预处理的内容,我们遇到再说。
一般来说,预处理代码就是跟在导库后的第一部分内容。
在其之后的下一步,就是载入和划分数据集,来继续看:
# 加载整个数据集
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
# ImageFolder是一个图像数据集加载器,能够自动读取一个按照文件夹结构分类的图像数据集。
# 两个参数 root即为数据集存放文件夹路径,transform即为刚刚的预处理函数,在这里作为参数自动应用于加载的每个样本。
# ImageFolder会自动读取文件夹,并以文件夹名作为分类标签标注文件夹里的内容,这里就会自动将图片分为猫狗两类。
# 最后我们得到的返回值dataset是一个数据集对象,每一项都是(图片的张量表示, 标签)的形式# 先设置各部分大小
total_size = len(dataset)
train_size = int(0.8 * total_size) # 80% 训练集
val_size = int(0.1 * total_size) # 10% 验证集
test_size = total_size - train_size - val_size # 10% 测试集# 按设置好的比例随机划分
# 这里的随机是指对某张图分入哪部分的随机,并非比例随机
train_dataset, val_dataset, test_dataset = random_split(dataset=dataset, lengths=[train_size, val_size, test_size]
)
# random_split可以把一个数据集对象随机拆分成若干个子数据集。
# 两个参数 dataset即为待拆分数据集,lengths即为每个子数据集的大小
# 最后的返回train_dataset, val_dataset, test_dataset就是划分好的训练集,验证集和测试集。# 定义批量数据迭代器
# 这里干的实际上是我们之前说了很久的向量化。
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# DataLoader 三个参数,第一个即为要处理的数据集,batch_size是批次大小,就是我们向量化里的m
# shuffle=True 表示每个 epoch 开始前,会随机打乱数据集的顺序,防止模型按固定顺序学习
# 最后我们得到三个迭代器,即可用于各部分的输入,DataLoader 加载数据时,会把多个样本堆叠成 batch,即[批次,通道数,高,宽]
要说明的一点是,我们之前在理论部分的讲解中的一次处理所有样本,就是把这里的batch_size设置为训练集大小,而我们处理完整个训练集一次是一个轮次(epoch)。
这样,一个epoch就会进行一次传播。
而实际上,batch_size通常小于训练集大小,而一个批次(batch)便会传播一次,因此,在这种情况下,一个epoch就会进行多次传播。
2.2.3 模型构建
这便是最核心的部分了,我们用一个类来实现模型的架构,如果类的规模较大,我们会单独创建文件存放模型类。类定义一般会包含两类方法:
- 初始化方法:这个模型里有什么(层级,激活函数等)
- 向前传播方法:输入进入模型后怎么走
来看代码:
class LogisticRegressionModel(nn.Module):
# 类继承自nn.Module,是 PyTorch 所有模型的基类#初始化方法def __init__(self): super().__init__() #父类初始化,用于注册子模块等,涉及源码,这里当成固定即可。 self.flatten = nn.Flatten() #把张量后三维展平为一维(通道C*高H*宽W)self.linear = nn.Linear(128 * 128 * 3, 1) # 输入是128x128x3,输出1个加权和# nn.Linear接受的是二维输入[batch_size, features],这里是[32,128 * 128 * 3]# 但Linear层不需要在参数里写 batch 维度,它内部会自动处理批量输入,只关心每个样本的特征数和每个样本输出的维度,这也是广播机制的应用。self.sigmoid = nn.Sigmoid() #激活函数#向前传播方法def forward(self, x): # 现在,x的维度是[32,3,128,128]x = self.flatten(x) #1.展平# 现在,x的维度是[32,128 * 128 * 3]x = self.linear(x) #2.过线性组合得到加权和# 现在,x的维度是[32,1]x = self.sigmoid(x) #3.过激活函数得到输出# 现在,x的维度是[32,1]return x
定义完成模型类后,我们便可以将其实例化并加以使用。
2.2.4 设备选择
model = LogisticRegressionModel() #实例化模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #自动选择CPU或者GPU
model.to(device) #模型的所有参数(权重、偏置)都会存放在对应设备里。
我们都知道CPU就像计算机的“大脑”,但在深度学习的模型训练领域中,反而GPU更常用,尤其是在较大的模型训练中,GPU 是深度学习的“加速引擎”,它用大量并行核心,把神经网络训练和推理中重复、耗时的矩阵运算做得又快又高效,所谓的“租用服务器让模型跑快点”,实际上就是利用服务器的较先进的GPU。
2.2.5 损失函数和优化器
我们同样使用内置函数来定义这两部分:
criterion = nn.BCELoss() # 二分类的交叉熵损失。
optimizer = optim.SGD(model.parameters(), lr=0.01) #梯度下降法,每个批次传播一次。
# SGD 两个参数 model.parameters()即为模型的所有参数:权重,偏置等。
# lr即为学习率。
2.2.6 训练和验证
这部分的逻辑较为复杂,主要思路就是遍历轮次和批次来进行传播,并记录相应量用于后续画图。
# 定义训练的总轮数
epochs = 10 # 表示训练整个数据集的次数
train_losses = [] # 用于记录每个epoch的训练损失,便于可视化
val_accuracies = [] # 用于记录每个epoch验证集准确率,便于可视化# 开始训练循环,每个epoch表示遍历完整个训练集一次
for epoch in range(epochs): model.train() # 设置模型为训练模式epoch_train_loss = 0 # 用于累计该epoch的总训练损失# 遍历训练集DataLoader,每次获取一个batchfor images, labels in train_loader: # images: Tensor, 形状 [32, 3, 128, 128]# labels: Tensor, 形状 [32]images, labels = images.to(device), labels.to(device).float().unsqueeze(1)# .to(device): 将张量移动到GPU或CPU# .float(): 将标签转为float类型,因为BCELoss要求输入为浮点数# .unsqueeze(1): 在第1维增加一维,使labels形状变为 [32, 1],与输出匹配# 前向传播:输入图片,计算模型预测输出outputs = model(images) # 调用模型的forward方法,返回 [32, 1]#官方推荐这样的形式,实际上相当于model.forward(images)loss = criterion(outputs, labels) # 计算二分类交叉熵损失,输出标量Tensor# 反向传播与参数更新optimizer.zero_grad() # 清空上一次梯度,避免梯度累加loss.backward() # 自动求梯度,计算每个参数的梯度optimizer.step() # 根据梯度更新参数,完成一次优化步骤# 累计损失,用于计算平均训练损失epoch_train_loss += loss.item() # .item():将单元素Tensor转为Python浮点数,便于记录# 计算该epoch的平均训练损失avg_train_loss = epoch_train_loss / len(train_loader)train_losses.append(avg_train_loss) # 保存到列表,用于后续绘图# 验证集评估准确率model.eval() # 设置模型为评估模式val_true, val_pred = [], [] # 用于记录验证集真实标签和预测标签with torch.no_grad(): # 禁用梯度计算,节省显存和计算量for images, labels in val_loader: # 遍历验证集images = images.to(device) # 移动到GPU/CPUoutputs = model(images) # 前向传播得到预测概率preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten()# outputs.cpu().numpy(): 移动到CPU并转为numpy数组# numpy不用导入,这是PyTorch 内部实现的桥接接口# 要用到scikit-learn、matplotlib 等库计算或可视化,这些库只接受 CPU 数据# > 0.5: 将概率转换为0/1预测# .astype(int): 把布尔值 True/False 转为整数 1/0# .flatten(): 将二维数组展平成一维val_pred.extend(preds) # 将预测结果加入列表val_true.extend(labels.numpy()) # 将真实标签加入列表# 使用sklearn计算验证集准确率val_acc = accuracy_score(val_true, val_pred)val_accuracies.append(val_acc) # 保存准确率,用于绘图# 打印该epoch的训练损失和验证集准确率print(f"轮次: [{epoch+1}/{epochs}], 训练损失: {avg_train_loss:.4f}, 验证准确率: {val_acc:.4f}")# {变量:.4f}表示保留4位小数2.2.7 可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置全局字体为黑体(SimHei),支持中文显示
# plt.rcParams 是 Matplotlib 的全局参数字典,可修改默认样式
plt.rcParams['axes.unicode_minus'] = False
# 设置 False 表示允许正常显示负号# 绘制曲线
plt.plot(train_losses, label='训练损失')
# 绘制训练集损失曲线
# plt.plot(y, label=...) 用于绘制折线图,label 用于图例说明
plt.plot(val_accuracies, label='验证准确率')
# 作绘制验证集准确率曲线# 设置标题与坐标轴
plt.title("训练损失与验证准确率随轮次变化图") # 设置图表标题
plt.xlabel("训练轮次(Epoch)") # 设置横轴标题
plt.ylabel("数值") # 设置纵轴标题plt.legend() # 显示图例,用于区分不同折线
# plt.legend() 会显示各 plt.plot() 的 label 内容
plt.grid(True) # 开启网格显示
plt.show() # 显示绘制的图形窗口
2.2.8 最终测试
在最后用测试集进行评估之前,其实应该有根据训练集对超参数进行调优的过程,但由于目前的篇幅已经较长了,我们先看完流程,我会在最后再附上一个使用方格调优版本的代码。
# 模型评估(测试集)
model.eval()
y_true, y_pred = [], []
# 定义两个空列表,用于存储测试集的真实标签与预测标签
with torch.no_grad():for images, labels in test_loader:images = images.to(device)outputs = model(images)preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten()y_pred.extend(preds)y_true.extend(labels.numpy())
acc = accuracy_score(y_true, y_pred)
print(f"测试准确率: {acc:.4f}")
可以发现,验证集和测试集的代码部分几乎没有差别,二者的主要差别在于它们起到的作用上。
2.3 结果分析
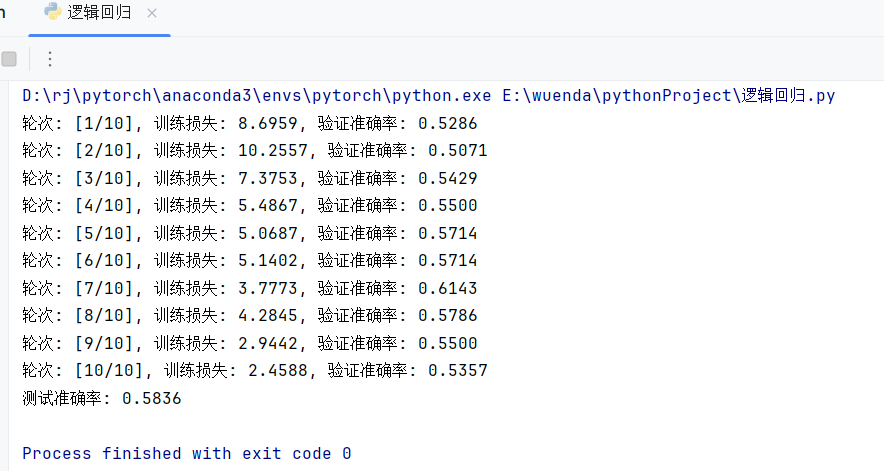
这是这个模型的结果,可以发现准确率不高,只有一半左右。
而造成这个结果的因素是多样的:
- 数据集规模不大,图片大小不一。
- 预处理简单,可能造成失真。
- 模型结构简单,拟合能力不强
- 没有对超参数进行较详细地调优
此外,还有其他影响因素。
而下面便是可视化部分的代码结果:
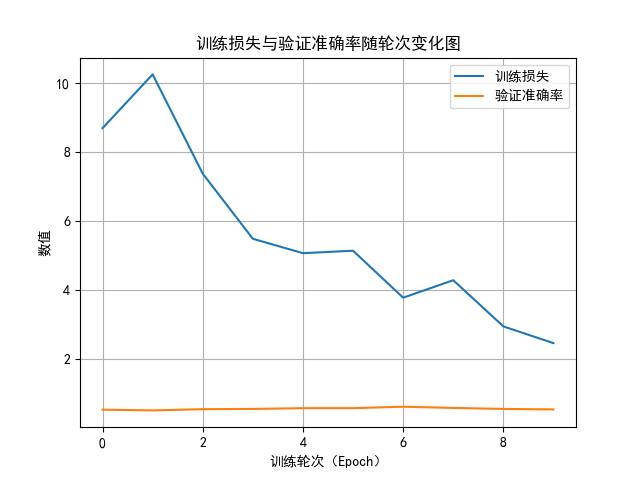
我们可能会发现这样一个问题:按照梯度下降法的思路,损失值应该一直下降才对,为什么反而会有升高的反复现象?
其实,这是一个非常常见的现象。
虽然梯度下降的理论目标是不断让损失函数下降,但在实际训练中,损失值并不会严格单调递减,原因主要有以下几点:
- 每次迭代并不是用全部数据计算梯度,而是用一个小批量,不同批次的数据分布略有差异,会导致梯度方向有波动,因此损失可能短暂上升。
- 如果学习率偏大,每次更新的步长过长,可能会“越过”最优点,使损失出现震荡。
- 即使是简单模型,在高维空间中损失函数也可能存在多个局部极小值和鞍点,训练过程可能会在这些区域间来回波动。
换句话说,总体趋势下降才是关键,出现轻微的上升是正常现象,不代表模型没有学习。
我们本篇的主要目的还是展示模型构建的过程,在之后的课程学习里,会涉及更多更复杂的算法,函数与优化等,我们到时使用其再来试试在猫狗二分类数据集上的分类效果。
最后,完整代码如下:
- 示例版本:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score transform = transforms.Compose([ transforms.Resize((200, 200)), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform) train_size = int(0.7 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) class LogisticRegressionModel(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.linear = nn.Linear(200 * 200 * 3, 1) # 输入200x200x3像素 self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.flatten(x) x = self.linear(x) x = self.sigmoid(x) return x model = LogisticRegressionModel()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01) epochs = 10
train_losses = []
val_accuracies = [] for epoch in range(epochs): model.train() epoch_train_loss = 0 for images, labels in train_loader: images, labels = images.to(device), labels.to(device).float().unsqueeze(1) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() epoch_train_loss += loss.item() avg_train_loss = epoch_train_loss / len(train_loader) train_losses.append(avg_train_loss) model.eval() val_true, val_pred = [], [] with torch.no_grad(): for images, labels in val_loader: images = images.to(device) outputs = model(images) preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten() val_pred.extend(preds) val_true.extend(labels.numpy()) val_acc = accuracy_score(val_true, val_pred) val_accuracies.append(val_acc) print(f"轮次: [{epoch+1}/{epochs}], 训练损失: {avg_train_loss:.4f}, 验证准确率: {val_acc:.4f}") plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False plt.plot(train_losses, label='训练损失')
plt.plot(val_accuracies, label='验证准确率')
plt.title("训练损失与验证准确率随轮次变化图")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show() model.eval()
y_true, y_pred = [], []
with torch.no_grad(): for images, labels in test_loader: images = images.to(device) outputs = model(images) preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten() y_pred.extend(preds) y_true.extend(labels.numpy())
acc = accuracy_score(y_true, y_pred)
print(f"测试准确率: {acc:.4f}")
- 加入方格搜索优化超参数的版本:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
from sklearn.metrics import accuracy_score
import itertools transform = transforms.Compose([ transforms.Resize((128, 128)), transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))
]) dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size]) class LogisticRegressionModel(nn.Module): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.linear = nn.Linear(128 * 128 * 3, 1) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.flatten(x) x = self.linear(x) x = self.sigmoid(x) return x device = torch.device("cuda" if torch.cuda.is_available() else "cpu") param_grid = { 'lr': [0.01, 0.001], 'batch_size': [16, 32], 'num_epochs': [5, 10]
} best_acc = 0
best_params = None for lr, batch_size, num_epochs in itertools.product(param_grid['lr'], param_grid['batch_size'], param_grid['num_epochs']): print(f"当前超参数: 学习率={lr}, 批次大小={batch_size}, 总轮次={num_epochs}") train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) model = LogisticRegressionModel().to(device) criterion = nn.BCELoss() optimizer = optim.SGD(model.parameters(), lr=lr) for epoch in range(num_epochs): model.train() epoch_loss = 0 for images, labels in train_loader: images, labels = images.to(device), labels.to(device).float().unsqueeze(1) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() epoch_loss += loss.item() avg_loss = epoch_loss / len(train_loader) model.eval() y_val_true, y_val_pred = [], [] with torch.no_grad(): for images, labels in val_loader: images = images.to(device) outputs = model(images) preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten() y_val_pred.extend(preds) y_val_true.extend(labels.numpy()) val_acc = accuracy_score(y_val_true, y_val_pred) print(f"轮次 {epoch+1}/{num_epochs}, 损失: {avg_loss:.4f}, 验证准确率: {val_acc:.4f}") if val_acc > best_acc: best_acc = val_acc best_params = {'lr': lr, 'batch_size': batch_size, 'num_epochs': num_epochs, 'model_state_dict': model.state_dict()}
print(f"\n最佳验证准确率: {best_acc:.4f} 超参数设置: {best_params}")
best_model = LogisticRegressionModel().to(device)
best_model.load_state_dict(best_params['model_state_dict'])
best_model.eval()
y_test_true, y_test_pred = [], []
with torch.no_grad(): for images, labels in test_loader: images = images.to(device) outputs = best_model(images) preds = (outputs.cpu().numpy() > 0.5).astype(int).flatten() y_test_pred.extend(preds) y_test_true.extend(labels.numpy()) test_acc = accuracy_score(y_test_true, y_test_pred)
print(f"使用最优超参数的测试准确率: {test_acc:.4f}")