Hyperband是机器学习中一个相当实用的超参数调优算法,核心思路是用逐次减半来分配计算资源。说白了就是让一堆配置先跑几轮,表现差的直接踢掉,剩下的继续训练更多轮次。
这个方法的巧妙之处在于平衡了探索和利用。你既要试足够多的配置组合(探索),又要给有潜力的配置足够的训练时间(利用)。传统方法要么试得不够多,要么每个都试要很久浪费时间。
本文我们来通过调优一个lstm来展示Hyperband的工作机制,并和贝叶斯优化、随机搜索、遗传算法做了对比。结果挺有意思的。
Hyperband的工作原理
Hyperband结合了多臂策略和逐次减半算法(SHA)。多臂机问题其实就是在探索新选择和利用已知好选择之间做权衡。
SHA则是具体的资源分配策略如下:给随机采样的配置分配固定预算(比如训练轮数),每轮评估后踢掉表现最差的,把剩余预算分给剩下的。Hyperband更进一步,用不同的初始预算跑多次SHA,这样既能快速筛选,又不会遗漏那些需要长时间训练才能显现优势的配置。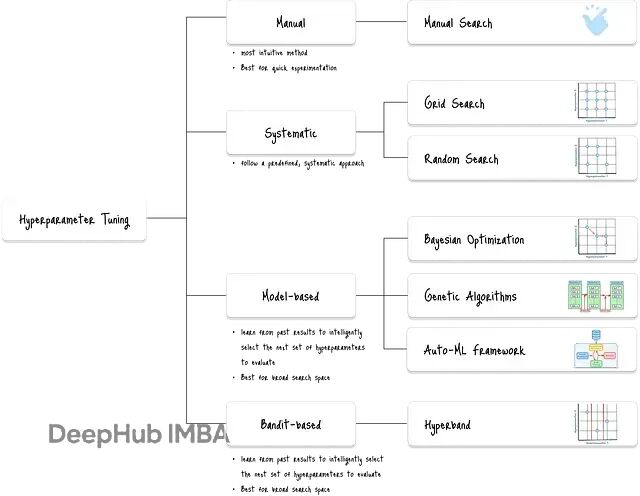
相比其他调优方法,Hyperband在处理大搜索空间时速度和效率优势明显。
https://avoid.overfit.cn/post/08d708548fdd4c19b4d9ff7973e9e612