Disruptor框架深度解析与实战指南
目录
- Disruptor概述与背景
- 核心原理与架构设计
- 性能优化原理
- Java实战开发
- 高级特性与最佳实践
- 总结与展望
Disruptor概述与背景
什么是Disruptor
Disruptor是LMAX交易所开发的高性能线程间消息传递框架,旨在解决传统队列在高并发场景下的性能瓶颈。它基于环形缓冲区(Ring Buffer)数据结构,采用无锁设计,能够实现每秒处理超过2500万条消息,延迟低于50纳秒。
Disruptor的核心理念是"机械同情"(Mechanical Sympathy),即深入理解底层硬件工作原理来设计算法和数据结构,从而最大化CPU缓存利用率,减少锁竞争和上下文切换开销。
传统队列的性能问题
传统队列在高并发环境下面临多重性能挑战:
- 写竞争问题:多个生产者和消费者对队列头尾指针的修改会导致缓存行失效和伪共享
- 锁开销:为了保护共享状态必须使用锁机制,导致上下文切换和内核态切换
- 内存分配问题:动态节点分配增加GC压力
- 缓存不友好:链表结构的随机访问模式无法有效利用CPU预取机制
这些问题在金融服务、高频交易等低延迟场景中尤为突出。研究表明,使用传统队列的延迟成本与磁盘I/O操作相当,显著降低系统性能。
核心原理与架构设计
环形缓冲区(Ring Buffer)机制
Ring Buffer是Disruptor的核心数据结构,它是一个固定大小的循环数组,预先分配内存以避免运行时GC开销。数组结构提供了O(1)的随机访问能力,与现代CPU的缓存预取机制完美契合。

每个槽位存储事件对象,通过序列号(Sequence)来定位,计算方式为sequence & (bufferSize - 1),要求bufferSize为2的幂次方以便使用位运算替代取模运算。这种设计消除了传统队列的头尾指针竞争,实现了真正的无锁并发。
序列器(Sequencer)协调机制
Sequencer是Disruptor的并发协调核心,负责管理生产者对Ring Buffer的访问:
- 单生产者模式:使用SingleProducerSequencer,通过简单的long变量维护生产序列
- 多生产者模式:使用MultiProducerSequencer,采用CAS操作解决序列号竞争
Sequencer通过跟踪消费者的最小序列号来防止生产者覆盖未消费的数据,实现了高效的背压机制。当Ring Buffer满时,生产者会自旋等待或使用配置的等待策略,避免了传统队列的阻塞问题。
消费者依赖与屏障机制
Disruptor支持复杂的消费者依赖关系图,通过Sequence Barrier来协调消费者之间的处理顺序:
// 配置消费者依赖关系示例
disruptor.handleEventsWith(validationHandler).then(transformationHandler).then(persistenceHandler, notificationHandler);
每个消费者维护自己的Sequence指针,表示已处理到的位置。屏障会检查依赖消费者的Sequence,确保当前消费者不会超越依赖者。这种机制支持:
- 并行处理:独立消费者同时处理事件
- 流水线处理:消费者形成处理链
- 依赖处理:确保处理顺序的正确性
消费者可以批量处理事件,减少线程切换开销,同时保证处理顺序的正确性。
性能优化原理
缓存行填充与伪共享避免
伪共享是多线程性能的头号杀手,当多个线程频繁修改位于同一缓存行的不同变量时,会导致缓存行在CPU核心间来回传输。
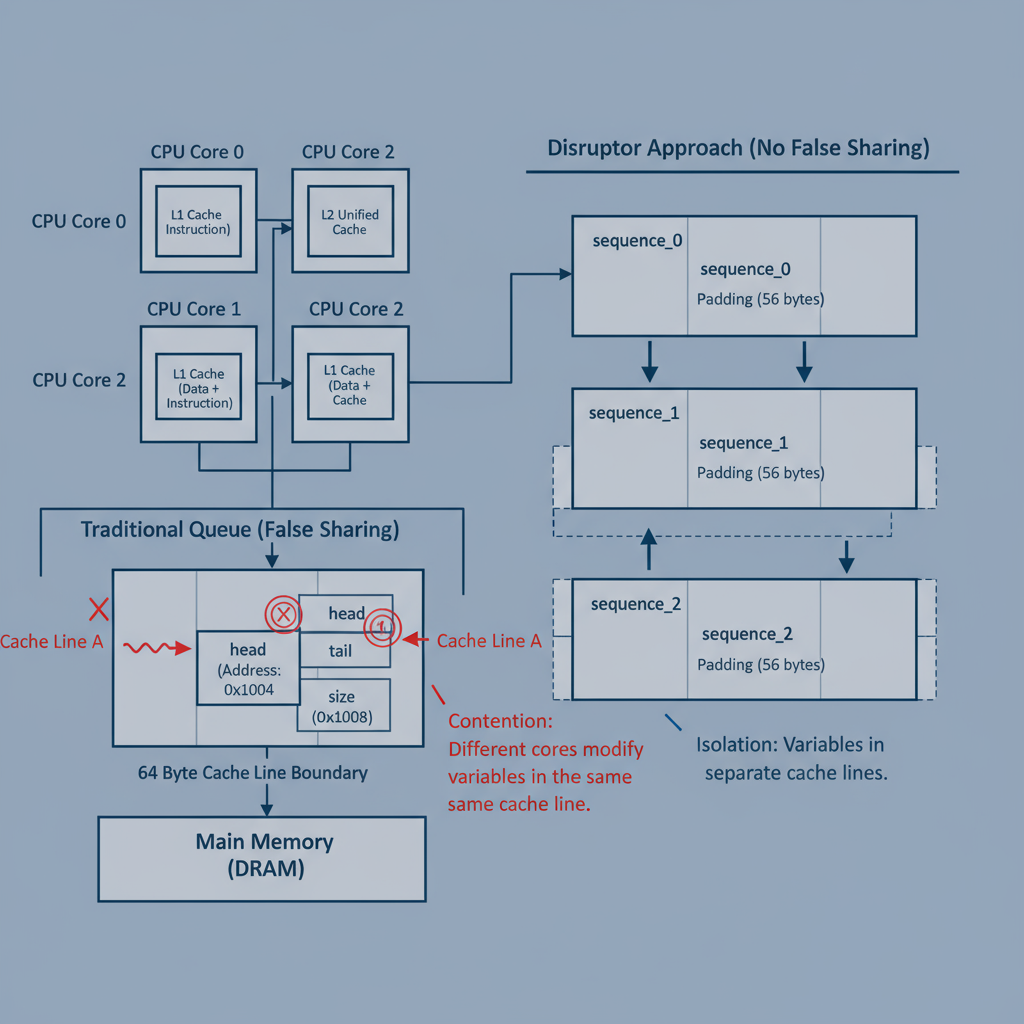
Disruptor通过缓存行填充技术解决此问题,在Sequence等关键变量周围添加足够的填充字节,确保每个变量独占一个缓存行(通常64字节):
public class Sequence extends RhsPadding {private volatile long value;// 填充确保独占缓存行private long p1, p2, p3, p4, p5, p6, p7;
}
这种设计消除了伪共享带来的性能损失,是Disruptor高性能的关键因素之一。
单写入者原则与内存屏障
单写入者原则是Disruptor设计的核心原则:任何内存位置在任何时候都只有一个线程写入。这避免了写竞争,使得CPU可以高效地管理缓存一致性。
生产者写入事件数据后,通过内存屏障确保修改对所有消费者可见:
// 生产者发布事件流程
long sequence = ringBuffer.next(); // 1. 获取序列号
try {BasicEvent event = ringBuffer.get(sequence); // 2. 获取事件对象event.set(data); // 3. 填充数据
} finally {ringBuffer.publish(sequence); // 4. 发布事件(内存屏障)
}
这种设计充分利用了现代CPU的弱一致性模型,通过显式的内存屏障指令来控制指令重排序,在保证正确性的同时最大化并行性能。
性能对比分析
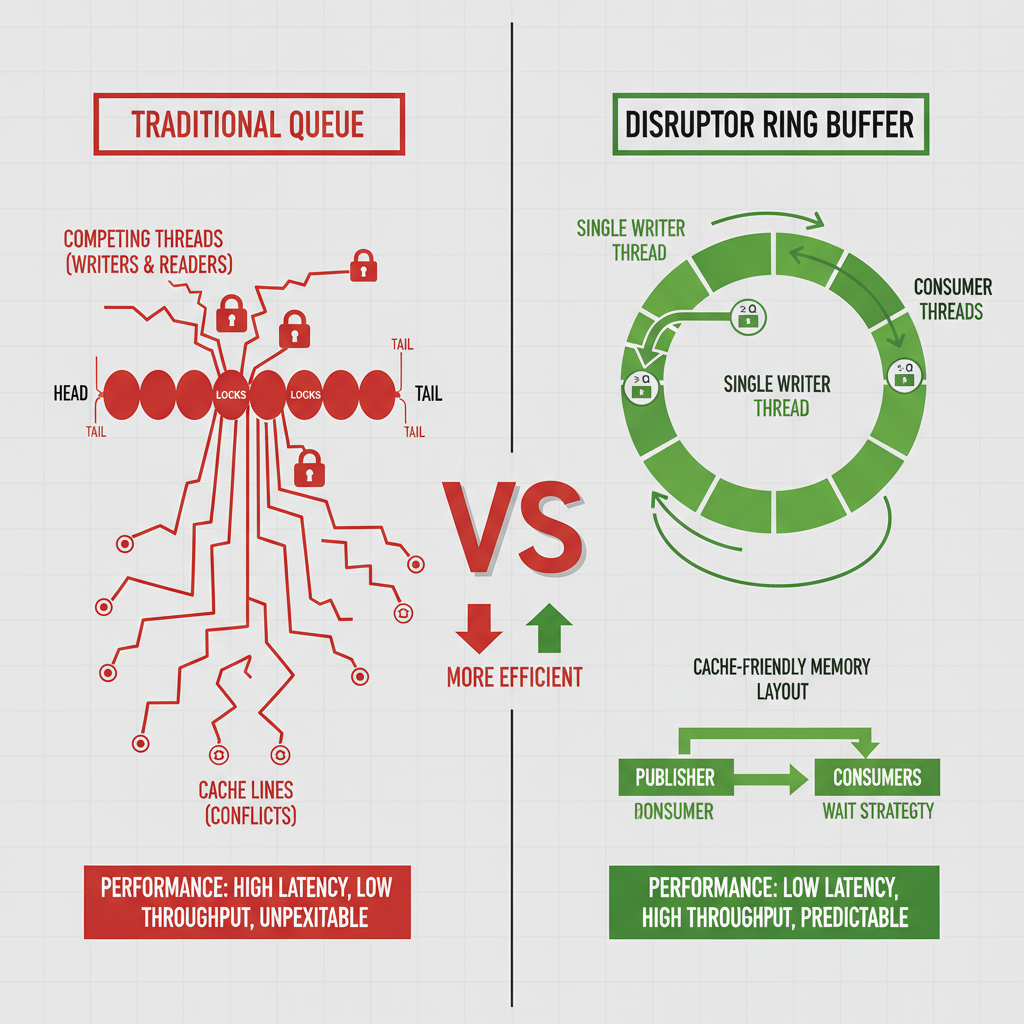
根据LMAX的基准测试结果:
- 延迟:Disruptor比传统队列低3个数量级
- 吞吐量:在三阶段流水线中处理能力约高出8倍
- 无锁设计:避免了锁竞争和上下文切换开销
Java实战开发
基础事件模型设计
在Disruptor中,事件是数据传输的基本单元。设计良好的事件模型应该包含所有必要的业务数据,避免频繁的对象创建:
public class BasicEvent {private long value;private String message;private long timestamp;public void set(long value, String message) {this.value = value;this.message = message;this.timestamp = System.nanoTime();}public void clear() {this.value = 0;this.message = null;this.timestamp = 0;}// getters and setters...
}
事件工厂负责创建事件实例,Disruptor在启动时会预先创建所有事件对象:
public class BasicEventFactory implements EventFactory<BasicEvent> {@Overridepublic BasicEvent newInstance() {return new BasicEvent();}
}
生产者实现模式
Disruptor支持多种生产者模式,单生产者模式性能最优,多生产者模式通过CAS操作协调序列号分配:
// 单生产者模式
Disruptor<BasicEvent> disruptor = new Disruptor<>(eventFactory,BUFFER_SIZE,executor,ProducerType.SINGLE, // 单生产者new YieldingWaitStrategy()
);// 多生产者模式
Disruptor<BasicEvent> disruptor = new Disruptor<>(eventFactory,BUFFER_SIZE,executor,ProducerType.MULTI, // 多生产者new BusySpinWaitStrategy()
);
生产者发布事件的流程:
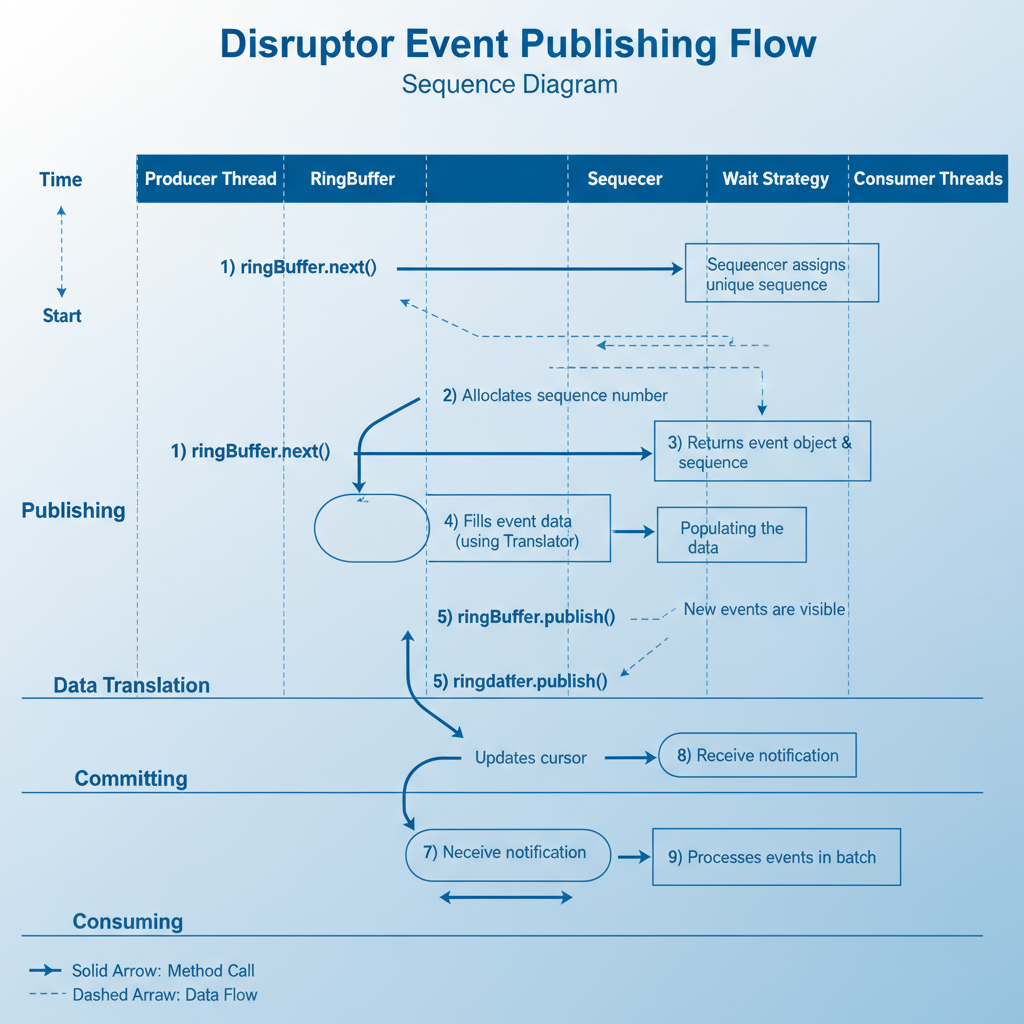
// 事件发布示例
public void publishEvent(long value, String message) {long sequence = ringBuffer.next(); // 1. 获取序列号try {BasicEvent event = ringBuffer.get(sequence); // 2. 获取事件对象event.set(value, message); // 3. 填充数据} finally {ringBuffer.publish(sequence); // 4. 发布事件}
}// 使用EventTranslator简化代码
public static final EventTranslator<BasicEvent> TRANSLATOR = (event, sequence, buffer) -> {event.set(buffer.getLong(0), "Translated-" + sequence);};ringBuffer.publishEvent(TRANSLATOR, byteBuffer);
消费者处理器实现
消费者通过实现EventHandler接口来处理事件:
public class BasicEventHandler implements EventHandler<BasicEvent> {private final String handlerName;private long processedCount = 0;@Overridepublic void onEvent(BasicEvent event, long sequence, boolean endOfBatch) throws Exception {// 处理事件逻辑processEvent(event);processedCount++;// 批处理优化if (endOfBatch) {// 批量提交数据库等操作}}
}
Disruptor支持复杂的消费者配置:
// 独立消费者并行处理
disruptor.handleEventsWith(handler1, handler2, handler3);// 依赖消费者形成处理链
disruptor.handleEventsWith(handler1).then(handler2);// 复杂依赖关系
disruptor.handleEventsWith(handler1, handler2).then(handler3).then(handler4, handler5);
完整示例代码
SimpleDisruptorExample.java - 单生产者单消费者示例:
public class SimpleDisruptorExample {private static final int BUFFER_SIZE = 1024;private static final int EVENT_COUNT = 1000000;public static void main(String[] args) throws InterruptedException {// 创建DisruptorDisruptor<BasicEvent> disruptor = new Disruptor<>(new BasicEventFactory(),BUFFER_SIZE,Executors.newCachedThreadPool(),ProducerType.SINGLE,new YieldingWaitStrategy());// 注册处理器disruptor.handleEventsWith(new BasicEventHandler("MainHandler"));disruptor.start();// 生产者逻辑RingBuffer<BasicEvent> ringBuffer = disruptor.getRingBuffer();for (long i = 0; i < EVENT_COUNT; i++) {long sequence = ringBuffer.next();try {BasicEvent event = ringBuffer.get(sequence);event.set(i, "Message-" + i);} finally {ringBuffer.publish(sequence);}}// 关闭资源disruptor.shutdown();}
}
AdvancedDisruptorExample.java - 多生产者多消费者示例:
public class AdvancedDisruptorExample {public static void main(String[] args) throws InterruptedException {// 多生产者配置Disruptor<BasicEvent> disruptor = new Disruptor<>(new BasicEventFactory(),BUFFER_SIZE,executor,ProducerType.MULTI,new BusySpinWaitStrategy());// 复杂消费者依赖关系disruptor.handleEventsWith(validationHandler).then(transformationHandler).then(persistenceHandler, notificationHandler);// 多生产者逻辑for (int i = 0; i < PRODUCER_COUNT; i++) {final int producerId = i;new Thread(() -> {for (long j = 0; j < EVENTS_PER_PRODUCER; j++) {long sequence = ringBuffer.next();try {BasicEvent event = ringBuffer.get(sequence);event.set(producerId * 1000000L + j, "Producer-" + producerId);} finally {ringBuffer.publish(sequence);}}}).start();}}
}
PerformanceTest.java - 性能测试对比:
public class PerformanceTest {private static long testDisruptor(int messageCount) throws InterruptedException {Disruptor<BasicEvent> disruptor = new Disruptor<>(new BasicEventFactory(),BUFFER_SIZE,Executors.newCachedThreadPool(),ProducerType.SINGLE,new BusySpinWaitStrategy());// 添加处理器和计数逻辑disruptor.handleEventsWith(new EventHandler<BasicEvent>() {private final AtomicLong count = new AtomicLong(0);@Overridepublic void onEvent(BasicEvent event, long sequence, boolean endOfBatch) {if (count.incrementAndGet() == messageCount) {latch.countDown();}}});long startTime = System.nanoTime();// 生产消息逻辑...long endTime = System.nanoTime();return TimeUnit.NANOSECONDS.toMillis(endTime - startTime);}
}
高级特性与最佳实践
等待策略选择与调优
等待策略决定了消费者等待新事件时的行为,直接影响延迟和CPU使用率:
| 等待策略 | 延迟 | CPU使用率 | 适用场景 |
|---|---|---|---|
| BusySpinWaitStrategy | 最低 | 最高 | 高频交易、超低延迟 |
| YieldingWaitStrategy | 低 | 中等 | 平衡性能和CPU使用 |
| SleepingWaitStrategy | 中等 | 低 | 后台处理、非关键路径 |
| BlockingWaitStrategy | 高 | 最低 | 传统阻塞场景 |
选择合适的等待策略需要考虑业务需求、硬件资源和并发级别:
// 高频交易场景 - 最低延迟
Disruptor<BasicEvent> disruptor = new Disruptor<>(eventFactory, BUFFER_SIZE, executor,ProducerType.SINGLE,new BusySpinWaitStrategy() // CPU密集但延迟最低
);// Web应用 - 平衡性能和资源使用
Disruptor<BasicEvent> disruptor = new Disruptor<>(eventFactory, BUFFER_SIZE, executor,ProducerType.MULTI,new YieldingWaitStrategy() // 平衡选择
);// 批处理系统 - 资源友好
Disruptor<BasicEvent> disruptor = new Disruptor<>(eventFactory, BUFFER_SIZE, executor,ProducerType.MULTI,new SleepingWaitStrategy() // CPU友好
);
性能监控与调优技巧
Disruptor提供了丰富的监控接口来获取运行时状态:
public class DisruptorMonitor {private final Disruptor<BasicEvent> disruptor;private final ScheduledExecutorService monitorExecutor;public void startMonitoring() {monitorExecutor.scheduleAtFixedRate(() -> {RingBuffer<BasicEvent> ringBuffer = disruptor.getRingBuffer();// 监控RingBuffer状态long cursor = ringBuffer.getCursor();long remainingCapacity = ringBuffer.remainingCapacity();logger.info("RingBuffer Status - Cursor: {}, Remaining Capacity: {}", cursor, remainingCapacity);// 监控消费者进度for (Sequence sequence : disruptor.getRingBuffer().getGatingSequences()) {logger.info("Consumer Sequence: {}", sequence.get());}}, 0, 1, TimeUnit.SECONDS);}
}
调优技巧包括:
- 合理设置Ring Buffer大小:过小会导致频繁等待,过大增加内存占用
- 优化事件对象结构:减少内存访问,避免复杂嵌套
- 使用批量处理:提高吞吐量,减少方法调用开销
- 配置线程优先级:确保关键线程获得足够CPU时间
- 避免阻塞操作:在事件处理中避免IO操作
异常处理与容错机制
Disruptor提供了完善的异常处理机制:
// 设置异常处理器
disruptor.setDefaultExceptionHandler(new ExceptionHandler<BasicEvent>() {@Overridepublic void handleEventException(Throwable ex, long sequence, BasicEvent event) {logger.error("Error processing event at sequence: " + sequence, ex);// 记录错误事件,发送到错误队列等}@Overridepublic void handleOnStartException(Throwable ex) {logger.error("Error starting disruptor", ex);}@Overridepublic void handleOnShutdownException(Throwable ex) {logger.error("Error shutting down disruptor", ex);}
});// 特定处理器的异常处理
public class RobustEventHandler implements EventHandler<BasicEvent> {private static final int MAX_RETRIES = 3;@Overridepublic void onEvent(BasicEvent event, long sequence, boolean endOfBatch) {int retries = 0;Exception lastException = null;while (retries < MAX_RETRIES) {try {processWithRetry(event);return; // 成功处理} catch (Exception e) {lastException = e;retries++;if (retries < MAX_RETRIES) {// 指数退避重试try {Thread.sleep(100 * retries);} catch (InterruptedException ie) {Thread.currentThread().interrupt();return;}}}}// 重试失败,记录错误或发送到DLQlogger.error("Failed to process event after {} retries", MAX_RETRIES, lastException);sendToDeadLetterQueue(event);}
}
实际应用案例分析
金融交易系统
在高频交易系统中,Disruptor用于处理市场行情和订单流:
// 市场行情处理器
public class MarketDataHandler implements EventHandler<MarketDataEvent> {private final PriceEngine priceEngine;private final RiskManager riskManager;@Overridepublic void onEvent(MarketDataEvent event, long sequence, boolean endOfBatch) {// 快速价格计算double price = priceEngine.calculatePrice(event);// 风险检查if (riskManager.checkLimit(price, event.getQuantity())) {// 发送订单到交易所sendOrder(new Order(price, event.getQuantity()));}}
}// 配置超低延迟的Disruptor
Disruptor<MarketDataEvent> disruptor = new Disruptor<>(new MarketDataFactory(),8192, // 较小的缓冲区减少延迟new AffinityThreadFactory("market-data"),ProducerType.SINGLE,new BusySpinWaitStrategy() // 最低延迟
);
日志聚合系统
在大规模日志处理中,Disruptor用于高效的日志收集和分发:
public class LogEventHandler implements EventHandler<LogEvent> {private final ElasticsearchClient esClient;private final List<LogEvent> batch = new ArrayList<>(BATCH_SIZE);@Overridepublic void onEvent(LogEvent event, long sequence, boolean endOfBatch) {batch.add(event);if (endOfBatch || batch.size() >= BATCH_SIZE) {// 批量写入ElasticsearchesClient.bulkIndex(batch);batch.clear();}}
}
总结与展望
Disruptor代表了并发编程领域的一个重要里程碑,它通过深入理解硬件工作原理,重新定义了高性能线程间通信的标准。掌握Disruptor不仅需要理解其API使用,更重要的是理解其设计哲学和性能优化原理。
关键要点总结
- 核心原理:环形缓冲区 + 无锁设计 + 机械同情
- 性能优势:低延迟、高吞吐量、缓存友好
- 设计模式:单写入者、事件驱动、批量处理
- 适用场景:高频交易、实时系统、日志处理
最佳实践建议
- 合理配置:根据业务场景选择合适的等待策略和缓冲区大小
- 对象重用:充分利用事件对象重用机制,避免GC压力
- 批量优化:利用批处理能力提高吞吐量
- 监控调优:持续监控系统性能指标,及时调整配置
未来发展趋势
随着现代硬件的不断发展,Disruptor的设计理念将继续影响未来的并发编程模式:
- 硬件加速:利用CPU新特性进一步优化性能
- 分布式扩展:将Disruptor模式应用到分布式系统
- 云原生适配:更好地支持容器化和微服务架构
- AI/ML集成:结合机器学习优化参数配置
Disruptor不仅是一个框架,更是一种思维方式,它教会我们如何与硬件"对话",如何设计出真正高效的并发系统。在实际应用中,应该根据具体场景选择合适的配置,持续监控和调优系统性能,才能充分发挥Disruptor的强大能力。
参考文献
- LMAX Disruptor官方文档
- Disruptor技术论文
- Martin Fowler - LMAX架构
- Disruptor源码分析
本文档基于Disruptor 3.4.4版本编写,包含完整的原理讲解、实战代码和性能优化指南。如需最新信息,请参考官方文档。