
1. k8s 架构
K8s 属于经典的主从模型(Master-Slave 架构),由 Master 和 Node 节点构成:
- Master 节点:负责集群的管理,协调集群中的所有活动。例如应用的运行、修改、更新等。
- Node 节点:为 Kubernetes 集群中的工作节点,可以是 VM 虚拟机、物理机。每个 node 上有一个 Kubelet(负责每个节点的运行状态,以及与 master 节点通信,执行 master 节点的指令),同时 Node 节点上至少还需要运行 container runtime(比如 docker,这样才能够运行相关镜像)。
简单的示意图架构图如下所示:
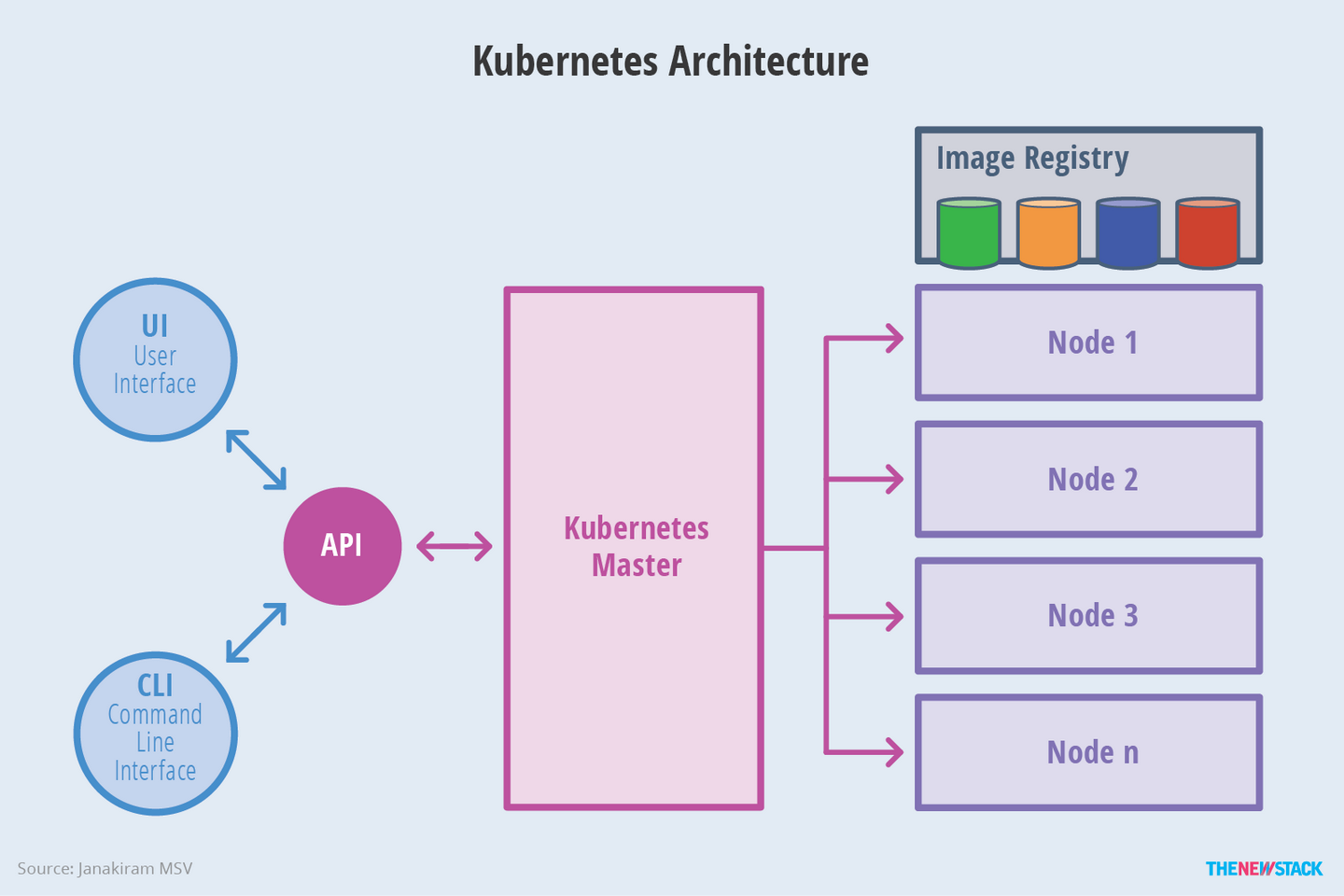
完整的架构图如下所示,其中 Node 中的 pod 可以理解为运行应用程序的容器,例如运行java的一个微服务jar包,至于其他的组件,将在后面进行详细介绍。
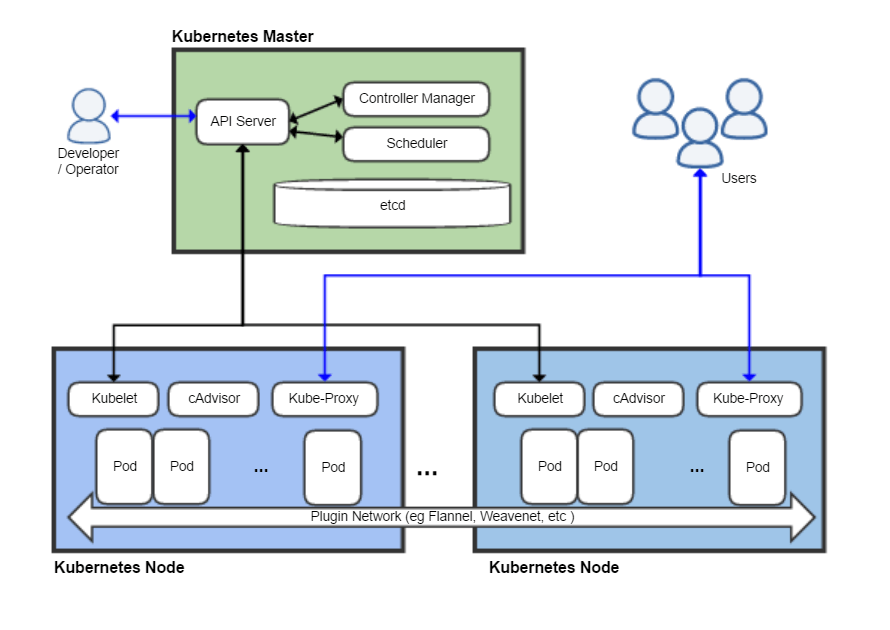
2. Master 节点
Master节点是整个k8s的大脑
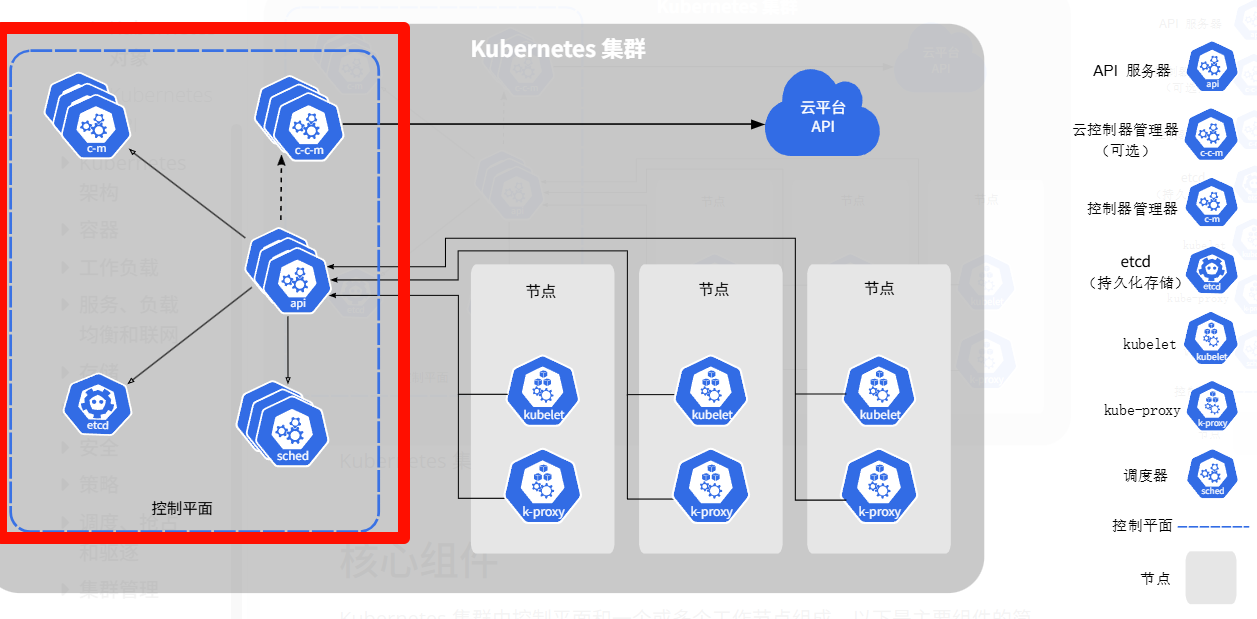
Master 节点也被称之为控制平面组件,也就是上图中红色框中的区域。Master 节点一般来说,由如下构成:
-
kube-apiserver:提供 RESTful API,供用户、kubectl、其他组件和外部系统调用。无状态,可水平扩展,通常部署多个实例实现高可用。
-
etcd:分布式键值数据库,存储集群的所有配置数据和状态信息(如节点、Pod、Service 等对象的状态,配置文件)。所有组件通过 apiserver 读写 etcd,不直接访问。一般来说是部署多个节点,使用 Raft 协议保证一致性。
-
kube-scheduler:负责 Pod 的调度,决定将新创建的 Pod 分配到哪个 Node 上运行。
-
kube-controller-manager(图中 c-m):运行控制器进程,确保集群的实际状态与期望状态一致。这句话听起来似乎有点抽象,但是实际上我们可以把它理解为一个管家,它不断检查集群的“实际状态”,并努力让它与用户定义的“期望状态”保持一致。 例如说,我希望我的集群中有 3 个 nginx pod 在运行(通过相关配置文件进行定义),突然有一个 pod 挂了,gg 了,那么 c-m 就会重新拉起来一个 pod,执行顺序如下:
- c-m 从 apiserver 读取“期望状态”(比如 replicas: 3)
- 从 apiserver 读取“当前实际状态”(比如现在只有 2 个 Pod 在运行)
- 如果不一致 → 执行操作(比如创建 1 个新 Pod)
- 写回 apiserver,更新状态
- 休息一会儿,然后重复步骤 1~5
-
cloud-controller-manager(图中 c-c-m):是 Kubernetes 与底层云平台(如 AWS、Azure、阿里云等)之间的“翻译官”和“对接员”,专门处理那些需要和云厂商 API 交互的功能。
3. Node 节点
Master 节点我们已经理解了,那么什么是 Node 节点呢。Node 节点(也称之为 Worker 节点),就是真正“运行应用”的 worker。在现实世界,Node 节点可以是一台物理服务器,一台 VM 虚拟机(一个 Node 节点严格对应一台“计算实例”),但是注意,Node 节点不是容器(Node 是运行容器的宿主机)。下图中,红色框框里面的内容便是 Node 节点。
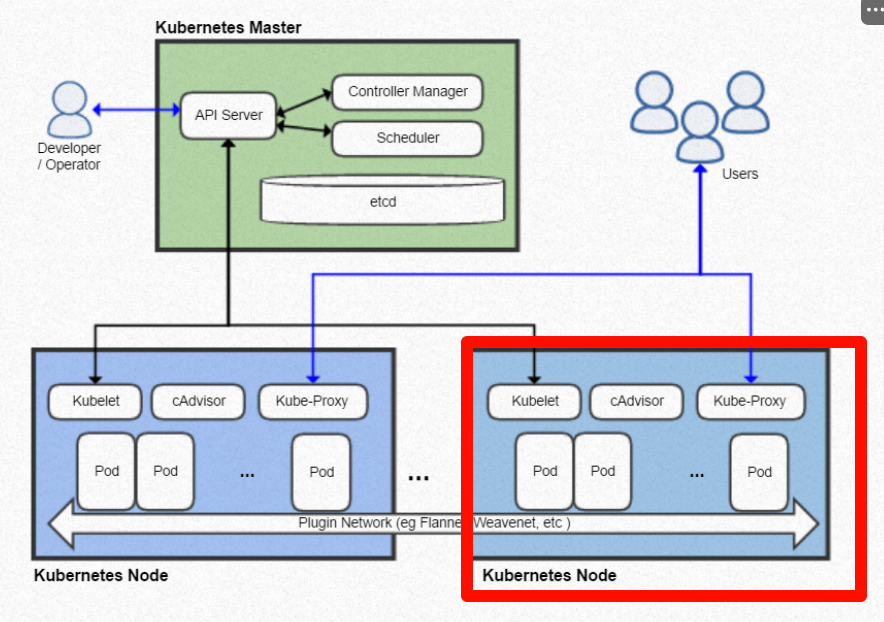
Node 节点主要包含如下组件:
- kubelet:负责与 Master 通信、接收调度指令、调用容器运行时启动或终止 Pod,并向 api-server 持续上报节点和容器的健康状态。执行探针,挂载卷,设置网络等等。每个 node 必须要有一个 kubelet。
- Container Runtime(容器运行时):根据 kubelet 的指令,拉取镜像、创建/启动/停止容器,管理容器的生命周期。如果简单的理解,你就可以把他看成一个 docker,可以运行相关的镜像。
- kube-proxy:在 每个 Node 上维护网络规则(如 iptables 或 IPVS),将访问流量(Service 的流量)转发到后端 Pod。每个 Node 都需要运行 kube-proxy,因为如果一个容器不跟外界通信,那么也毫无意义。
- cAdvisor:用于自动发现并收集当前 Node 节点上所有容器(包括 Pod 中的容器)的资源使用情况和性能数据,比如 CPU、内存、磁盘 I/O、网络使用率等。
4. 命名空间
k8s 集群在搭建好之后,需要提供给多个部门或者小组进行使用。而在我们开发和生产过程中,大概率不同小组可能会出现相同的资源(例如应用,服务)名,同时每个小组需要的计算资源数量也可能不同,以及每个小组的权限也不同(例如开发团队不能访问生产环境)。为了解决这个问题,k8s 提出了命名空间(namespace)的概念(默认的命名空间是default),命名空间有如下好处:
-
资源隔离
- 不同命名空间中的资源名称可以重复(例如两个命名空间中都可以有名为
web-app的 Deployment)。 - 避免资源命名冲突。
- 限制资源使用(配合 ResourceQuota 和 LimitRange)。
- 不同命名空间中的资源名称可以重复(例如两个命名空间中都可以有名为
-
权限控制(RBAC)
- 可以为不同命名空间设置不同的访问权限。例如:开发团队只能访问
dev 命名空间,运维团队可访问prod。
- 可以为不同命名空间设置不同的访问权限。例如:开发团队只能访问
-
环境隔离
- 将开发(dev)、测试(test)、预发布(staging)、生产(prod)环境部署在不同命名空间中,便于管理。
-
简化管理
- 可以按命名空间批量操作资源(如删除整个命名空间及其所有资源)。
- 日志、监控、网络策略等也可以按命名空间维度配置。
但是需要注意的是,在 k8s 集群中,不同的命名空间里面应用,其网络是互通的。如果要避免网络互通,则需要进行相关的网络配置。在比较大型的网络开发中,还是推荐将生产和测试集群分开部署,而不是依赖于命名空间进行隔离。
5. 参考
- Kubernetes - 维基百科,自由的百科全书
- 从零开始的 K8S 学习笔记(一)概念入门 - 知乎