什么是NUMA
NUMA(Non-Uniform Memory Access,非统一内存访问)是一种用于多处理器系统的内存设计架构。在NUMA系统中,每个处理器(或一组处理器)拥有自己的本地内存,处理器访问本地内存的速度比访问其他处理器的内存(远端内存)要快。
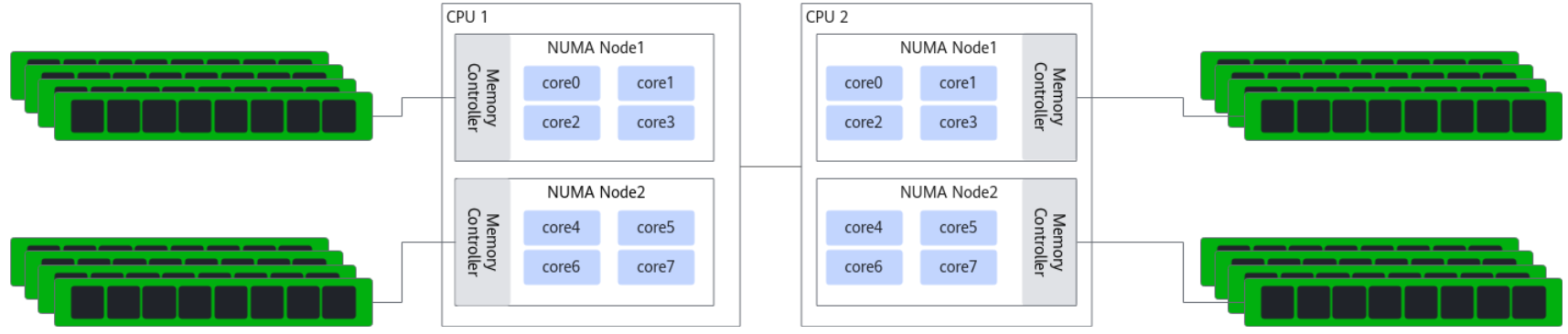
那你可能会有一个疑问,服务器会在什么时候出现跨NUMA的情况呢?
第一种场景:本地节点内存不足,或内存分配策略未绑定节点,导致CPU不得不访问其他节点的内存。
1、当某一节点的 CPU 进程占用内存超过其本地内存上限时,服务器会自动将超出部分的内存分配到其他 NUMA 节点的 “远程内存” 中,此时该 CPU 访问这部分内存就会触发跨 NUMA。
# 服务器有2个NUMA节点(节点0:CPU 0-7 + 128GB 本地内存;节点1:CPU 8-15 + 128GB 本地内存)。仅在节点0的CPU 0上运行一个需要150GB内存的数据库进程:节点0的128GB本地内存耗尽后,剩余22GB内存会被分配到节点1的本地内存中。此时CPU 0访问这22GB内存时,必须跨节点通过NUMA互联总线(如Intel UPI、AMD Infinity Fabric)访问节点1的内存,形成跨NUMA。
2、Linux/Unix系统默认的内存分配策略(如default策略)是 “优先分配本地内存,但本地不足时分配远程内存”;但如果未配置“强绑定策略”(如membind),即使本地内存充足,也可能因内核调度逻辑导致内存被分配到其他节点。
# 运维未通过工具(如numactl、taskset)绑定进程的内存节点,仅绑定了CPU核心。例如:将进程绑定到节点0的CPU 0,但内存分配未限制为节点0,内核可能因 “内存碎片优化” 将部分内存分配到节点1,导致跨NUMA。 # 虚拟化场景中,虚拟机(VM)的内存未与物理NUMA节点对齐:若VM的vCPU绑定到节点0,但VM的内存被KVM分配到节点1的物理内存,vCPU访问内存时会跨NUMA。
3、当多个NUMA节点的CPU需要访问同一块共享内存(如进程间通信的shm、分布式缓存的共享段)时,若共享内存被分配到某一节点(如节点 0),则其他节点(如节点1)的CPU访问该共享内存时,必然触发跨NUMA。
# 节点0的CPU 0创建一块10GB的共享内存,用于与节点1的CPU 8通信;节点1的CPU 8读取 / 写入该共享内存时,需跨节点访问节点0的本地内存,形成跨NUMA。
第二种场景:CPU访问非本地节点的PCIe设备
# 网卡场景:若网卡直连节点1的 PCIe 总线(归属节点1),但处理网卡流量的进程(如Nginx、DPDK 应用)被绑定到节点0的CPU,此时节点0的CPU需要跨节点访问节点1的网卡,导致数据传输延迟升高。 # SSD 场景:若 NVMe SSD归属节点0,但运行数据库的进程被绑定到节点1的CPU,CPU读取SSD数据时需跨NUMA,影响IO性能。
2. 多设备负载集中在单一节点,其他节点需跨节点调用
# 示例:某进程的内存分配在节点0,但其被调度器分配到节点1的CPU 8上运行。此时CPU 8访问该进程的内存(节点 0),就会触发跨 NUMA。 # 常见于默认调度策略(如Linux的CFS调度器):调度器优先考虑CPU负载均衡,而非NUMA节点亲和性,可能导致 “进程-内存-CPU” 跨节点。
# 若虚拟机的vCPU配置未与物理NUMA节点 “对齐”(如vCPU跨越物理节点0和1),KVM等虚拟化层可能将vCPU调度到不同物理节点的CPU上,导致vCPU访问VM内存时跨物理NUMA节点。 # 例如:VM配置4个vCPU,被分配到物理节点0的 CPU 0-2和节点1的CPU 8,此时vCPU 3(对应物理CPU8)访问VM内存(若分配到节点0)时,会跨NUMA。
第四章场景:NUMA节点配置错误或硬件限制
# 若服务器BIOS中未启用 NUMA(或配置为 “UMA 模式”,即均匀内存访问),但实际硬件支持NUMA,可能导致系统误将不同节点的资源视为同一节点,或反之将同一节点拆分为多个,间接引发跨NUMA。# 例如:BIOS中 “NUMA Node Interleaving”(NUMA节点交错)被启用,会强制内存跨节点均匀分配,导致所有CPU访问内存时都可能跨NUMA(除非进程强绑定)。
# 例如:服务器某一NUMA节点的CPU核心全部被占用(如节点0的8个CPU满负载),但仍有新进程需要运行,调度器只能将新进程分配到节点1的CPU,若新进程的内存/设备在节点0,则必然跨NUMA。
numactl工具
numactl工具可用于查看当前服务器的NUMA节点配置、状态,可通过该工具将进程 绑定到指定CPU core,由指定CPU core来运行对应进程。如果系统中没有这个命令可以通过yum -y install numactl numastat来进行安装
使用方法如下
numactl [ --interleave nodes ] [ --preferred node ] [ --membind nodes ] [ --cpunodebind nodes ] [ --physcpubind cpus ] [ --localalloc ] command {arguments ...} # 常用参数 # --hardware 显示系统上可用节点的清单,包括节点之间的相对距离。 # -N --cpunodebind 确保指定的命令及其子进程仅在指定节点上执行。 # -l --localalloc 指定始终从本地节点分配内存。 # -i --interleave=0,1|all:设置内存交错策略,内存将在指定的节点之间循环分配。 # --preferred=node:设置首选节点,如果可能,内存将被分配到这个节点上。 # -m --membind=nodes:设置内存绑定策略,只从指定的节点分配内存。 # --cpunodebind=nodes:设置CPU节点绑定,只在指定节点的CPU上执行命令。 # -C --physcpubind=cpus:设置物理CPU绑定,只在指定的CPU上执行进程。
步骤一、通过查看当前服务器的NUMA配置。
1、检查NUMA节点的内存访问统计
[root@localhost ~]# numastat node0 node1 node2 node3 numa_hit 414 552466 414 55540 numa_miss 0 0 0 0 numa_foreign 0 0 0 0 interleave_hit 0 3005 0 2847 local_node 0 224468 0 15870 other_node 414 327998 414 39670# numa_hit:该节点成功分配本地内存访问的内存大小 # numa_miss:内存访问分配到另一个node的大小,该值和另一个node的numa_foreign相对应 # numa_foreign 其他节点分配失败,由本节点代为分配的次数 # interleave_hit 通过交错策略在本节点分配的次数 # local_node:该节点的进程成功在本节点上分配内存访问的大小 # other_node:该节点进程在其它节点上分配的内存访问的大小# 或者通过下面命令 [root@localhost ~]# cat /sys/devices/system/node/node*/numastat numa_hit 210079 numa_miss 0 numa_foreign 0 interleave_hit 1412 local_node 206615 other_node 3464 ...
2、确认硬件拓扑和NUMA架构
[root@localhost ~]# lscpu | grep -i numa NUMA 节点: 4 NUMA 节点0 CPU: 0-23 NUMA 节点1 CPU: 24-47 NUMA 节点2 CPU: 48-71 NUMA 节点3 CPU: 72-95
3、这告诉你系统有4个NUMA节点,以及每个节点包含了哪些CPU核心。
[root@localhost ~]# numactl -H available: 4 nodes (0-3) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 node 0 size: 130333 MB node 0 free: 129064 MB node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 node 1 size: 130928 MB node 1 free: 130552 MB node 2 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 node 2 size: 130898 MB node 2 free: 130319 MB node 3 cpus: 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 node 3 size: 129903 MB node 3 free: 128242 MB node distances: node 0 1 2 3 0: 10 12 20 22 1: 12 10 22 24 2: 20 22 10 12 3: 22 24 12 10
关键信息:
-
node distances:节点间的访问代价。node0访问node0的内存代价是10,访问node1的内存代价是12(越高越慢)。这清晰地显示了跨节点访问的性能 penalty。
步骤二、通过numactl将进程绑定到指定CPU core。
1、通过 numactl -C 5-15 dd命令即是将进程“dd”绑定到5~15 CPU core上执行
[root@localhost ~]# numactl -C 5-15 --membind=0 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024 记录了1024+0 的读入 记录了1024+0 的写出 1073741824字节(1.1 GB,1.0 GiB)已复制,0.227962 s,4.7 GB/s [root@localhost ~]# numactl -C 5-15 --membind=1 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024 记录了1024+0 的读入 记录了1024+0 的写出 1073741824字节(1.1 GB,1.0 GiB)已复制,0.227861 s,4.7 GB/s [root@localhost ~]# numactl -C 5-15 --membind=2 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024 记录了1024+0 的读入 记录了1024+0 的写出 1073741824字节(1.1 GB,1.0 GiB)已复制,0.332766 s,3.2 GB/s [root@localhost ~]# numactl -C 5-15 --membind=3 dd if=/dev/zero of=/dev/shm/A bs=1M count=1024 记录了1024+0 的读入 记录了1024+0 的写出 1073741824字节(1.1 GB,1.0 GiB)已复制,0.348661 s,3.1 GB/s