LLM 在发挥作用。它不仅改变了人与计算机的交互方式,也推动了产业和学术的深刻变革。就是在人工智能的众多分支中,LLM(大语言模型)是近年来最受关注的核心技术。ChatGPT、Claude、文心一言等应用的背后,都
一、术语定义
LLM(Large Language Model,大语言模型)是一类基于海量文本数据训练的深度学习模型,核心任务是理解和生成自然语言。
其本质是依据预测“下一个最可能的词”来完成各种语言任务,这种机制称为“自回归生成”(autoregressive generation)。
Large(大):指模型规模庞大,拥有数十亿乃至数万亿参数。
Language(语言):专注于自然语言(人类的文字、符号、语音转写等)。
Model(模型):基于神经网络(尤其是 Transformer 架构)实现。
二、提出背景
1、传统 NLP 的局限
早期方法依赖人工规则(如语法树)。后来依靠统计模型(如 n-gram、HMM),但无法处理复杂语境。
2、深度学习突破
RNN、LSTM 解决了部分序列建模困难,但难以捕捉长距离依赖。
3、Transformer 的出现(2017)
《Attention Is All You Need》提出的 Transformer 结构,用注意力机制有效建模上下文。
GPT、BERT 等模型相继问世,奠定了 LLM 的科技基石。
三、工作原理
LLM 的核心机制可以用“预测下一个词”来理解:
1、输入文本 → 被切分为 token(最小语言单元,可能是词、子词或字符。在英文中常以子词为主,在中文中常以单字为主)。
2、嵌入表示 → 每个 token 转换为向量。
3、Transformer 架构编码 → 注意力机制建模上下文关系。
4、输出预测 → 模型计算下一个 token 的概率分布,再逐步生成句子。
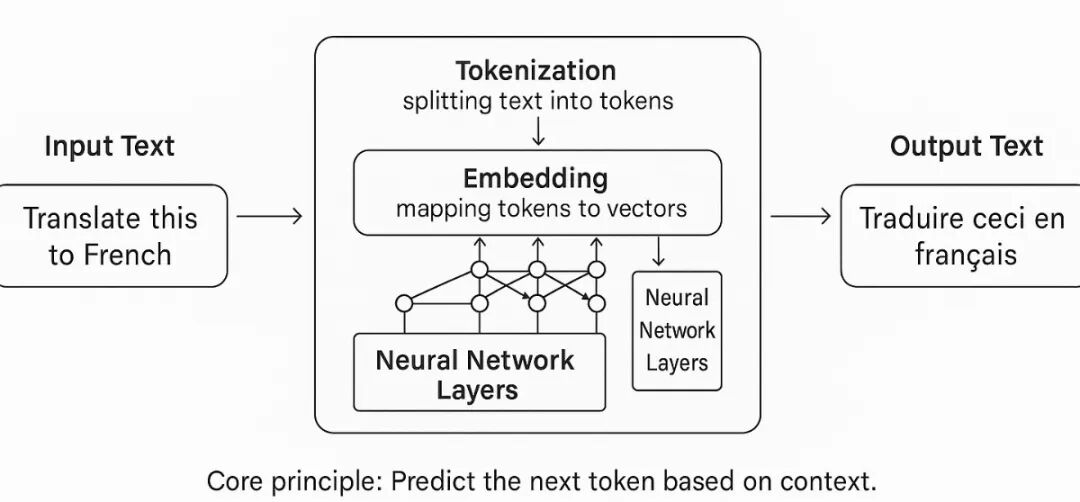
示意图由 DALL-E 生成
类比理解:
就像一个读书万卷的学生,他在写作文时不会逐字死记,而是根据上下文“预测”接下来该写什么,从而形成流畅连贯的表达。
四、典型模型
1、GPT 系列(OpenAI)
GPT-1(2018):验证生成式预训练可行。
GPT-3(2020):1750 亿参数,少样本学习成为现实。
GPT-4(2023):更强的推理与稳健性。
GPT-5(2025):多模态能力大幅增强。
2、BERT 系列(Google)
强调“理解”,在问答与分类任务中表现突出。
3、国内外开源模型
LLaMA(Meta)、Mistral、通义千问、文心一言、百川等。
五、应用场景
1、对话系统:ChatGPT、智能客服、语音助手。
2、写作与翻译:自动生成文章、摘要、诗歌、跨语言翻译。
3、代码生成:GitHub Copilot,辅助编程、自动修复。
4、教育与科研:解题、写作辅助、学术资料检索。
5、知识管理:企业文档问答、搜索引擎增强。
6、创意与娱乐:剧本、歌词、角色扮演。
六、优势与挑战
优势:
通用性强:一套模型可适配多任务。
少样本/零样本学习:无需大规模标注内容即可完成新任务。
多模态扩展:不仅处理文本,还能理解图像、音频、视频。
挑战:
资源消耗大:训练需海量算力和数据。
可解释性差:预测过程如“黑箱”。
偏见(Bias):可能继承材料中的不公正模式。
幻觉(Hallucination):生成听起来合理但与事实不符的内容,不仅是错误,更是“编造”。
安全与监管:涉及信息安全、隐私和伦理。
小结
LLM(大语言模型)的本质是基于 Transformer 架构,依据预测下一个词来理解与生成语言。
它的意义在于:
让计算机第一次具备了近似人类的语言理解与表达能力;
使 AI 从“专用工具”迈向“通用助手”,并逐步具备跨模态和复杂推理的能力;
推动了 AIGC 的全面爆发,并成为迈向 AGI 的关键一步。
未来,LLM 的演进不仅影响着 AIGC 的发展方向,更是实现通用人工智能(AGI)的关键基石。

“点赞有美意,赞赏是鼓励”