3. Ollama 安装,流式输出,多模态,思考模型
@
- 3. Ollama 安装,流式输出,多模态,思考模型
- 接入ollama本地模型
- 本地大模型安装
- 基于spring-ai使用 上我们在 Ollama 本地模型部署的大模型
- 关闭 thingking
- ollama 流式输出
- 多模态
- 接入ollama本地模型
- 最后:
接入ollama本地模型
ollama是大语言模型的运行环境 , 支持将开源的大语言模型以离线的方式部署到本地,进行私有化部署。 这也是企业中常用的方案, 因为本地化部署能保证企业级的数据安全, 降低企业使用成本。
可以将我们的 ollama 理解为是我们的 Docker 容器(Docker 拉取的是镜像),而 Ollama 拉取的就是大模型的镜像,同时运行大模型
本地大模型安装
-
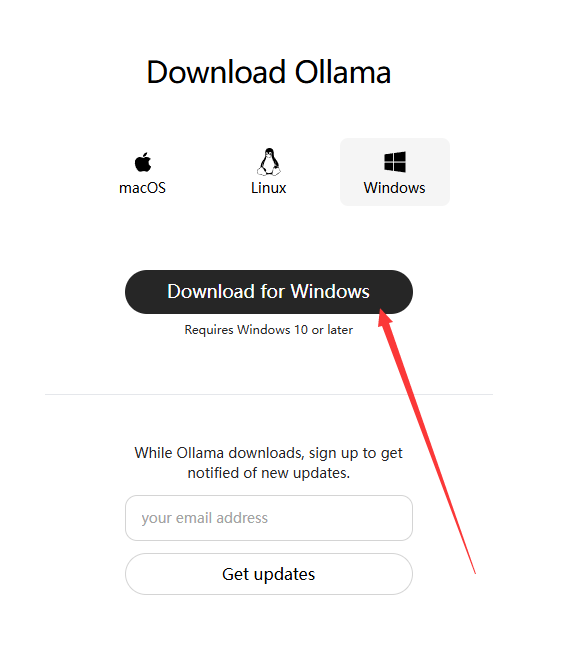
https://ollama.com/download
-
点击下载, 一直下一步即可非常简单
- 安装完后运行cmd --> ollama list 查看已安装的大模型(开始肯定什么都没有)
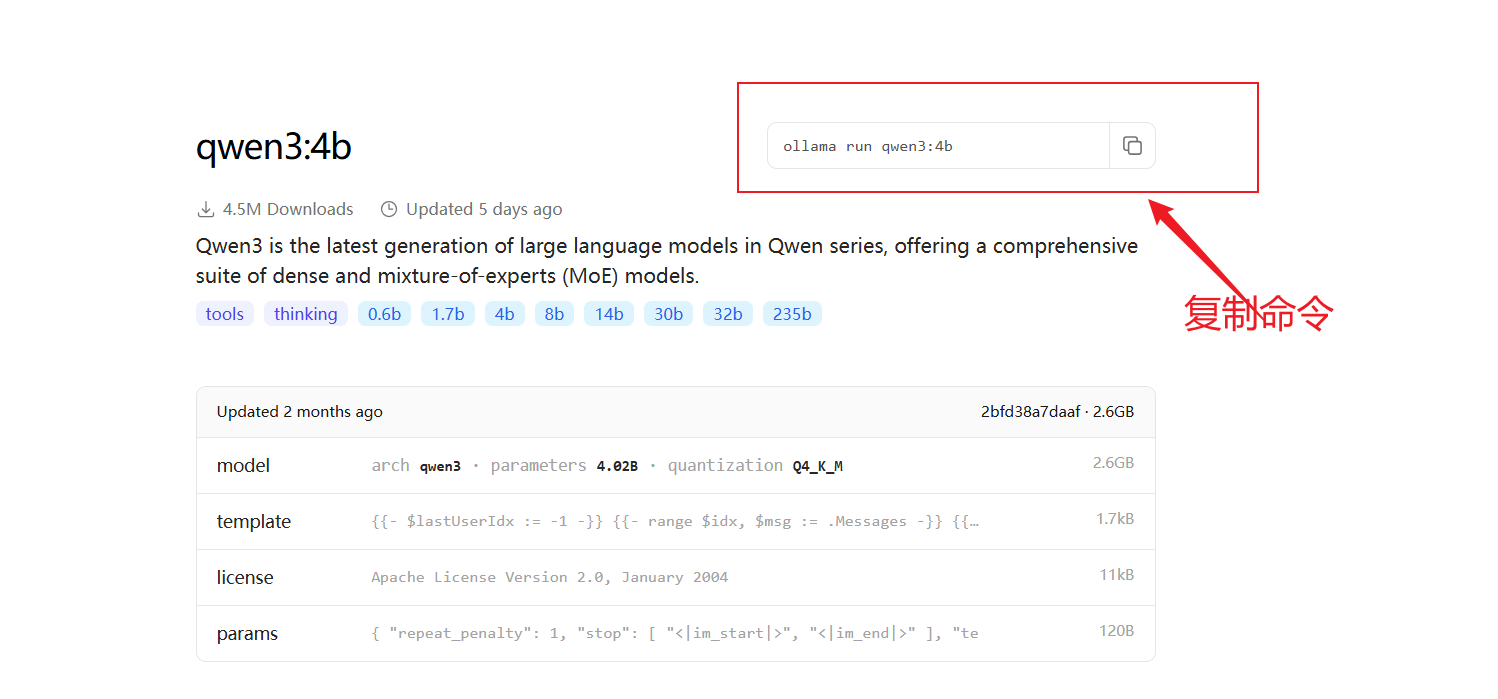
- 拉取模型 ollama run qwen3:4b
https://ollama.com/library/qwen3
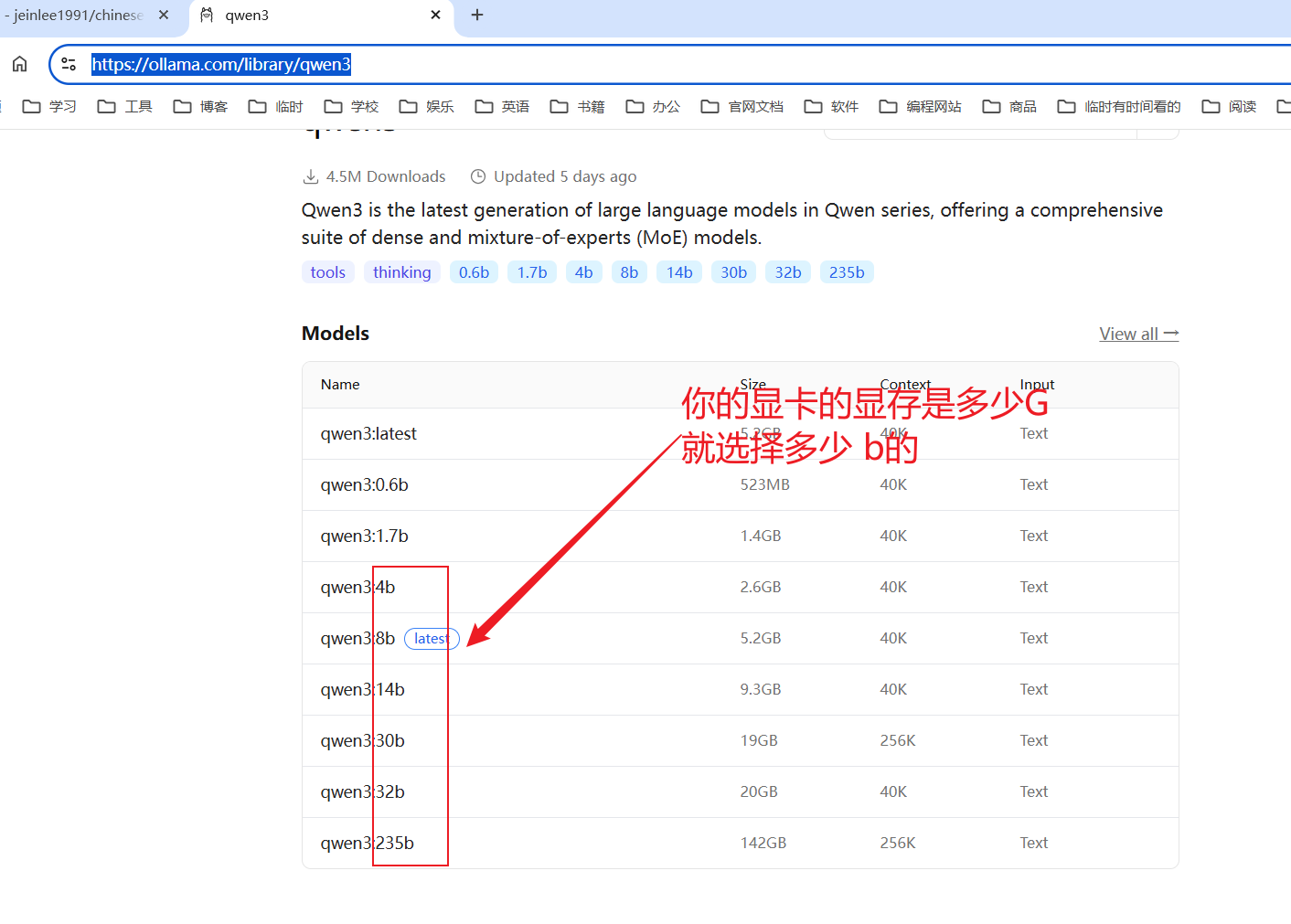
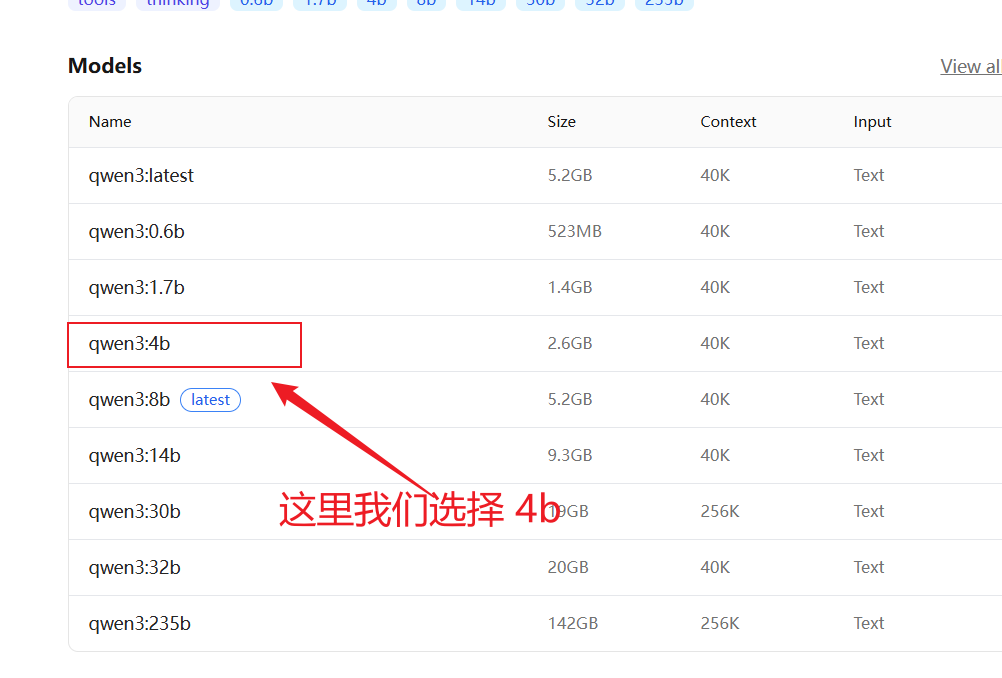
1. 这里的4b=40亿参数 对应gpu显存差不多是4G ,当然8B也可以只是比较卡
- 测试

基于spring-ai使用 上我们在 Ollama 本地模型部署的大模型
- 添加依赖(添加 ollama 的 SDK 依赖)
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
- 配置(配置 ollama 的配置,注意:ollama 是不需要配置 api_key 的,因为只有云端大模型才需要根据你的 api_key 计费算钱,授权。本地大模型是不需要的)。ollama 的默认端口 11434 。
ollama 是可以拉取配置运行多个本地大模型的,所以这里需要配置指明我们使用的是 ollama 本地当中的那个大模型
ollama list # 查看 ollama 当前含有配置拉取的有那些大模型
spring.ai.ollama.base-url= http://localhost:11434 # 默认端口是:11434
spring.ai.ollama.chat.model= qwen3:4b
- 测试
/*** @author */
@SpringBootTest
public class OllamaTest {@Testpublic void testChat(// 自动装配了 OllamaChatModel 配置类@Autowired OllamaChatModel ollamaChatModel) {String text = ollamaChatModel.call("你是谁");System.out.println(text);}
}

关闭 thingking
因为我们的 qwen3 大模型是一个思考模型(存在一个深度思考的过程),所以可能会思考的比较久,这里我们可以关闭 ollama 当中的大模型思考(深度思考)模式
可以通过 在提示词结尾加入“/no_think” 指令
String text = ollamaChatModel.call("你是谁/no_think"); // 你的提示词上加上 /no_think 软关闭,深度思考过程System.out.println(text);
但是依然有

ollama 0.9.0 支持了关闭think。但是在spring1.0版本还不兼容。(就是 ollama 虽然关闭了深度思考,但是我们项目的 Spring 1.0 还不兼容,所以是无效的。就是 OllamaOptions.builder().think()没有这个配置项,应该后面的 Spirng 1.1.x 就可能会有了)
ollama run qwen3:4b # 进入到对应要不关闭深度思考的大模型
/set nothink # 关闭该大模型的深度思考
https://ollama.com/blog/thinking
ollama 流式输出
stream + tools BUG 修复 spring ai 1.0 ollama 修改了
springai 1.0 小 BUG 使用stream + tools ,会报一个 #3372

@Testpublic void testStream(@Autowired OllamaChatModel chatModel) {Flux<String> stream = chatModel.stream("你是谁/no_think");// 阻塞输出stream.toIterable().forEach(System.out::println);}
ollama 0.8.0之前的版本不支持 stream+ollama
https://ollama.com/blog/streaming-tool 0.8.0+支持stream+ollama . 但是和springai1.0有兼容问题:https://github.com/spring-projects/spring-ai/issues/3369
多模态
注意:多模态是识别,多中不同文件的内容,理解不同文件的内容,而不是生成。

目前ollama支持的多模态模型:
- Meta Llama 4
- Google Gemma 3
- Qwen 2.5 VL
- Mistral Small 3.1
- and more vision models.
这里我们使用 ollama 拉取一个 gemma3:1b 的大模型测试:附上地址
/*** 多模态 图像识别, 采用的gemma3 * @param ollamaChatModel*/@Testpublic void testMultimodality(@Autowired OllamaChatModel ollamaChatModel) {// 指定读取文件的路径var imageResource = new ClassPathResource("gradle.png");// 指定大模型的配置项,这里使用 ollama 拉取当中的 gemma3 大模型OllamaOptions ollamaOptions = OllamaOptions.builder().model("gemma3").build();// 说明读取的是那个类型的多模态文件类型,这里是图片 imgMedia media = new Media(MimeTypeUtils.IMAGE_PNG, imageResource);ChatResponse response = ollamaChatModel.call(new Prompt(UserMessage.builder().media(media).text("识别图片").build(), // 写明提示词ollamaOptions));System.out.println(response.getResult().getOutput().getText());}

最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
