1. 论文介绍
论文题目:Less is More on the Over-Globalizing Problem in Graph Transformers
论文领域:图神经网络,graph transformer
论文发表: ICML 2024
论文代码:https://github.com/null-xyj/CoBFormer
论文背景:

2. 论文摘要
图变换器(graphtransformer)由于其全局注意机制,成为处理图结构数据的新工具。在全连通图中,全局注意机制考虑了一个更宽的感受域,这使得许多人相信可以从所有节点中提取有用的信息。在本文中,我们挑战这个信念:是否全球化的性质总是有益于图变压器?本文通过实证和理论分析揭示了图变换中的过度全球化问题,即当前的注意机制过分关注那些距离较远的节点,而包含大部分有用信息的距离较近的节点相对较弱。然后提出了一种新的具有协同训练的双层全局图变换器(CoBFormer),该变换器包括簇间变换器和簇内变换器,在保持从远程节点提取有价值信息的能力的同时,避免了过度全球化问题。同时,提出了协同训练的方法,为提高模型的泛化能力提供了理论保证。在各种图上的大量实验很好地验证了我们提出的协同变换器的有效性。
3. 相关介绍
3.1 背景介绍
GNN的缺点:因为其堆叠会导致过度平滑和过度挤压的问题,他们的关注力是在邻居
transformer是: 因为其全局注意力机制,表现出了卓越的表达能力。
给出本文的核心研究问题:针对Graph Transformer架构的全局注意力是否总是有效的。
全局的注意力架构可表述为

结论:
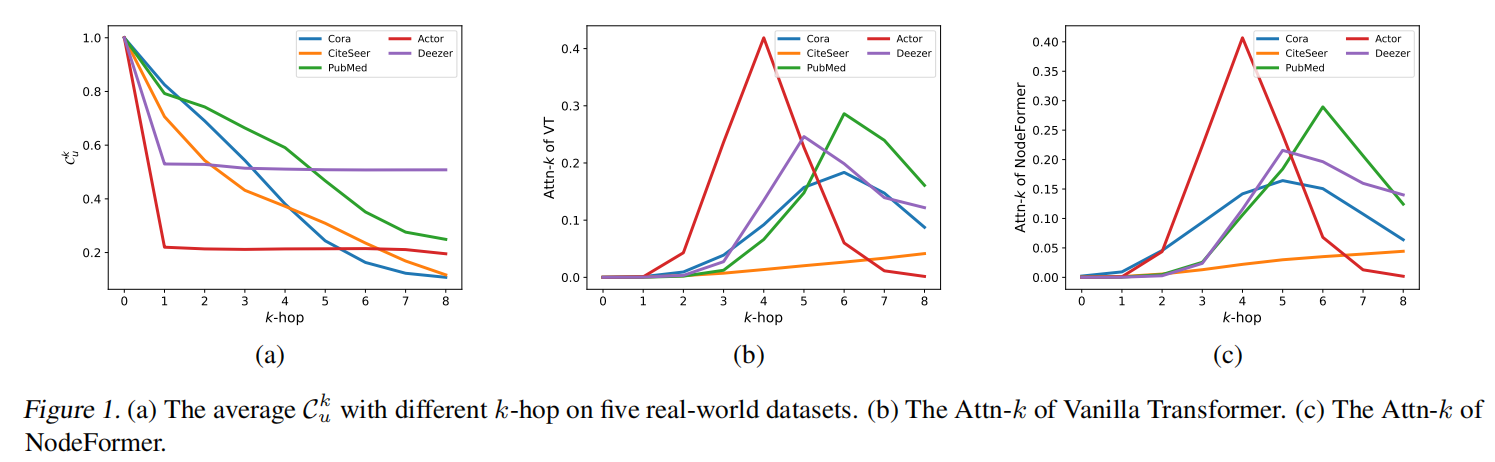
从实证上发现,所有节点对的学习注意力分数分布与实际信息节点的分布之间存在不一致,即全局注意力机制倾向于关注高阶节点,而有用信息往往出现在低阶节点上。
尽管高阶节点可能会提供额外的信息,但当前的注意力机制过于关注这些节点。从理论上讲,我们证明了过度扩展的感受野会降低全局注意力机制的有效性,进一步暗示了过度全局化问题的存在。
针对全局注意力在图上的缺陷的问题,
如何改进当前的全局注意力机制,防止 Graph Transformers 中过度全局化的问题,同时仍然保持从高阶节点提取有价值信息的能力?
已有的研究的方法:可以通过隐式或显式集成本地模块(例如 GNN)来补充图转换器来缓解这个问题。
3.2 过度全局化问题
仔细研究注意力分数的分布,以研究注意力机制捕获的信息。
定义了与节点共享相同标签的第 k 跳邻居的比例为
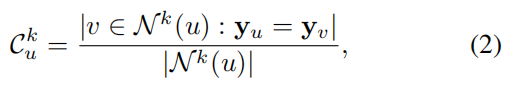
将分配给第 k 跳邻居的平均注意力分数表示为 Attn- k,定义为
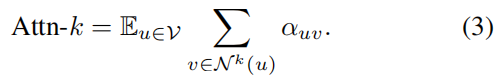
在数据Cora,Actor等数据集上的值随着k跳变化的变化,分析了不同跳数的邻居对应的C值
3.3 论文贡献
(1)首先展示了一个关键现象:Graph Transformer通常会产生节点分类注意力机制的过度全局化问题。理论分析和实证证据都表明,这个问题将从根本上影响Graph Transformer。我们的发现提供了一个视角,为图转换器的改进提供了宝贵的见解。
(2)提出了 CoBFormer,一个具有协作训练的双级全局图转换器,它有效地解决了过度全局化的问题。理论分析表明,我们提出的协同训练将提高模型的泛化能力。
(3)大量实验表明,CoBFormer 的性能优于最先进的图转换器,并有效解决了过度全局化问题。
4. CoBFormer
CoBFormer算法的整个算法框架为
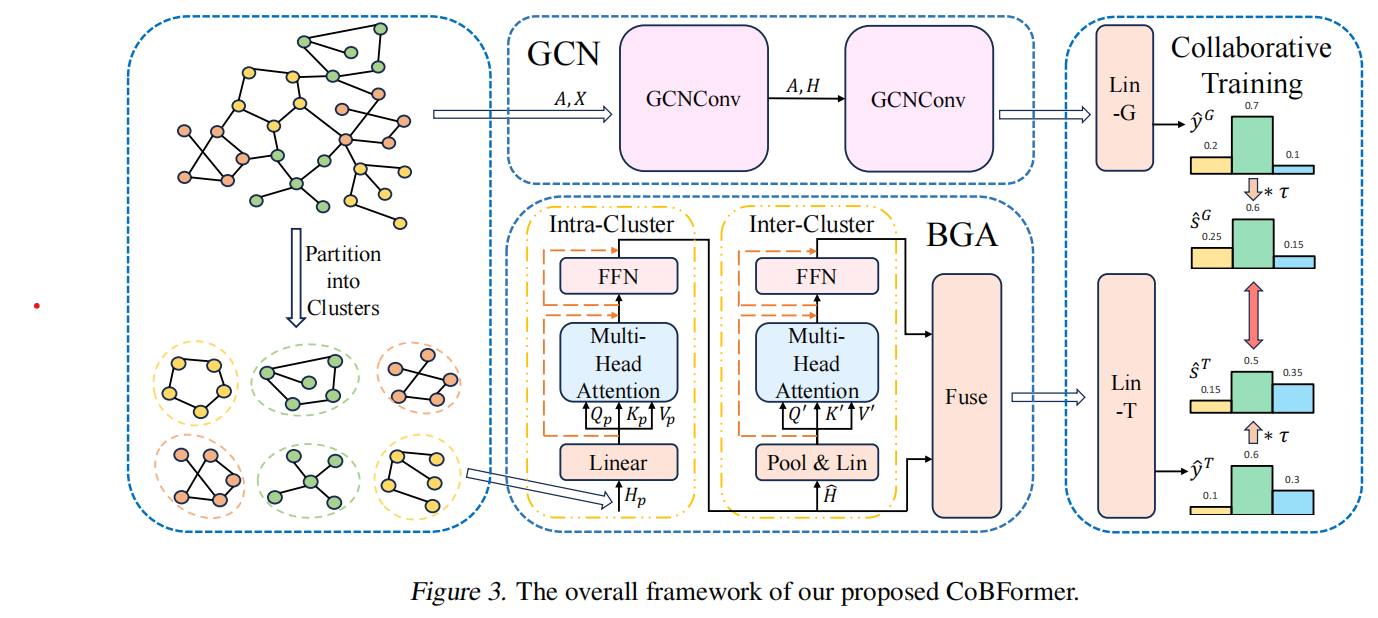
大概步骤:
(1)首先使用 METIS 算法将图划分为不同的聚类。
(2)提出了双级全局注意力(BGA)模块,该模块由集群内 Transformer 和集群间 Transformer 组成。该模块通过解耦集群内和集群间的信息,有效地缓解了过度全局化问题,同时保持了全局的接受能力。为了捕获 BGA 模块忽略的图结构信息,采用图卷积网络(GCN)作为局部模块。
(3)提出了协同训练,以整合 GCN 和 BGA 模块所学到的信息,提高其性能。
4.1 双级全局注意力模块
聚类类内部的tranformer架构为
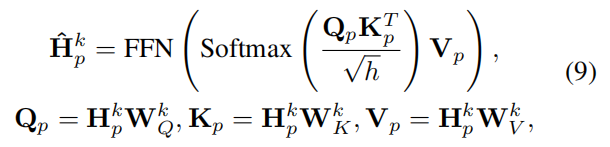
聚类类间的tranformer架构为

$𝐇_p^k$ 对于 和 $𝐏^k$ ,我们将节点表示与其相应的聚类表示连接起来,并 $𝐇_p^{k+1}$ 使用参数化为以下的 $𝐖_f$ 融合线性层计算输出节点表示:
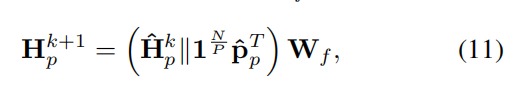
4.2 协同训练
使用两个线性层 Lin-G 和 Lin-T 将 GCN 和 BGA 模块的输出映射到标签空间
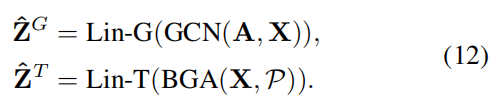
使用 SoftMax 函数来计算预测标签和软标签
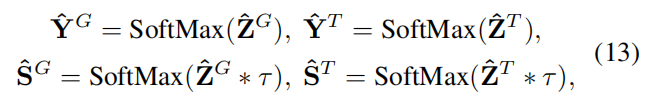
5. 实验设置
数据集采用同质图数据集有 Cora,CiteSeer,PubMed,Ogbn-Arxiv,Ogbn-Products。
异质图数据集有:Actor,Deezer。
对比基线:
两个经典的GNN:GCN和GATE
三个最先进的graph Tranformer:NodeFormer,NAGphormer,BGA算法
节点分类实验数据,评价标准采用Micro-F1和Macro-F1作为评价指标
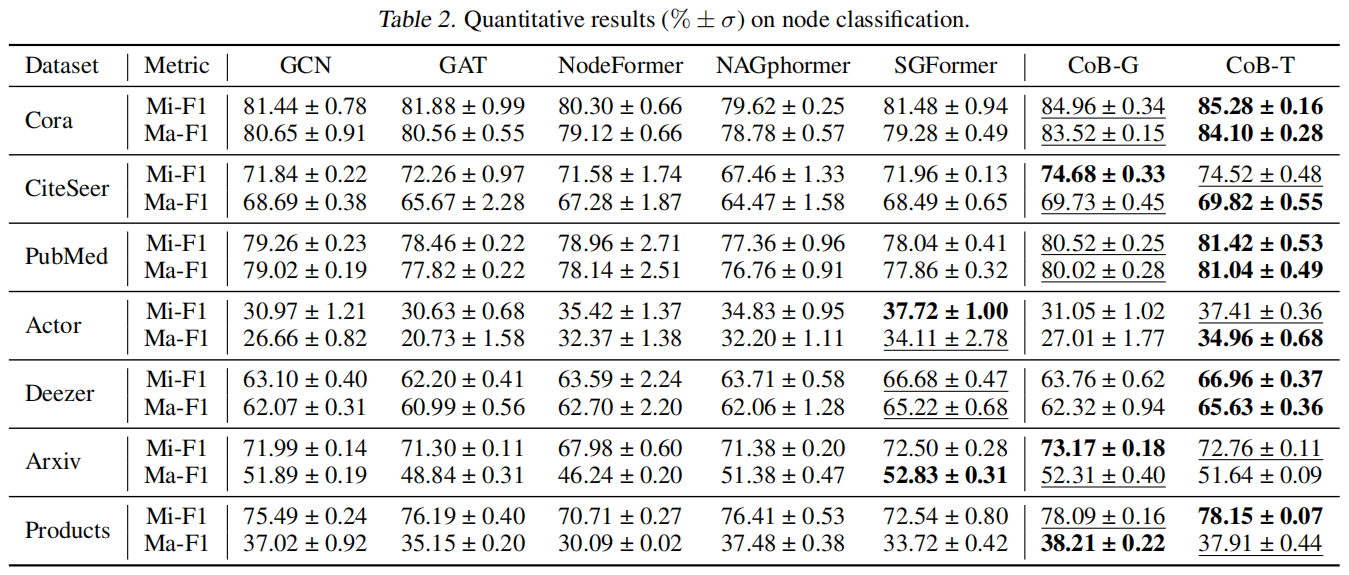
实验结论:
(1)CoBFormer 的 GCN 和 BGA 模块在同质图中都大幅优于所有基线,证明了 CoBFormer 的有效性。
(2)在异质图中,我们的 BGA 模块的性能可与最佳基线 SGFormer 相媲美,甚至超过。这表明我们的 BGA 模块可以成功捕获全局信息。
(3)与 GCN 和 GAT 相比,传统图转换器在异质图上表现出优异的性能。
消融实验
以评估 CoBFormer 的两个基本组件:BGA 模块和协作训练方法

(1) 无论是否使用协作训练,我们的 BGA 模块的准确性在所有数据集上的准确性始终优于普通的全球关注度,这证明了我们 BGA 模块的有效性。
(2)协同训练导致 GCN 和 BGA 模块的精度显著提高,表明它通过鼓励互学习增强了模型的泛化能力。
(3)BGA 模块大幅减少 GPU 内存,解决可扩展性问题。
解决过度全局化的能力

6. 总结
CoBFormer算法的创新点有两个,一个是METIS聚类,一个协同训练。同时在局部和全局进行transformer操作,有点bagging的意思。
7. 个人感悟
个人看起来注意力架构在graph tranformer领域中优化的已经挺深入了。