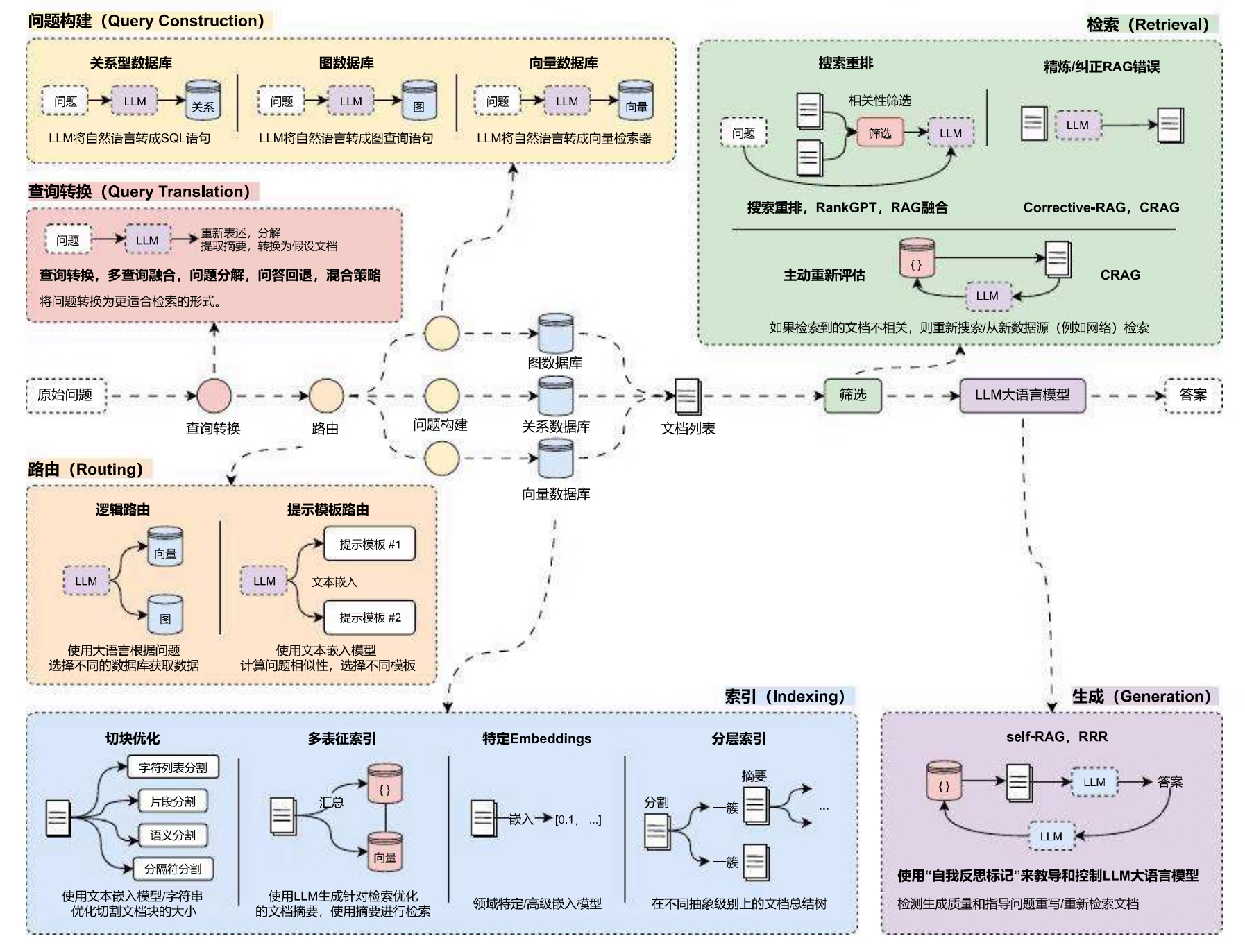
一、RAG是什么?
RAG(Retrieval-Augmented Generation,检索增强生成), 一种AI框架,将传统的信息检索系统(例如数据库)的优势与生成式大语言模型(LLM)的功能结合在一起。不再依赖LLM训练时的固有知识,而是在回答问题前,先从外部资料库中"翻书"找资料,基于这些资料生成更准确的答案。
RAG技术核心缓解大模型落地应用的几个关键问题:
二、RAG核心流程
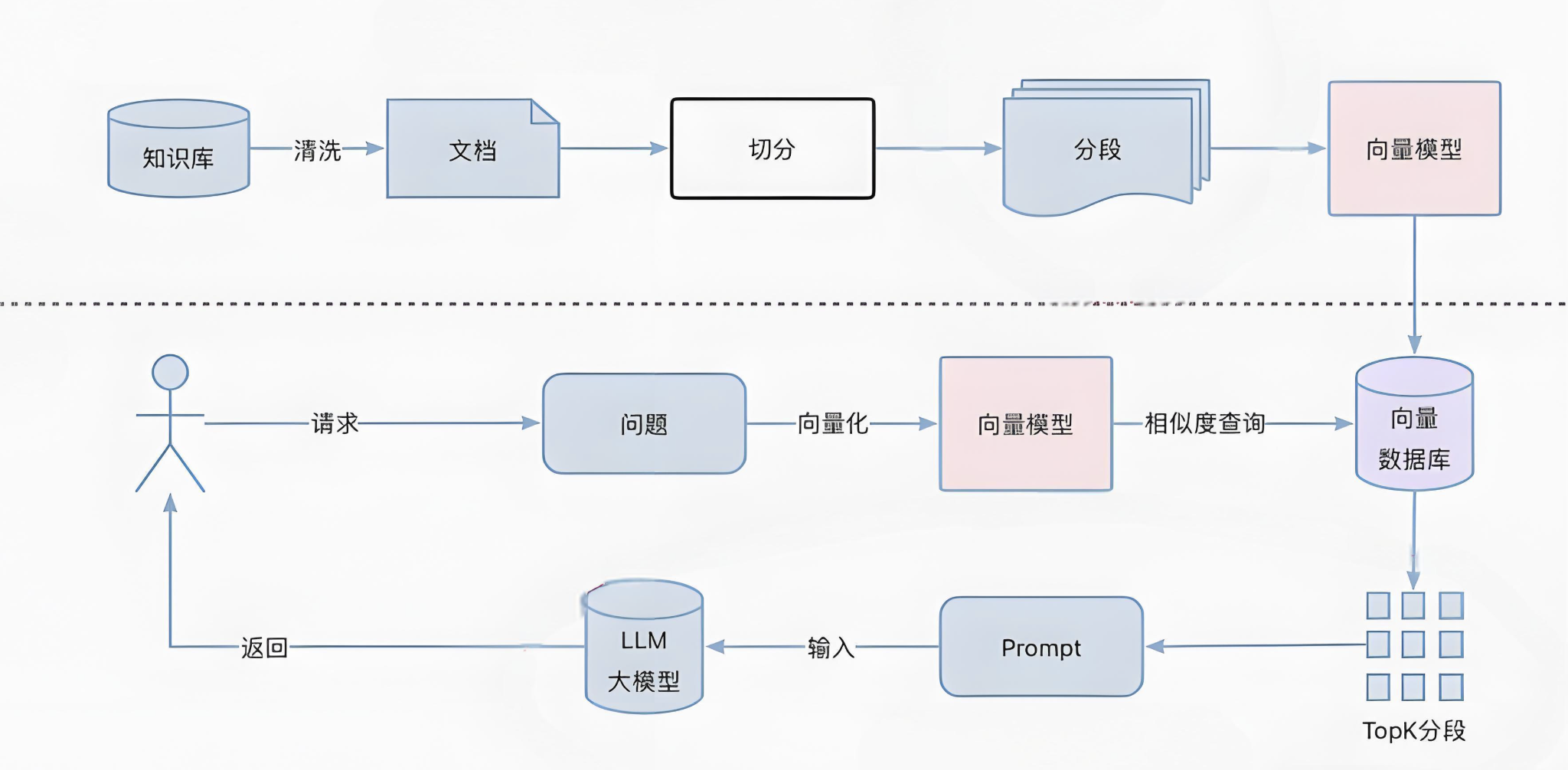
2.1 知识准备阶段
1、数据预处理
1、文档解析
例如:
[标题] 什么是 ROMA?
[段落] ROMA 是一个全自主研发的前端开发基于自定义DSL(Jue语言),一份代码,可在iOS、Android、Harmony、Web四端运行的跨平台解决方案。
[段落] ROMA 框架的中文名为罗码。
[标题] 今天天气
[列表项] 今天的室外温度为35°C,天气晴朗。文档的解析过程需要考虑不同文档内容例如文本、图片、表格等场景,以及文档的语言,布局情况,可以考虑使用一些优秀的三方工具或者一些视觉模型,布局分析模型,语义理解模型来辅助解析。
2、数据清洗与标准化处理
提升文本质量和一致性,使向量表示更准确,从而增强检索相关性和LLM回答质量;同时消除噪声和不规则格式,确保系统能正确理解和处理文档内容。
包括:
数据的清洗和标准化过程可以使用一些工具或NLTK、spaCy等NLP工具进行处理。
例如:
<p>ROMA框架</p>
处理:
"ROMA框架"今天的室外温度为35°C,天气晴朗。
处理:
"2025-07-17 的室外温度为35°C,天气晴朗"3、元数据提取
关于数据的数据,用于描述和提供有关数据的附加信息。
元数据在RAG中也非常重要,不仅提供了额外的上下文信息,还能提升检索质量:
1. 检索增强
2. 上下文丰富
常见的元数据提取方式:
例如:
complete_metadata_chunk1 = {'file_path': '/mydocs/roma_intro.md','file_name': 'roma_intro.md','chunk_id': 0,'section_title': '# 什么是 ROMA?','subsection_title': '','section_type': 'section','chunking_strategy': 3,'content_type': 'product_description','main_entity': 'ROMA','language': 'zh-CN','creation_date': '2025-07-02', # 从文件系统获取'word_count': 42 # 计算得出,'topics': ['ROMA', '前端框架', '跨平台开发'],'entities': {'products': ['ROMA', 'Jue语言'], # 实体识别'platforms': ['iOS', 'Android', 'Web']},
}2、内容分块(Chunking)
在RAG架构中,分块既是核心,也是挑战,它直接影响检索精度、生成质量,需要在检索精度、语境完整性和计算性能之间取得平衡。
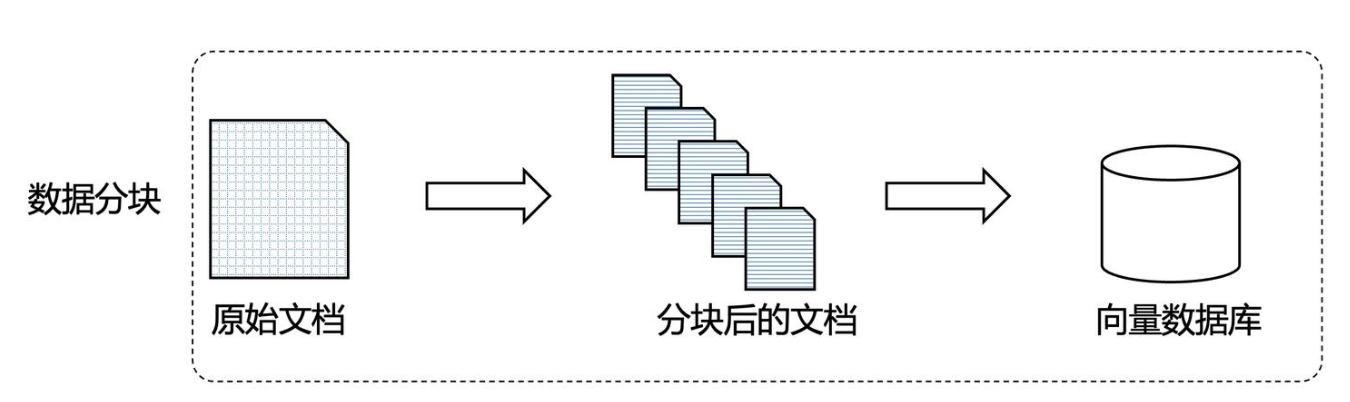
内容分块将长文档切分成小块,可以解决向量模型的token长度限制,使RAG更精确定位相关信息,提升检索精度和计算效率。
autobots 功能分块:
实际RAG框架中按照文档的特性选择合适的分块策略进行分块.
常见的分块策略
1. 按大小分块
按固定字符数进行分块,实现简单但可能切断语义单元。
优点:实现简单且计算开销小,块大小均匀便于管理。
缺点:可能切断语义单元,如句子或段落被分到不同块中。
例如:
第一段:# ROMA框架介绍ROMA是一个全自主研发的前端开发框架,基于自定义DSL(Jue语言)。
一份代码,可在iOS、Android、Harmony第二段:、Web三端运行的跨平台解决方案。ROMA框架的中文名为罗码。句子被截断,"一份代码,可在iOS、Android、Harmony" 和 "、Web三端运行的跨平台解决方案" 被分到不同块,影响理解。
2. 按段落分块
以段落为基本单位进行分块,保持段落完整性,但段落长度可能差异很大。
优点:尊重文档自然结构,保留完整语义单元。
缺点:段落长度差异大,可能导致块大小不均衡。
例如:
第一段:# ROMA框架介绍ROMA是一个全自主研发的前端开发框架,基于自定义DSL(Jue语言)。
一份代码,可在iOS、Android、Harmony、Web三端运行的跨平台解决方案。ROMA框架的中文名为罗码。第二段:# 核心特性1. 跨平台:一套代码运行于多端2. 高性能:接近原生的性能表现3. 可扩展:丰富的插件系统第一段包含标题和多行内容,而其他段落相对较短,可能导致检索不均衡。
3. 按语义分块
基于文本语义相似度进行动态分块,保持语义连贯性,但计算开销大。
说明:基于文本语义相似度动态调整分块边界。
优点:保持语义连贯性,能识别内容主题边界。
示例:
第一段:# ROMA框架介绍ROMA是一个全自主研发的前端开发框架,基于自定义DSL(Jue语言)。
一份代码,可在iOS、Android、Harmony、Web四端运行的跨平台解决方案。第二段:ROMA框架的中文名为罗码。
## 核心特性1. 跨平台:一套代码运行于多端使用依赖模型质量,相同文本在不同运行中可能产生不同分块结果。
分块策略总结:
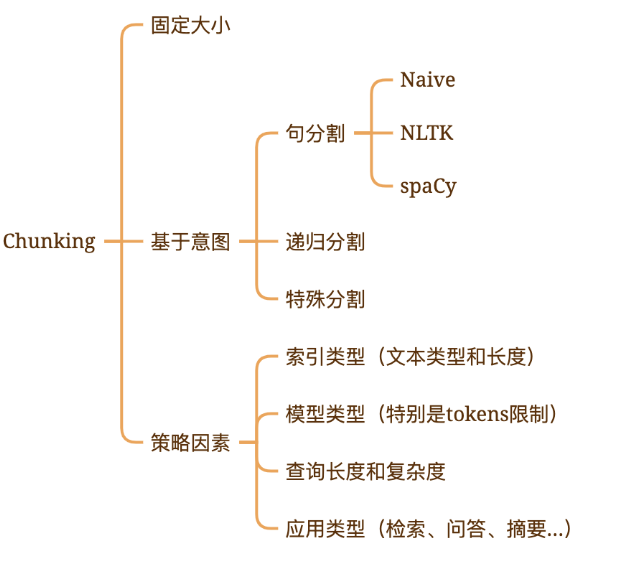
优化方式
结合多种分块方法的优点,如先按段落分块,再根据块大小调整,做到既保持语义完整性,又能控制块大小均匀
根据内容特性动态调整块之间的重叠区域大小,关键信息出现在多个块中,提高检索召回率
常用的分块工具
3、向量化(Embedding)
将高维文本数据压缩到低维空间,便于处理和存储。将文本转换为计算机可以理解的数值,使得计算机能够理解和处理语义信息,从而在海量数据文本中实现快速、高效的相似度计算和检索。
简单理解:通过一组数字来代表文本内容的“本质”。
例如,"ROMA是一个跨平台解决方案..."这句话可能被转换为一个384维的向量:
[块1] 什么是ROMA?
ROMA是一个全自主研发的前端开发框架,基于自定义DSL(Jue语言)...[{"chunk_id": "doc1_chunk1","text": "# 什么是 ROMA?\nROMA 是一个全自主研发的前端开发基于自定义DSL(Jue语言),一份代码,可在iOS、Android、Harmony、Web端运行的跨平台解决方案。","vector": [0.041, -0.018, 0.063, ..., 0.027],"metadata": {"source": "roma_introduction.md","position": 0,"title": "ROMA框架介绍"}},// 更多文档块...
]常用的Embedding模型
| 模型名称 | 开发者 | 维度 | 特点 |
| all-minilm-l6-v2 | Hugging Face | 384 | 高效推理,多任务支持,易于部署,适合资源受限环境 |
| Text-embedding-ada-002 | OpenAI | 1536 | 性能优秀,但可能在国内使用不太方便。 |
| BERT embedding | 768 (base) 1024 (large) | 广泛用于各种自然语言处理任务。 | |
| BGE (Baidu’s General Embedding) | 百度 | 768 | 在HuggingFace的MTEB上排名前2,表现非常出色。 |
4、向量数据库入库
将生成的向量数据和元数据进行存储,同时创建索引结构来支持快速相似性搜索。
常用的向量数据库包括:
| 数据库 | 复杂度 | 核心优势 | 主要局限 | 适用场景 |
| ChromaDB | 低 | 轻量易用, Python集成 | 仅支持小规模数据 | 原型开发、小型项目 |
| FAISS | 中 | 十亿级向量检索, 高性能 | 需自行实现特殊化 | 学术研究、大规模检索 |
| Milvus | 高 | 分布式扩展, 多数据类型支持 | 部署复杂, 资源消耗大 | 企业级生产环境 |
| Pinecone | 低 | 全托管, 自动扩缩容 | 成本高, 数据在第三方云 | 无运维团队/SaaS应用 |
| Elasticsearch | 高 | 全文搜索强大,生态系统丰富 | 向量搜索为后加功能,性能较专用解决方案差 | 日志分析、全文搜索、通用数据存储 |
2.2 问答阶段
1、查询预处理
` 意图识别:使用分类模型区分问题类型(事实查询、建议、闲聊等)。
问题预处理:问题内容清洗和标准化,过程与前面数据预处理类似。
查询增强: 使用知识库或LLM生成同义词(如“动态化” → “Roma”),上下文补全可以结合历史会话总结(例如用户之前问过“Roma是什么”)。
2、数据检索(召回)
1、向量化
使用与入库前数据向量化相同的模型,将处理后的问题内容向量化。
例子:
问题: "ROMA是什么?"处理后
{"vector": [0.052, -0.021, 0.075, ..., 0.033],"top_k": 3,"score_threshold": 0.8,"filter": {"doc_type": "技术文档"}
}2、检索
相似度检索:查询向量与所存储的向量最相似(通过余弦相似度匹配)的前 top_k 个文档块。
关键词检索:倒排索引的传统方法,检索包含"Roma"、"优势"等精确关键词的文档。
混合检索: 合并上面多种检索结果,效果最优。
例如:检索"ROMA是什么?"
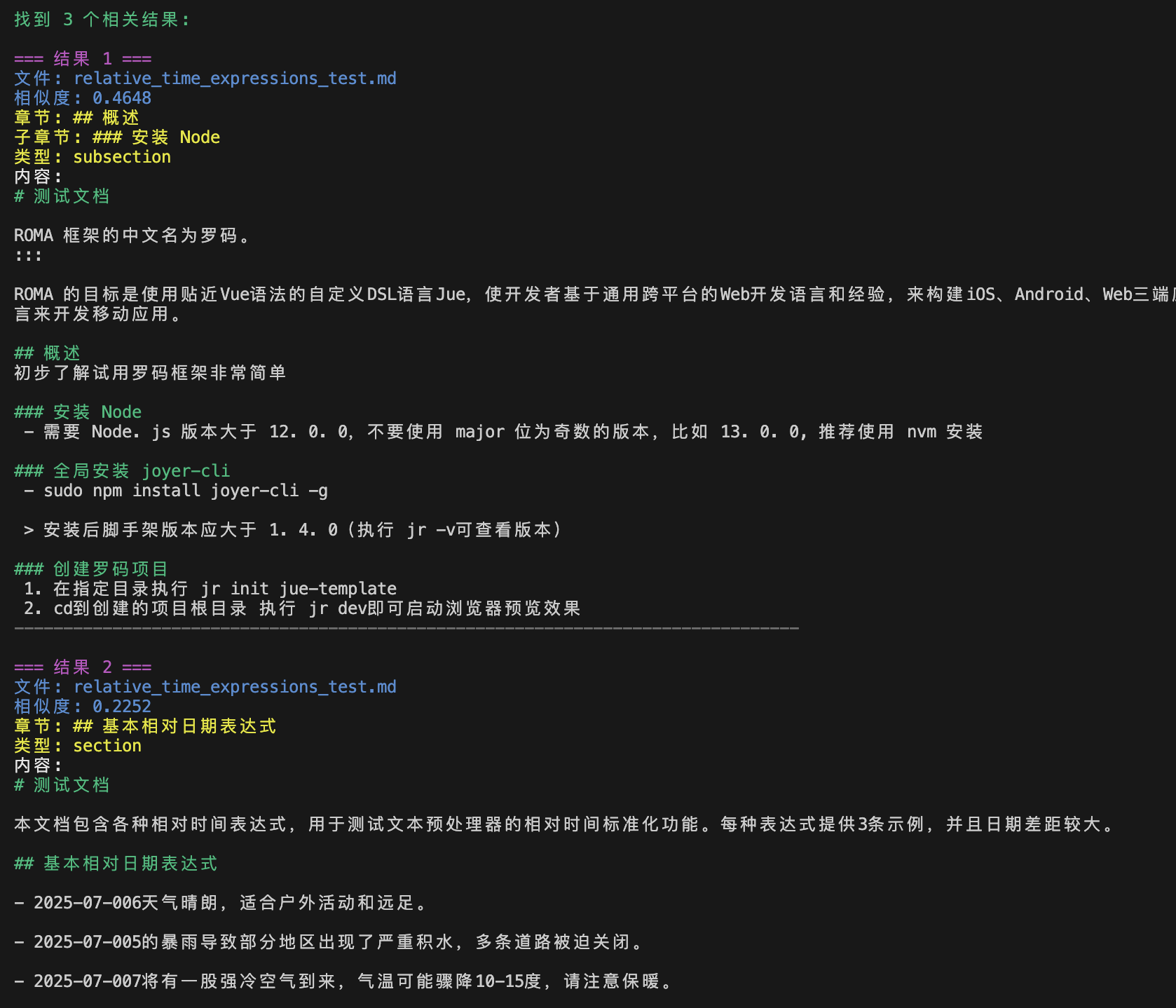
3、重排序(Reranking)
初步检索在精度和语义理解上的不足,通过更精细的上下文分析提升结果相关性。它能更好处理同义词替换、一词多义等语义细微差异,使最终结果准确。
原理:使用模型对每个检索结果计算相关性分数。
归一化:重排序模型原始输出分数没有固定的范围,它可能是任意实数,将结果归一化处理,将分数映射到 [0, 1] 范围内,使其更容易与向量相似度分数进行比较。
例如:
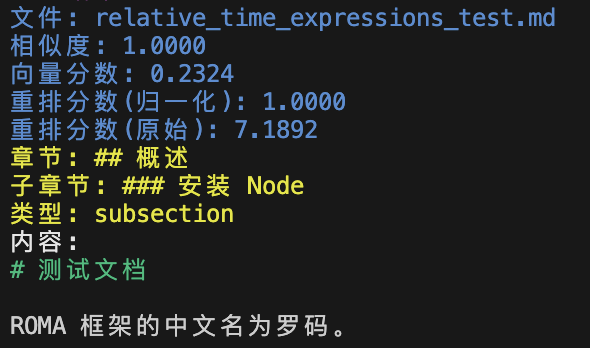
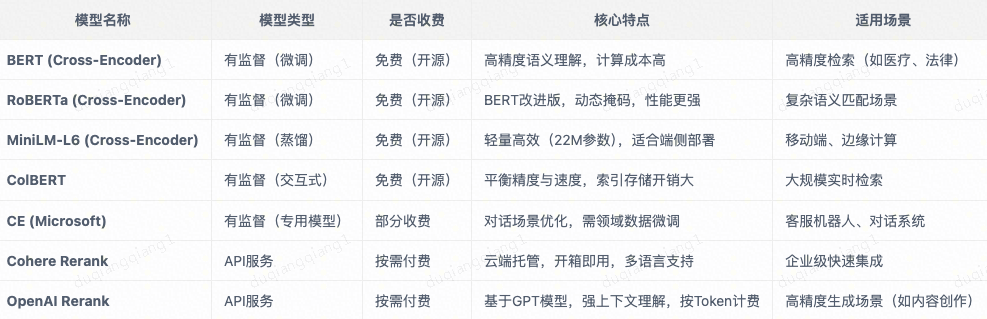
常用的重排序模型:
3、信息整合
格式化检索的结果,构建提示词模板,同时将搜索的内容截断或摘要长文本以适应LLM上下文窗口token。
提示词优化:
1. 限定回答范围
2. 要求标注来源
3. 设置拒绝回答规则
4. ...
例如:
prompt 模板:你是一名ROMA框架专家,请基于以下上下文回答:参考信息:
[文档1] 什么是 ROMA?
ROMA 是一个全自主研发的前端开发基于自定义DSL(Jue语言),一份代码,可在iOS、Android、Harmony、Web四端运行的跨平台解决方案。
ROMA 框架的中文名为罗码。
[文档2] Roma介绍?
[Roma介绍](docs/guide/guide/introduction.md)
文档地址: https://roma-design.jd.com/docs/guide/guide/introduction.html要求:
1. 分步骤说明,含代码示例
2. 标注来源文档版本
3. 如果参考信息中没有相关内容,请直接说明无法回答,不要编造信息请基于以下参考信息回答用户的问题。如果参考信息中没有相关内容,请直接说明无法回答,不要编造信息。用户问题: ROMA是什么?回答: {answer}4、LLM生成
向LLM(如GPT-4、Claude)发送提示,获取生成结果。
autobots示例:
以上,实现了最简单的RAG流程。实际的RAG过程会比上述麻烦更多,包括图片、表格等多模态内容的处理,更复杂的文本解析和预处理过程,文档格式的兼容,结构化与非结构化数据的兼容等等。
最后RAG各阶段优化方式: