01 引言
当前,三维重建技术正处于从"实验室演示"迈向"工业级应用"的关键时期。每一次对场景细节的精准还原,每一帧实时流畅的渲染效果,都在检验算法对真实世界的复现能力。高效、高质量的三维重建能够显著提升数字资产制作效率,助力提升虚拟测试的真实性,加速仿真验证流程。
然而,在"平衡重建质量与效率"这一核心目标下,现有技术仍面临诸多挑战,包括大规模场景的处理效率、动态物体的建模能力,以及跨平台部署的兼容性等难题。
针对这些问题,笔者也有一些思考、经验与看法,本文将与大家一起交流。下文将介绍3DGS原理框架、实战 demo 与自驾仿真落地探索等相关内容。
02 3DGS的原理框架
1、技术概览
3D Gaussian Splatting(3DGS)是一种基于数百万个可学习的“3D色块”来实现逼真3D场景实时渲染的新兴技术。这里的“3D色块”实际上是指3D高斯球——每一个都是具备位置、形状、颜色和透明度属性的基础单元。
利用这些高斯球,我们可以对真实场景进行三维重建,再通过Splatting技术将其投影至二维平面,最后借助图像分块的光栅化方法渲染成最终图像。
以下展示的是采用3DGS技术重建的部分场景,不难看出,无论是场景的细节还原度还是色彩表现力,效果都十分出色。

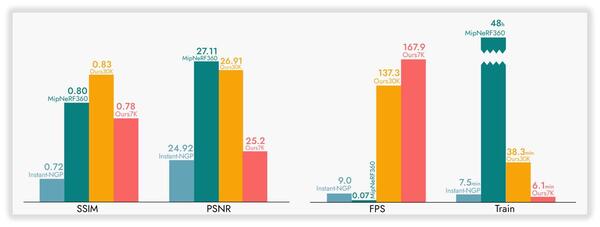
在保持高保真度场景重建的同时,3DGS技术还具备出色的渲染速度,这得益于其采用的基于图像分块的渲染方式。通过与其他三维重建方法对比可见,3DGS在视觉效果上能够媲美NeRF-360,而训练时间却大幅缩短至几十分钟甚至几分钟。相较于NeRF-360动辄数十小时的训练成本,这无疑是一项重要突破。
能够在与Instant-NGP相当的训练时长内,达到接近NeRF-360的重建质量,正是3DGS技术的关键优势所在,也是其在三维重建领域持续受到关注的重要原因。
2、3DGS整体框架
3D Gaussian Splatting(3DGS)的整体框架是一个端到端的管道,其核心思想是将整个三维场景表示为数百万个可学习的3D高斯球。这些高斯球作为场景的基本表示单元,每个都拥有各自的属性,包括3D空间中的位置、描述其形状与方向的协方差矩阵、以及视角相关的球谐函数所表示的颜色和不透明度。
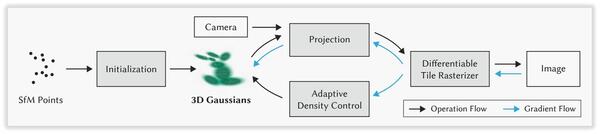
整个流程可以分为7个步骤:
-
初始化:基于输入的RGB图像序列,通过sfm算法(COLMAP)估计初始稀疏点云及相机位姿;
-
高斯空间建模:将初始点云转换为一系列3D高斯椭球;
-
视锥体筛选:根据当前相机参数,剔除位于视锥体范围之外的3D高斯椭球;
-
可微分投影:将保留的3D高斯椭球通过可微分的仿射变换投影至2D图像平面;
-
分块光栅化:将投影后的高斯椭球按图像块组织,并采用基于瓦片的光栅器,实现并行、有序的混合渲染;
-
损失计算与反向传播:比较渲染输出与真实图像,计算重构损失并通过反向传播优化高斯椭球的各项属性参数;
-
自适应密度控制:在训练过程中动态执行高斯椭球的克隆与分裂操作。
03 3DGS的实战Demo搭建
利用开源模型就可以进行一些场景的重建,开源仓库:https://github.com/graphdeco-inria/gaussian-splatting
1、COLMAP初始化点云
要对3DGS模型进行训练,需要先的得到一组初始化点云,利用COLMAP可以从一组无序的照片中,得到相机的拍摄位姿和场景的三维点云。得到初始化点云和相机位姿的效果如下图:

2、输入模型进行迭代训练
得到初始化点云后,就可以将点云信息输入到3DGS模型中进行迭代训练。3DGS迭代训练通过不断渲染误差反馈来优化高斯的位置、颜色和形状,并动态增删高斯,使场景逐渐从粗糙点群精化为高保真实体模型。
以下是初始化点云和训练迭代2万次后的点云对比,可以看到迭代训练后的点云信息更加丰富,场景细节更加多样。利用这些点云和3DGS椭球就可以构建出逼真的三维场景

04 3DGS在自驾仿真中的应用探索
1、从World Extractor到aiSim
World Extractor能从原始传感器数据中,直接创建出3DGS重建的数据信息,从而可以直接导入康谋仿真软件aiSim中,进行场景渲染。这大大节省了仿真场景构建时间。并且,aiSim通过优化渲染模型,可以获得高保真的3DGS场景导入。
-
新构建了GGSR,即通用高斯泼溅渲染器,优化3D重建场景下RayTracying传感器渲染
-
优化广角镜头渲染,增强一致性
-
支持自由移动视角,减少伪影产生
左边是渲染优化前,会出现大FoV相机不一致性。右边是渲染方案优化后,可以增强一致性。

优秀的仿真效果:

05 3DGS未来发展与挑战
在系统探讨了3DGS的技术原理与实践路径后,我们需要清醒地认识到:这项技术正处在从"可用"到"好用"的关键演进阶段,同时也存在着很多待发展的技术要点和面临的挑战!
1、发展
3DGS技术正沿着效率极致化与能力边界拓展的双重路径演进。一方面追求超大规模场景的实时重建与交互,另一方面致力于实现动态场景的精准建模与语义级理解。
(1)效率与应用的极致化
- 实时性与交互性:实现毫秒级动态场景重建与渲染,支持用户实时交互;
- 硬件加速:开发专用硬件(如ASIC/FPGA)与更优的CUDA内核,让3DGS在移动端、边缘设备上流畅运行;
- 大规模场景:突破内存限制,实现对城市级、自然景观等超大规模场景的高效建模与漫游。
(2)动态场景与语义理解
- 4D重建:轻松处理动态物体,生成高质量4D动态场景,直接应用于影视、自动驾驶仿真;
- 语义与编辑:与SAM等分割模型结合,实现实例级的物体识别、分离与编辑;
- 生成式AI融合:作为3D表示,与Diffusion等生成式模型结合,实现文本/图片到3D场景的高质量、高效率生成。
(3)与其他技术的融合与统一
- 与NeRF互补: 发挥3DGS渲染快的优势,弥补NeRF在抗锯齿、细节重建上的不足,形成混合建模管线;
- “3D基础模型”的基石: 作为一种高效的3D表示方法,为构建大规模3D场景的基础模型提供可能。
2、挑战
3DGS技术在渲染质量与动态场景处理方面仍存在理论瓶颈,其"黑箱"特性与数据依赖性也制约了技术的规模化应用。这些挑战亟待从算法原理与工程实现层面协同突破。
(1)渲染质量与一致性
- 锯齿与闪烁:由于2D Splatting的固有特性,容易出现锯齿、走样和边缘闪烁问题;
- 跨视角不一致性:在不同视角下,Gaussian的分布可能出现轻微的不一致,影响几何的精确性;
- 透明与反射材质:对半透明、镜面等高光/反射材质的建模能力仍然较弱,效果不如基于体素渲染的NeRF。
(2)动态场景与学习瓶颈
- 动态处理“粗暴”:目前的动态3DGS多依赖于变形场或时序参数,难以处理剧烈的、非刚性的形变;
- 数据依赖性强:性能高度依赖于输入图像的质量和数量,对稀疏输入或存在大量遮挡的场景,重建效果会急剧下降;
- 缺乏标准与生态:相比成熟的Mesh流程,3DGS缺乏行业标准工具链。
(3)理论基础与可控性
- “黑箱”特性:Gaussian的分布与参数缺乏明确的物理和几何解释,像一个可微分的点云渲染“黑盒”,难以进行精确的、程序化的控制;
- 参数冗余与过拟合:场景复杂度直接与Gaussian数量挂钩,可能导致训练过拟合和存储浪费。
06 总结
显而易见,3DGS以创新的3D高斯球表示方法,在重建质量与效率间实现了突破性平衡。从技术原理到实战演示,再到康谋在自动驾驶仿真中的完整工具链实践,3DGS展现了显著的工程价值。
尽管在动态场景处理和渲染质量方面仍面临挑战,但随着硬件加速和算法优化的持续推进,3DGS有望在自动驾驶、数字孪生等领域发挥更大价值,为三维重建技术开启新的可能!
参考资料
1. https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2. https://arxiv.org/pdf/2308.04079
3. https://arxiv.org/pdf/2401.03890v1