官方blog:https://tongyi-agent.github.io/zh/blog/introducing-tongyi-deep-research/
论文一:继续预训练 Scaling Agents via Continual Pre-training
https://arxiv.org/pdf/2509.13310
核心贡献
- 将多种非结构化数据源转换为以实体为中心的知识库
- 使用模型第一步推理合成planning数据,采用两步法合成reasoning数据,无需使用搜索API
- 使用备选solution对原有的轨迹数据进行增强,利用修改轨迹建立类似process reward的效果
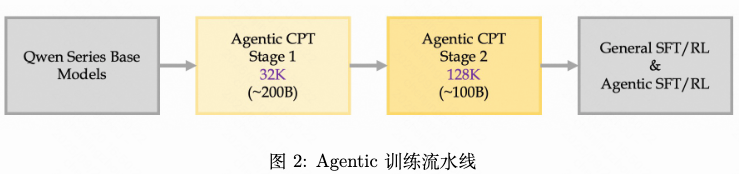
该智能体依赖于一种系统化且可扩展的数据合成方法,包括一阶动作合成(FAS)、高阶动作合成(HAS)以及两阶段训练策略。为了高效地吸收这两种合成的 Agentic 数据,我们提出了一种渐进式的两阶段训练策略。第一阶段主要利用 FAS 数据以及上下文窗口为 32K 的短 HAS 材料,第二阶段则聚焦于高质量的 HAS 数据,并采用扩展至 128K 上下文长度的训练。
2.2 无需监督信号的一阶动作合成(FAS)
2.2.1 Scaling Training Contexts via Knowledge-to-Question Transformation(从知识图谱产生难题)
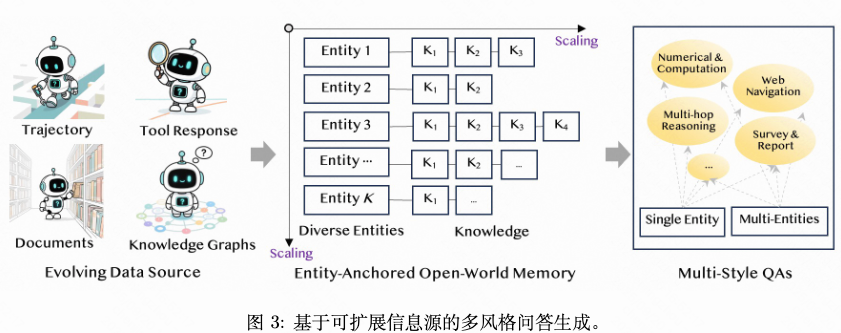
- **阶段 1:实体锚定的开放世界知识记忆。**参考上图的中间子图,由实体及其对应知识构成。例如,包含“2025 年 5 月法国游客人数为 3,793 千人,6 月增至 4,222 千人”的网络数据可被重构为:(“法国”, “2025 年 6 月法国游客人数达到 4,222 千人”)
- 阶段 2:多风格问题生成。基于实体锚定的开放世界记忆,我们采样实体簇及其相关知识声明,以生成涵盖事实检索、数值计算、多跳推理和综合任务的多样化问题。借助利用每个实体下高密度的声明来诱导隐式的跨实体关联**,我们的方法生成了多样、可靠且新颖的问题。与WebSailor (Li et al., 2025b) 需显式构建实体间关系不同,***我们的方法借助实体锚定记忆中重构的知识声明的丰富性,实现自然的知识交叉,显著提升了疑问生成的可靠性与新颖性。***此外,每个实体所具备的全面知识覆盖能力,使得即使在单实体情境下也能生成复杂的挑战。

2.2.2 合成Planning Action
传统的基于搜索和网页爬取API合成轨迹内容的方法价格昂贵且合成效率低下,为应对这一挑战,我们提出了一种可扩展的推理-动作合成方法。我们观察到,大模型对复杂问题的初始分析通常涉及问题分解、信息需求识别和解决方案规划,这本身便构成了高质量的规划素材。更重要的是,第一步推理的质量与最终任务完成率呈现显著正相关。
材料合成方案:合成单步材料,仅生成推理链和程序调用,无需调用API。
通过数据验证方案(也就是拒绝采样):由于问题构建中涉及的知识是可获取的,我们能够基于知识对齐验证实施拒绝采样。具体而言,我们采用 LLM-as-Judge 途径评估当前推理和动作获得所需知识的概率是否较高。
2.2.3 合成Reasoning Action
基于知识簇构建的问题不仅包含问题本身,还能精确映射到解决问题所需的信息。在此基础上,我们提出一种两步逻辑推理数据合成方案:
- 步骤 1:我们要求语言模型将问题 Q 分解为多个子障碍,然后利用其内部知识为每个子问题生成合理的推测和答案,从而得出初步答案 A1。
2. 步骤 2:给定挑战 Q 及其映射的相关知识,我们要求模型对答案 A1 进行优化,纠正逻辑错误,并生成最终答案 A2。
值得注意的是,我们在两个阶段都禁止模型调用任何外部工具独立的,没有因果关系)采用这种就是。(整理者注:禁止调用工具和两步设计之间应该两步设计的动机在于,***倘若直接同时提供挑战和必要知识,模型往往会机械地将给定知识作为中间推理结点加以利用,而不是模拟真实的思考过程。***我们下面展示一个示例。

拒绝采样。此外,我们采用基于大语言模型的评判方法来评估生成答案 A2 与真实值答案之间的对齐程度,并据此实施拒绝采样。如果最终答案被证实正确,我们将认为A2 中包含的推理过程是可靠的。经过这一方法,我们生成了大量高质量的逻辑思维链数据。值得强调的是,这种逻辑演绎能力构成了深度研究智能体在整个问题求解生命周期中所需的基本能力。
2.3 高阶动作合成(HAS)
轨迹复用挑战。在智能体模型的后训练阶段,拒绝采样微调和强化学习均会产生大量轨迹素材。然而,这些方法严重依赖于轨迹级别的延迟反馈进行质量评估,导致许多轨迹在未达到严格的质量阈值时被完全丢弃或仅使用一次。这种粗粒度的评估方式造成了真实轨迹中蕴含的学习信号大量浪费。尽管步骤级评估理论上能更好地利用这些信号,但对中间步骤的精确评估仍然具有挑战性**。若将此类不确定的奖励信号直接纳入 SFT 或 RL 训练,可能引发模型坍塌风险。因此,在保持训练稳定性的同时有效复用次优轨迹当前的关键挑战。就是,仍
洞察。我们认识到,轨迹中的每一步都得到了高质量上下文的承受,包括原始问题、先前步骤及其真实反馈。这些上下文定义了一个具有广泛可行推理-动作选项的空间的特殊推理状态。因此,每一步本质上都是一个隐藏的决策过程。然而,尽管智能体在单次推理-动作回合中通常会生成多个候选(例如,备选查询或探索方向),这些候选仍属于同一条路径的内部分支,而监督关键奖励完整轨迹的重现。因此,模型学习的是模仿序列,而非在关键步骤上进行决策。我们因此将目标从轨迹模仿转变为逐步决策,显式利用每一步的选择空间,实现从轨迹重现到基于决策的推理的转变。
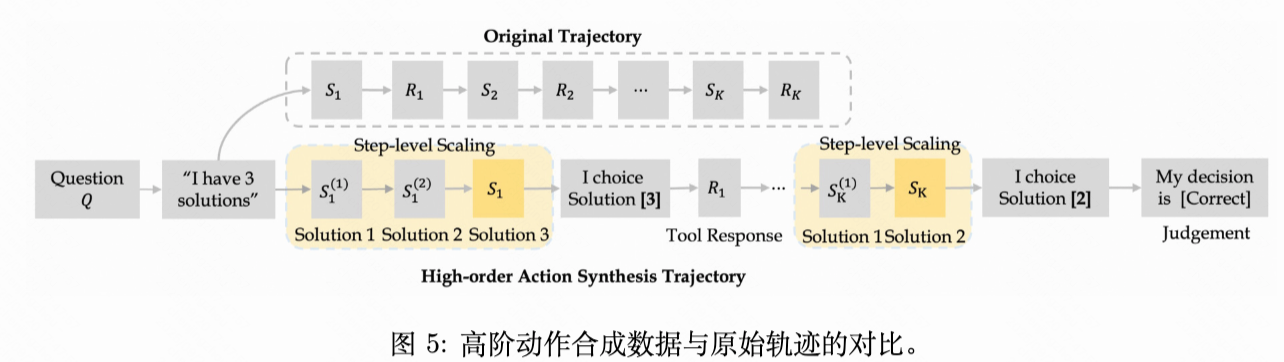
方法:原始轨迹的每步决策中,模型只提出一个solution。该方法做了以下三步(整理者注:整体流程相当于向原始轨迹加入需要多选一的决策步,并利用拼接上下文为模型注入反馈):
- 额外生成N个solution(与原始solution属于平行关系)加入到轨迹中,相当于模型在这条新轨迹上需要从N+1个solution中选择一个。
- 向轨迹中拼接一个决策步骤,内容为“我选择了第k个solution”,此处k对应的solution就是原始轨迹的那个solution。
- 通过拼接上下文实现的。就是向轨迹中拼接反馈步:“我的决策 {正确/错误}”,这里的正误信号来自原始轨迹的最终结果。这一步有点像PRM,但是
该方法规避了直接使用不确定的步骤级奖励所带来的风险,同时使模型能够从多样的推理路径中学习,从而防止对特定轨迹模式的过拟合。依据这种综合策略,此前未被充分利用的轨迹数据被转化为丰富的训练信号,显著提升了智能体学习过程的样本效率。
论文二:材料合成WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
WebSailor-V2:https://arxiv.org/abs/2509.13305
WebSailor-V1:https://arxiv.org/abs/2507.02592
以下内容结合了V1和V2
核心贡献
基于图的复杂问题合成,可扩展性强,覆盖各种复杂的图结构。
1. 数据合成
a. 问题合成
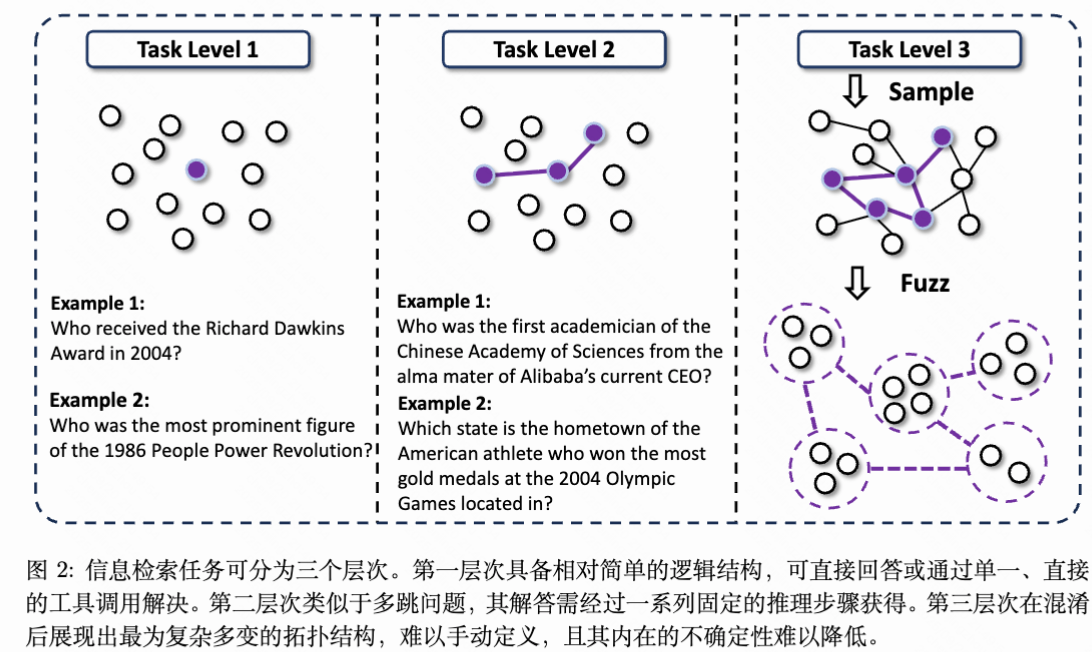
构建难以降低的 Uncertainty 的结构基础:为生成三级任务,我们首先构建一个信息复杂度高、不确定性难以降低的环境。借鉴随机游走的思想,我们的流程旨在创建具有涌现性、非线性结构的知识图谱。开始,从 Wikidata 的 SPARQL 服务中提取一个模糊实体作为起点,确保任务具有挑战性。通过模拟网页浏览,我们从互联网上搜集关于该实体的非结构化文本及特征。基于这些原始信息,提取相关实体及其间关系,形成初始的结点与边。关键步骤在于迭代扩展:我们概率性地选择现有结点,并寻找新的、不同的实体进行连接。这一随机过程避免了简单线性链(二级任务的特征),转而促进生成一个关系路径错综复杂、相互交织的稠密连接图。最终形成的图谱为那些缺乏预设推理路径的问题供应了结构基础,迫使智能体在复杂的信息网络中导航,而非沿直线行进。
通过子图采样与模糊化生成高不确定性提问: 基于这些复杂的图结构,我们生成了以高初始不确定性为特征的挑战。这是借助采样具有多样拓扑结构的子图实现的,每个子图代表了一组独特的耦合实体及其关系。随后,我们根据子图构建挑战与答案。***关键在于,我们通过故意信息模糊化引入了分歧。不是呈现明确的事实,而是对问题中的特征和关系进行模糊处理。例如,将具体日期转换为模糊时间段(“2010 年代初”),部分隐藏名称(“由首字母为‘F’的人创立的机构”),或将定量属性定性描述(“市场份额不足1%”)。***这种模糊化直接增加了初始不确定性,迫使智能体进行推理、比较和综合信息,而非简单地执行查找。我们将这种合成的训练信息命名为 SailorFog-QA。
V2改进:
- 为了实现更全面的拓扑覆盖以克服无环图的局限性,我们对图扩展阶段进行了显著增强。具体而言,我们主动寻找并建立结点之间更稠密的连接,有意构造循环结构。这确保了生成的图不仅是一个庞大的树状结构,而是一个丰富互联的网络,更准确地反映了现实世界知识的复杂、非线性特征。除了这些结构上的改进,大家如今还保留了更完整的流程信息,例如具体的搜索查询和引导新发现的来源URL。此外,我们为每个实体计算并存储多种统计特征,这对后续的问答生成阶段至关重要,使我们能够构建更具细微差别和挑战性的问题。
- 在先前的版本中,我们的子图采样策略依赖于随机采样,并尝试枚举固定边数的所有可能子结构。然而,随着V2版本中图的稠密度显著增加,由于组合爆炸,这种穷举枚举在计算上变得不可行。为克服这一可扩展性问题,我们采用基于随机游走的子图提取方法。最终,该策略使大家能够高效地收集足够数量的非同构且连通的子图,全面代表了各种结构复杂性,而无需付出暴力搜索所带来的高昂代价。
- 在生成问答(QA)时,我们不会将子图直接端到端输入大语言模型(LLM)以生成结果。相反,我们先分析给定拓扑中存在多少个非同构结点,从而确保问答焦点能够均匀分布在所有轨道结点(即占据不同结构角色的结点)上。
- 数据curation模型能力提升的核心驱动力,其重要性甚至超过算法本身。素材质量直接决定了模型通过自我探索在分布外场景下泛化的上限。为应对这一挑战,我们根据训练动态实时优化数据。该优化通过一个完全自动化的资料合成与过滤流水线实现,能够动态调整训练集。通过将数据生成与模型训练形成闭环,该方法不仅保障了训练的稳定性,还带来了显著的性能提升。就是数据
b. 冷启动数据合成
Step 1:使用专家模型(例如QwQ)进行推理,对推理得到的轨迹进行拒绝采样和过滤
Step 2:使用其他模型凝练专家模型的思考过程,以避免上下文过长和思考风格污染
2. 训练算法
具体算法暂时略过。
然而,我们认为算法虽然重要,但并非决定Agentic RL成功与否的唯一因素。我们尝试了多种不同的算法和技巧,发现数据质量以及训练环境的稳定性可能是决定强化学习是否有效的更关键因素。有趣的是,我们曾直接在BrowseComp测试集上训练模型,结果却明显劣于使用合成素材时的表现。我们推测,这种差异源于合成数据献出了更一致的数据分布,使模型能够更奏效地进行适配。相比之下,人工标注数据(如BrowseComp)本身具有更高的噪声水平。由于其规模有限,难以近似出可学习的潜在分布,从而阻碍了模型从中学习并实现泛化。
3. 环境
a. 仿真环境
我们利用离线的Wikipedia数据库及其配套的一系列网络工具构建了一个仿真环境。为了在此环境中填充高质量、结构复杂的任务,我们对SailorFog-QA-V2生成流水线进行了适配,使其能够在该离线语料库上运行,从而创建了一套专用于仿真的训练与测试数据。这使我们能够在高成本效益、快速且完全可控的平台上高频次地开展算法实验,显著加速了我们的开发与迭代进程。
b. 真实环境
我们的智能体工具包功能多样,整合了多个搜索数据源、多种网页解析器以及代码执行沙箱。该复合架构的可靠性至关重要,因为外部API 的固有波动性可能污染轨迹资料。这种数据污染掩盖了性能难题的真实根源,使得难以判断次优策略是由算法缺陷还是环境本身的不稳定性所导致。为缓解这些挑战,我们设计了一个统一的工具执行接口。其核心是一个调度与管理层,负责协调工具的执行。针对每个程序,我们开发了稳健的并发处理和容错策略,例如QPS 限制、结果缓存、自动超时重试机制、非关键故障的服务降级,以及无缝切换至备用数据源。这种多层设计确保从智能体的角度来看,工具调用过程被抽象为一个确定性和稳定的接口,从而将训练环路与现实世界的随机性隔离开来,并显著降低运营成本。
论文三:环境、工具集合成 Towards General Agentic Intelligence via Environment Scaling
https://arxiv.org/pdf/2509.13311
2. 环境构建与Scaling
2.1 环境构建

- 搜集了30000个api
- 采用图建模工具间的依赖关系,然后聚簇为工具簇
2.2 任务构建
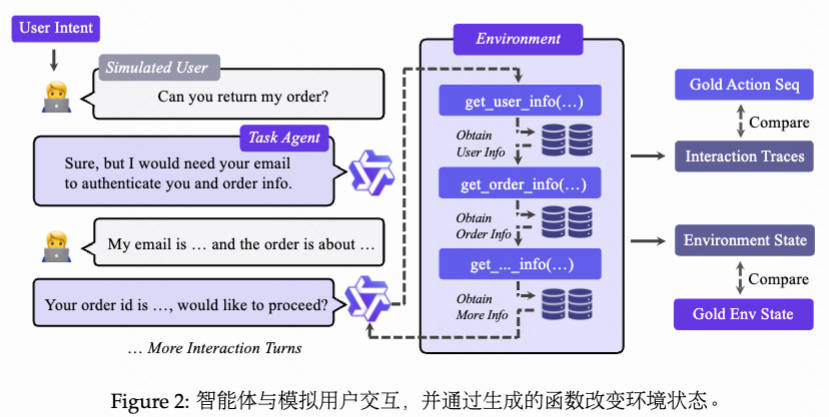
具体而言,我们首先基于领域特定的数据库模式初始化环境状态,并尽可能在初始状态中引入多样性。接着,我们从领域的工具图中采样逻辑连贯的程序序列,具体方法是构建API上的有向依赖图,并通过遍历该图获得有效的序列。从随机选择的初始结点出发,进行有向行走,直到达到最大执行步数或遇到无出边的结点为止。此过程生成一个逻辑连贯的工具序列。对于每一步,我们生成相应的参数并执行实际的工具调用,直接基于数据库进行操作,并持续跟踪不断演化的数据库状态。该流程在两个互补的粒度上实现了可验证性:(i) 数据库级别的状态一致性,以及(ii) 工具序列的精确匹配。
3. Agent Experience Learning
论文四:上下文管理ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
https://arxiv.org/pdf/2509.13313
核心贡献
- 在搜索过程中定期(例如超过 token 预算、达到轮次限制、agent主动调用)对上下文进行总结
- 运用蒸馏方法训练了专用于Search任务的summary模型,该模型专门用于提取关键证据并识别关键信息缺口
- 相应的强化学习算法
全文概述
在上下文限制被突破之前,将不断增长的交互历史转化为紧凑的推理状态。ReSum 并非逐条追加每次交互,而是就是为应对这一挑战,我们提出 ReSum,一种新型范式,通过上下文摘要实现无限探索。核心思想周期性地将对话压缩为结构化的摘要,并从这些状态重新开始探索,使智能体能够在不受上下文约束的情况下持续保持对先前发现的认知。借助这种方式,ReSum 在对 ReAct 进行最小修改的前提下实现了长时程推理,避免了架构复杂性,同时确保了简洁性、高效性以及与现有智能体的无缝兼容性。
ReSum 使用现成的 LLM 作为摘要工具,但通用 LLM(尤其是较小的模型)在网页搜索场景下的对话摘要任务中往往表现不佳。因此,我们经过微调 Qwen3-30B-A3B-Thinking (Team, 2025b),利用从强大开源模型 (Guo et al., 2025; OpenAI, 2025a) 收集的 ⟨Conversation, Summary⟩ 对,对摘要能力进行特化,从而得到 ReSumTool-30B。与传统摘要工具不同,ReSumTool-30B 专门训练用于从长篇交互中提取关键线索和证据、识别信息缺口,并突出下一步行动方向。这种特化使其在网页搜索任务中具有独特优势,兼具轻量级部署与任务特定增强。大量评估表明,ReSumTool-30B 在摘要质量上优于更大的模型,如 Qwen3-235B (Team, 2025b) 和 DeepSeek-R1-671B (Guo et al., 2025)。
最后,为了使智能体掌握 ReSum 模式,我们采用强化学习(RL)方法,借助定制的 ReSum-GRPO 算法实现。与需要昂贵专家级 ReSum 轨迹数据且存在覆盖智能体现有能力风险的监督微调不同,RL 使智能体能够通过自我演化适应该模式,同时不损害其固有的推理能力 (Qin et al., 2025)。具体而言,ReSum-GRPO 遵循标准 GRPO 流程 (Shao et al., 2024),但针对长轨迹进行了改进:当接近上下文限制时,智能体调用 ReSumTool-30B 对对话进行压缩,并从摘要状态继续,自然地将完整轨迹分割为多个部分。每个部分成为一个独立的训练回合,我们将轨迹级别的优势广播到同一轨迹内的所有段落。该机制促使智能体既能从压缩状态中有用推理,又能收集生成高质量摘要所需的信息。
摘要模型
在 ReSum 中,现成的大型语言模型可作为摘要工具。然而,其作用远超传统的对话摘要作用。为了引导网络智能体进行持续且目标导向的探索,***摘要器具必须对冗长且嘈杂的交互历史执行逻辑推理,从大段文本中提炼出可验证的证据,并提出基于网络上下文、切实可行且范围明确的下一步行动建议。这些能力通常超出缺乏网络上下文推理能力的通用模型的能力范围,***因此促使大家开发专用于 ReSum 的摘要工具。
我们采用一个强大的开源模型(整理者注:比如GPT)作为素材引擎,因其易于获取且具备生成高质量摘要的容量。在训练数据方面,我们选择 ***SailorFog‑QA ***(Li et al., 2025a),这是一个具有挑战性的基准,智能体需在长时间探索过程中调用摘要工具,而非更简单的数据集(问题可在几次工具调用内应对)。我们从 ReSum 滚动中收集 ⟨Conversation, Summary⟩ 对,并将此能力提炼至 Qwen3‑30B-A3B-Thinking。 通过监督微调,获得了具备专业摘要功能的 ReSumTool-30B。
论文五:上下文管理 WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
https://arxiv.org/pdf/2509.13309
核心贡献
- 上下文管理:每步结束后总结当前的内容,作为下一步的初始状态,这样上下文长度始终保持恒定,不会随着步数增加而变长。(整理者注:有点像research step wise的RNN)
- 数据合成:反复迭代以增加问题复杂度。
1. IterResearch范式
IterResearch 会周期性地将其研究成果整合为一份综合报告,并重建其工作空间,从而在任意研究深度下保持知识的连续性和推理的清晰性。具体而言,IterResearch 经过离散轮次运行,每个状态仅涵盖必要组件:研究困难、不断演化的报告(综合所有先前发现和当前研究进展)以及最近工具交互的即时上下文。这一不断演化的报告充当智能体的核心记忆——每一轮都通过整合新见解与现有知识逐步优化。在轮次之间,状态转移函数保留此更新后的报告,同时丢弃临时信息,确保满足马尔可夫性质的同时避免信息丢失。
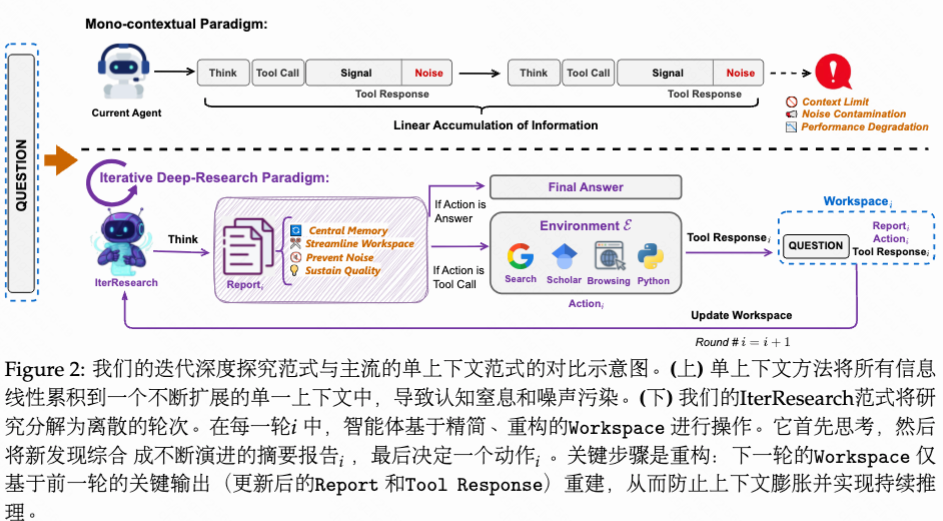
传统单一上下文窗口的障碍:
- 上下文太长导致模型缺乏思考空间
- 前期的噪声信息不断累积
2. 数据合成
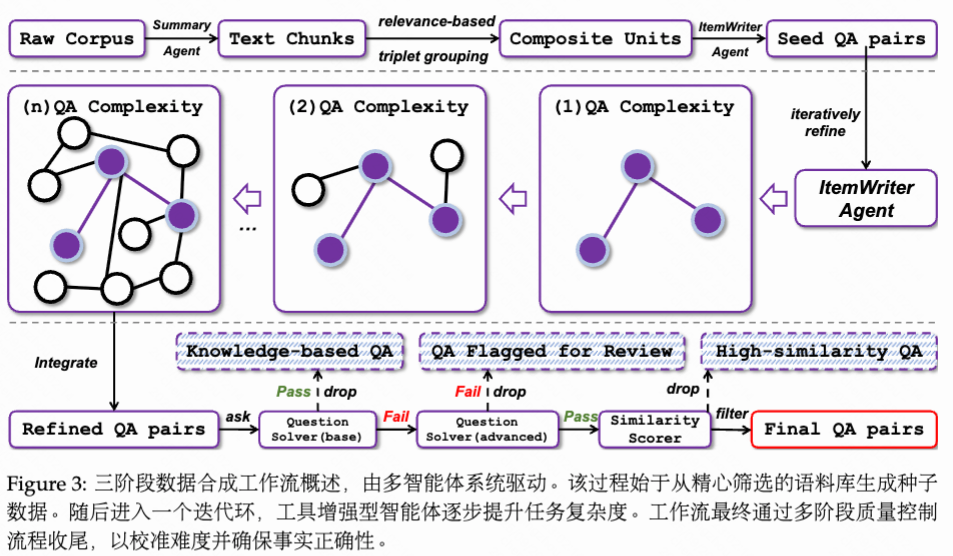
a. 初始挑战合成
b. 问题迭代
数据引擎的核心是一个由ItemWriter智能体协调的自举法精炼环。在此阶段,该智能体被赋予一系列外部工具:(i) 通用网络搜索,(ii) 学术文献搜索,(iii) 网页浏览器,以及(iv) Python代码解释器。对于每个种子QA对,该工具增强型智能体迭代演化疑问与答案,以提升其认知复杂度,并将其范围扩展至原始语境之外。这一迭代演化由四项关键操作驱动。
- 起初,智能体执行知识扩展,查询外部资源以拓宽问题的范围。
- 随后,它进行概念抽象,分析材料以提炼高层次原理,并识别细微的跨领域关系。
- 为确保正确性,通过多源交叉验证实现事实锚定,从而提升答案的准确率与深度。
- 终于,智能体利用Python环境进行计算建模,构造必须定量计算或逻辑仿真的困难。
这种迭代过程形成一个良性循环,即在一次迭代中生成的更繁琐的问答对成为下一次迭代的种子。这使得任务复杂度能够得到受控且系统化的提升。
c. 内容过滤
去掉太简单的障碍(模型在无搜索工具情况下也能克服)和太难或答案有误的问题(模型在有设备的情况下仍然不能解决)。
论文六:规划-检索交替优化/上下文管理 WebWeaver: Structuring Web-Scale Evidence withDynamic Outlines for Open-Ended Deep Research
https://arxiv.org/pdf/2509.13312
任务:开放式研究
核心贡献
- 交替进行信息检索和提纲优化
- 基于记忆模块的上下文管理
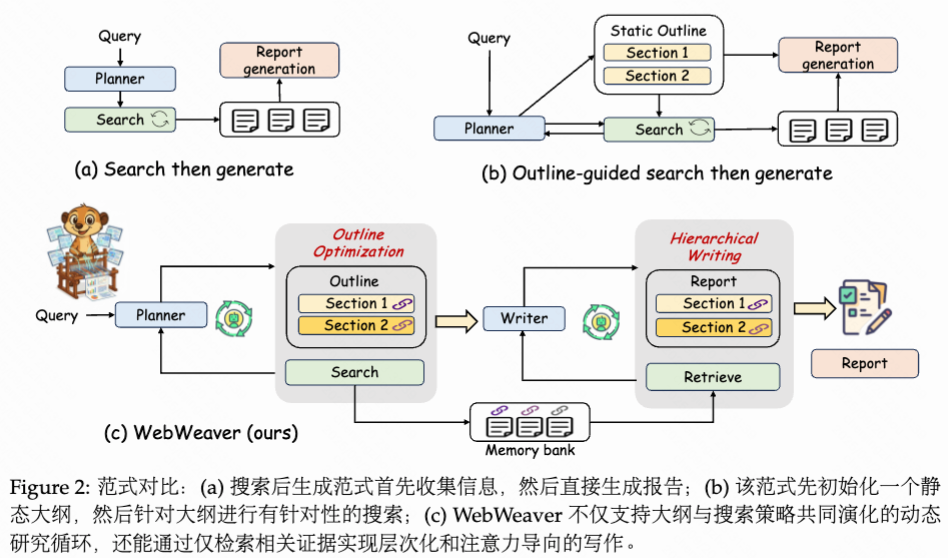
如图2 所示,第一种是直接的“搜索-生成”方法(Tao et al., 2025; Roucher et al., 2025),即智能体在生成报告前收集所有信息。该方法常导致低质量、不连贯的输出,因为它缺乏指导性大纲来组织信息整合过程先生成一个静态大纲,再针对每个部分进行定向搜索(Han et al., 2025; Research,2025e;c)。然而,此种策略存在根本性缺陷:就是。第二种更为复杂的策略则大纲在初期就固定下来,完全依赖大语言模型内部且往往过时的知识。这种僵化性“固化”了研究过程,使智能体无法探索在搜索过程中发现的意外但有价值的路径。此外,将所有检索到的材料一次性输入到单一上下文中进行最终生成,容易引发众所周知的“中间丢失”困难(Liu et al., 2023) 和幻觉增加,严重影响报告的准确性和深度(Bai et al., 2024; Wu et al., 2025c)。
本文用涵盖一个规划者和一个写作者的双智能体框架,以及一个用于存储材料的记忆模块。如图2 所示,规划者体现了探索性研究阶段,以动态循环的方式迭代地交替进行证据获取与提纲最优化,最终生成一份全面且基于来源的调研提纲,其中每个部分均通过引用明确关联到经过筛选的记忆库中的源证据。进入写作阶段后,为应对关键的长上下文和注意力管理挑战,写作者执行基于记忆的分层综合过程。它逐部分构建报告,针对每个子任务仅从结构化的记忆库中检索相关证据。这种协同分工使大家的智能体能够驾驭困难的信息环境,并生成在范围上全面且在证据协助上严谨的报告。
整理者注:在撰写报告时,根据当前撰写进度从记忆模块中检索相关信息加入上下文,撰写完成当前部分后将检索得到的信息从上下文中去除,以此进行上下文管理。
参考汉松 的想法
作者:汉松 链接: 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一般让 AI 写长文都是把资料一股脑放到上下文里面,这会导致模型注意力错乱,因为参考的资料太多,上下文太长,模型不可避免会忽略一些核心信息或者被无关信息误导。
WebWeaver 的解法是分而治之,在写作大纲里面放入引用的资料 id,然后让模型一个个章节写,写每个章节的时候都只提供当前该章节的资料,这样就避免了上下文太长的疑问,保护了模型的注意力。
上面的写作过程也是 Agentic 的,不得硬编码让模型按顺序写,而是直接把整个大纲提供给它,让它自己调用查询资料的软件一步步写出来。这里还有个压缩上下文的技巧是在写最新的章节的时候,把之前的章节的资料都隐藏,只保留写作结果,这样模型既有全局的信息,又能节省上下文。
大纲示例
1. Hoehn and Yahr Scale Classifications <citation>id_2, id_6, id_9, id_12, id_13, id_14, id_15, id_17, id_20, id_21</citation>
资料查询工具示例
{"name": "retrieve", "arguments": {"url_id": ["id_2", "id_6", "id_9", "id_12", "id_13", "id_14", "id_15","id_17", "id_20", "id_21"], "goal": "Gather comprehensive information about Hoehn and Yahr scaleclassifications and disease staging systems for Parkinson’s disease"}}
这种利用查询工具传递 id 的方式来压缩上下文,我在 DeepResearch 的阅读工具里面也用过,关键是用来减少模型生成 url 比较慢的困难,但用在写报告的阶段我确实没想到,对我很有启发。
但这种 Agentic 的方式相比用 Workflow 的方式效果好多少,我是存疑的,基于你让模型自己调用FunctionCall 可能会有幻觉,用代码的方式手动解析大纲继而用 Workflow 的方式可能更可靠。后续我也会做实验对比看看。
参考:
https://zhuanlan.zhihu.com/p/1952775844146712621