一、 为什么要优化订单查询?
1)订单查询是一个高频接口,并且订单数据非常大。
2)面向C端用户的订单查询接口其访问量非常大。
3)对于运营端的订单查询接口虽然访问量不大但由于订单数据较多也需要进行优化,提高查询性能。
二、 确定优化方向
面向查询类的接口的优化方向是什么呢?
1)使用缓存。
将查询的订单数据进行缓存,提高查询性能。
2)优化数据库索引提高查询性能。
当缓存中没有时或缓存过期时会从数据库查询数据,通过添加数据库索引去提高数据库的查询性能。
三、 订单详情优化方案。
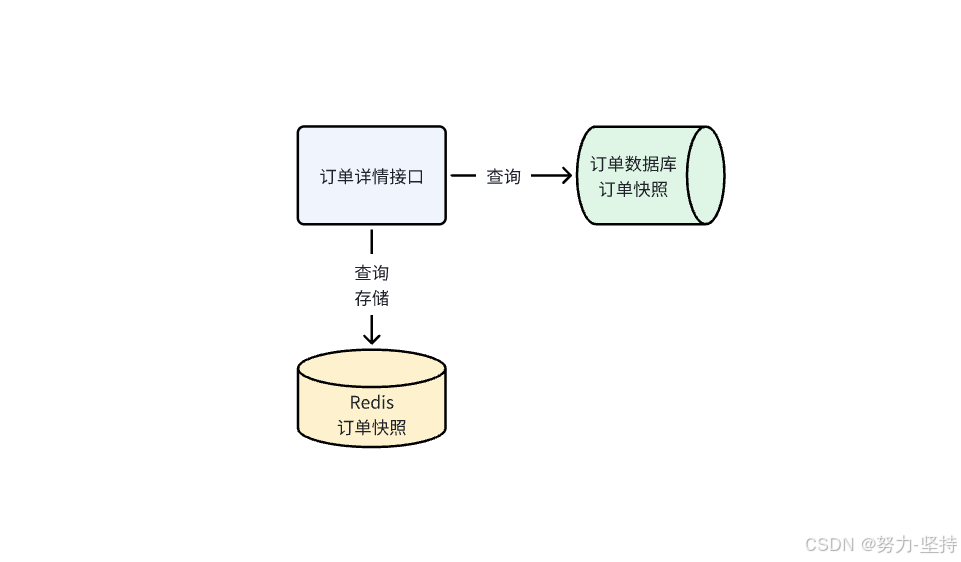
针对单条订单信息查询接口可以使用缓存进行优化。
对于单条订单信息查询接口通过快照查询接口查询订单的详情信息。
参考AbstractStateMachine类的String getCurrentSnapshotCache(String bizId)快照查询方法,将快照信息缓存到 redis提供查询效率。
根据订单Id查询缓存信息,先从缓存查询如果缓存没有则查询快照表的数据然后保存到缓存中。缓存设置了过期时间是30分钟。
当订单状态变更,此时订单最新状态的快照有变更,会删除快照缓存,当再次查询快照时从数据库查询最新的快照信息进行缓存。
四、 用户端订单列表优化方案
用户端通过小程序查询订单列表,界面上没有分页查询的按钮,用户端查询订单列表可采用滚动查询的方法。
滚动查询就是一次查询指定数量的记录,不用进行count查询,省去count查询的消耗。
具体方案如下:
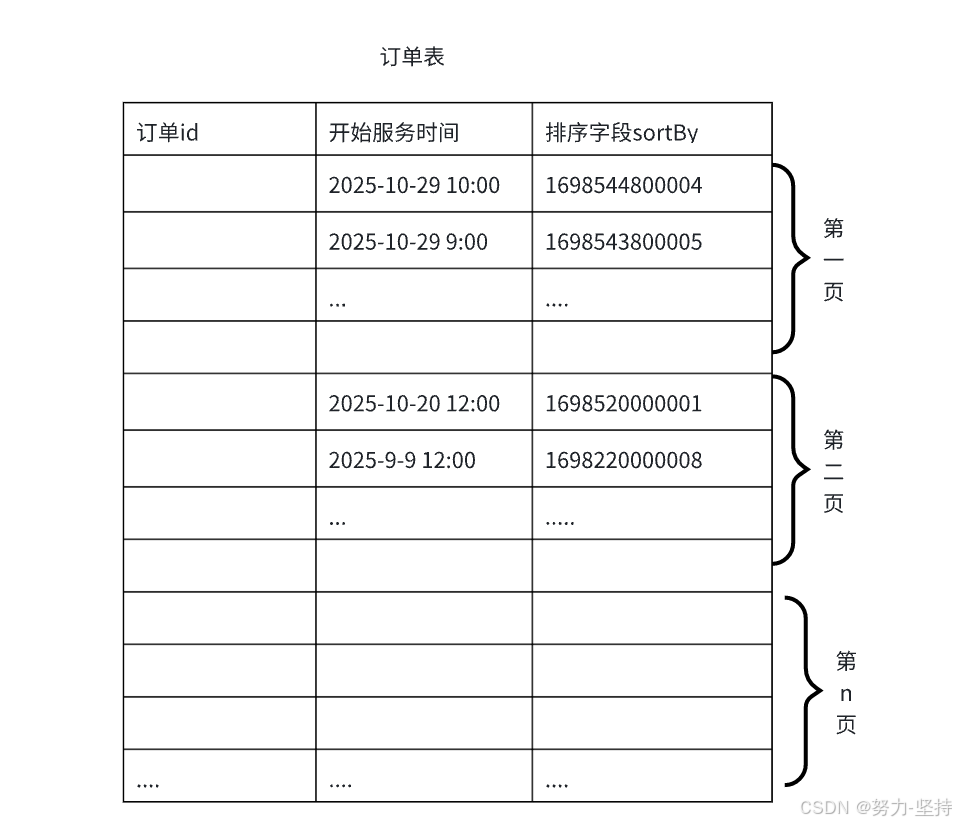
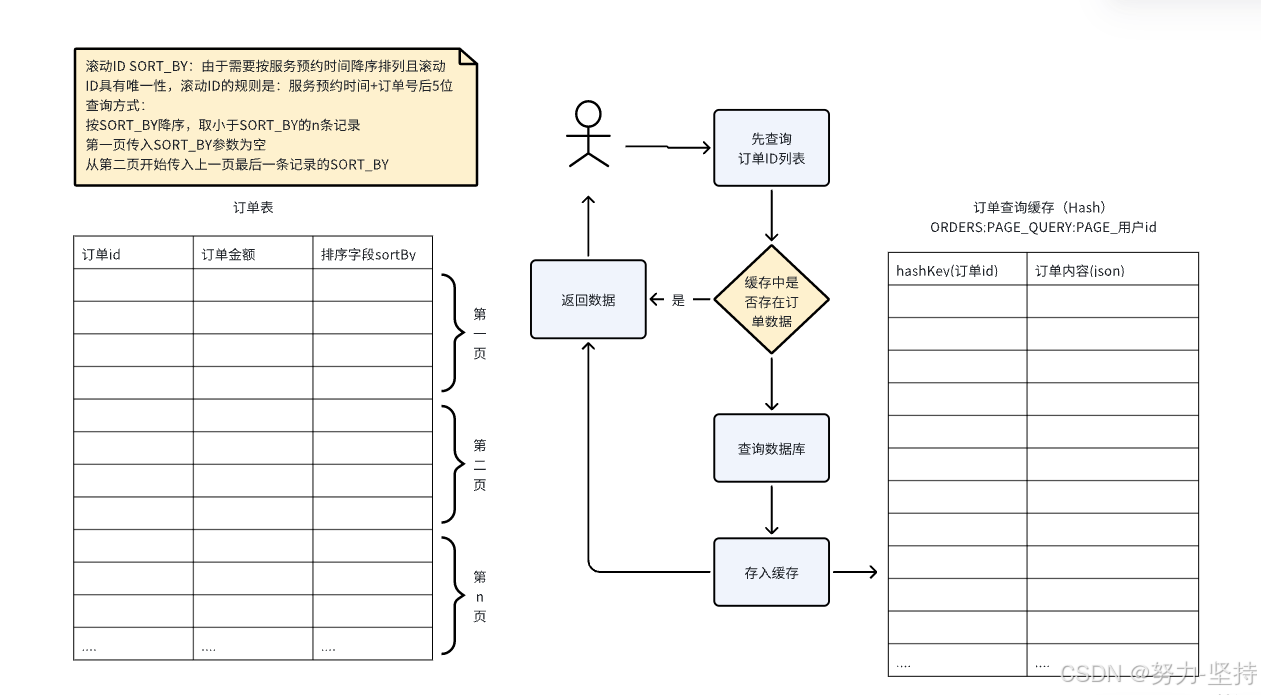
1. 首先查询符合条件的订单ID。
由于是滚动查询需要传入滚动ID,这里我们在订单表使用排序字段sort_by作为滚动ID。
滚动ID是一种递增的序列号,按服务预约时间降序排列且滚动ID具有唯一性,滚动ID的规则是:服务预约时间+订单号后5位。
滚动查询方式: 按SORT_BY降序,取小于SORT_BY的n条记录 第一页传入SORT_BY参数为空 从第二页开始传入上一页最后一条记录的SORT_BY
示例:
2. 使用覆盖索引优化
根据查询条件查询符合条件的订单ID,这里使用覆盖索引优化的方法。
我们知道在InnoDB存储引擎中有两种索引存储形式:

聚集索引:查询条件只有主键的情况会通过聚集索引查询。
非聚集索引:查询条件有多个,此时为了提高查询效率可以创建多个字段的联合索引,根据非聚集索引找到符合条件主键,如果要查询的列只有索引字段则通过非聚集索引直接拿到字段值返回,如果要查询列有一部分在索引之外此时会进行回表查询聚集索引最终拿到数据。
示例:
user表(id、name、 age、address)对name、age创建联合索引。
sql1:
select id、name、age from user where name=? and age =?
该查询直接从索引中拿到符合条件的数据,不存在回表查询。
sql2:
select * from user where name=? and age =?
该查询列是select * ,address没有包含在索引中,where条件通过联合索引找到符合条件的主键,再通过主键回表查询聚集索引,最终拿到数据。
覆盖索引是什么呢?
覆盖索引是一种优化手段,上边的sql1就是实现了覆盖索引。
覆盖索引(covering index)指一个查询语句的执行只需要从非聚集索引中就可以得到查询记录,而不需要回表去查询聚集索引,可以称之为实现了索引覆盖。
根据上边的需求,我们根据查询条件建立联合索引,通过联合索引找到符合条件的订单ID(主键),从索引中找到的符合条件的订单ID无需回表查询聚集索引。
3. 使用订单ID匹配缓存,如果有缓存则直接获取否则从数据库查询。
五、运营端订单列表优化方案
运营端订单列表由于访问量不大这里无需使用缓存,实现方案是首先通过覆盖索引查询符合条件的订单ID,再根据订单ID查询聚集索引拿到数据。
我们根据查询条件创建的联合字段索引是非聚集索引,先从非聚集索引中查询到符合条件的ID,再根据订单ID从聚集索引中查找数据。