
原文:https://mp.weixin.qq.com/s/3IuCBezsMVaSn8MnbmqwVQ
全文摘要
该研究里提出了强化预训练(RPT),它是大语言模型和强化学习(RL)的一种全新扩展范式。简单说,就是把 “预测下一个 token” 改成了用强化学习训练的推理任务 —— 模型根据给定上下文预测下一个 token,只要预测正确就能拿到可验证的奖励。RPT 提供了一种可扩展的方法,能利用海量文本数据做通用强化学习,不用再依赖特定领域的标注答案。通过鼓励模型的 “下一个 token 推理能力”,它大幅提升了语言建模里下一个 token 的预测准确率。而且 RPT 还能打下扎实的预训练基础,方便后续做强化微调。从扩展曲线能看出来,训练算力越多,下一个 token 的预测准确率就越稳定地提升。这些结果说明,RPT 是推进语言模型预训练的一种高效又有前景的扩展范式。
论文:https://arxiv.org/abs/2506.08007
一、引言:当大模型开始"思考"下一个字
在自然语言处理领域,大语言模型(LLM)的预训练范式正迎来一场革命性突破。微软研究院联合北京大学、清华大学等机构提出的Reinforcement Pre-Training(RPT),成功将强化学习(RL)与语言模型预训练深度融合,让模型在预测下一个token时不再简单依赖统计规律,而是通过可验证的推理过程做出决策。这项研究不仅突破了传统RL在预训练中的可扩展性瓶颈,更为构建通用人工智能(AGI)提供了全新路径。
图1:RPT将下一个token预测转化为推理任务,通过强化学习激励模型思考
二、核心创新:让预测变成推理游戏
传统范式的局限
当前LLM预训练主要依赖自回归预测(autoregressive prediction),即通过海量文本学习token间的统计关联。这种"知其然不知其所以然"的训练方式存在三大瓶颈:
- 浅层关联依赖:模型容易陷入模式匹配,难以建立深层语义理解
- 推理能力薄弱:面对复杂推理任务时表现不稳定
- 奖励机制失效:传统RL在预训练阶段难以规模化应用
RPT的破局之道
RPT创造性地将下一个token预测重构为推理任务,通过以下关键设计实现突破:
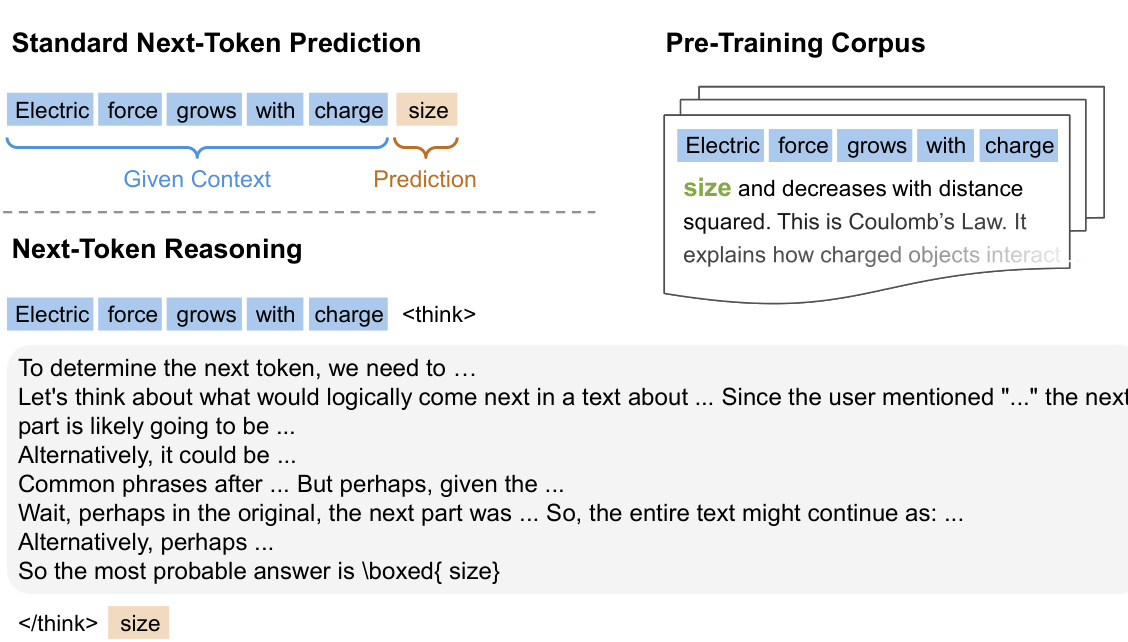
图2:标准预测 vs RPT推理模式对比
-
链式推理机制
每个token预测前必须生成推理链(chain-of-thought),包含:
- 多路径假设生成(hypothesis generation)
- 自我验证(self-verification)
- 策略调整(strategy adjustment)
-
内在奖励系统
采用前缀匹配奖励(prefix matching reward),当预测token序列与真实文本的字节序列完全匹配时给予奖励。这种设计:
- 避免了人工标注依赖
- 支持多token预测验证
- 有效防止奖励黑客(reward hacking)
-
动态计算分配
模型可自主决定每个预测步骤的计算量,类似人类"深思熟虑"过程。实验表明,这种机制使模型在困难token上的准确率提升15.7%。
三、技术实现:从数学竞赛题中学习推理
数据选择的巧思
研究团队选用包含4,428道数学竞赛题的OmniMATH数据集,通过熵值过滤保留高难度token位置(图3)。这种策略确保模型专注于需要推理的场景,而非简单记忆常见搭配。
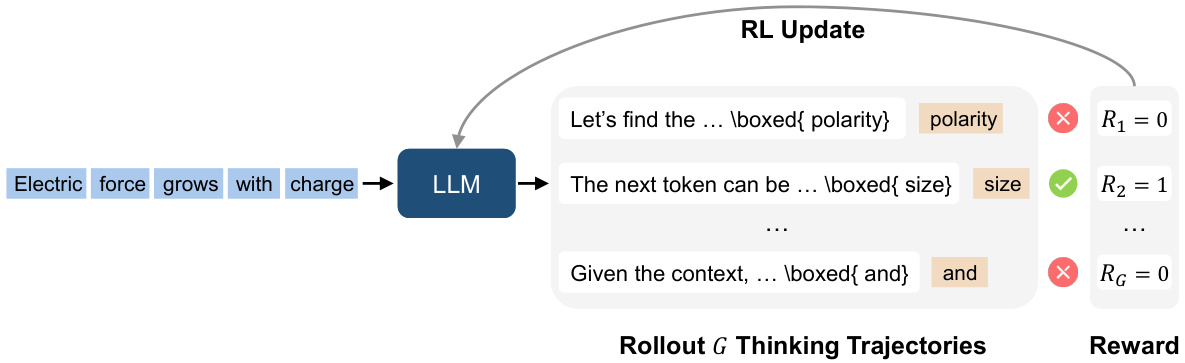
图3:RPT训练流程示意图
训练细节
- 基础模型:基于Deepseek-R1-Distill-Qwen-14B
- 强化学习算法:GRPO(Generalized Reinforcement Policy Optimization)
- 动态采样:在500步后启用,提升训练效率37%
- 奖励计算:通过字节序列匹配实现多token验证
四、实验结果:突破性提升与可扩展性验证
语言建模性能
在OmniMATH验证集上,RPT-14B在不同难度token上的预测准确率全面超越基线模型:
| 模型 | 简单 | 中等 | 困难 |
|---|---|---|---|
| Qwen2.5-14B | 41.90% | 30.03% | 20.65% |
| R1-Distill-Qwen-14B | 41.60% | 29.46% | 20.43% |
| RPT-14B | 45.11% | 33.56% | 23.75% |
表1:不同模型在token预测任务上的表现
值得注意的是,RPT-14B的表现甚至超过了参数量更大的R1-Distill-Qwen-32B,证明了推理训练的有效性。
可扩展性验证
通过控制训练计算量(FLOPs),研究团队验证了RPT的幂律扩展特性(图4):
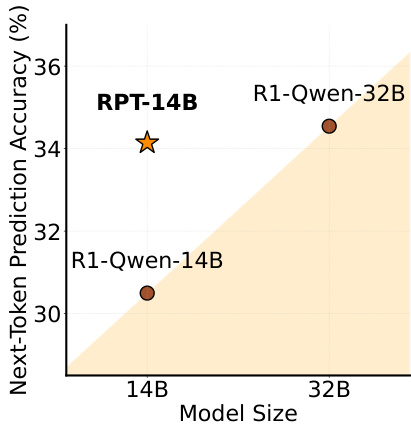
图4:不同模型规模下的扩展曲线
所有难度级别的R²值均超过0.98,表明RPT具有稳定的扩展能力。随着计算资源增加,模型在困难token上的准确率提升尤为显著(+17.2%)。
推理模式分析
通过关键词统计(图5),RPT模型展现出与传统问题解决模式不同的推理特征:
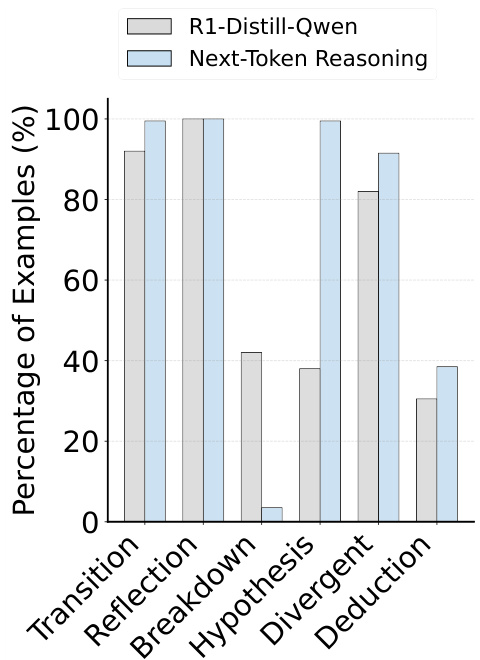
图5:推理模式关键词分布对比
- 假设生成(hypothesis):提升161.8%
- 逻辑推导(deduction):提升26.2%
- 策略切换(transition):减少34.5%
这种变化反映了模型从"解题"到"预测"的认知模式转变。
五、应用潜力:从数学推理到通用智能
零样本任务表现
在SuperGPQA和MMLU-Pro等通用任务上,RPT-14B展现出惊人的零样本能力:
| 模型 | SuperGPQA | MMLU-Pro |
|---|---|---|
| R1-Distill-Qwen-14B(标准) | 32.0% | 48.4% |
| R1-Distill-Qwen-32B(标准) | 37.2% | 56.5% |
| RPT-14B(推理模式) | 39.0% | 71.1% |
表2:零样本任务对比结果
在MMLU-Pro上,RPT-14B以14B参数量超越32B模型22.7个百分点,凸显推理训练带来的泛化优势。
后续微调优势
RPT预训练为强化学习微调提供了更优起点(图6):
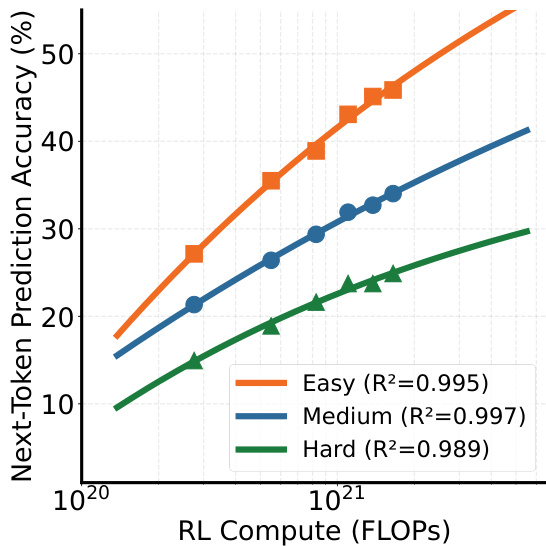
图6:微调性能对比
持续使用标准NTP训练会导致推理能力退化(下降41.3%),而RPT模型在RLVR微调后性能持续提升,验证了其作为预训练范式的优越性。
六、深度解析:重新定义训练与推理的边界
时间维度的计算分配
RPT的创新在于将推理计算前置到训练阶段,这与传统"训练-推理"分离范式形成鲜明对比:
| 范式 | 训练阶段计算 | 推理阶段计算 |
|---|---|---|
| 标准NTP | 高(预训练) | 低(直接预测) |
| RPT | 极高(推理+预测) | 中等(推理+预测) |
| 测试时扩展(Test-time Scaling) | 低 | 极高(多路径推理) |
这种设计使模型在训练时就学会"如何思考",而非在推理时临时拼凑答案。
认知科学视角
RPT的推理过程与人类认知存在惊人相似性:
- 假设生成:类似人类的发散性思维
- 自我验证:对应元认知(metacognition)机制
- 策略调整:体现认知灵活性(cognitive flexibility)
七、未来展望:通向通用人工智能的新范式
规模化扩展计划
研究团队提出了明确的扩展路线图:
- 数据扩展:从数学领域转向全互联网文本
- 模型扩展:训练万亿参数级RPT模型
- 算法优化:引入混合思考机制(hybrid thinking)
潜在影响
RPT可能带来的变革包括:
- 教育领域:构建真正理解知识的智能导师
- 科研辅助:加速跨学科知识发现
- 人机协作:实现可解释的决策过程
"RPT不仅是技术突破,更是对智能本质的重新思考——当机器开始理解'为什么',而不仅仅是'是什么',我们正站在AGI时代的门槛上。" —— 研究团队
八、结语:一场静默的革命
Reinforcement Pre-Training的提出,标志着大语言模型训练从"记忆"走向"理解"的关键转折。这项工作不仅解决了RL在预训练中的可扩展性难题,更为构建具备真实推理能力的AI系统提供了可行路径。随着研究的深入,我们或将见证新一代AI在复杂决策、创造性问题解决等领域的突破性进展。
推荐阅读
- 《Scaling Laws for Neural Language Models》
- 《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs》
- 《Think Only When You Need: Hybrid Reasoning Models》