在充满不确定性的现实世界里,AI的价值不在于预设规则,而在于持续学习和适应
AI Agent这个概念最近被炒得很热,从管理日程的语音助手到仓库里跑来跑去的机器人,大家都在谈论Agent的"自主性"。但是真正让Agent变得intelligent的核心技术,其实是强化学习(Reinforcement Learning, RL)。
想象一下自动驾驶汽车在复杂路况中的决策,或者量化交易系统在市场波动时的操作——这些场景的共同点是什么?环境动态变化,规则无法穷尽。传统的if-else逻辑在这里完全失效,而RL恰好擅长处理这类问题。它让Agent像人一样,从试错中学习,在探索(exploration)和利用(exploitation)之间找平衡。
本文会从RL的数学基础讲起,然后深入到知识图谱的多跳推理,最后在LangGraph框架里搭建一个RL驱动的智能系统。
RL的底层逻辑:马尔可夫决策过程
教机器人玩游戏的过程其实很像教小孩骑自行车——没人会给它写一本"如何骑车的完整手册",而是让它自己试,摔了就爬起来再试,在练习的同时我们给予帮助,如果做对就鼓励,做错了给个提示应该怎么做,这样慢慢他就学会了,而RL的数学框架就是根据这个流程设计的。
RL的核心是Markov Decision Process(MDP),它把决策过程拆成几个要素:状态(State)、动作(Action)、转移概率(Transition)、奖励(Reward)和折扣因子(Discount Factor)。形式化表示是个五元组 (S, A, P, R, γ)。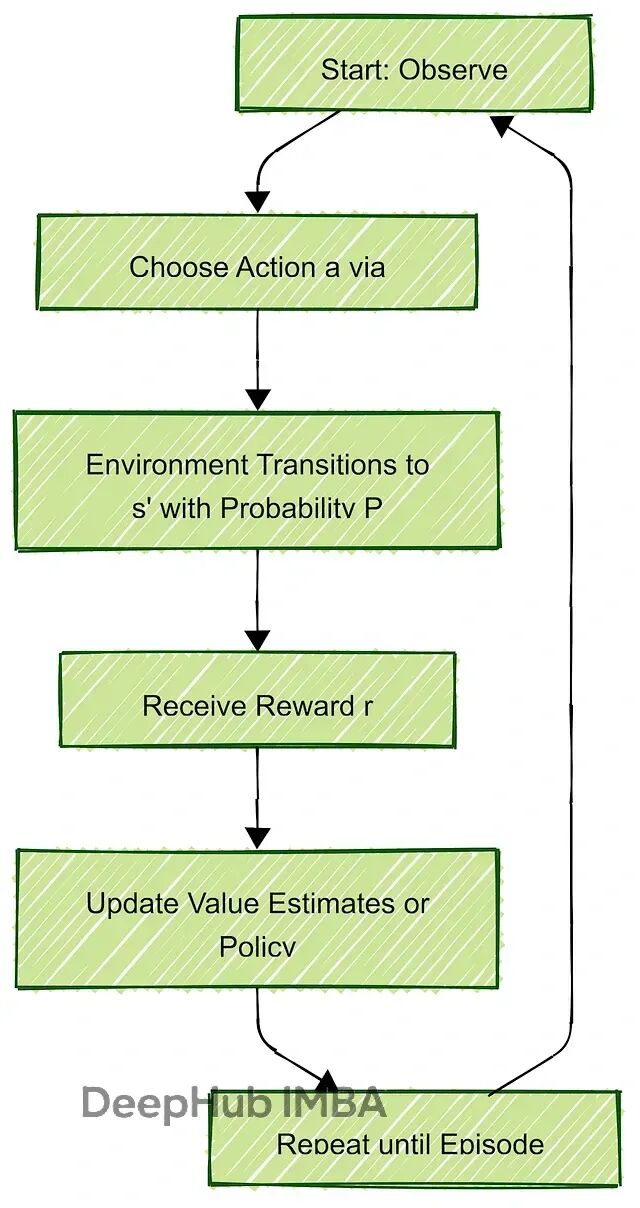
State(状态集合 S)就是"现在是什么情况"。比如对于一个走迷宫的机器人,状态可能就是它在网格上的坐标(3,5);而对于自动驾驶系统,状态会复杂得多——车速、位置、周围障碍物、天气情况等等都得考虑进去。状态可以是离散的(grid position),也可以是连续的(speed from 0 to 100 mph)。
https://avoid.overfit.cn/post/7f95145bedf4402daa3704ed1dca21d8