注意机器启动过之后,同步的时候不要同步data文件夹
一次写入,多次读出,不支持文件修改。适合数据分析,不适合网盘应用
分布式存储,文件系统。
优点:
- 高容错性。多复制,丢失自动恢复
- 适合大数据,数据以及文件规模
- 可以在廉价机器上,多副本来实现高可靠
缺点:
- 不适合低延时数据访问
- 无法对小文件高效存储
- 不支持并发多线程同时写入、文件随机修改,只支持append
组成
nn:master,
- 管理HDFS命名空间;
- 配置副本策略(放在那个nn节点);
- 管理数据块Block(DN里面存放的是一个个数据块,不是简单的文件)的映射信息;
- 处理客户端读写请求
dn:slave,nn下达指令,DN执行操作。
- 存储实际的数据块,数据块的形式存在
- 执行读写操作。
client:
- 文件切块,block大小由此处决定,平衡数据存储
- 与NN交互,获取文件位置信息
- DN交互,获取文件信息
- 访问和管理HDFS
2NN:
- NN助手
HDFS文件块:
物理上是分块存储的,大小可以通过配置参数来决定,默认是128M

web页面无法新建文件夹权限问题
http://hadoop101:9870/explorer.html#/
在浏览器创建目录和删除目录及文件,是dr.who用户,dr.who其实是hadoop中http访问的静态用户名,并没有啥特殊含义,可以通过修改core-site.xml,配置为当前用户
<property>
<name>hadoop.http.staticuser.user</name>
<value>deltaqin</value>
</property>
另外,通过查看hdfs的默认配置hdfs-default.xml发现hdfs默认是开启权限检查的。
dfs.permissions.enabled=true #是否在HDFS中开启权限检查,默认为true
解决
第一种方案
直接修改/user目录的权限设置,操作如下:
hdfs dfs -chmod -R 755 /user
第二种方案
在Hadoop的配置文件core-site.xml中增加如下配置:

<property>
<name>hadoop.http.staticuser.user</name>
<value>deltaqin</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
命令行操作
bin/hadoop fs
bin/hdfs dfshadoop fs
hdfs dfs
# 启动Hadoop集群(方便后续的测试)
# 101
sbin/start-dfs.sh
# 102
sbin/start-yarn.sh# -help:输出这个命令参数
hadoop fs -help rm#上传
# -moveFromLocal:从本地剪切粘贴到HDFS
touch kongming.txt
hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
# -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal README.txt /
# -appendToFile:追加一个文件到已经存在的文件末尾
touch liubei.txt
vi liubei.txt
# 输入
san gu mao lu
hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
# -put:等同于copyFromLocal
hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/# 下载
# -copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
# -get:等同于copyToLocal,就是从HDFS下载文件到本地
hadoop fs -get /sanguo/shuguo/kongming.txt ./
# -getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt# HDFS直接操作
# -ls: 显示目录信息
hadoop fs -ls /
# -mkdir:在HDFS上创建目录
hadoop fs -mkdir -p /sanguo/shuguo
# -cat:显示文件内容
hadoop fs -cat /sanguo/shuguo/kongming.txt
# -chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
hadoop fs -chown deltaqin:deltaqin /sanguo/shuguo/kongming.txt
# -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
# -mv:在HDFS目录中移动文件
hadoop fs -mv /zhuge.txt /sanguo/shuguo/
# -tail:显示一个文件的末尾
hadoop fs -tail /sanguo/shuguo/kongming.txt
# -rm:删除文件或文件夹
hadoop fs -rm /user/atguigu/test/jinlian2.txt
# -rmdir:删除空目录
hadoop fs -mkdir /test
hadoop fs -rmdir /test
# -du统计文件夹的大小信息
hadoop fs -du -s -h /user/atguigu/test
2.7 K /user/atguigu/testhadoop fs -du -h /user/atguigu/test
1.3 K /user/atguigu/test/README.txt
15 /user/atguigu/test/jinlian.txt
1.4 K /user/atguigu/test/zaiyiqi.txt# -setrep:设置HDFS中文件的副本数量
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
客户端操作
连接和关闭
@Before
public void before() throws IOException, InterruptedException {
// 相当于site文件,配置HDFS
// Configuration configuration = new Configuration();
// 2个副本
// configuration.set("dfs.replication", "2");
// 128/2 = 64M
// configuration.set("dfs.blocksize", "67108864");//1. 新建HDFS对象fileSystem = FileSystem.get(URI.create("hdfs://hadoop101:8020"),new Configuration(), "deltaqin");
}@After
public void after() throws IOException {fileSystem.close();
}
基本操作API
/*** 上传* @throws IOException* @throws InterruptedException*/
@Test
public void put() throws IOException, InterruptedException {// 相当于site文件,配置HDFS// Configuration configuration = new Configuration();// 2个副本// configuration.set("dfs.replication", "2");// 128/2 = 64M// configuration.set("dfs.blocksize", "67108864");//2. 操作集群fileSystem.copyFromLocalFile(new Path("/Users/qinzetao/Pictures/QQ20200621-0.jpg"),new Path("/1.jpg"));
}/*** 下载**/
@Test
public void get() throws IOException {fileSystem.copyToLocalFile(new Path("/1.jpg"),new Path("/Users/qinzetao/Documents/大数据/1_hadoop/代码/Hadoop/hdfs200105"));
}/*** 查看文件和文件夹* @throws IOException*/
@Test
public void ls() throws IOException {FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));for (FileStatus fileStatus : fileStatuses) {System.out.println(fileStatus.getPath());System.out.println(fileStatus.getOwner());System.out.println("=================");}
}/*** 查看文件* @throws IOException*/
@Test
public void lf() throws IOException {RemoteIterator<LocatedFileStatus> statusRemoteIterator =fileSystem.listFiles(new Path("/"), true);while (statusRemoteIterator.hasNext()) {LocatedFileStatus fileStatus = statusRemoteIterator.next();System.out.println(fileStatus.getPath());BlockLocation[] blockLocations = fileStatus.getBlockLocations();for (int i = 0; i < blockLocations.length; i++) {System.out.println("第" + i + "块");String[] hosts = blockLocations[i].getHosts();for (String host : hosts) {System.out.print(host + " ");}System.out.println();}System.out.println("===================================");}
}/*** 追加*/
@Test
public void append() throws IOException {FSDataOutputStream append = fileSystem.append(new Path("/README.txt"));append.write("TestAPI".getBytes());IOUtils.closeStream(append);
}/*** 移动*/
@Test
public void mv() throws IOException {fileSystem.rename(new Path("/1.jpg"),new Path("/logs/2.jpg"));
}
数据流
写数据
完整流程

注意每一块选择存放在哪些节点是完全独立的过程。
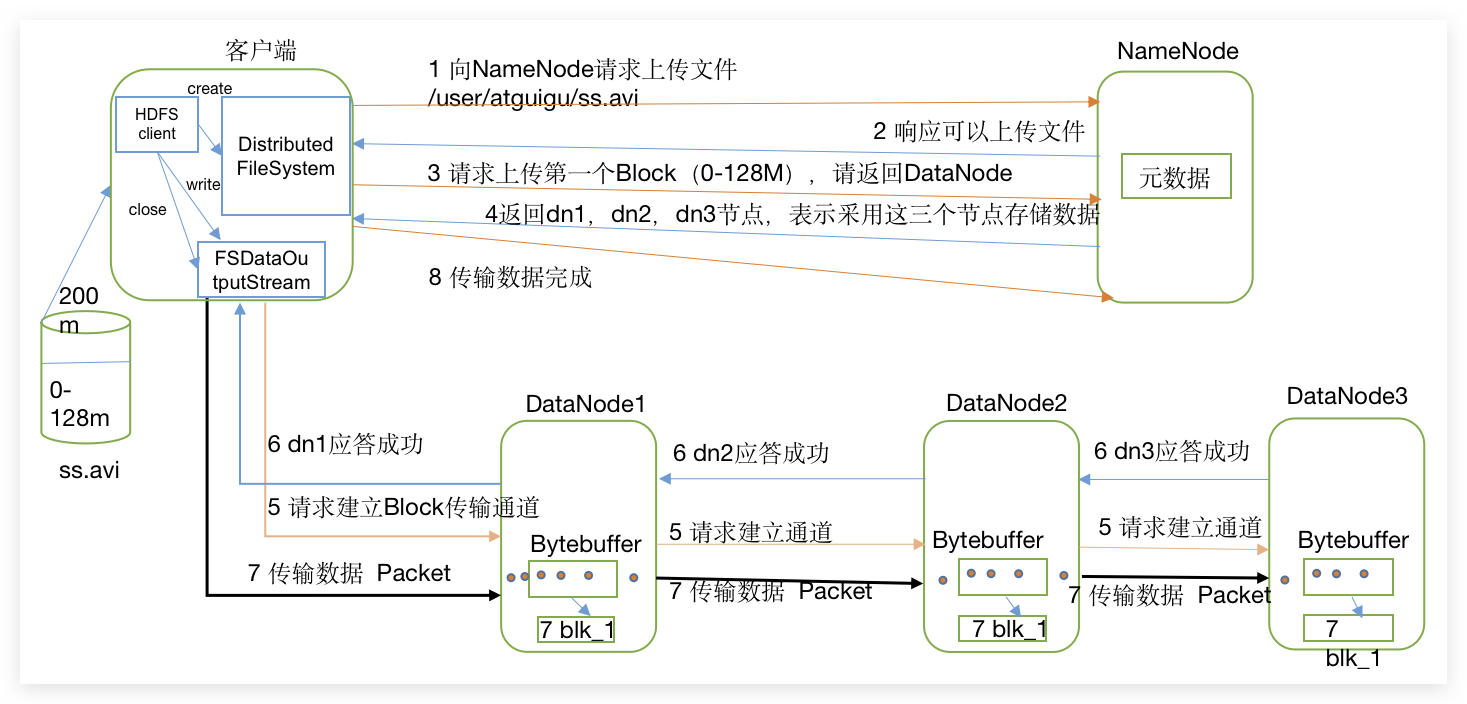
节点选择
NameNode会选择距离待上传数据最近距离的DataNode接收数据
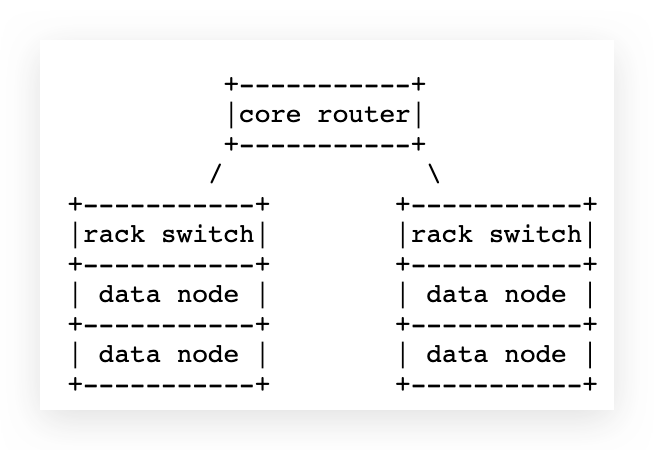
- 节点距离(网络拓扑距离):两个节点到达最近的共同祖先的距离总和。
- rack:机架,看做路由器,下面有很多DN
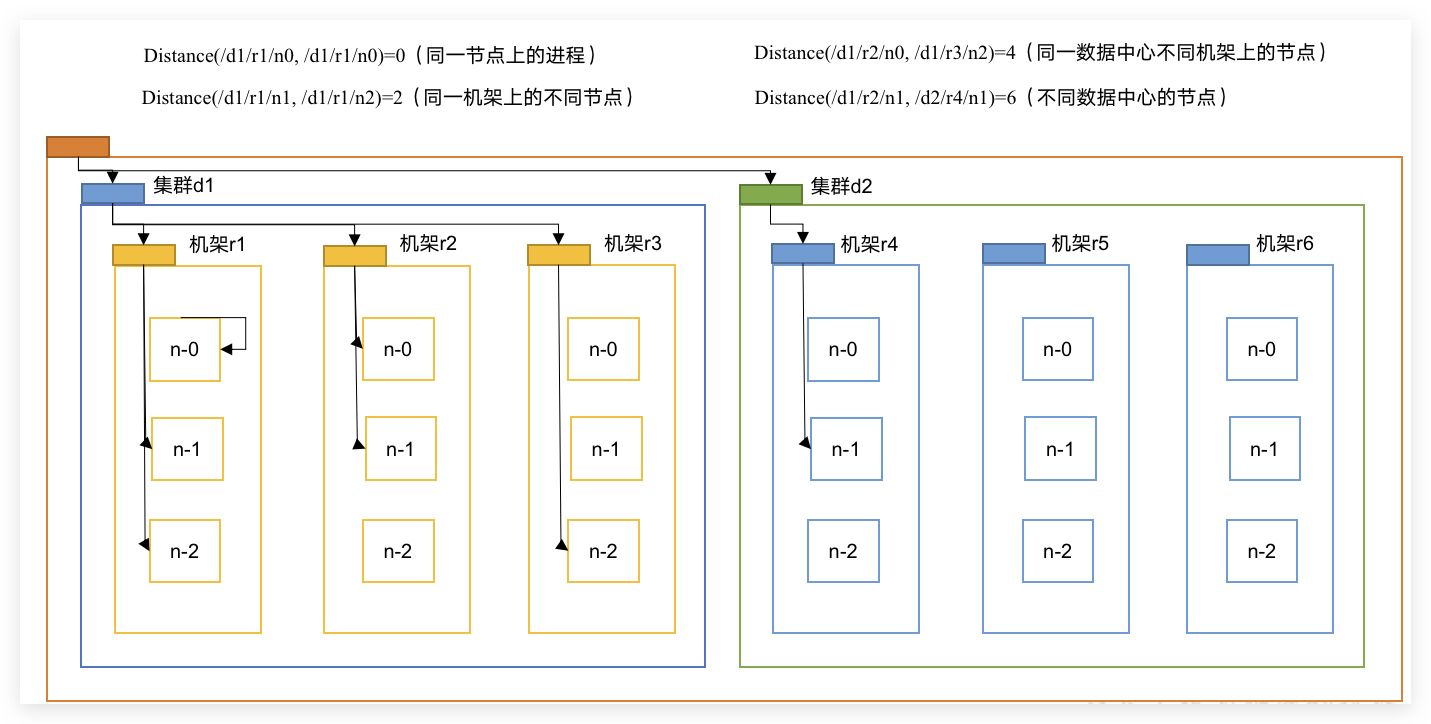
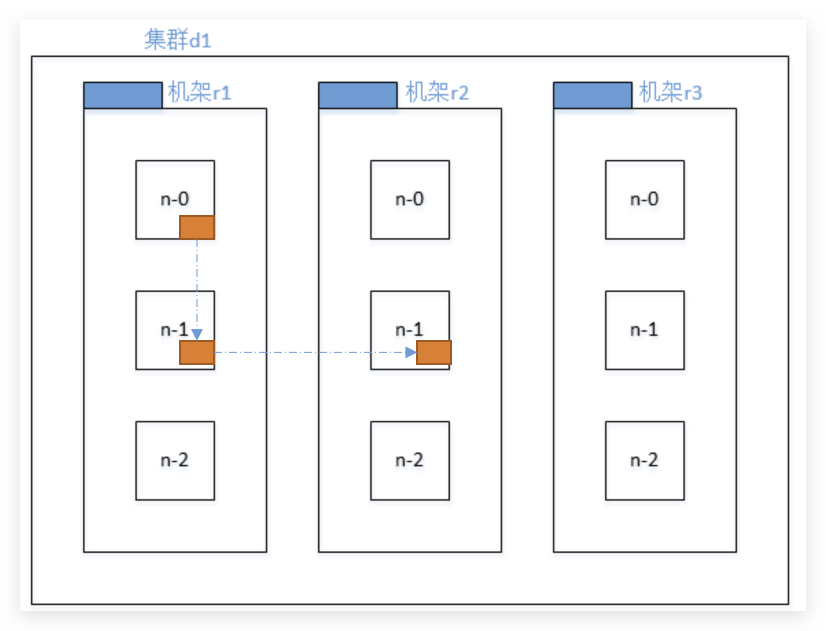
机架感知(副本存储节点****选择)
副本放置策略:For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
- 第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
- 第二个副本和第一个副本位于相同机架,随机节点 。
- 第三个副本位于不同机架,随机节点。
读数据
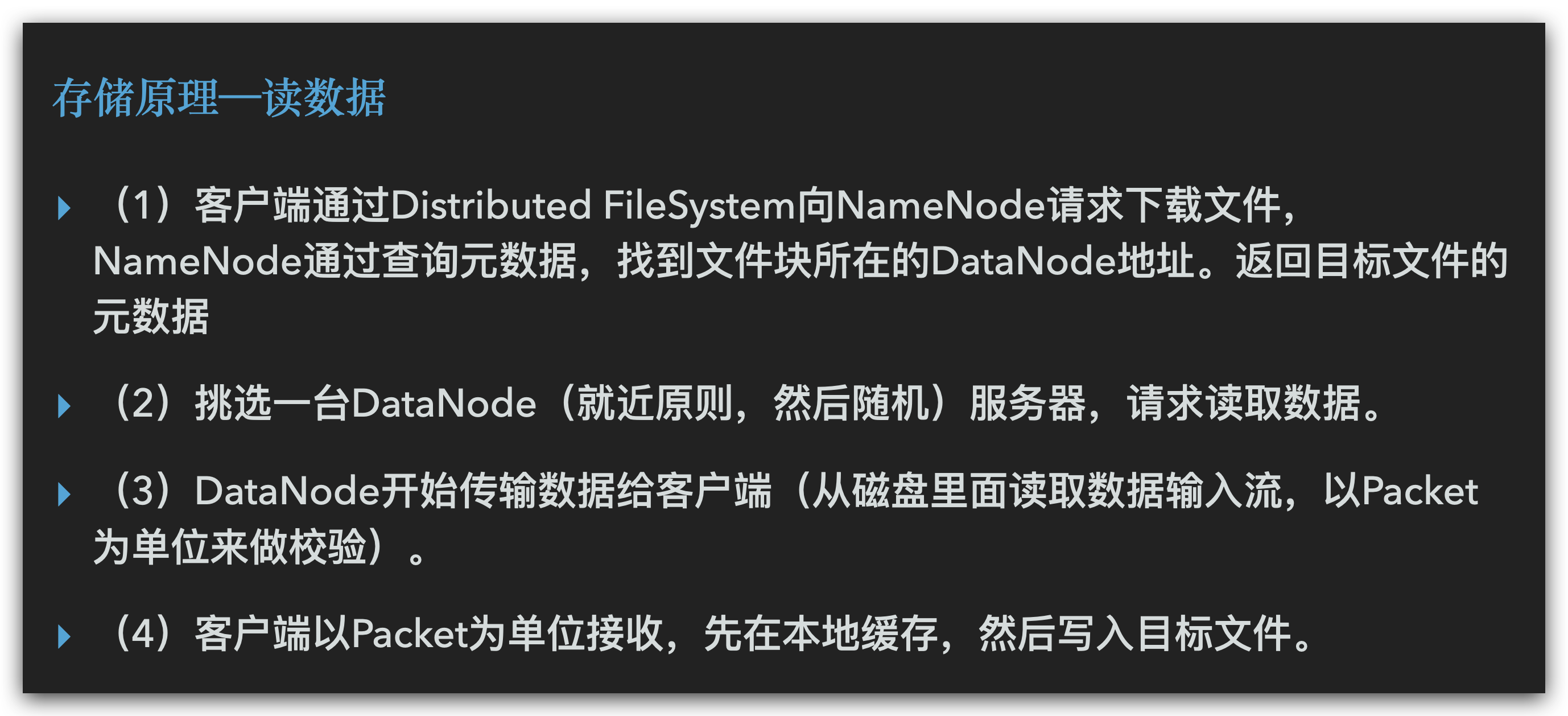
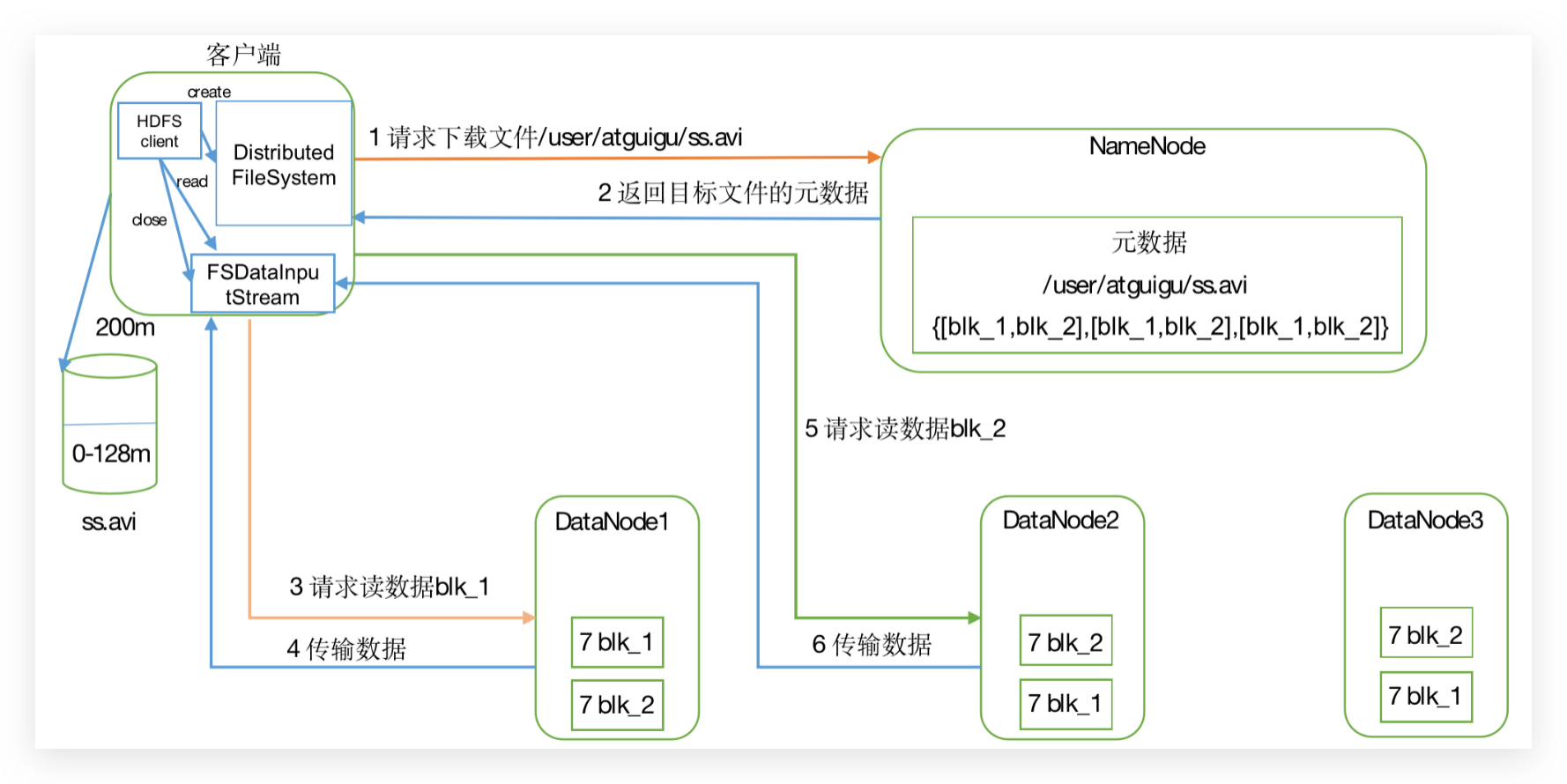
NameNode和SecondaryNameNode
元数据要求读写快,放在内存里面
涉及到持久化问题,如何提高效率?
利用多级缓存的思想!!!
- FSImage文件是HDFS中名字节点NameNode上文件/目录元数据在特定某一时刻的持久化存储文件。(相当于是内存的镜像)
- edits.log记录的是该干什么,不是元数据,元数据是读取这个记录之后读取对应的元数据放到内存里面得到的。
- 日志和image都在磁盘上,一个是日志,一个是数据
NN
NN只持久化操作日志,
edits.log:记录操作,编辑日志
fsimage:edits持久化,镜像文件

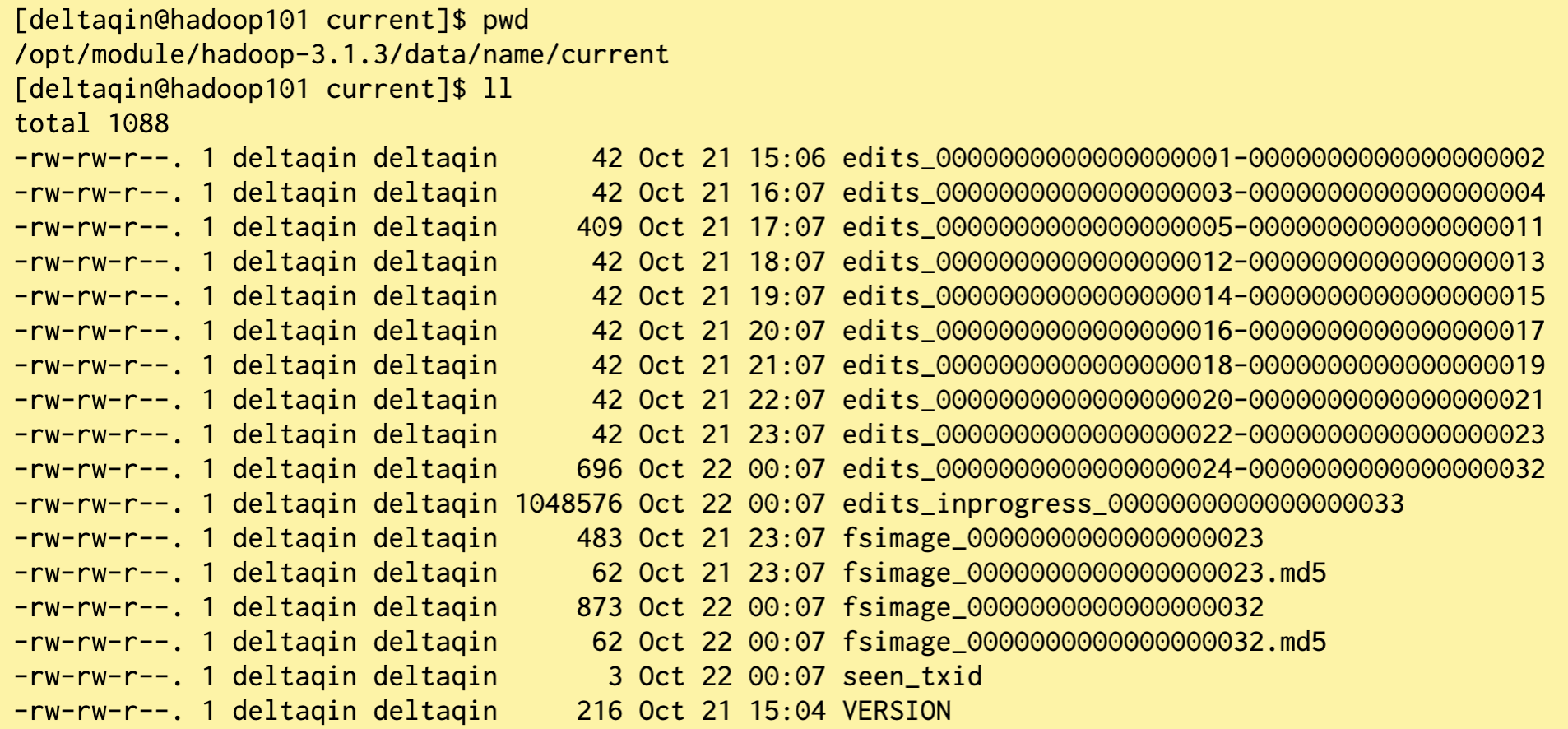
NameNode被格式化之后,将在 $HADOOP_HOME/data/tmp/dfs/name/current 目录中产生如下文件:
- Fsimage文件:(记录某一时刻内存状态)HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
- Edits文件:(记录过程,没有元数据)存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
- seen_txid文件保存的是一个数字,就是最后一个edits_的数字
- 每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
启动流程
重启结束之后会触发一次合并,保存为checkpoint
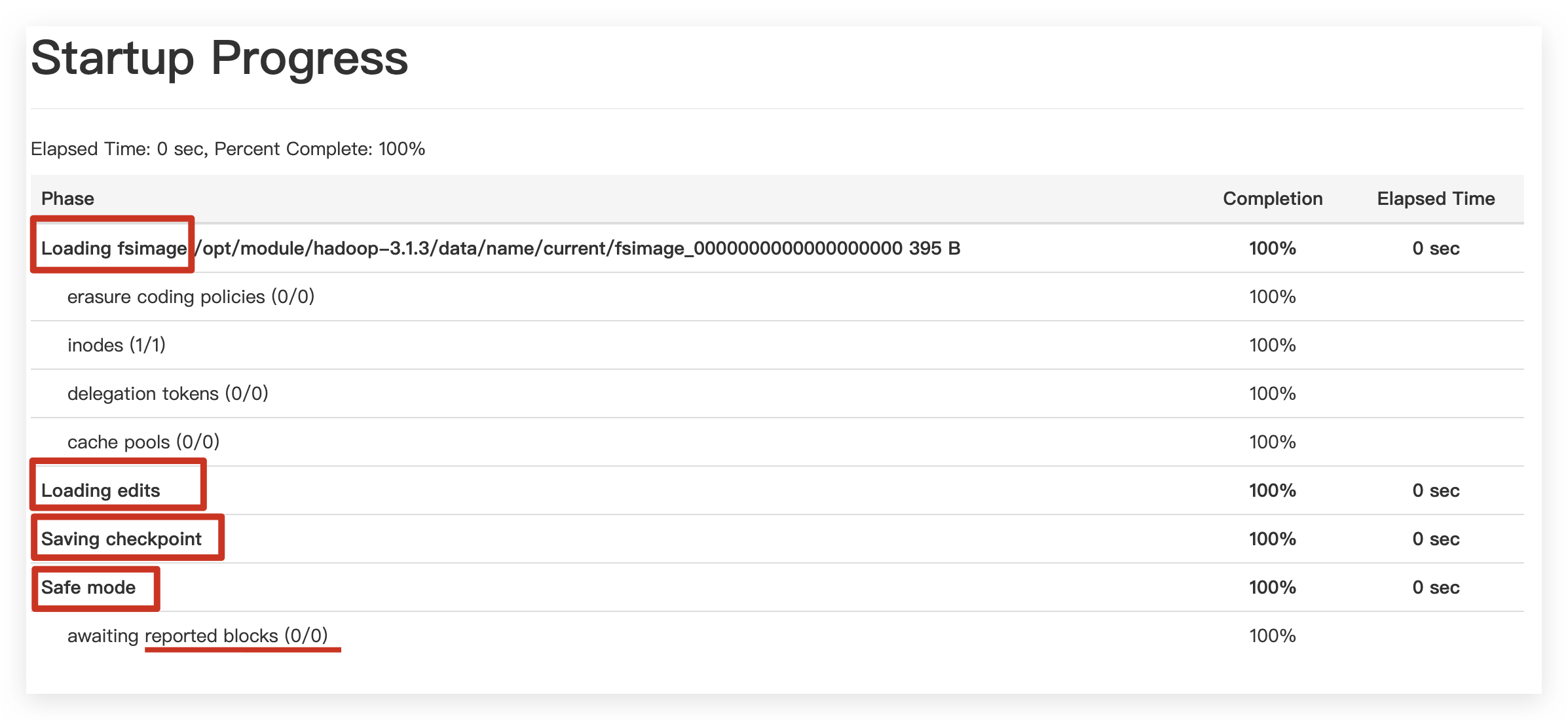
2NN

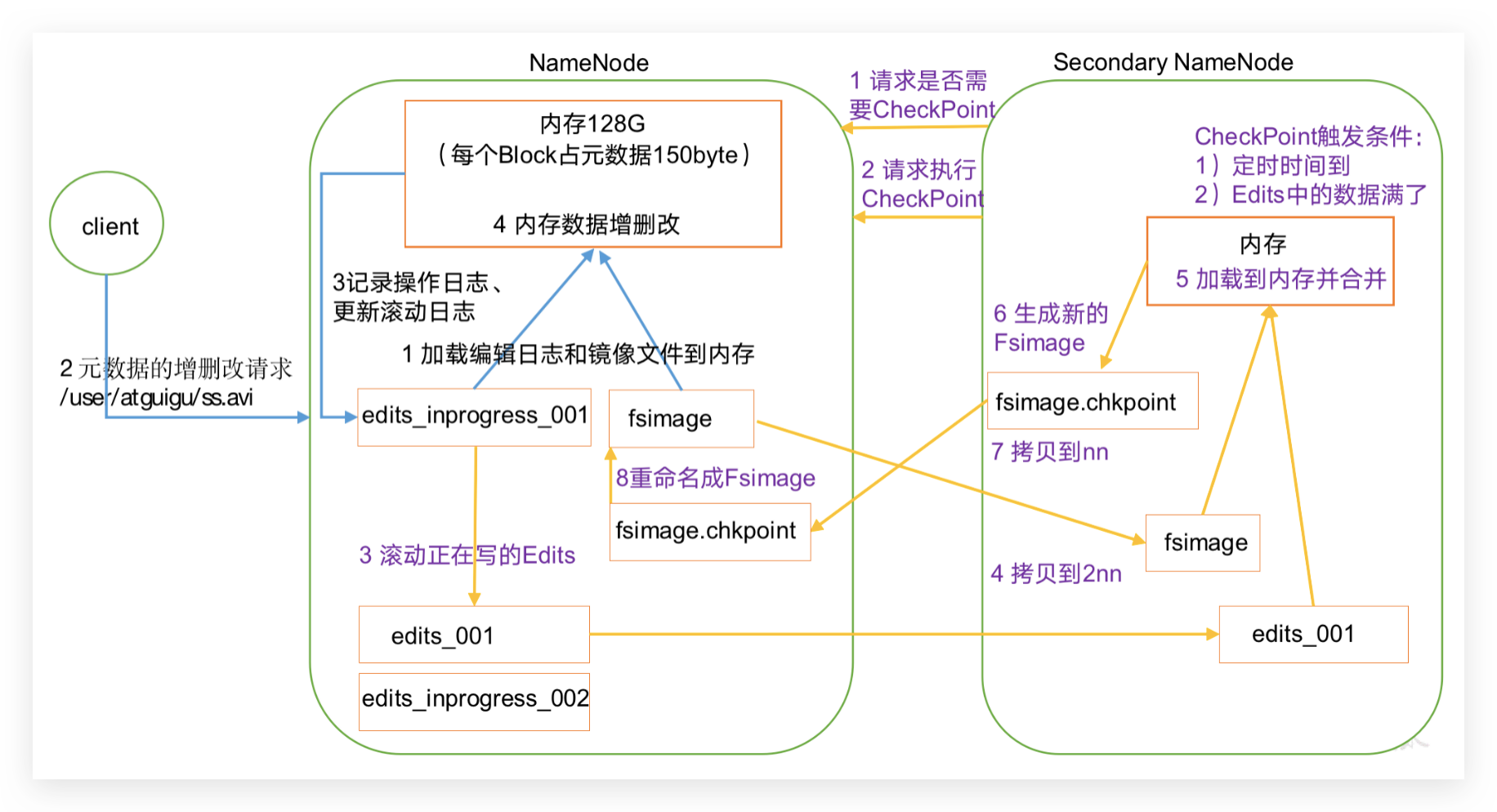
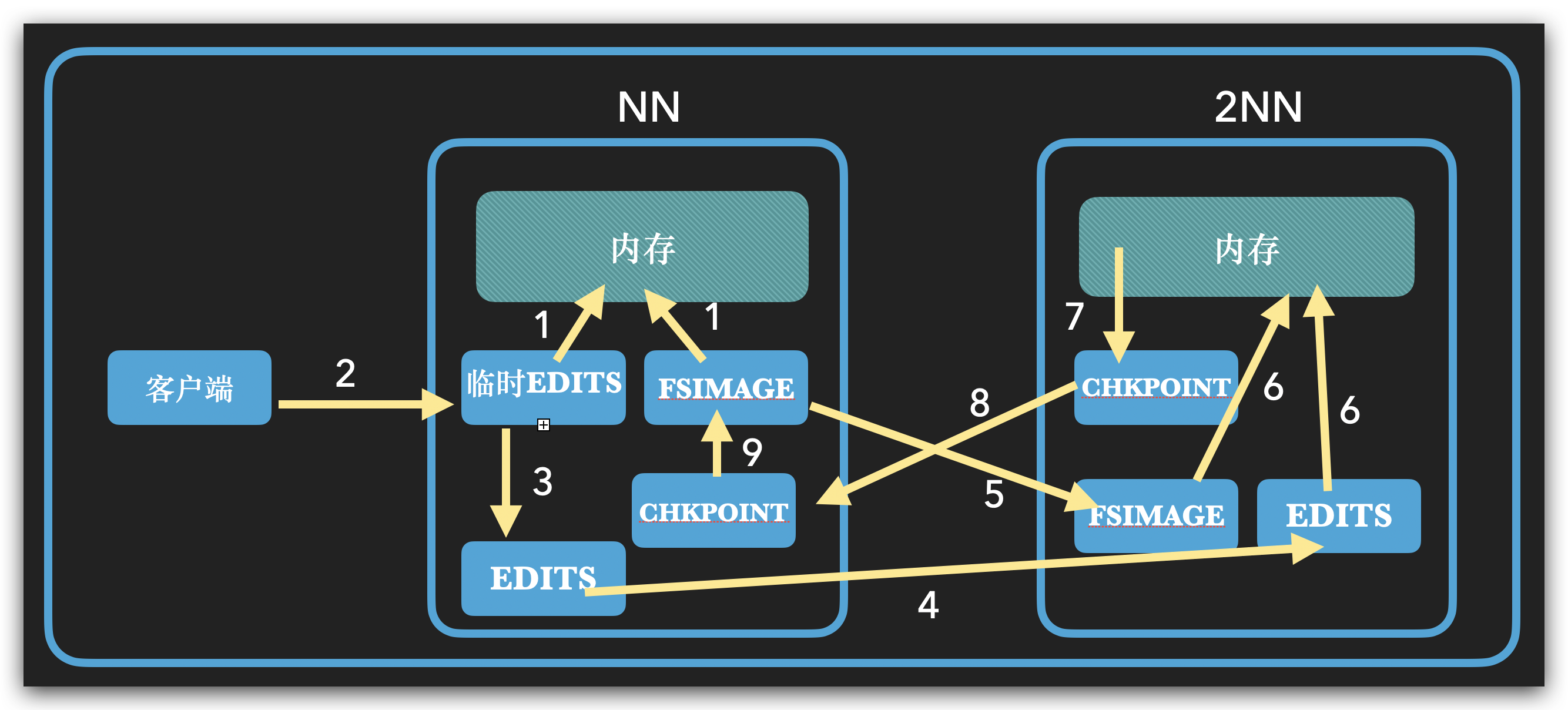
Fsimage和Edits
格式化会生成一个空的fsimage,就可以启动了。
oiv查看Fsimage文件
oev apply the offline edits viewer to an edits file
oiv apply the offline fsimage viewer to an fsimage
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径pwd
/opt/module/hadoop-3.1.3/data/tmp/dfs/name/current
hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
cat /opt/module/hadoop-3.1.3/fsimage.xml
记录块信息,几块,多大
Fsimage中只记录由哪些块组成,没有记录块所对应DataNode,为什么?
在集群刚刚启动后,加载fsimage之后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。(在安全模式里面,由DN主动向NN汇报,不让NN维护可以避免自己拿到的是陈旧的位置,)
oev查看Edits文件
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
cat /opt/module/hadoop-3.1.3/edits.xml
内部是一个个的record,记录的是一个个操作
NameNode如何确定下次开机启动的时候合并哪些Edits?
CheckPoint时间设置
通常情况下,SecondaryNameNode每隔一小时执行一次。下图所示:
hdfs-default.xml:
<property><name>dfs.namenode.checkpoint.period</name><value>3600</value>
</property>
一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value>
<description>操作动作次数</description>
</property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
(现在都用HA,不用这个)NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
2NN的数据其实只是NN的部分数据,所以这个一般不再使用
kill -9 NameNode进程
# 删除NameNode存储的数据(/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-3.1.3/data/tmp/dfs/name/*
# 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/tmp/dfs/namesecondary/* ./name/
# 重新启动NameNode
hdfs --daemon start namenode
使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode 中数据拷贝到NameNode目录中。
修改hdfs-site.xml中的
<property><name>dfs.namenode.checkpoint.period</name><value>120</value>
</property><property><name>dfs.namenode.name.dir</name><value>/opt/module/hadoop-3.1.3/data/tmp/dfs/name</value>
</property>
kill -9 NameNode进程
# 删除NameNode存储的数据(/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-3.1.3/data/tmp/dfs/name/*
# 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将
# SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/tmp/dfs/namesecondary ./rm -rf in_use.lockpwd
/opt/module/hadoop-3.1.3/data/tmp/dfsls
data name namesecondary# 导入检查点数据(等待一会ctrl+c结束掉)
bin/hdfs namenode -importCheckpoint# 启动NameNode
hdfs --daemon start namenode
集群安全模式
集群状态不正确的时候,就加入,启动的时候也会进入。
- NameNode启动
NameNode启动时,首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的Fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。这个过程期间,NameNode一直运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
- DataNode启动
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
- 安全模式退出判断
如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1,一块只要有一个副本就可以)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
- 以下内容可以不看:
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
# 查看当前模式
hdfs dfsadmin -safemode get
Safe mode is OFF
# 先进入安全模式
hdfs dfsadmin -safemode enter
# 创建并执行下面的脚本
# 在/opt/module/hadoop-3.1.3路径上,编辑一个脚本safemode.sh
touch safemode.sh
vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
chmod 777 safemode.sh./safemode.sh # 再打开一个窗口,执行
hdfs dfsadmin -safemode leave# 观察
# 观察上一个窗口
Safe mode is OFF# HDFS集群上已经有上传的数据了。
DataNode
- 原理:把文件数据整整齐齐切开之后按照block存放,想要直接自己恢复的话,可以复制出来,使用cat将文件追加,拼接起来之后直接解压就可以获取原始数据
- 块也有自己的元数据

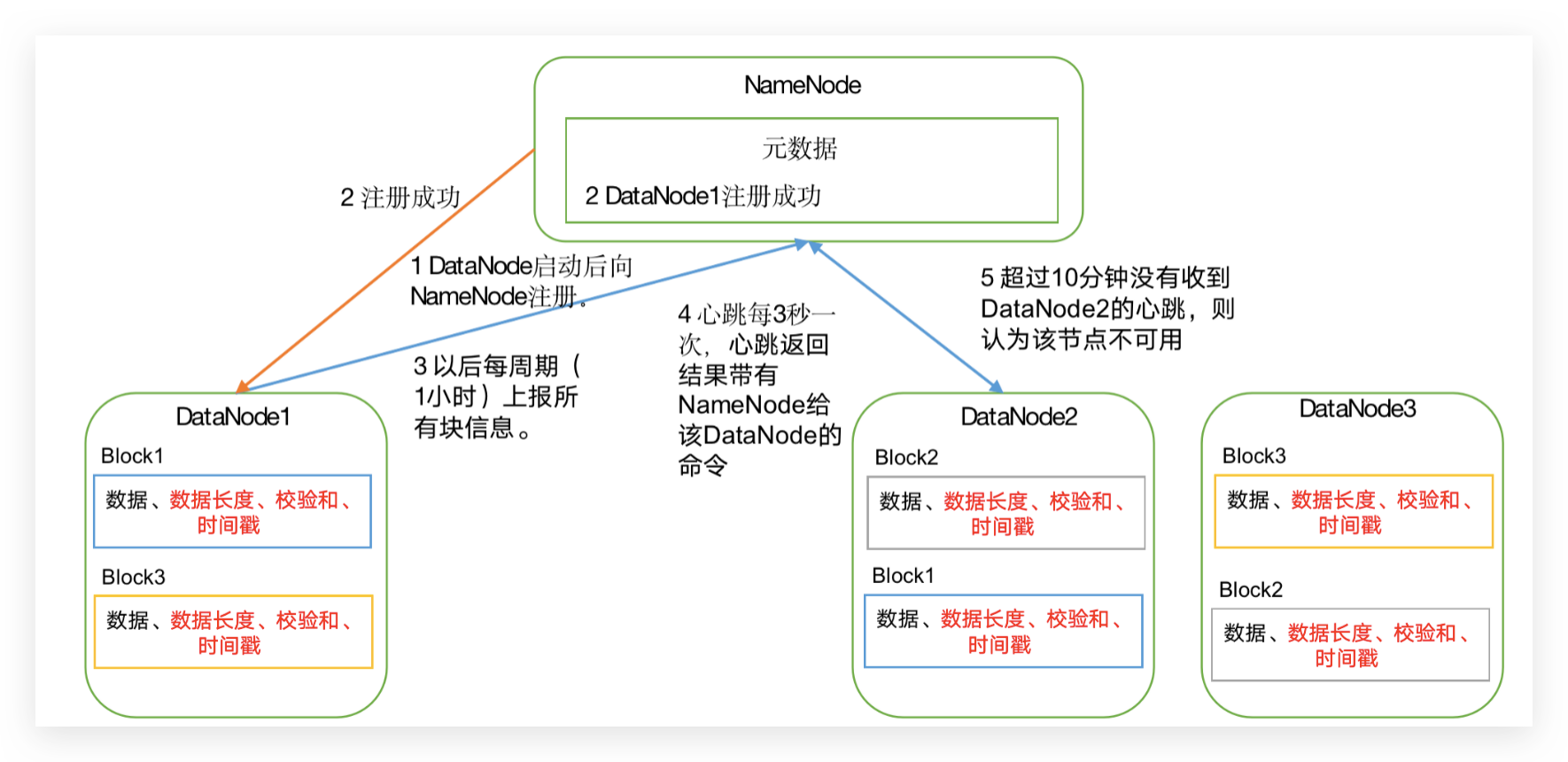
保证数据完整性的方法
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)DataNode在其文件创建后周期验证CheckSum。
掉线处理(时限设置)
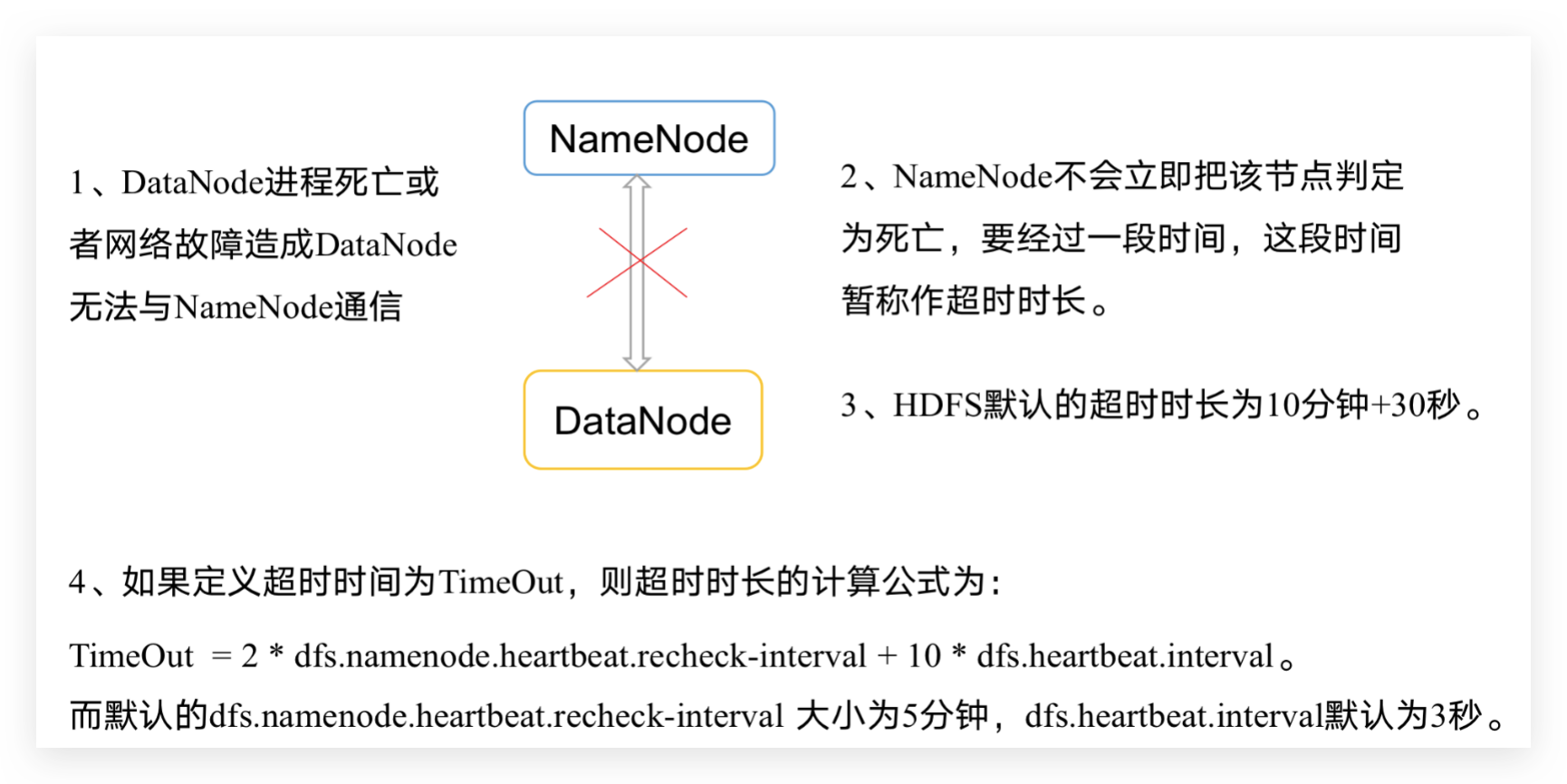
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value>
</property>
<property><name>dfs.heartbeat.interval</name><value>3</value>
</property>
添加新数据****节点
在原有集群基础上动态添加新的数据节点。
再克隆一台hadoop104主机,修改IP地址和主机名称,
-a 包含所有属性以及角色权限复制
sudo rsync -av /opt/module hadoop104:/opt
sudo rsync -av /etc/profile.d hadoop104:/etc
删除原来HDFS文件系统留存的文件(/opt/module/hadoop-3.1.3/data和log),source一下配置文件 source /etc/profile
注意这里使用的不是群起,所以不需要配置workers
# 停止DataNode
hdfs --daemon stop datanode# 直接启动DataNode,即可关联到集群
hdfs --daemon start datanode
sbin/yarn-daemon.sh start nodemanager# 在hadoop104上上传文件
hadoop fs -put /opt/module/hadoop-3.1.3/LICENSE.txt /# 如果数据不均衡,可以用命令实现集群的再平衡
./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
退役旧数据****节点
添加白****名单
添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。
# 在NameNode的/opt/module/hadoop-3.1.3/etc/hadoop目录下创建dfs.hosts文件
pwd
/opt/module/hadoop-3.1.3/etc/hadooptouch dfs.hosts
vi dfs.hosts
# 添加如下主机名称(不添加hadoop105)
hadoop102
hadoop103
hadoop104
# 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property><name>dfs.hosts</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/dfs.hosts</value>
</property>
# 配置文件分发
xsync hdfs-site.xml
# 刷新NameNode
hdfs dfsadmin -refreshNodes
Refresh nodes successful
# 更新ResourceManager节点
yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033# 在web浏览器上查看
# 如果数据不均衡,可以用命令实现集群的再平衡
./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
黑名单****退役
在黑名单上面的主机都会被强制退出。
# 在NameNode的/opt/module/hadoop-3.1.3/etc/hadoop目录下创建dfs.hosts.exclude文件
pwd
/opt/module/hadoop-3.1.3/etc/hadooptouch dfs.hosts.exclude
vi dfs.hosts.exclude
# 添加如下主机名称(要退役的节点)
hadoop105# 在NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property><name>dfs.hosts.exclude</name><value>/opt/module/hadoop-3.1.3/etc/hadoop/dfs.hosts.exclude</value>
</property># 刷新NameNode、刷新ResourceManager
hdfs dfsadmin -refreshNodes
Refresh nodes successfulyarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033# 检查Web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点
# 等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。
# 注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役# 退役之后就可以关闭,退役完成意味着数据备份完成,
# 注意这里不是群起,群关闭,所以只需要单独在需要操作的机器上关闭
hdfs --daemon stop datanode
stopping datanodesbin/yarn-daemon.sh stop nodemanager
stopping nodemanager# 如果数据不均衡,可以用命令实现集群的再平衡
sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-3.1.3/logs/hadoop-atguigu-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
# 注意:不允许白名单和黑名单中同时出现同一个主机名称。
Datanode多****目录配置
DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本
配置namenode所在的机器的hdfs-site.xml,数据就会均匀的放在data/data和data/data2
<property><name>dfs.datanode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
Hadoop3新特性
- 最低java版本由7升级为8
- 引入纠删码,默认3副本,开销较大,只是为了提高容错能力。纠删码在不到百分之50的数据冗余的情况下提供和3副本相同的容错机制,所以使用纠删码作为副本机制的改进
- 重写shell脚本。