Qwen-VL论文笔记
摘要
在这项工作中,我们介绍Qwen-VL系列,一组旨在感知和理解文本与图像的大规模视觉语言模型。从Qwen-LM这个基础大语言模型出发,我们通过如下四条精心设计,赋予了其视觉能力: (1)视觉编码器;(2)输入输出接口设计;(3)三阶段训练流程;(4)多语言多模态清理后的语料。除了常规的图像描述和问答任务,我们通过对齐(图像,注释,坐标框)这种三元组方式,实现了Qwen-VL的定位和文本读取能力。得到的模型包括Qwen-VL,Qwen-VL-Chat在很多视觉基准如图像注释、问答、视觉定位和不同设置下如零样本、少样本任务上都创造了新的记录。此外,在现实世界对话基准上,我们的指令微调Qwen-VL-Chat模型相比现有视觉语言对话机器人也展现出了优越性能。所有模型都公开以促进未来的研究。
方法
模型结构
Qwen-VL的整个网络架构由三个组件构成,模型参数细节参考Table 1。
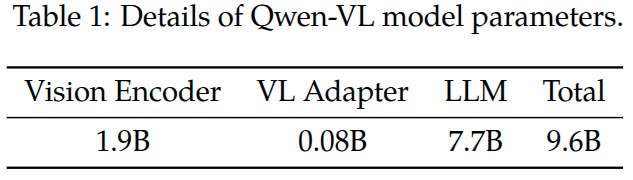
大语言模型: Qwen-VL采用大语言模型Qwen-7B作为其基础组件
视觉编码器: Qwen-VL视觉编码器采用ViT架构,使用Openclip的VIT-BigG这个模型权重进行初始化。在训练和推理过程中,输入图像都调整为特定的尺寸(224x224, 448x448)。视觉编码器将图片分拆为14x14的小块,进而生成一组图像特征。
位置感知的视觉-语言适配器: 为了解决很长图像特征序列带来的效率问题,Qwen-VL采用了一个视觉-语言适配器来压缩图像特征。这个适配器是一个随机初始化的单层cross-attention模块,该模块采用一组可训练的向量作为Query向量,图像特征作为Key向量。这种机制将视觉特征序列的长度压缩为固定的256. 关于查询向量数量的消融实验请参考原味附录E.2. 考虑到细粒度图像理解,器位置信息的重要性,将2D绝对位置编码集成到cross-attention中的query-key对中,以消除在压缩过程中位置信息的损失。 压缩后的图像特征序列长度为256,然后被送给大语言模型。
注: 位置信息是如何注入的? 假设将图像分拆为hxw个patch,对应第(i,j)位置patch特征记为\(K_{i,j}\), 2D的绝对位置编码可以求出pos_emb = get_2d_sincos_pos_embed(h, w, d),那么可以通过\(K_{i,j}^{'}=K_{i,j} + pos_emb(i,j)\)这种方式注入。这种方式也很好理解。而查询向量由于是训练学习的,没有明确2D空间位置,因此不太可能给查询向量这样加。真实的位置编码如何添加请阅读Qwen-VL代码获取。
注: 如何实现图像特征训练的压缩? 假设图像特征序列长度为1024, 查询特征序列长度为256.
# Q: [B, 256, D], K=V: [B, 1024, D]
scores = torch.bmm(queries, image_features_with_pos.transpose(1, 2)) / (D ** 0.5) # [B, 256, 1024]
attn_weights = F.softmax(scores, dim=-1) # [B, 256, 1024]# 加权聚合 Value(这里 V = 原始图像特征 或 也可用带位置的,依设计)
compressed_features = torch.bmm(attn_weights, image_features) # [B, 256, D]
输入和输出
图像输入: 图像经过视觉编码器和适配器后,得到固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,2个特殊的token: , 添加到图像特征序列的前面和后面,表明图像内容的开始和结束。
坐标框输入和输出: 为了增强模型的细粒度视觉理解和定位能力,Qwen-VL训练包含区域描述、问题和检测的数据。不同于常规任务比如图文描述/问题,这类任务要求模型精确的理解和以某种格式生成区域描述。为此对于任意给定的坐标框,首先归一化范围在[0,1000),再转换为这种\((X_{topleft}, Y_{topleft}), (X_{bottomright}, Y_{bottomright})\)格式。 这个字符串按Text解析,为了区分检测字符串和常规的文本字符串,使用两个特征token:
训练
如图3所示,Qwen-VL模型的训练过程包括3个阶段:2个预训练阶段和最后一个指令微调阶段。
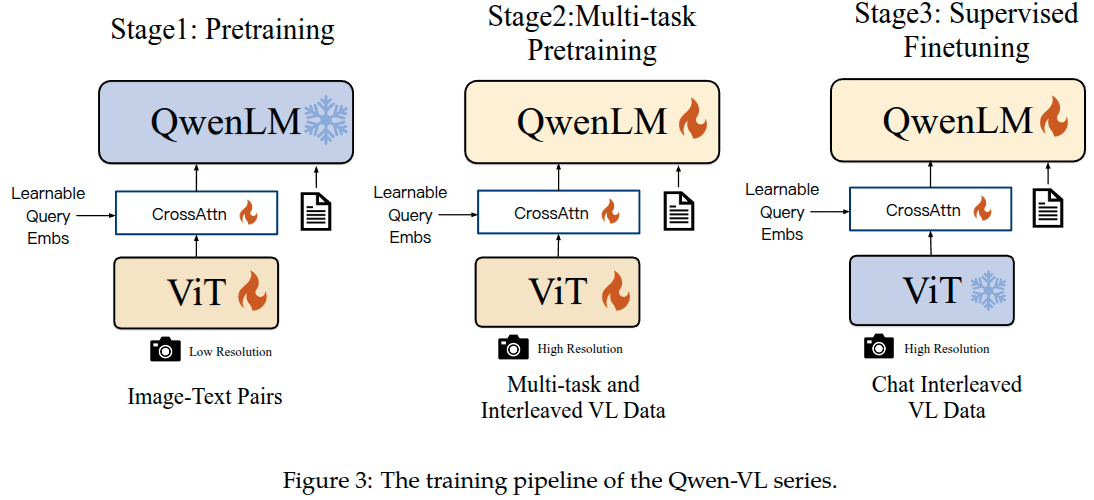
预训练
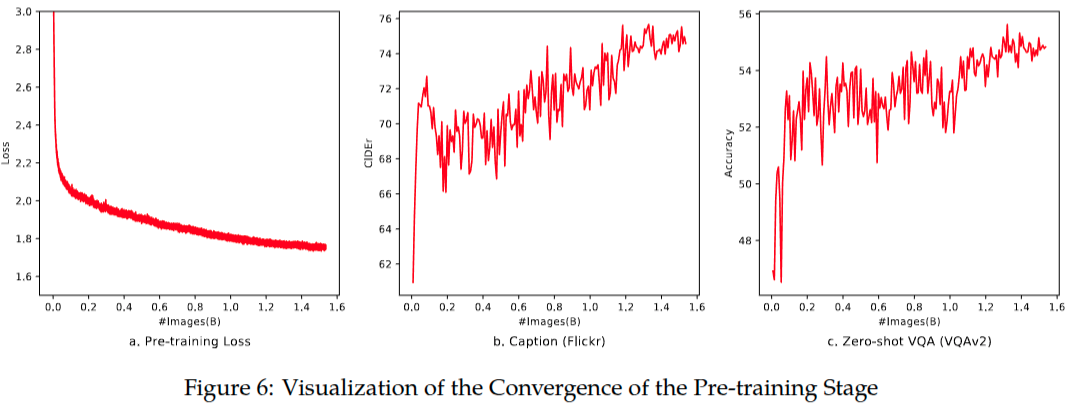
预训练的第一阶段,我们主要是利用大规模弱标注网络爬取的图文对。预训练守护聚集中包含许多公开可获取的资源和一些内部数据。我们努力清理了某些模式的数据集。总结在了表2中,原始数据集有50亿个图文对,清理后剩余14亿,文本部分,其中77.3%是英文,22.7%是中文。 在这个阶段训练冻结大语言模型的参数,仅优化视觉编码器和VL适配器。输入图片的尺寸统一调整为224x224。训练目标是最小化文本token的交叉熵。最大学习率是\(2e^{-4}\),训练batchsize设置为30720,整个预训练过程持续50000步,预计消费了15亿图文对数据。(大约就是完成1个epoch训练)

第一阶段预训练随着训练图像的增多,训练损失值稳定得下降。而且观察到,虽然在这个训练阶段没有添加VQA数据,但是零样本分数也在波动式增长。
多任务预训练
在第二阶段的多任务预训练中,采用了具有更高输入分辨率的高质量和细粒度的VL注释数据,而且数据以图文交替方式组织。Qwen-VL同时在7个任务上训练,总结在表格3中。Caption数据与表格2中是一致的,除了使用更少的样本和排除掉LAION-COCO。(之所以是使用更少的数据是可能由于筛选出图片尺寸达到448x448分辨率,排除LAION-COCO是由于它是合成的数据。)最后通过将相同任务的数据以交替方式打包在一起,以达到2048的训练长度。这个阶段使用的图片输入分辨率是448x448以减少信息的损失。
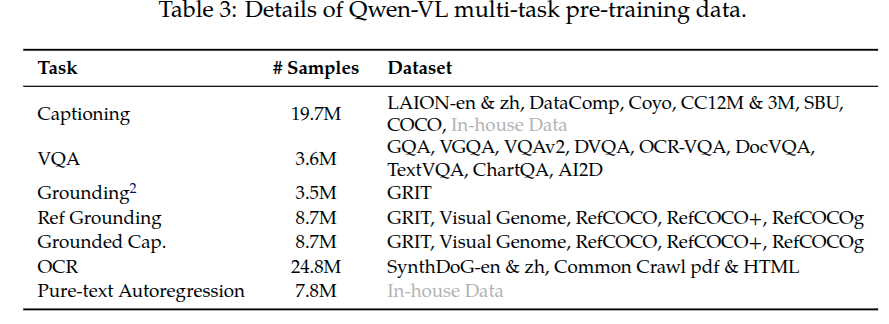
注: text-oriented task 表示什么含义? 指图片中包含文字的这类图片,识别出图片中的文字,是多模态大模型能力一个重要方面。通常会用包含文字的图片及对应文字内容构成数据集来训练多模态模型。这里就使用来自Common Crawl中的pdf和HTML格式的数据来训练多模态模型。pdf格式数据很好理解,HTML格式是指使用HTML渲染得到的界面截图得到图片,对应文字信息是HTML页面中呈现的文字内容,可能也包含页面中包含图片信息的描述。
有监督微调
在这个阶段,通过指令微调微调Qwen-VL预训练模型来增强它的指令跟随和对话能力,得到了交互式的Qwen-VL-Chat模型。多模态指令微调数据主要来自由LLM自指令生成的描述数据和对话数据。这经常只能解决单张图片对话和推理,限制了图像内容理解。本文通过人工标注、模型生成和策略拼接构建了一个额外的对话数据集,以赋予Qwen-VL模型定位和多图理解能力。另外本文将多模态数据和纯对话数据进行混合,以确保模型通用的对话能力。整个指令数据集达到了35万条。
strategy concatenation 策略拼接具体包含哪些呢?
- 多轮对话拼接:把单轮的QA数据拼接为多轮对话,模拟真实的人机对话场景
- 原始数据:- Q1: 这张图里有什么? -> A1: 一只猫。- Q2: 猫在做什么? -> A2: 在沙发上睡觉
- 拼接后:用户: 这张图片里有什么?模型: 一只猫。用户: 猫在做什么?模型: 在沙发上睡觉。- 多图拼接: 把多个单图数据组合成一个任务,让模型在多个图像间进行比较或推理。
- 原始数据:- 图1 -> 描述: 一只狗在草地上跑。- 图2 -> 描述: 一只猫在沙发上睡觉。
- 拼接后:- Q: 对比这两张图片里的动物,它们在做什么?- A: 狗在跑,而猫在睡觉。- 任务拼接:把Caption、VQA、Grounding等不同类型的数据组合在一起- 给一张图,既有caption,又有定位坐标,还有相关的QA。- 请描述这张图,并标出人所在的位置。- LLM辅助拼接- 用大语言模型把原始数据扩展成多轮、多任务格式。- 比如给单一caption,让LLM生成对应的问题,推理链,形成更复杂的instruction数据。
We confirm that the model effectively transfers these capabilities to a wider range of languages and question types. 这句话如何理解?
这里的these capabilities是指图像caption、视觉问答、视觉定位、OCR识别、指令跟随与对话交互能力等。虽然指令数据集有35万,但是毕竟有限覆盖不全,比如没有包含西班牙语的多轮对方多模态样本,或者视觉定位样本比较少。 这句话所表达的含义就是,论文验证了在这样的条件下,模型仍将这些能力迁移到了更广泛的语言和问题类型。
数据格式
多任务预训练的数据格式
下图展示了7种任务的数据格式,黑色文本看作前缀序列不计算损失,而蓝色文本作为Ground truth要计算损失值。

SFT数据格式
为了更好地支持多图像对话和多个图像输入,我们在不同图像前添加字符串“Picture id:”,其中 id 对应图像在对话中输入的顺序。在对话格式方面,我们采用 ChatML(OpenAI)格式构建指令微调数据集,每个对话轮次的语句均使用两个特殊标记(<im_start> 和 <im_end>)进行标注,以帮助模型识别对话的起止边界。在训练中,为保持训练与推理分布一致,仅对答案和特殊标记进行监督(蓝色标注),而不监督角色名和问题。
