Survey 站在 security 研究者的角度来关注 LLM + 程序分析的如下几个方向:
-
静态分析:在不同的下游应用上评估 LLM 的作用,下游应用包括 vulnerability detection,malware detection,program verification, static analysis enhancement
-
动态分析:包括 malware detection,fuzzing,penetration testing
-
其他方法:包括 unit test generation 等
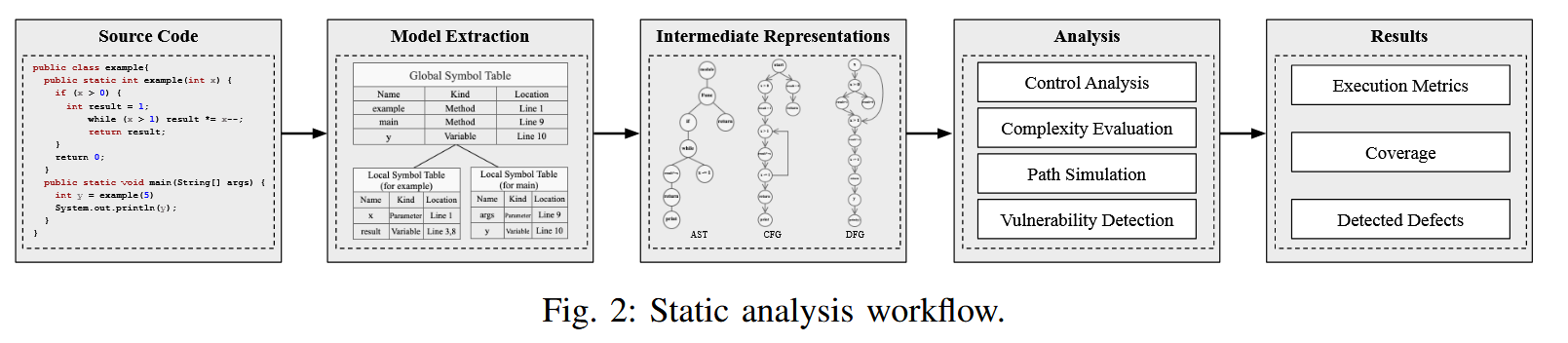
Survey 认为 static analysis 的工作流:源代码 -> 解析源代码得到关键的信息和 IR -> 在 IR 上做下游分析 -> 得到结果。
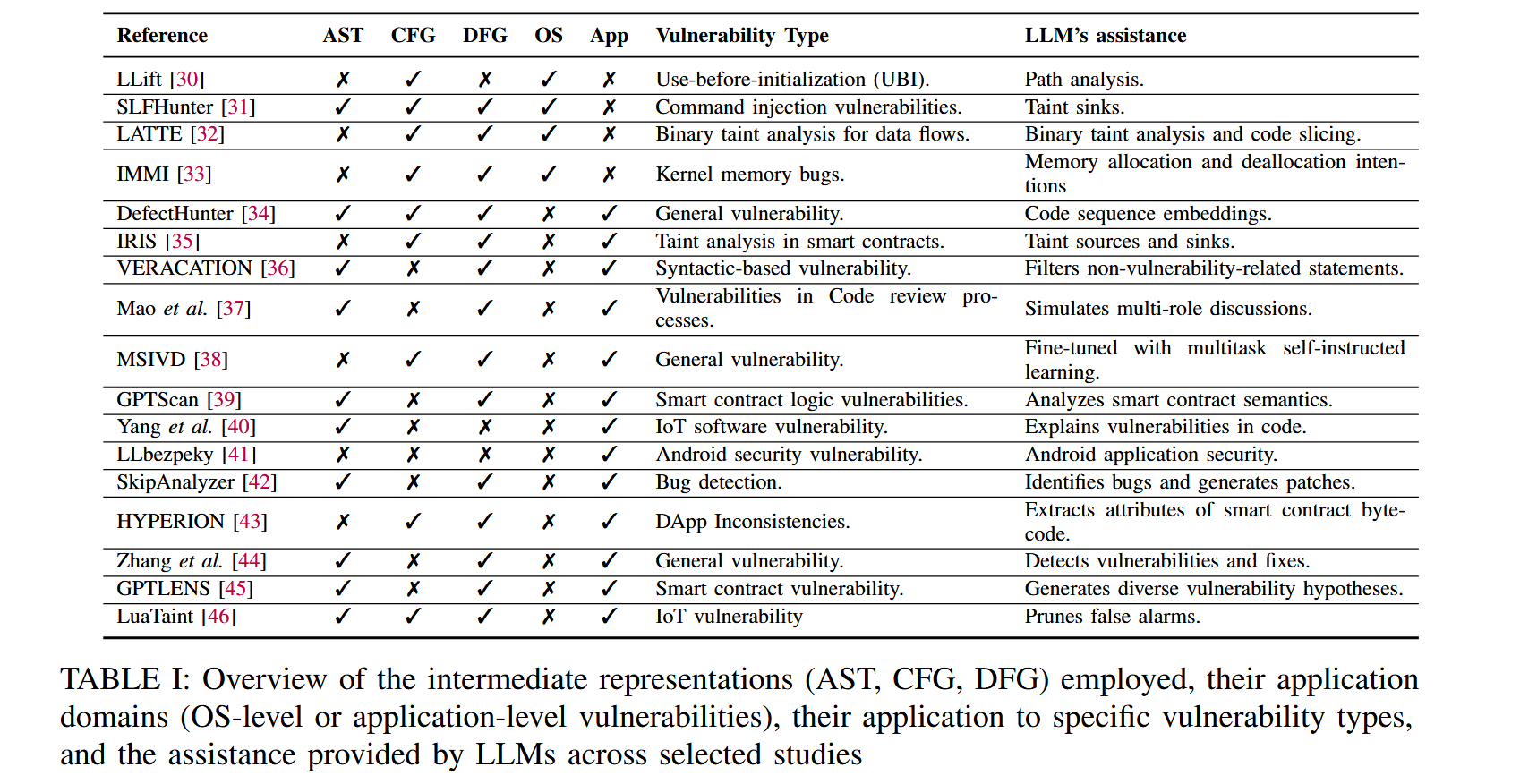
根据上面的工作流,对于 vulnerability detection,可以通过 IR,缺陷类型,LLM 发挥的作用等特征进行分类。上表的 OS/App 指缺陷是 OS-level 还是 App-level 的。
OS-level 的 vulnerability detection 面临 path-sensitivity 和 scalability 两方面的挑战,LLM 相关的静态分析方法包括:
-
LLift:Arxiv 2023,Zhiyun Qian,UC Riverside。Linux 系统内部存在一类 use-before-initialization 简称 UBI 的代码缺陷。C 语言还存在相当多的库函数,如果分析深入到这些库函数的时候显然是 unscalable 的,不去分析又会导致这部分的语义缺失导致 unsoundness。使用 LLM 识别所有的 initializer,并构建和分析相契合的 post-constraint,给 initializer 做总结判断是否一定会初始化变量。LLift 的工作基于前者的 UBITect,UBITect 会有大量的报告,40% 的报告没办法 decide,把这 40% 丢给 LLift 再次确认,效果还不错。Website。参考文献:https://cn-sec.com/archives/2123113.html
-
LATTE:Arxiv 2023,TSE'25,Ant Group,二进制代码的污点分析,先将二进制代码反编译,首先利用 LLM 识别危险程序点,然后进行反向依赖分析,得到一条或者多条调用链,调用链上必须存在某个危险源头 source(好像是手动构造判定的?),然后利用调用链进行代码切片,构造 prompt 模板让 LLM 在链上进行迭代判定。Baseline 选择 Emtaint 和 Arbiter,在 Juliet 和 Karonte 数据集上比 baseline 找到了更多的漏洞。参考文献:https://sh10rl.top/posts/harnessing-llm/
-
SLFHunter:CCS'24,命令注入漏洞 CI 是 Linux 嵌入式固件的常见漏洞,可以通过 taint analysis 解决。然而用户自定义的 DLL 不好处理。单独对某个二进制分析检查不出外部库问题,联合分析多个二进制文件非常耗时。同样先将二进制固件反汇编,然后利用 LLM 准确识别出可疑库函数中可能引起 CI 的输入参数,把信息导入前期工作 EmTaint 中。在测试中 SLFHunter 可以帮助 EmTaint 发现42个额外的命令注入漏洞,平均时间成本增加为89秒。参考文献:https://blog.csdn.net/XLYcmy/article/details/143976444
-
IMMI:USENIX Sec'24,inconsistent memory management intentions 指 caller 和 callee 之间内存管理动作不一致(都不处理内存或者抢着处理内存)的问题。从最基本的一些内存管理函数(kfree这种)出发,然后逐步去寻找更上层的封装函数给函数的内存管理方式做总结,然后对设计内存对象的代码做切片之后让 LLM 判断函数内部的内存管理方式是否一致,如果在多个分支间存在了不一致那么就可以报错了。参考文献:https://cn-sec.com/archives/3442658.html
上面的工作利用 LLM 的动机和做法很相似,出发点都是减少静态分析的开销,利用 LLM 自己的知识给分析做补全,实施上都是切片 + prompt engineer 的思路,面对不同的问题特征在切片方法,提示词构建作出不同的调整。
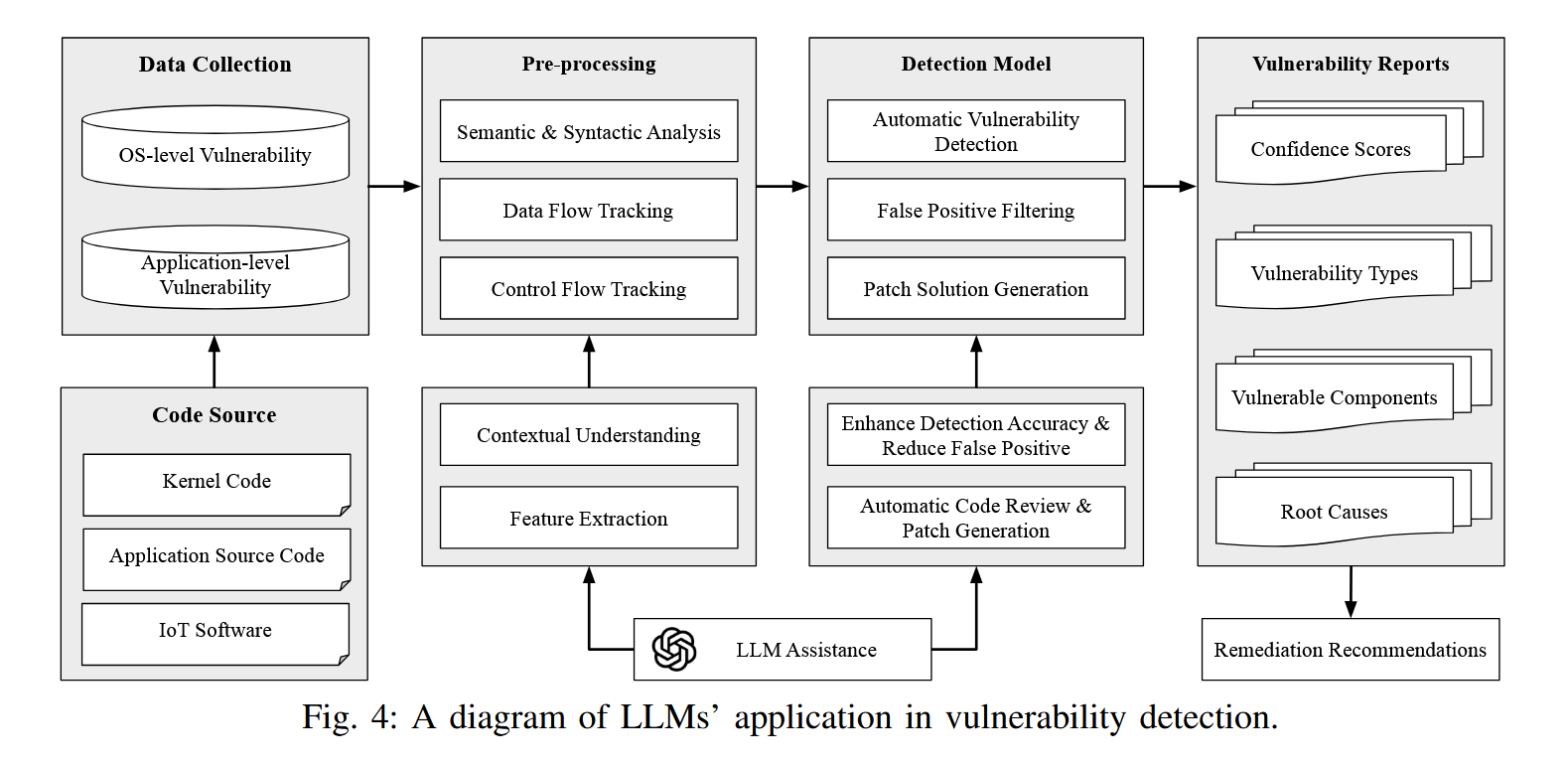
没太理解 app-level 和 OS-level 的 vulnerability detection 有什么太本质的区别,app-level 的工作选几个和静态分析更相关的工作:
- IRIS:Arxiv'24,ICLR'25,Mayur Naik,UPeen,静态分析负责提取候选的源和汇,而大型语言模型(LLM)则推断特定 CWE 类别的 taint specification。是把 LLM 集成到静态分析下游应用的思路。
其他工作: