扫描操作

由于A B C这些矩阵现在是动态的了,因此无法使用卷积表示来计算它们(卷积核是固定的),因此,我们只能使用循环表示,如此也就而失去了卷积提供的并行训练能力
Mamba通过并行扫描(parallel scan)算法使得最终并行化成为可能,其假设我们执行操作的顺序与关联属性无关。因此,我们可以分段计算序列并迭代地组合它们,即动态矩阵B和C以及并行扫描算法一起创建选择性扫描算法(selective scan algorithm)
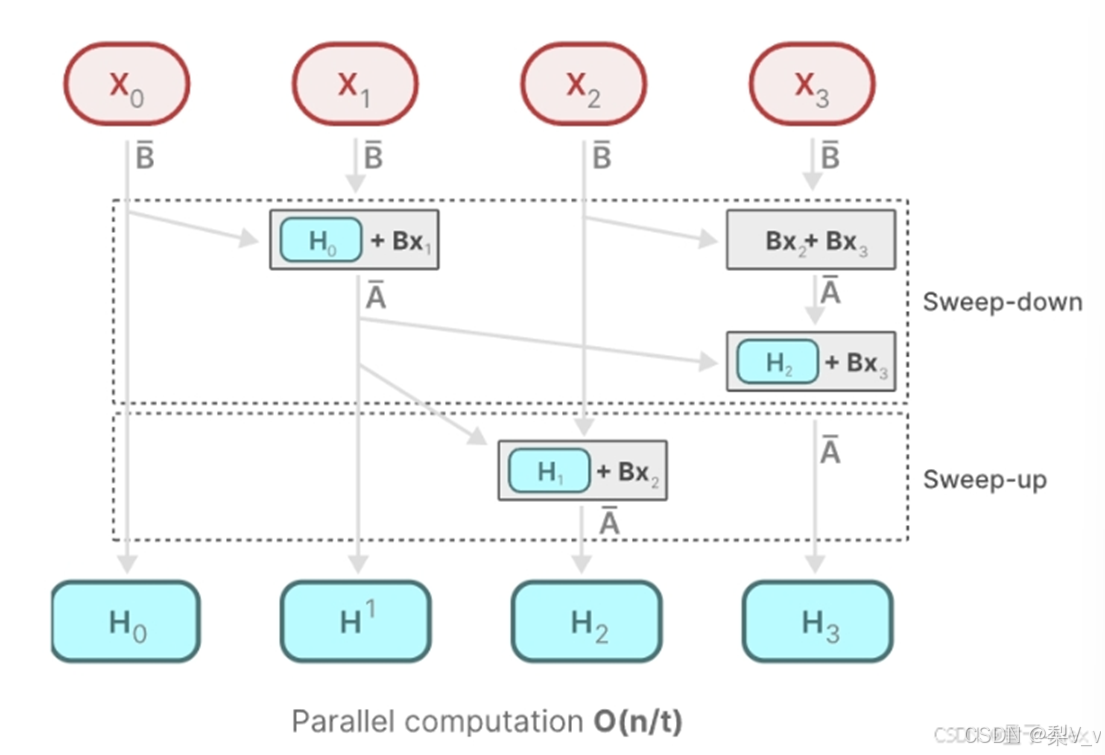
在并行计算中,时间复杂度 O(n/t) 中的 t ,通常代表用于执行任务的处理器或计算单元的数量
核融合
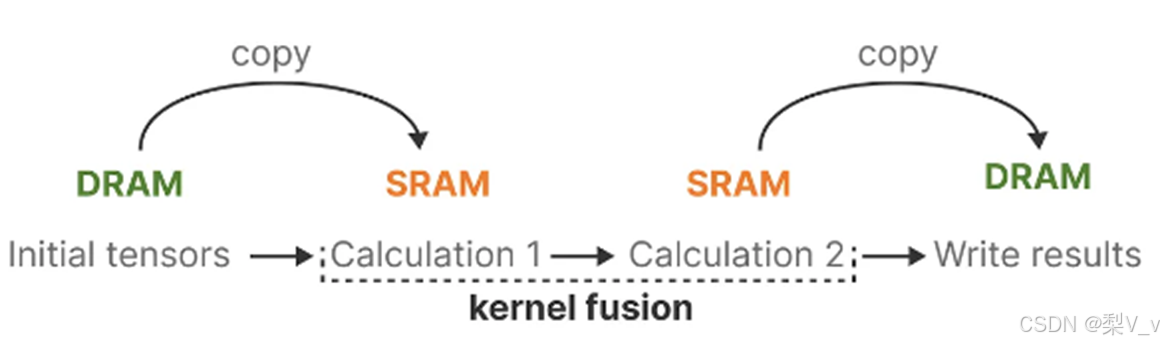
最新 GPU 的一个缺点是其小型但高效的 SRAM 与大型但效率稍低的 DRAM 之间的传输 (IO) 速度有限。在 SRAM 和 DRAM 之间频繁复制信息成为瓶颈。

Flash Attention技术
利用内存的不同层级结构处理SSM的状态,减少高带宽但慢速的HBM内存反复读写这个瓶颈
具体而言,就是限制需要从 DRAM 到 SRAM 的次数(通过内核融合kernel fusion来实现),避免一有个结果便从SRAM写入到DRAM,而是待SRAM中有一批结果再集中写入DRAM中,从而降低来回读写的次数