每周读书与学习是由清华大学出版社出版的《JMeter核心技术、性能测试与性能分析》一书的作者推出,分享作者多年的IT从业经历,希望对很多计算机科学技术IT类专业毕业生以及IT从业者有所帮助。
1、前置处理器
在Jmeter中,前置处理器即预处理器,用于在实际取样器(Sampler)发出请求之前对即将发出的请求进行初始化的预处理,如下图所示。
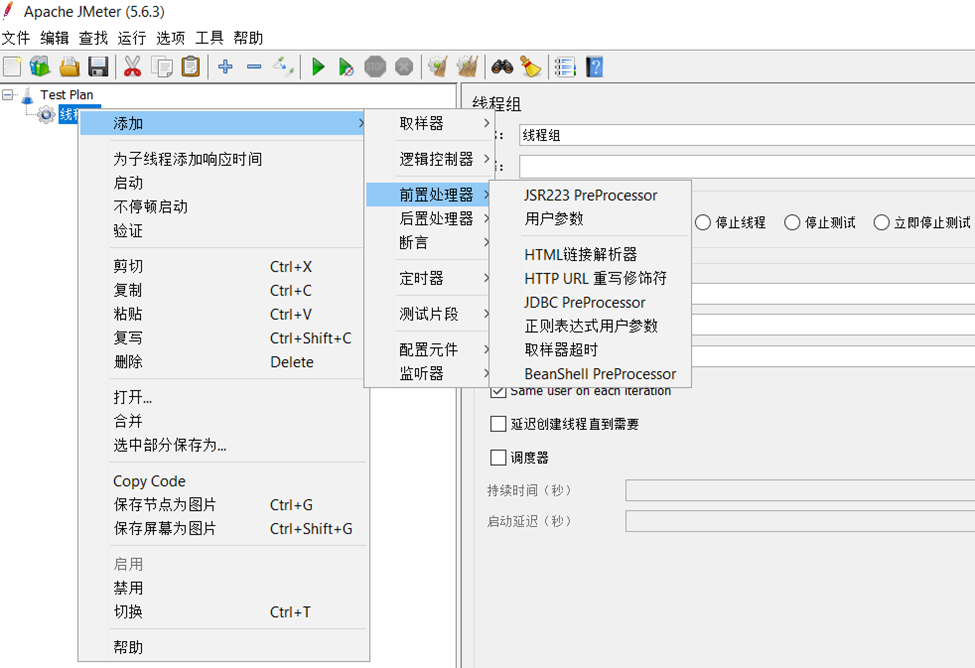
从图中可以看到前置处理器通常包括:
- JSR223 预处理程序:指的是使用JSR223规范(全称为Java Specification Request 223,是一个Java语言平台发布的规范,用于提供一种标准化的方式来嵌入脚本语言到Java应用程序中)实现的一种预处理程序,该预处理程序中可以使用多种脚本语言,如下所示:
- BeanShell:是使用Java语言实现的一个免费小型的支持嵌入的面向对象的脚本语言。
- Bsh:是BeanShell的简写,该脚本语言功能和BeanShell一致。
- EcmaScript:是由ECMA国际(全称为European Computer Manufacturers Association,即欧洲计算机制造商协会)通过ECMA-262标准设计的一种脚本语言,我们经常使用的JavaScript脚本语言就是对EcmaScript标准的一种扩展实现。
- Groovy:是一种运行在JVM(Java 虚拟机)上面向对象编程的脚本语言,Groovy既支持面向对象也支持作为一种纯粹的脚本语言来使用,在使用时,可以和Java语言之间互相引用和调用,由于Jmeter自身是通过Java语言实现的,所以很容易就能支持Groovy脚本语言的嵌入。
- Java:目前使用最广泛的一种面向对象的编程语言,Jmeter 自身就是通过Java语言实现的,所以预处理程序肯定会支持Java语言的编写。
- JavaScript:是目前使用最广泛的一种动态解析和执行的脚本语言,通常广泛的应用于前端网页的开发中,是Web开发的核心语言。
- Jexl:是Java Expression Language的简写,是一种表达型的语言。
- Jexl2:是Jexl语言的2.0版本。
- 用户参数:用户参数是一个对每个线程做预处理的动态赋值以便在性能测试时使用这些值,在Jmeter中,每个线程其实就是一个并发用户。
- HTML链接解析器:指的是自动处理 HTML 响应,解析出其中所有的HTML链接和表单, 以便在下一个HTTP取样器中使用,通常当在一个性能测试中同时存在同个HTTP取样器时会被使用到,如下图所示。

- HTTP URL 重写修饰符:和HTML链接解析器类似,但是其支持对HTTP URL进行重写以便存储会话ID来替代存储Cookies,通常可以在线程组中添加这个元件,只需要在此元件上指定会话id参数的名称,该元件就可以在页面中自动找到该参数,并且将该参数添加到每个取样器的请求中,该元件包含的其他功能如下:
- 路径扩展:通过添加分号和会话id参数来重写URL。
- Do not use equals in path extension:表示在参数名称和值之间不使用“=”符号的情况下需要重写URL。
- Do not use questionmark in path extension:表示不让查询字符串最终出现在路径扩展中。
- 缓存会话Id:表示当会话Id不存在时,是否应该保存会话Id的值以供后续测试使用。
- URL Encode:写入参数是否进行URL编码处理。
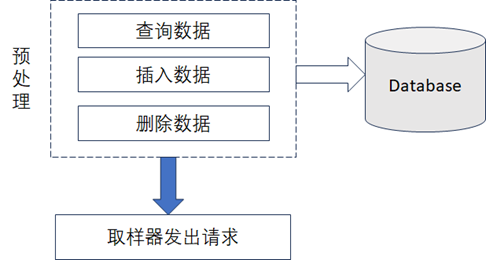
- JDBC 预处理程序:JDBC预处理程序指的是在取样器发出请求之前,可以通过JDBC的方式来运行一些SQL语句,这些SQL语句可以直接操作数据库,比如使用取样器发出请求之前,需要先查询数据库来获取请求的参数或者是取样器发出请求之前需要先向数据库中构造一些初始数据或者删除一些已经存在的数据等,如下图所示。
- 正则表达式用户参数:指的是使用正则表达式的方式从上一个HTTP取样器请求的响应结果中提取HTTP参数指定的动态值以用于下一个HTTP取样器作为请求参数使用,正则表达式用户参数只特定于单个线程中传递使用,如下图所示。

正则表达式用户参数主要包容如下功能:
-
- Regular Expression Reference Name:表示正则表达式引用的名称。
- Parameter names regexp group number:表示用于提取参数名称的正则表达式的组号。
- Parameter values regex group number:用于提取参数值的正则表达式的组号。
如下图所示,展示的是一个从上一个HTTP取样器请求的响应结果中提取数据来作为下一个HTTP取样器请求的参数的过程,在图中可以看到:
-
- 当需要从上一个HTTP取样器的响应结果中提取数据时,需要先为上一个HTTP取样器创建一个后置处理器,后置处理器类型选择为正则表达式提取器,关于后置处理器,我们将会在接下来的内容详细讲解,后置处理器通常是在取样器之后才会运行。
- 为下一个HTTP取样器创建一个前置的正则表达式用户参数元件,该元件用于接收上面正则表达式提取的结果数据,并且按照规则提取参数名称和参数值。
- 下一个HTTP取样器使用提取的参数名称和参数值来发出下一个HTTP取样器的请求。
![]()
- 取样器超时:用于设置取样器的超时时长,单位为毫秒,当取样器超时此时长时会中断取样器的执行,当设置为0或者负数时,表示设置的时长为无限大,永远不会超时。
- BeanShell 预处理程序:使用BeanShell脚本语言来编写取样器的预处理程序,界面上主要包含如下功能: 每次调用前重置bsh.Interpreter重置解释器:如果设置这个选项为True代表每次调用前都会重新创建解释器,默认为False,通常不需要进行修改。
- 传递给BeanShell的参数:用于设置传递给BeanShell脚本的参数,可以以单个字符串的形式传递参数也可以以字符串数组的形式传递参数。
- 脚本文件名:设置要运行的BeanShell脚本的文件路径以及名称,通常如果是使用外部的脚本文件时,可以使用这个设置。
- Script:直接在Jmeter界面中编写脚本。

2、定时器
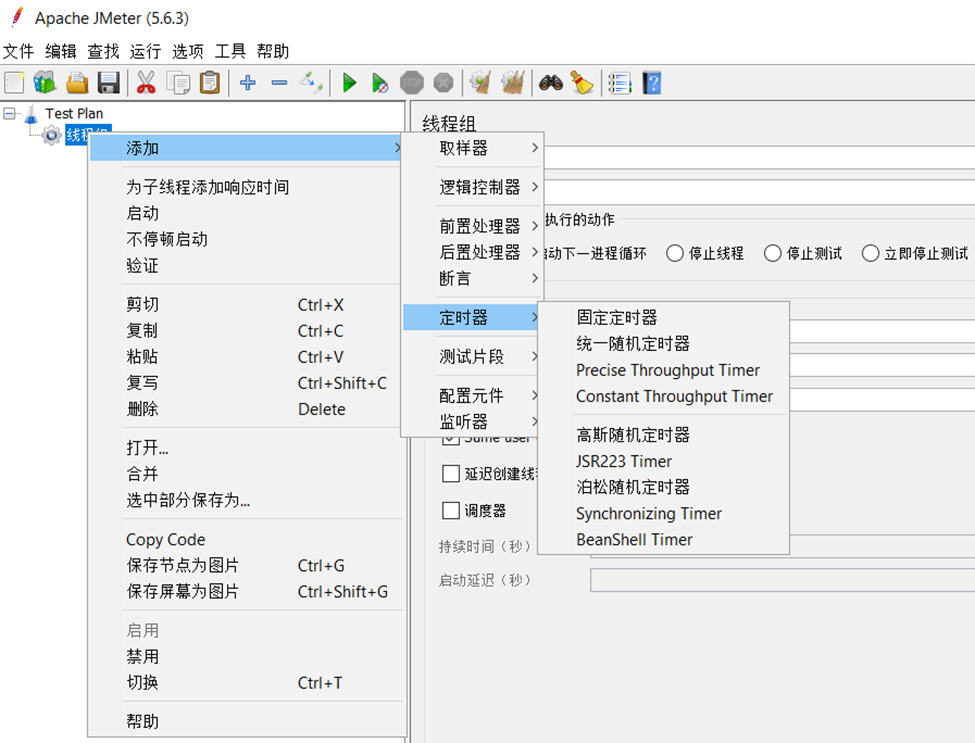
在Jmeter中,定时器类似于LoadRunner中的思考时间(think time),用来设置线程的延迟和同步时间,如下图所示,通常是在每个取样器发出请求之前执行,定时器主要是有时候为了让一个线程(并发用户)的操作更加符合真实的人工使用场景,比如人在点击某个系统中的某个界面按钮或者打开某个页面时,都会存在思考时间或者操作的延迟时间。
从图中可以看到,定时器主要包括:
- 固定定时器:用于设置每个线程在发起取样器请求之前等待相同的一段时长,此时长的单位为毫秒。
- 统一随机定时器:用于设置每个线程在发起取样器请求之前随机等待一段时长,时长的单位为毫秒。
- Constant Throughput Timer:又叫常数吞吐量定时器,顾名思义就是根据设置的吞吐量的值来控制线程的运行延迟。可以通过设置每分钟的吞吐量来控制线程的延迟,比如设置1分钟内的吞吐量为30,那么如果在1分钟内已经达到30的吞吐量后,线程就会暂停发起取样器请求,直到下一分钟开始,线程才会继续发送请求。计算吞吐量的方式包括只有此线程、所有活动线程、当前线程组中的所有活动线程、所有活动线程(共享)、当前线程组中的所有活动线程(共享)。
- Precise Throughput Timer:又叫准确的吞吐量定时器,和Constant Throughput Timer有点类似,可以准确的根据设置的每个吞吐量周期下的目标吞吐量来控制线程发起取样器请求的延迟时长,该定时器主要包含如下参数:
- 目标吞吐量(每个“吞吐期”的样本):设置每个“吞吐量周期”要从所有受影响的采样器请求中获取的最大吞吐量,该设置会包括线程组中的所有线程的吞吐量之和。
- 吞吐量周期(秒):设置统计吞吐量的周期时长,单位为秒。
- 测试持续时间(秒):用于设置本次吞吐量定时器运行的持续时长,单位为秒。
- 批处理离开-批处理中的线程数(线程):用于设置批处理中的线程数量。
- 批处理离开-批处理中的线程之间的延迟(ms):用于设置批处理中线程之间的延迟时长,单位为毫秒。
- 随机种子(从0变为随机):设置随机数生成的种子值,默认为0,表示完全随机。
- 高斯随机定时器:用于设置每个线程在发起取样器请求之前随机等待一段时长,可以指定该时长的偏差范围,由于该定时器的偏差变化符合高斯曲线分布,所以命名为高斯随机定时器。
- JSR223 Timer:指的是使用JSR223(全称为Java Specification Request 223,是一个Java语言平台发布的规范)脚本语言来生成线程延迟,在JSR223 Timer中支持的脚本语言包括groovy、java、javascript、jexl等,和JSR223 预处理程序类似,JSR223 Timer同时也支持将参数传递给脚本作为参数来使用。
- 泊松随机定时器:和统一随机定时器很类似,同样也是用于设置每个线程在发起取样器请求之前随机等待一段时长,时长的单位为毫秒,和统一随机定时器不同的是,泊松随机定时器的延迟时长通常都发生在一个特定值的附近,彼此相差不会很大并且符合泊松分布,所以又叫泊松随机定时器。
- Synchronizing Timer:又叫同步定时器,是一种阻塞型的定时器,其目的主要用于设置每次阻塞到指定的线程数量后再一次释放所有的阻塞的线程去同时发起取样器请求,有点类似LoadRunner中的集合点(或者又叫同步点)。相当于是让指定的数量的线程同时达到了可执行状态后,再同时去发起取样器请求,如下图所示。

Synchronizing Timer主要包含如下两个参数配置:
-
- 模拟用户组的数量:用于设置每次让多少个线程进行阻塞以达到统一执行的状态。
- 超时时间以毫秒为单位:用于设置等待的时长以让所有的线程达到可执行的状态,如果超过这个时长后,指定的所有线程还没有达到可执行的状态,那么将不再继续等待,会直接向下执行。
- BeanShell Timer:即BeanShell定时器,指的是使用自定义的BeanShell 脚本语言来生成线程延迟,和JSR223 Timer很类似,同时也支持将参数传递给脚本作为参数来使用。
3、本次学习总结
- 前置处理器的使用,包括JSR223 预处理程序、用户参数、HTML链接解析器、HTTP URL 重写修饰符、JDBC 预处理程序、正则表达式用户参数、取样器超时、BeanShell 预处理程序等,其中HTTP URL 重写修饰符、JDBC 预处理程序、正则表达式用户参数这三个前置处理器元件建议读者们进行重点掌握。
- 定时器的使用,包括固定定时器、统一随机定时器、Constant Throughput Timer、Precise Throughput Timer、高斯随机定时器、JSR223 Timer、泊松随机定时器、Synchronizing Timer、BeanShell Timer等,定时器通常适用于一些特殊的性能测试场景,用于模拟出更加真实的用户需求,其中固定定时器、统一随机定时器、高斯随机定时器、Synchronizing Timer这几个定时器元件建议读者们进行重点掌握。
出处:本次学习的内容参考自清华大学出版社出版的《JMeter核心技术、性能测试与性能分析》一书