方法
Qwen2-VL系列包含三种体量的模型,分别是Qwen2-VL-2B, Qwen2-VL-7B, Qwen2-VL-72B。表1列举出这些模型的超参数和重要信息。值得注意的是,这三个模型视觉编码器始终都采用675M参数量的ViT,没有因模型而改变。此举是为了确保ViT部分的计算量保持常量,没有因为采用更大体量的LLM,ViT也采用更多参数量。
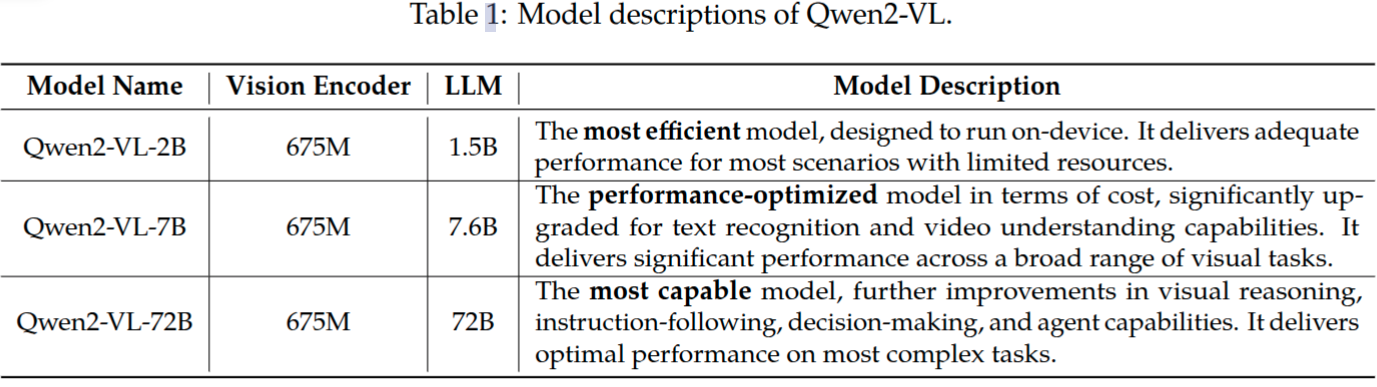
模型结构
图2展示了Qwen2-VL模型的完整的结构图。由视觉编码器、大语言模型这两部分构成。
Qwen2-VL模型没有像之前大多数的VL模型,采用视觉-语言适配器,而是丢弃掉这个模块。为什么Qwen2-VL采用这种做法呢?
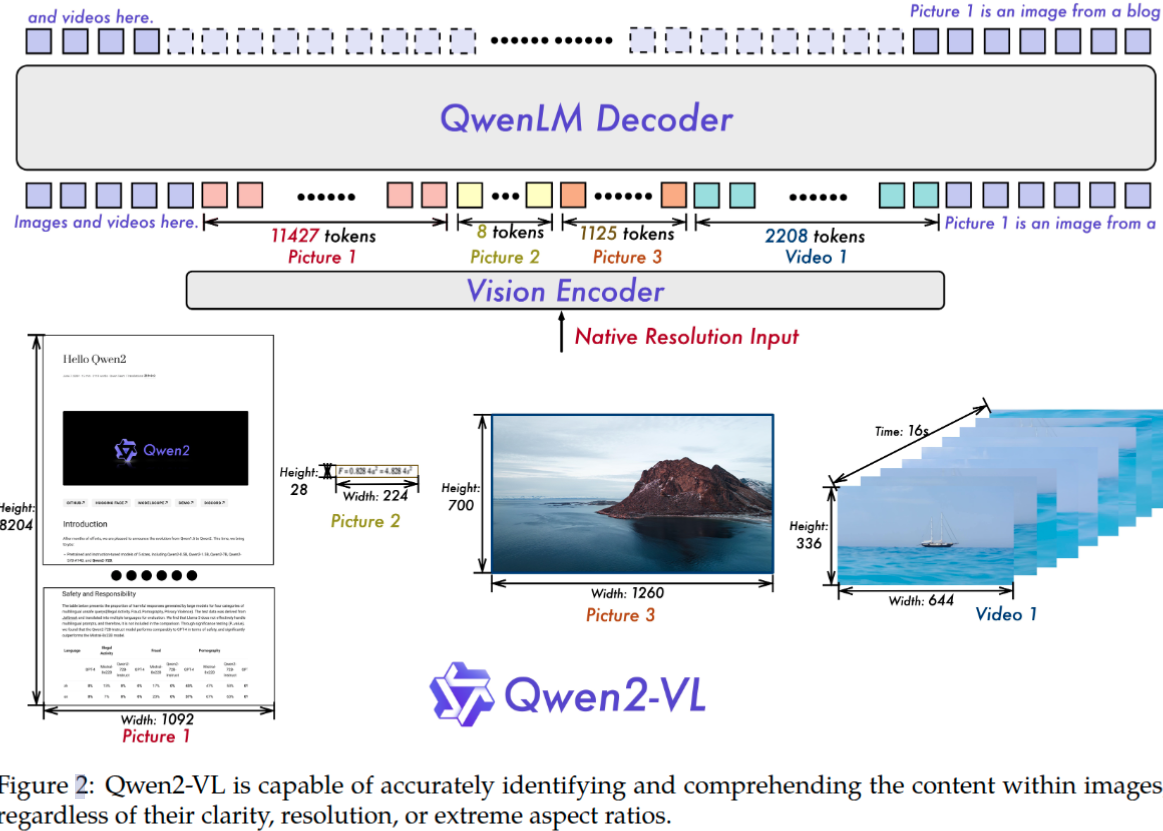
除了采用更强大的Qwen2系列语言模型,论文还通过如下几个方面升级来进一步增强对图像和视频的感知和理解能力。
动态分辨率 Qwen2-VL模型的一项关键改进就是引入了动态分辨率支持。不同于Qwen-VL将图片先预处理为固定尺寸x再提取特征,Qwen2-VL能处理任意分辨率的图像,动态地将图片转换为不同数量的视觉token。为了实现这个功能,不再采用原始的绝对位置编码,而采用2D-RoPE来获取图像的两个维度上的位置信息。在推理过程中,不同分辨率的图像提取完特征后要再打包为一个特征序列,当然特征序列的长度不能无限长,取决于GPU内存大小。为了更进一步减少图片的视觉token数量,使用一个简单的MLP层将相邻的2x2 tokens压缩为一个token。并在压缩后的视觉token序列前后分别添加2个特殊的token:<|vision_start|>,<|vision_end|> 已标记视觉token的位置。比如224x224分辨率的图片,patch_size=14的情况下,如果不压缩将产生16x16=256个token,经过压缩后就变成了64个token,如果再添加上用于视觉标识的2个特征token,这样最终就是66个token了。
疑问:VIT提取视觉特征是一个token序列,已经失去了图像原有的二维空间几何关系,怎么这里是使用MLP层将相邻的2x2 tokens压缩为1个token呢? 原始VIT论文是将图像切分按patch_size 不重叠地切分\(N=\frac{HW}{patch_size^2}\)个图像块,每个图像块映射为一个长度为D维的特征向量,并将这些特征向量按照对应图像块从上到下从左到右序列排列。然后得到N个特征向量,这N个特征向量添加位置编码特征,再经过transfomer结构得到最终的特征序列。这个token序列在序列中的位置,其实是隐含了刚才patch块二维空间位置信息,通过reshape就可以将token序列变成形式上的二维。这样就可以使用MLP层将2x2 tokens压缩为1个token。
M-RoPE 多模态旋转位置编码(M-RoPE)是另一项关键的架构改进。与传统大语言模型中仅能编码一维位置信息的1D-RoPE不同,M-RoPE能够有效建模多模态输入的位置信息。其实现方式是将原始的旋转位置编码分解为三个组成部分:时间维度(temporal)、高度维度(height)和宽度维度(width)。对于文本输入,这三个组成部分使用相同的位置ID,使得M-RoPE在功能上等价于1D-RoPE。在处理图像时,每个视觉token的时间维度ID保持不变,而高度和宽度维度则根据该token在图像中的空间位置分别赋予不同的ID。对于视频(被视为帧序列),时间维度ID随每一帧递增,而高度和宽度维度的ID分配方式则与图像处理相同。当模型输入包含多种模态时,每种模态的位置编号从上一种模态的最大位置ID加一后开始初始化。图3展示了M-RoPE的示意图。M-RoPE不仅增强了对位置信息的建模能力,还降低了图像和视频所对应的位置ID数值,从而使模型在推理阶段能够更好地外推至更长的序列。 如图3所示。
统一图像和视频理解 Qwen2-VL采用了融合图像和视频数据的混合训练策略,以确保模型在图像理解和视频理解方面都具有出色的能力。为了尽可能保留完整的视频信息,每个视频每秒采样2帧。另外使用2层的3D卷积来预处理视频输入,使得模型能够处理3D数据,同时也可以处理更多的视频帧而不增加token序列长度。为了保持一致性,每张图片看作是2个相同的帧参与计算。为了平衡长视频处理的计算开销和整个训练效率,训练过程中动态调整视频的尺寸,限制视频的总token数量不超过16384。

训练
Qwen2-VL训练与Qwen-VL三阶段训练保持一致,具体参考Qwen多模态系列模型笔记—Qwen-VL
Qwen-VL中关于训练集构成进行了详细说明,而Qwen2-VL论文则没有详细说明其构成,仅定性描述了一下。从论文零散的地方可以看出不同于Qwen-VL的部分。
- Qwen2-VL相比Qwen-VL增加对视频的分析理解能力,数据集必然包括视频为中心的数据
- 引言中提到了,Qwen2-VL定位服务全球,不仅限于中文和英文。数据集扩充多语种数据,包括大多数欧洲语言、日文、韩文、阿拉伯文、越南文等。
- 从表1中,Qwen2-VL-7B显著提升了OCR识别能力。由此推测Qwen2-VL扩充了OCR识别相关数据集。但这种能力提升也可能是采取动态分辨率带来的,不像Qwen-VL采用固定低分辨448x448。尤其是整页包含大量文本/公式这样大图片,采用动态分辨率方式能有效降低采取固定分辨率带来的损失。
数据格式
与Qwen-VL一样,仍然需要对图像视频、坐标、文本中指代这些使用特殊标记它们的开始和结束,但是具体的标识符改变了。
| 模型 | 图像标识符 | 视频标识符 | 坐标框标识符 | 指代标识符 | 对话标识符 |
|---|---|---|---|---|---|
| Qwen-VL | <img>, <\img> |
/ | <box>, <\box> |
<ref>, <\ref> |
<im_start>,<im_end> |
| Qwen2-VL | <|vision_start|>,<|vision_end|> |
<|vision_start|>,<|vision_end|> |
<|box_start|>,<|box_end|> |
<|object_ref_start|>,<|object_ref_end|> |
<|im_start|>,<|im_end|> |


消融实验
动态分辨率 论文对动态分辨率和固定分辨率的性能进行了对比。这里提到的固定分辨率并不是像Qwen-VL那样将输入图片尺寸调整为固定的224x224或者448x448尺寸,而是调整图像的尺度以便经过VIT后得到固定长度的token序列。这种方式就不会破坏原始图像的纵横比参考Table7。可以看到图像特征序列长度有64,576,1600,3136这4种,这4种长度,如果是方图,则依次对应224x224, 672x672, 1120x1120, 1568x1568这4种图像分辨率。可以看出随着图像特征序列长度增加,在InfoVQA, REalWorldQA, OCRBench这3个测试集上,指标值有明显提升。说明了输入较大尺寸的图片,是可以达到更好的模型指标。而采用动态分辨率技术,使得使用平均较短的特征序列能达到采用更大输出尺寸相当的模型指标。这表明了动态分辨率技术具有更大的优势,相当的模型指标下,计算量更小。
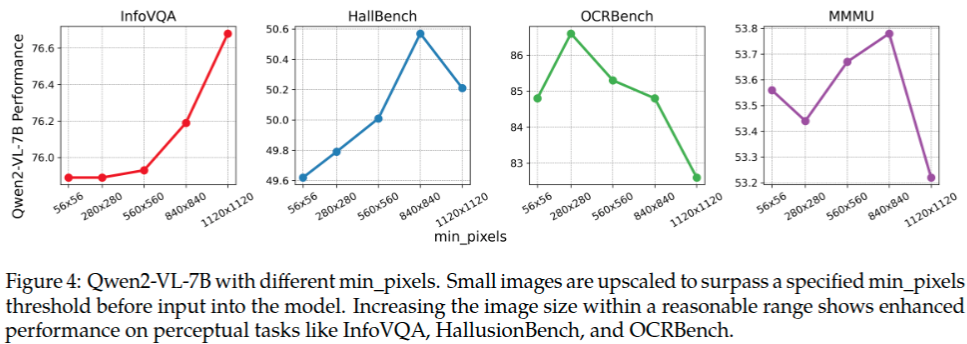
动态分辨率模式下,设置了最小和最大像素数量。\(min pixels=100 \times 28 \times 28\), \(max pixels=16384 \times 28 \times 28\),如果是方形图像,那么就对应着 \(280 \times 280\), \(3584 \times 3584\) 这两个分辨率。大多数图片像素总量也都落在这个范围了,这也是为什么如此设置的原因。图4列出了,最小图片像素对模型性能的影响。可以看出将最小图片像素阈值逐渐增大,并没有显著地提升模型的性能。这说明了小尺寸的图片没有必要上采样更大的尺寸,原始是小尺寸图片就采用原始的分辨率进行后续VIT特征提取,也能达到较好的模型性能。最终验证了动态分辨率方案的优越性。

关于Qwen2-VL能处理视频长度的问题。下面4段是论文原话,第1段说可以处理20分钟即1200秒左右的视频;第2段说每秒提取2帧,那么推理得到可以Qwen2-VL可以处理最大2400帧。第3,4段限制视频最大token数量是16384,而Qwen2-VL处理单张最小的图片得到100个token,那么最多是163帧。这样就产生了矛盾,163帧 vs 2400帧,无法处理20分钟的视频。猜测:如果要处理这么长的视频,就不能采用每秒采样2帧,而是每隔几秒种采样一帧才能实现。比如24分钟分辨率280x280的视频,每隔12秒采样一帧,那么总的视频token数量就是\(\frac{24 \times 60 \times 100}{12}=12000\),没有超过16384.
Comprehension of extended-duration videos (20 min+): Qwen2-VL is capable of understanding videos over 20 minutes in length, enhancing its ability to perform high-quality video-based question answering, dialogue, content creation, and more.
To preserve video information as completely as possible, we sampled each video at two frames per second.
For consistency, each image is treated as two identical frames. To balance the computational demands of long video processing with overall training efficiency, we dynamically adjust the resolution of each video frame, limiting the total number of tokens per video to 16384.
For dynamic resolution, we only set min_pixels= 100 × 28 × 28 and max_pixels= 16384 × 28 × 28, allowing the number of image tokens depend primarily on the image's native resolution.