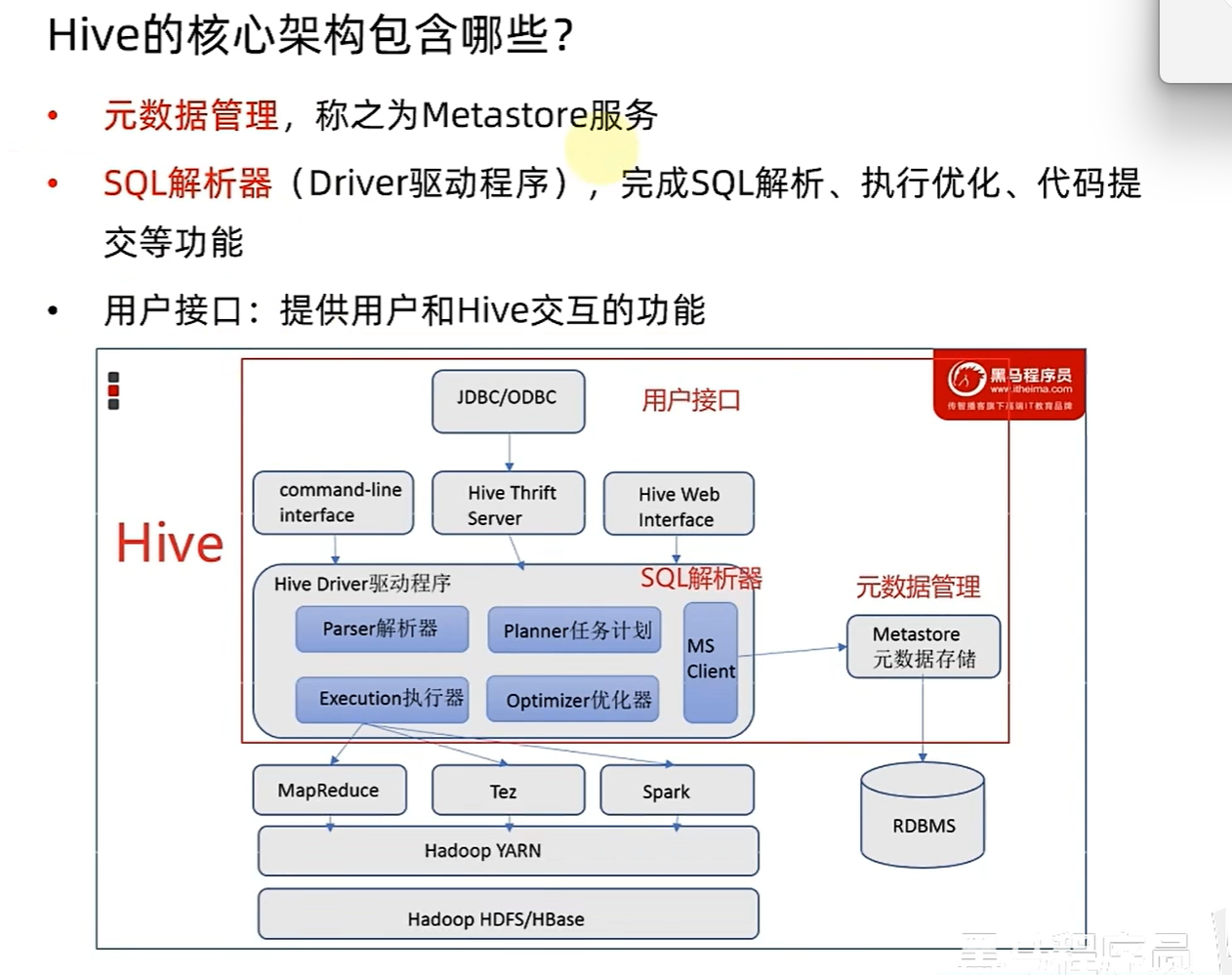
分布式SQL计算



Hive 基础架构
切换java版本
ln -sfn /export/server/jdk1.8.0_361 /export/server/jdk # 切换回 JDK8
ln -sfn /export/server/jdk-17.0.12 /export/server/jdk # 切换到 JDK17
#启动HDFS
start-dfs.sh
#启动YARN集群
start-yarn.sh
#启动或停止历史服务器
mapred --daemon start historyserver#启动元数据管理服务(hive目录下)
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &#启动Hive客户端(hive目录下)
bin/hive#先启动metastore服务 然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &#启动Beeline
bin/beeline
#连接Hdfs(在Beeline里) (用户:hadoop 密码:空)
! connect jdbc:hive2://node1:10000http://node1:9870 // 查看HDFS系统的状态
http://node1:8088 //查看YARN集群的监控界面
这里使用Tez 报错 修改为MR,可以正常启动Hive

# 切到 JDK 17
cd /export/server && rm -f jdk && ln -s /export/server/jdk-17.0.12 jdk && java -version# 切到 JDK 1.8
cd /export/server && rm -f jdk && ln -s /export/server/jdk1.8.0_361 jdk && java -version
Hive客户端
HiveServer2

Hive操作
创建数据库

创建表
show databases;// 创建数据库
create database myhive;desc database myhive;use myhive;
create table test(id int,name string,gender string
);//删除数据库表
drop table test;内部表与外部表

内外部表转换

数据加载和导出
加载 local是从Linux系统上传


导出
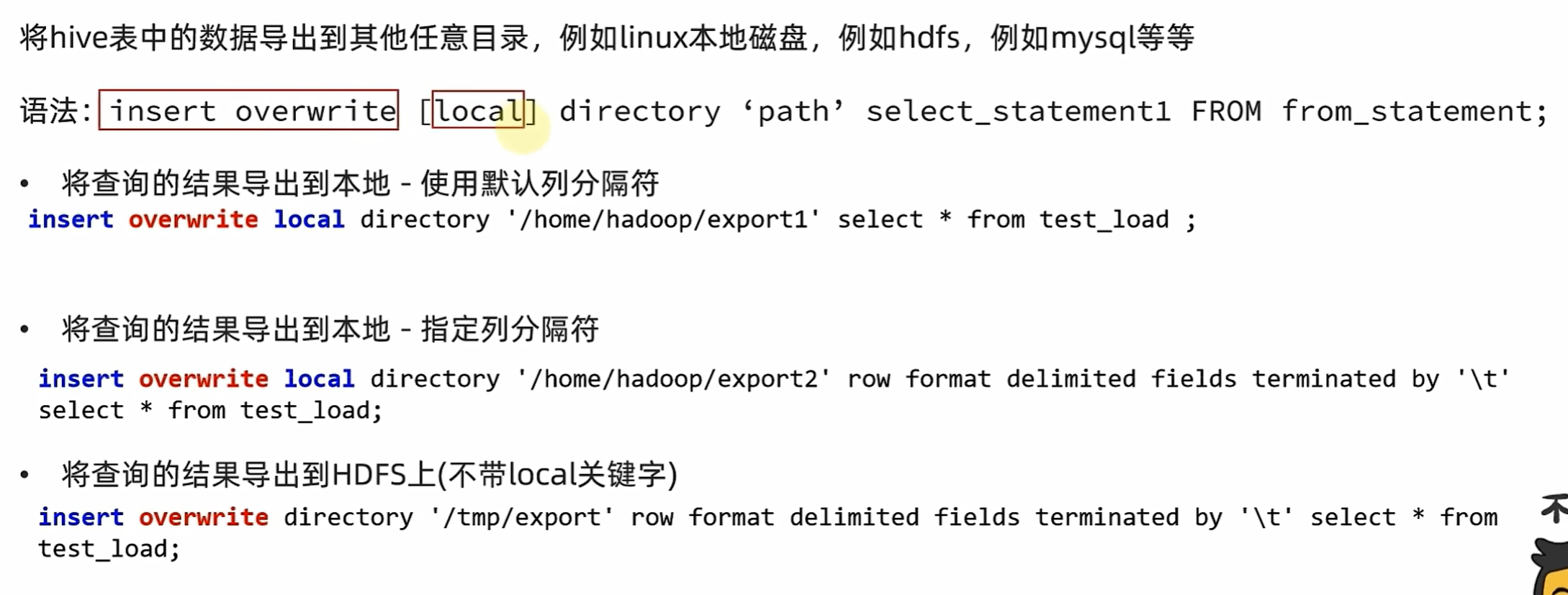
通过bin/hive

> 重定向符 可以将输出结果重定向到文件ls -l > 1.txt
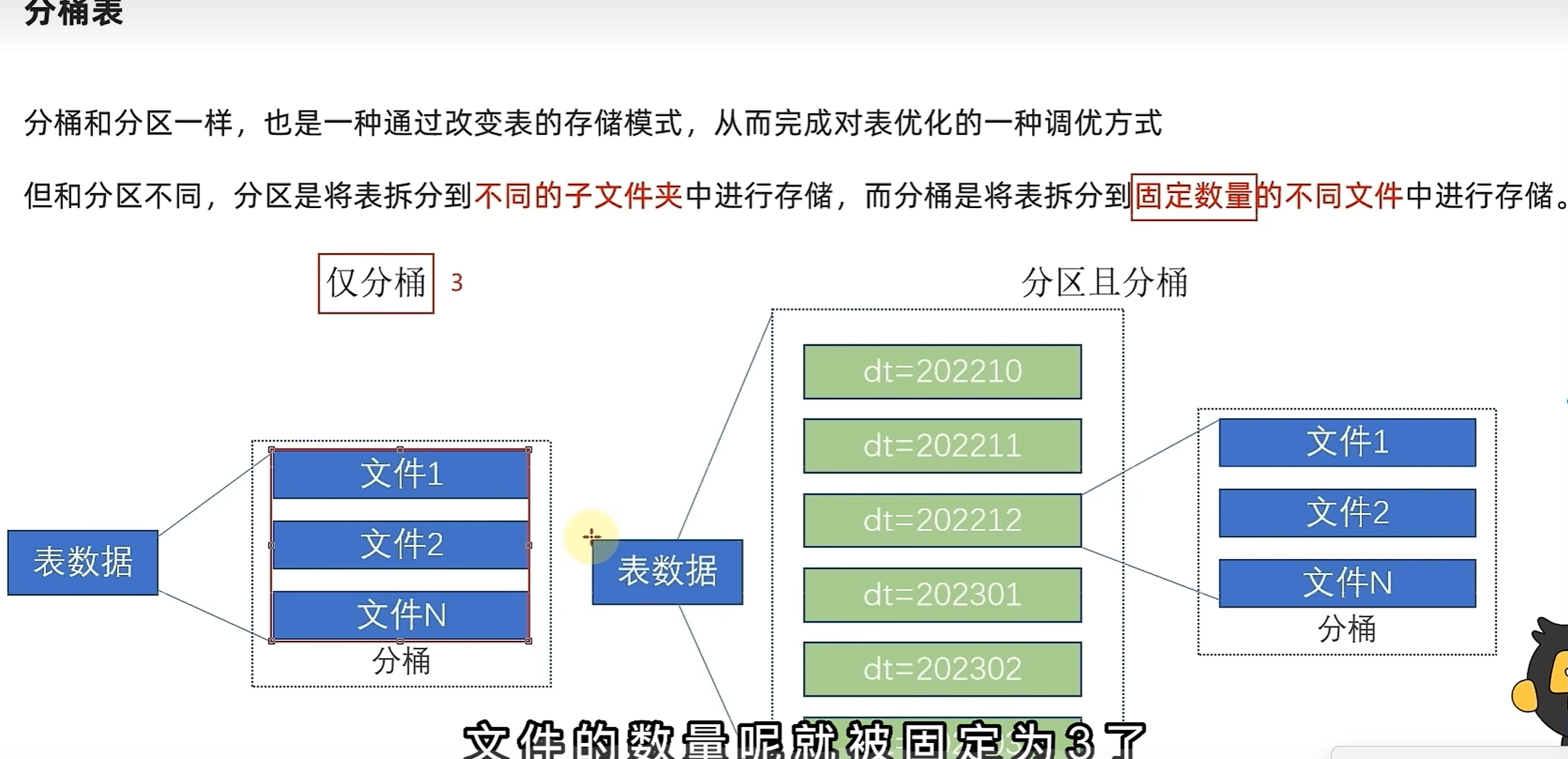
总结
分区

-- 单分区
create table myhive.score(id string, cid string, score int) partitioned by (year string)
row format delimited fields terminated by '\t';load data local inpath '/home/hadoop/score.txt' into table score partition(year='2024');
load data local inpath '/home/hadoop/score.txt' into table score partition(year='2025');-- 多分区
create table myhive.score2(id string, cid string, score int) partitioned by (year string, month string)
row format delimited fields terminated by '\t';load data local inpath '/home/hadoop/score.txt' into table score2 partition(year='2024', month='1');
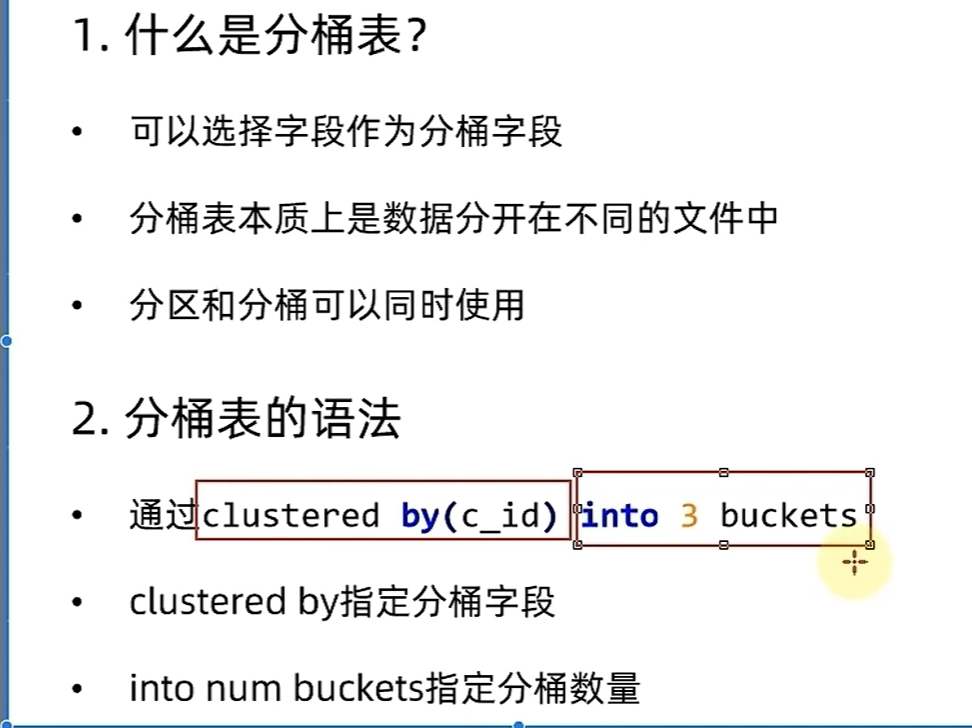
分桶
-- 开启分桶表自动处理功能
-- 说明:设置为 true 后,Hive 会根据表定义的分桶数自动进行分桶操作
-- 无需手动指定 reduce 任务数量或显式使用 CLUSTER BY
set hive.enforce.bucketing=true;-- 创建分桶表
-- 说明:
-- 1. 表结构包含课程 ID (c_id)、课程名称 (c_name)、教师 ID (t_id)
-- 2. clustered by (t_id):指定按教师 ID (t_id) 进行分桶
-- 3. into 3 buckets:将数据分为 3 个桶
-- 4. row format delimited fields terminated by '\t':指定字段间分隔符为制表符
create table myhive.course
(
c_id string,
c_name string,
t_id string
) clustered by (t_id) into 3 buckets row format delimited fields terminated by '\t';-- 删除 course 表
-- 说明:删除已存在的 course 表,若表不存在会报错,可添加 if exists 避免
drop table course;-- 创建临时数据表
-- 说明:
-- 1. 临时表结构与分桶表一致,用于中转数据
-- 2. 分桶表通常不直接使用 load data 加载,而是通过临时表过渡
create table myhive.temp_course
(
c_id string,
c_name string,
t_id string
) row format delimited fields terminated by '\t';-- 加载数据到临时表
-- 说明:
-- 1. local inpath:表示从本地文件系统加载数据(不加 local 则从 HDFS 加载)
-- 2. '/home/hadoop/course.txt':本地数据文件路径
-- 3. 数据格式需与表定义的分隔符一致(此处为制表符)
load data local inpath '/home/hadoop/course.txt' into table temp_course;-- 向分桶表中插入数据
-- 说明:
-- 1. insert overwrite:覆盖分桶表中已有数据
-- 2. 从临时表查询数据并插入分桶表
-- 3. cluster by (c_id):插入时指定分桶逻辑(建议与表定义的 clustered by 字段保持一致)
insert overwrite table myhive.course
select *
from myhive.temp_course cluster by (c_id);
总结

修改表
alter table score2 rename to score;# 修改表的属性
desc formatted score;
alter table score set tblproperties('EXTERNAL'='TRUE');
alter table score set TBLPROPERTIES('comment'='this is table comment');# 添加表分区
alter table score add partition(year='2019', month='10', day='01');
# 修改分区值(修改元数据记录, HDFS的实体文件夹不会改名但是在元数据记录中是改名了的)
alter table score partition(year='2019', month='10', day='01') rename to partition(year='2019', month='10', day='07');
# 删除分区(删除元数据, 数据本身还在)
alter table score drop partition(year='2019', month='10', day='07');# 添加新列
alter table score add columns (v1 int, v2 string);
# 修改列名
alter table score change v2 v2new string;# 删除表
drop table myhive.score;# 清空表数据(无法清空外部表)
truncate table course;
truncate table test_load2;
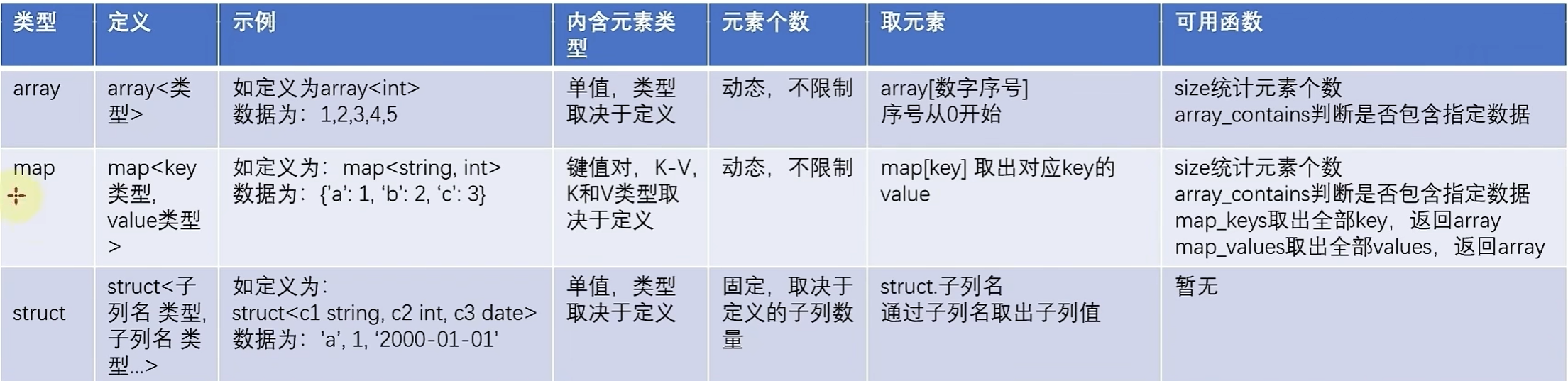
复杂类型
array类型
-- array类型
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
collection items terminated by ',';-- 加载数据
load data local inpath '/home/hadoop/test_array.txt' into table test_array;-- 查询
select * from myhive.test_array;-- 序号从0开始
select name, work_locations[0] from test_array;-- 找谁在tianjin工作过
select * from myhive.test_array where array_contains(work_locations, 'tianjin');

map复杂类型
create table myhive.test_map(id int,name string,members map<string, string>,age int
) row format delimited fields terminated by ','
collection items terminated by "#"
map keys terminated by ':';load data local inpath '/home/hadoop/data_for_map_type.txt' into table myhive.test_map;-- 查看内容
select * from myhive.test_map;-- 查看成员中每个人的父亲是谁
select name, members['father'] , members['mother'] from myhive.test_map;-- 取出map的key , 类型是 array
select map_keys(members) from myhive.test_map;
-- 获取map的value,类型是array
select map_values(members) from myhive.test_map;-- array_contains 去查看指定的数据是否包含在map中, 看看谁有sister这个key
select * from myhive.test_map where ARRAY_CONTAINS(map_keys(members), 'sister') ;
-- array_contains 去查看指定的数据是否包含在map中, 看看谁有王林这个value
select * from myhive.test_map where ARRAY_CONTAINS(map_values(members), '王林') ;

Struct类型
create table myhive.test_struct(id int,info struct<name:string, age:int>
) row format delimited fields terminated by "#"
collection items terminated by ':';load data local inpath '/home/hadoop/data_for_struct_type.txt' into table myhive.test_struct;-- 查询内容
select * from myhive.test_struct;

总结
查询
普通查询
create database itheima;
use itheima;CREATE TABLE itheima.orders (orderId bigint COMMENT '订单id',orderNo string COMMENT '订单编号',shopId bigint COMMENT '门店id',userId bigint COMMENT '用户id',orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货',goodsMoney double COMMENT '商品金额',deliverMoney double COMMENT '运费',totalMoney double COMMENT '订单金额(包括运费)',realTotalMoney double COMMENT '实际订单金额(折扣后金额)',payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他',isPay tinyint COMMENT '是否支付 0:未支付 1:已支付',userName string COMMENT '收件人姓名',userAddress string COMMENT '收件人地址',userPhone string COMMENT '收件人电话',createTime timestamp COMMENT '下单时间',payTime timestamp COMMENT '支付时间',totalPayFee int COMMENT '总支付金额'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/itheima_orders.txt' INTO TABLE itheima.orders;CREATE TABLE itheima.users (userId int,loginName string,loginSecret int,loginPwd string,userSex tinyint,userName string,trueName string,brithday date,userPhoto string,userQQ string,userPhone string,userScore int,userTotalScore int,userFrom tinyint,userMoney double,lockMoney double,createTime timestamp,payPwd string,rechargeMoney double
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/itheima_users.txt' INTO TABLE itheima.users;-- 查询全表数据
SELECT * FROM itheima.orders;-- 查询单列信息
SELECT orderid, userid, totalmoney FROM itheima.orders o ;-- 查询表有多少条数据
SELECT COUNT(*) FROM itheima.orders;-- 过滤广东省的订单
SELECT * FROM itheima.orders WHERE useraddress LIKE '%广东%';-- 找出广东省单笔营业额最大的订单
SELECT * FROM itheima.orders WHERE useraddress LIKE '%广东%'
ORDER BY totalmoney DESC LIMIT 1;-- 统计未支付、已支付各自的人数
SELECT ispay, COUNT(*) FROM itheima.orders o GROUP BY ispay ;-- 在已付款的订单中,统计每个用户最高的一笔消费金额
SELECT userid, MAX(totalmoney) FROM itheima.orders WHERE ispay = 1 GROUP BY userid;
-- 统计每个用户的平均订单消费额
SELECT userid, AVG(totalmoney) FROM itheima.orders GROUP BY userid;
-- 统计每个用户的平均订单消费额,并过滤大于10000的数据
SELECT userid, AVG(totalmoney) AS avg_money FROM itheima.orders GROUP BY userid HAVING avg_money > 10000;-- 订单表和用户表JOIN 找出用户username
SELECT o.orderid, o.userid, u.username FROM itheima.orders o JOIN itheima.users u ON o.userid = u.userid;
SELECT o.orderid, o.userid, u.username FROM itheima.orders o LEFT JOIN itheima.users u ON o.userid = u.userid;rlike
-- 查找广东省数据
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*广东.*';
-- 查找用户地址是: xx省 xx市 xx区
SELECT * FROM itheima.orders WHERE useraddress RLIKE '..省 ..市 ..区';
-- 查找用户姓为: 张、王、邓
SELECT * FROM itheima.orders WHERE username RLIKE '[张王邓]\\S+';
-- 查找手机号符合: 188*****0*** 规则
SELECT * FROM itheima.orders WHERE userphone RLIKE '188\\S{4}0[0-9]{3}';### Union```sql
SELECT * FROM itheima.course WHERE t_id = '王力鸿';
-- 去重演示
SELECT * FROM itheima.course
UNION
SELECT * FROM itheima.course;
-- 不去重
SELECT * FROM itheima.course
UNION ALL
SELECT * FROM itheima.course;
-- UNION写在FROM中 UNION写在子查询中
SELECT t_id, COUNT(*) FROM
(
SELECT * FROM itheima.course WHERE t_id = '周杰轮'
UNION ALL
SELECT * FROM itheima.course WHERE t_id = '王力鸿'
) AS u GROUP BY t_id;
-- 用于INSERT SELECT
INSERT OVERWRITE TABLE itheima.course2
SELECT * FROM itheima.course
UNION
SELECT * FROM itheima.course;数据抽样
-- 随机桶抽取,分配桶是有规则的
-- 可以按照列的hash取模分桶
-- 按照完全随机分桶
-- 其它条件不变的话,每一次运行结果一致
select username, orderId, totalmoney
FROM itheima.orderstablesample (bucket 3 out of 10 on username);-- 完全随机,每一次运行结果不同
select *
from itheima.orderstablesample (bucket 3 out of 10 on rand());-- 数据块抽取,按顺序抽取,每次条件不变,抽取结果不变
-- 抽取100条
select *
from itheima.orderstablesample (100 rows);-- 取1%数据
select *
from itheima.orderstablesample (1 percent);-- 取1KB数据
select *
from itheima.orderstablesample (1K);虚拟列
set hive.exec.rowoffset = true
select username, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK
from itheima.orders

函数
-- 查看所有可用函数
show functions;
-- 查看函数使用方式
describe function extended count;
-- 数值函数
-- round 取整,设置小数精度
select round(3.1415926); -- 取整 (四舍五入)
select round(3.1415926, 4); -- 设置小数精度4位 (四舍五入)
-- 随机数
select rand(); -- 完全随机
select rand(3); -- 设置随机数种子,设置种子后每次运行结果一致的
-- 绝对值
select abs(-3);
-- 求PI
select pi();
-- 集合函数
-- 求元素个数
use myhive;
select size(work_locations) from test_array;
select size(members) from test_map;
select map_keys(members) from test_map;
select map_values(members) from test_map;
select * from test_array where ARRAY_CONTAINS(work_locations, 'tianjin');
select *, sort_array(work_locations) from test_array;-- 类型转换函数
-- 转二进制
select binary('hadoop');
-- 自由转换,类型转换失败报错或返回NULL
select cast('1' as bigint);
-- 日期函数
-- 当前时间戳
select current_timestamp();
-- 当前日期
select current_date();
-- 时间戳转日期
select to_date(current_timestamp());
-- 年月日季度等
select year('2020-01-11');
select month('2020-01-11');
select day('2020-01-11');
select quarter('2020-01-11');
select dayofmonth('2020-05-11');
select hour('2020-05-11 10:36:59');
select minute('2020-05-11 10:36:59');
select second('2020-05-11 10:36:59');
select weekofyear('2020-05-11 10:36:59');
-- 日期之间的天数
select datediff('2022-12-31', '2019-12-31');
-- 日期相加、相减
select date_add('2022-12-31', 5);
select date_sub('2022-12-31', 5);-- 条件函数
-- if判断
use itheima;
select if(truename is NULL, '不知道名字', truename) from users;
-- null判断
select isnull(truename) from users;
select isnotnull(truename) from users;
-- nvl: 如果value为 null,则返回default_value,否则value.
select nvl(truename, '不知道名字') FROM users;
-- 返回第一个不是 NULL 的 v,如果所有 v 都是 NULL,则返回 NULL。
select coalesce(truename, brithday) from users;
-- 当 a = b 时,返回 c; [当 a = d 时,返回 e]* ;否则返回 f。
select username, case username when '周杰伦' then '知名歌星' when '张鲁依' then '知名演员' else '不知道身份' end from users;
select truename, case when truename is null then '不知道名字' else truename end from users;
-- When a = true, returns b; when c = true, returns d; else returns e.
-- a可以是表达式, 如1=1
-- 如果 a=b, 则返回 NULL;否则返回 a。
-- 等价: CASE WHEN a = b then NULL else a
select truename , nullif(truename, '萧呀轩') from users;
--如果boolean_condition结果不为True,则引发异常报错
select assert_true(1=1);-- 字符串函数
-- 连接字符串
select concat(loginname, username) from users;
select concat_ws(',', loginname, username) from users;
-- 统计长度
select username, length(username) from users;
-- 转大小写
select lower('ABCDE'); -- 转小写
select upper('abcde'); -- 转大写
-- 去除首尾空格
select trim(' hadoop ');
-- 字符串分隔
select split('hadoop,bigdata,hdfs', ',');-- 数据脱敏函数
-- hash 加密 (结果是16进制字符串)
select mask_hash('hadoop');-- 其它函数
-- hash加密 (结果是数字)
select hash('hadoop');
select hash('bigdata');
-- 当前用户
select current_user();
-- 当前数据库
select CURRENT_DATABASE();
-- hive版本
select version();
-- 计算md5
select md5('hadoop');