C 预处理:宏定义、带参宏、副作用消除、条件编译、系统预定义宏、调试宏开关 ,写完代码“不改一行”就能切换功能!
一、编译四步曲回顾
| 阶段 | 工具 | 输入→输出 | 关键选项 |
|---|---|---|---|
| 预处理 | cc1 |
.c → .i |
gcc -E |
| 编译 | cc1 |
.i → .s |
gcc -S |
| 汇编 | as |
.s → .o |
gcc -c |
| 链接 | ld |
.o → a.out |
gcc -lc -lgcc |
> 本篇聚焦第一步:预处理——所有 # 开头指令都在这里完成
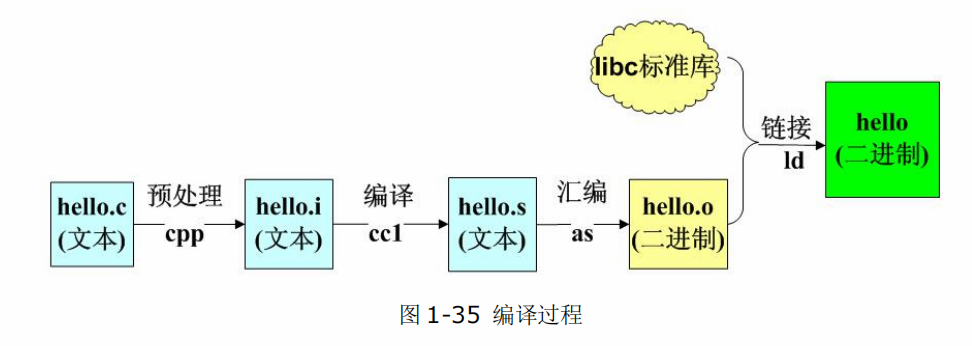
预处理
在C语言程序源码中,凡是以井号(#)开头的语句被称为预处理语句,这些语句严格意义上并不属于C语言语法的范畴,它们在编译的阶段统一由所谓预处理器(cc1)来处理。所谓预处理,顾名思义,指的是真正的C程序编译之前预先进行的一些处理步骤,这些预处理指令包括:
1.头文件:#include
2.定义宏:#define
3.取消宏:#undef
4.条件编译:#if、#ifdef、#ifndef、#else、#elif、#endif
5.显示错误:#error
6.修改当前文件名和行号:#line
7.向编译器传送特定指令:#progma
基本语法
- 一个逻辑行只能出现一条预处理指令,多个物理行需要用反斜杠
\连接成一个逻辑行 - 预处理是整个编译全过程的第一步:预处理 - 编译 - 汇编 - 链接
- 可以通过如下编译选项来指定来限定编译器只进行预处理操作:
gcc example.c -o example.i -E
编译
经过预处理之后生成的.i 文件依然是一个文本文件,不能被处理器直接解释,我们需要进一步的翻译。接下来的编译阶段是四个阶段中最为复杂的阶段,它包括词法和语法的分析,最终生成对应硬件平台的汇编语言(不同的处理器有不同的汇编格式),具体生成什么平台的汇编文件取决于所采用的编译器,如果用的是 GCC,那么将会生成 x86 格式的汇编文件,如果用的是针对 ARM 平台的交叉编译器,那么将会生成 ARM 格式的汇编文件。
gcc hello.i -o hello.s -S
加上一个编译选项 -S 就可以使得 gcc 在进行完第一和第二阶段之后停下来,生成一个默认后缀名为.s 的文本文件。打开此文件看一看,你会发现这是一个符合 x86 汇编语言的源程序文件。
汇编
接下来的步骤相对而言比较简单,编译器 gcc 将会调用汇编器 as 将汇编源程序翻译成为可重定位文件。汇编指令跟处理器直接运行的二进制指令流之间基本是一一对应的关系,该阶段只需要将.s 文件里面的汇编翻译成指令即可。
gcc hello.s -o hello.o -c
可以看到,只要在编译的时候加上一个编译选项-c,则会生成一个扩展名为.o 的文件,这个文件是一个 ELF 格式的可重定位(relocatable)文件,所谓的可重定位,指的是该文件虽然已经包含可以让处理器直接运行的指令流,但是程序中的所有的全局符号尚未定位,所谓的全局符号,就是指函数和全局变量,函数和全局变量默认情况下是可以被外部文件引用的,由于定义和调用可以出现在不同的文件当中,因此他们在编译的过程中需要确定其入口地址,比如 a.c 文件里面定义了一个函数 func( ),b.c 文件里面调用了该函数,那么在完成第三阶段汇编之后,b.o 文件里面的函数 func( )的地址将是 0,显然这是不能运行的,必须要找到 a.c 文件里面函数 func( )的确切的入口地址,然后将 b.c 中的“全局符号”func重新定位为这个地址,程序才能正确运行。因此,接下来需要进行第四个阶段:链接。
链接
如前面所述,经过汇编之后的可重定位文件不能直接运行,因为还有两个很重要的工作没完成,首先是重定位,其次是合并相同权限的段。
关于重定位的问题,上面已经给出了简单的描述。更一般的地,我们编译一个程序通常都需要链接系统的标准 C 库、gcc 内置库等基本库文件。因为 Linux 下任何一个程序编译都需要用到这些基本库的全局符号。
gcc hello.o -o hello -lc -lgcc
二、宏的概念
宏(macro) 实际上就是一段特定的字串,在源码中用以直接替换为指定的表达式。例如:
#define PI 3.14
此处,PI 就是宏(宏一般习惯用大写字母表达,以区分于变量和函数,但这并不是语法规定,只是一种习惯),是一段特定的字串,这个字串在源码中出现时,将被替换为3.14。例如:
int main()
{printf("圆周率: %f\n", PI); // 此语句将在预处理阶段被替换为:printf("圆周率: %f\n", 3.14);
}
宏的作用:
- 使得程序更具可读性:字串单词一般比纯数字更容易让人理解其含义。
- 使得程序修改更便利:修改宏定义,即修改了所有该宏替换的表达式。
- 提高程序的运行效率:程序的执行不再需要函数切换开销,而是在预处理时(程序运行前)已经展开。
三、无参宏:文本替换
无参宏意味着使用宏的时候,无需指定任何参数,比如:
#define PI 3.14
#define SCREEN_SIZE 800*480*4
int main()
{// 在代码中,可以随时使用以上无参宏,来替代其所代表的表达式:printf("圆周率: %f\n", PI); mmap(NULL, SCREEN_SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, ...);
}
注意到,上述代码中,除了有自定义的宏,还有系统预定义的宏:
// 自定义宏:
#define PI 3.14
#define SCREEN_SIZE 800*480*4 // 系统预定义宏
#define NULL ((void *)0)
#define PROT_READ 0x1 /* Page can be read. */
#define PROT_WRITE 0x2 /* Page can be written. */
#define MAP_SHARED 0x01 /* Share changes. */printf("File=%s Line=%d Date=%s\n", __FILE__, __LINE__, __DATE__);
宏的最基本特征是进行直接文本替换,以上代码被替换之后的结果是:
int main()
{printf("圆周率: %f\n", 3.14); mmap(((void *)0), 800*480*4, 0x1|0x2, 0x01, ...);
}
四、带参宏:函数式替换(零开销)
带参宏意味着宏定义可以携带“参数”,从形式上看跟函数很像(宏函数),例如:
#define MAX(a, b) a>b ? a : b
#define MIN(a, b) a<b ? a : b
以上的MAX(a,b) 和 MIN(a,b) 都是带参宏,不管是否带参,宏都遵循最初的规则,即宏是一段待替换的文本,例如在以下代码中,宏在预处理阶段都将被替换掉:
int main()
{int x = 100, y = 200;printf("最大值:%d\n", MAX(x, y));printf("最小值:%d\n", MIN(x, y));// 以上代码等价于:// printf("最大值:%d\n", x>y ? x : y);// printf("最小值:%d\n", x<y ? x : y);
}
带参宏的特点:
a.直接文本替换,不做任何语法判断,更不做任何中间运算。
b.宏在编译的第一个阶段(预处理)就被替换掉,运行中不存在宏。
c.宏将在所有出现它的地方展开,这一方面牺牲了内存空间,另一方面有节约了切换时间。
带参宏的副作用消除(必须加括号)
由于宏仅仅做文本替换,中间不涉及任何语法检查、类型匹配、数值运算,因此用起来相对函数要麻烦很多。例如:
#define MAX(a, b) a>b ? a : bint main()
{int x = 100, y = 200;printf("最大值:%d\n", MAX(x, y==200?888:999));
}
直观上看,无论 y 的取值是多少,表达式 y==200?888:999 的值一定比 x 要大,但由于宏定义仅仅是文本替换,中间不涉及任何运算,因此等价于:
printf("最大值:%d\n", x>y==200?888:999 ? x : y==200?888:999);
可见,带参宏的参数不能像函数参数那样视为一个整体,整个宏定义也不能视为一个单一的数据,事实上,不管是宏参数还是宏本身,都应被视为一个字串,或者一个表达式,或者一段文本,因此最基本的原则是:
- 将宏定义中所有能用括号括起来的部分,都括起来,比如:
- 把宏函数中的每一个参数使用( ) 括起来强调优先级
- 在使用一对( ) 把整个宏的表达式括起来,强调他们是一个整体
#define MAX(a, b) ((a)>(b) ? (a) : (b))
五、无值宏定义
定义无参宏的时候,不一定需要带值,无值的宏定义经常在条件编译中作为判断条件出现,例如:
// 定义无值宏作为条件编译标志
#define DEBUG
#define BIG_ENDIAN
#define USE_OPTIMIZED_CODE// 使用这些标志进行条件编译
#ifdef DEBUG#define DBG_PRINT(x) printf("DEBUG: %s\n", x)
#else#define DBG_PRINT(x) // 空定义,调试代码被移除
#endif#ifdef BIG_ENDIAN#define SWAP_BYTES(x) __builtin_bswap32(x)
#else#define SWAP_BYTES(x) (x) // 小端序无需交换
#endif
六、条件编译
概念: 有条件的编译,通过控制某些宏的值,来决定编译哪段代码。
- 形式1:判断表达式
MACRO是否为真,据此决定其所包含的代码段是否要编译- 注意:#if 形式条件编译需要有值宏
#define A 0
#define B 1
#define C 2
// 多路分支
#if A... // 如果 A 为真,那么该段代码将被编译,否则被丢弃
#elif B...
#elif C...
#endif
#if DEBUG... // 宏DEBUG 在代码并没有定义,因此可以通过编译命令直接定义并对他进行赋值
#endif
该操作可以在不打开任何项目代码的情况下直接通过编译器来启动或禁用某一写代码块。
gcc Test.c -DDEBUG=1 // 如此编译则 第10行的代码块会被编译
gcc Test.c // 如此编译则 第10行的代码块【不会】被编译
gcc Test.c -DDEBUG=0 // 如此编译则 第10行的代码块【不会】被编译
- 形式2:判断宏
MACRO是否已被定义,据此决定其所包含的代码段是否要编译- 判断是否有定义的语法则可以使用有值宏或无值宏都可以
// 单独判断
#ifdef MACRO...
#endif// 二路分支
#ifdef MACRO...
#else...
#endif
- 形式3:判断宏
MACRO是否未被定义,据此决定其所包含的代码段是否要编译
// 单独判断
#ifndef MACRO...
#endif// 二路分支
#ifndef MACRO...
#else...
#endif
总结:
#ifdef此种形式,判定的是宏是否已被定义,这不要求宏有值。#if、#elif这些形式,判定的是宏的值是否为真,这要求宏必须有值。
条件编译的使用场景
控制调试语句:
在程序中,用条件编译将调试语句包裹起来,通过gcc编译选项随意控制调试代码的启停状态。
例如:
gcc example.c -o example -D MACRO
以上语句中,-D意味着 Define,MACRO 是程序中用来控制调试语句的一个宏,如此一来就可以在完全不需要修改源代码的情况下,通过外部编译指令选项非常方便地控制调试信息的启停。
选择代码片段:
在一些大型项目中(例如 Linux 内核),某个相同功能的模块往往有不同的实现,需要用户根据具体的情况来“配置”,这个所谓的配置的过程,就是对代码中不同的宏的选择的过程。
例如:
#define A 0 // 网卡1
#define B 1 // 网卡2 √
#define C 0 // 网卡3// 多路分支
#if A...
#elif B...
#elif C...
#endif