关系型数据库的基本理论
数据库核心概念
数据库(DB)
数据库是按数据结构存储和管理数据的计算机软件系统,核心作用包括:
- 存储大量数据,提供便捷的检索与访问能力。
- 维护数据的一致性与完整性,避免数据冲突或错误。
- 支持多用户数据共享,同时保障数据安全(如权限控制)。
- 通过多维度数据组合分析,生成新的有价值信息(如报表统计)。
数据库管理系统(DBMS)
数据库管理系统是专门用于管理数据库的系统软件,是用户与数据库之间的交互桥梁,核心功能如下:
- 提供数据定义、建立、维护、查询和统计等操作能力。
- 控制数据完整性(如字段约束)与安全性(如访问权限)。
- 在关系型数据库中,将二维表数据以“数据文件”形式存储于磁盘,用户通过DBMS与数据文件交互。
- 建立在操作系统之上,统一管理和处理所有数据库访问请求。
数据库应用系统(Database Application System)
使用数据库技术构建的信息系统,几乎所有信息系统都属于此类,通常由三部分组成:
- 软件:包括应用程序(如客户端界面)、DBMS等。
- 数据库:存储业务相关的结构化数据。
- 数据管理员:负责系统运维与数据管理的专业人员。
数据库管理员(DBA)
负责数据库全生命周期管理的专业角色,核心职责包括:
- 创建数据库,设计数据结构与存储方案。
- 监控数据库运行状态,优化性能(如索引调整)。
- 维护数据安全与备份,处理故障恢复。
- 确保数据可被有权限的用户高效使用,通常由业务水平高、资历深的人员担任。
数据库管理系统的功能结构
数据定义功能
- 提供数据定义语言(DDL) 及建库机制,用户可通过DDL语句(如
CREATE DATABASE、CREATE TABLE)快速建立数据库与表结构。 - 支持修改数据结构(如
ALTER TABLE),灵活适配业务需求变化。
数据操纵功能
- 实现数据的插入、修改、删除、查询、统计等存取操作,是数据库的基础功能。
- 通过数据操纵语言(DML) 实现,常用语句包括
INSERT(插入)、UPDATE(修改)、DELETE(删除)、SELECT(查询)。
数据库的建立和维护功能
- 数据层面:支持数据载入(初始化数据)、转储(备份)、重组织(优化存储)及恢复(故障后数据还原)。
- 结构层面:允许修改、变更及扩充数据库结构(如新增字段、调整表关联)。
数据库的运行管理功能
- 并发控制:防止多用户同时操作数据导致的冲突(如脏读、幻读)。
- 存取控制:基于用户权限管理数据访问范围(如只读、读写权限)。
- 完整性检查:执行数据完整性约束(如主键唯一、字段非空),确保数据合法。
- 内部维护:自动完成日志记录、空间回收等后台运维操作。
数据库系统的分类
数据模型是数据库系统的核心与基础,由数据结构、数据操作、完整性约束三部分组成。传统数据库系统按数据模型分为三类,同时包含非关系型数据库等扩展类型:
网状型数据库
- 基于网状模型设计,是最早出现的网状DBMS。
- 代表产品:1964年美国通用电气公司开发的ID(Integrated Data Store),是世界上第一个DBMS。
层次型数据库
- 基于树状层次模型设计,数据间呈父子级关联关系。
- 代表产品:IBM公司的IMS(Information Management System),自20世纪60年代末诞生以来已发展至IMSV6版本,目前仍在WWW应用连接、商务智能场景中使用;其他产品还包括DB2、Informix。
关系型数据库
- 建立在关系模型上,核心是满足特定条件的二维表,数据库由二维表及表间联系组成。
- 二维表核心概念:
- 元组:表中的一行,对应一个实体(如一条学生记录),相当于传统的“记录”。
- 域:表中的一列,对应实体的一个属性(如学生的“学号”“姓名”),相当于传统的“数据项”,也叫“列”或“字段”。
- n元关系:若表包含n个域(列),则每行称为“n元组”,该关系称为“n度(元)关系”。
- 数据存储:表的行列交点存储简单值,满足规范化条件的关系集合构成关系模型。
其他类型
- 非关系型数据库(NoSQL):不依赖传统关系模型,适用于非结构化/半结构化数据存储(如文档、键值对),代表产品有MongoDB、Redis。
- 对象数据库(ODBMS):将数据以对象形式存储,适配面向对象编程场景。
关系型数据库的组成(二维表规范)
一个关系表需满足以下6个条件,才能成为关系模型的有效组成部分:
- 原子性:每个单元(行列交点)仅存储一条原子数据,不可再分(即“信息原则”)。
- 数据类型一致性:同一列(域)的所有数据必须属于相同数据类型(如“年龄”列全为整数)。
- 行唯一性:表中每行(元组)均唯一,无完全重复的记录。
- 列无顺序:列的排列顺序不影响数据逻辑,可根据需求调整。
- 行无顺序:行的排列顺序不影响数据逻辑,查询时可通过排序语句指定顺序。
- 列名唯一性:每列需有唯一的名称(字段名),避免混淆。
关系型数据库的E-R模型
E-R模型(实体-关系模型)是关系型数据库的核心逻辑设计工具,通过图形化方式将现实世界的“实体”与“实体间联系”转化为逻辑模型,为数据库表结构设计提供依据。
E-R模型的核心组成
E-R模型主要由实体(方形)、属性(椭圆)、联系(菱形) 三部分构成,三者通过连接线关联,具体定义如下:
实体和属性
-
实体
- 定义:客观存在且可相互区分的事物,如“教师”“学生”“雇员”。
- 实体集:具有相同属性的实体集合(如“学生实体集”包含所有学生);实体是实体集中的单个实例(如“王大锤”是“学生实体集”的一个实例)。
-
属性
- 定义:描述实体特征的信息,如学生的“学号”“姓名”“性别”“班级”。
- 主键属性:可唯一标识实体的属性(如“学号”可唯一区分每个学生),是后续表结构设计中“主键”的来源。
联系
实体间的关联关系需在E-R模型中明确表示,用“菱形”符号标注联系名,通过连接线关联相关实体,并标注联系类型。两个实体间的联系分为三类:
| 联系类型 | 定义 | 标记 | 示例 |
|---|---|---|---|
| 一对一 | 实体集A中的每个实体,在实体集B中最多有一个实体与之关联;反之亦然 | 1:1 | “学生”与“学生证”(一个学生对应一个学生证,一个学生证对应一个学生) |
| 一对多 | 实体集A中的每个实体,在实体集B中有多个实体与之关联;实体集B中的每个实体,在实体集A中最多有一个实体与之关联 | 1:n | “班级”与“学生”(一个班级包含多个学生,一个学生仅属于一个班级) |
| 多对多 | 实体集A中的每个实体,在实体集B中有多个实体与之关联;反之,实体集B中的每个实体,在实体集A中也有多个实体与之关联 | m:n | “学生”与“课程”(一个学生可选多门课程,一门课程可被多个学生选择) |
实例
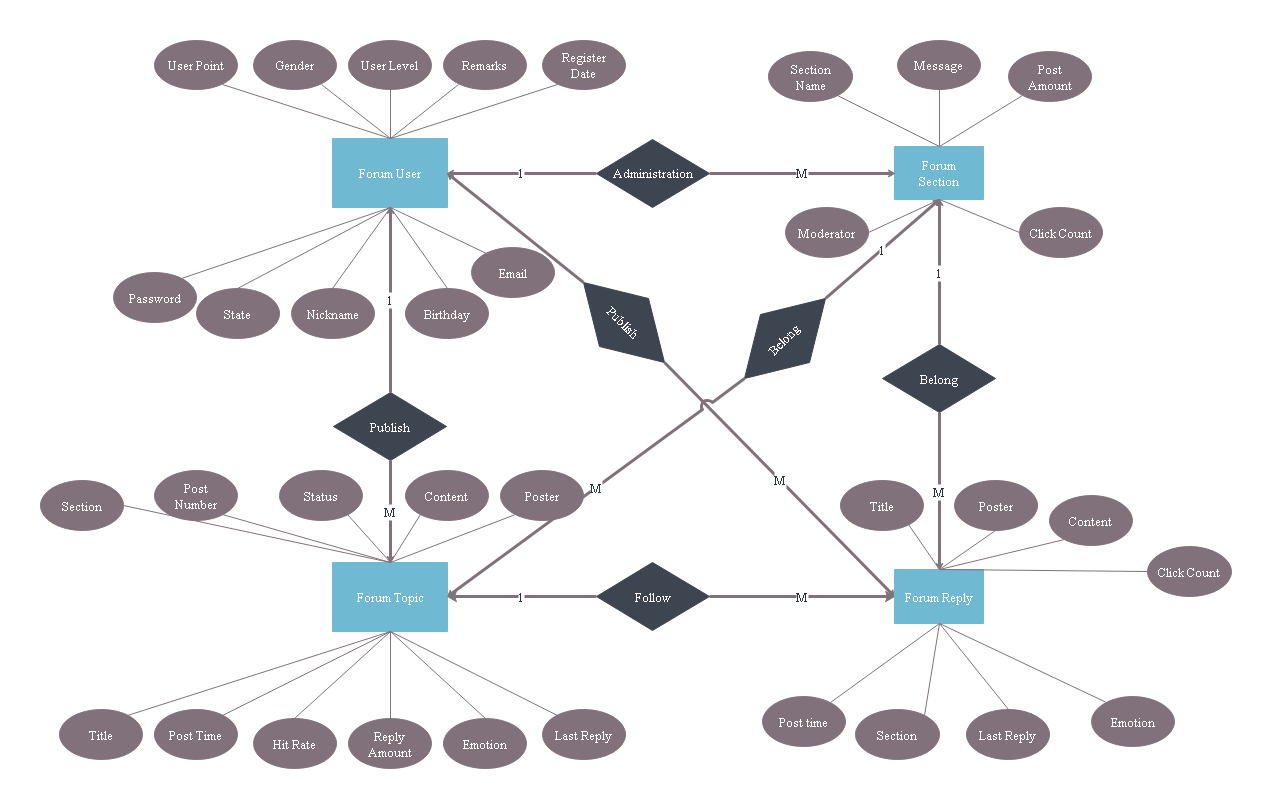
关系型数据库的设计范式
设计关系型数据库时,需通过“规范化”过程优化表结构,目标是最小化数据冗余的同时保持数据完整性,避免出现更新异常、插入异常、删除异常。规范化需遵循“范式法则”,从低到高分为1NF、2NF、3NF、4NF、5NF、6NF、BCNF等,关系型数据库需满足1NF,通常优化至3NF即可满足大部分业务需求。
第一范式(1NF):属性不可再分
核心要求
满足1NF的表,其所有属性(列)必须是“原子性”的,即字段不可再拆分为更小的子字段。
示例对比
| 未满足1NF的表(“代课时间”可拆分) | 满足1NF的表(“代课时间”拆分为“开始时间”“结束时间”) |
|---|---|
| 讲师 | 性别 |
| 李老师 | Male |
| 李老师 | Male |
| 陈老师 | male |
说明
未满足1NF的表中,“代课时间”字段包含“开始”和“结束”两个子信息,查询时需拆分处理(如提取开始时间),易出错;拆分后每个字段仅存储单一信息,符合原子性要求。
第二范式(2NF):消除部分函数依赖
核心要求
- 首先满足1NF。
- 表中的每条记录需被唯一区分,通常通过“主键”(单一字段或复合字段)实现。
- 所有非主属性需“完全依赖”于主键,而非“部分依赖”(即非主属性不能仅依赖主键的某一部分)。
示例分析(员工工资信息表)
未满足2NF的设计
- 复合主键:(员工编码,岗位)
- 字段依赖关系:(员工编码,岗位)→(姓名、年龄、学历、基本工资、绩效工资、奖金)
- 问题:存在“部分依赖”:
- (员工编码)→(姓名、年龄、学历):非主属性“姓名”“年龄”“学历”仅依赖主键中的“员工编码”,与“岗位”无关。
- (岗位)→(基本工资):非主属性“基本工资”仅依赖主键中的“岗位”,与“员工编码”无关。
满足2NF的优化方案
拆分表结构,消除部分依赖:
- 表1:员工基本信息表(主键:员工编码)
- 字段:员工编码、姓名、年龄、学历、绩效工资、奖金
- 表2:岗位工资表(主键:岗位)
- 字段:岗位、基本工资
- 表3:员工岗位关联表(主键:员工编码)
- 字段:员工编码、岗位(关联表2的“岗位”)
第三范式(3NF):消除传递函数依赖
核心要求
- 首先满足2NF。
- 消除“传递依赖”:所有非主属性不依赖于其他非主属性(即非主属性仅依赖于主键,不通过中间属性间接依赖主键)。
示例分析(员工信息表)
未满足3NF的设计
- 主键:员工编号
- 字段依赖关系:(员工编号)→(员工姓名、年龄、部门编码、部门经理)
- 问题:存在“传递依赖”:
- (员工编号)→(部门编码)→(部门经理):非主属性“部门经理”依赖于“部门编码”,而“部门编码”又依赖于主键“员工编号”,属于间接依赖。
满足3NF的优化方案
拆分表结构,消除传递依赖:
- 表1:员工基本信息表(主键:员工编号)
- 字段:员工编号、员工姓名、年龄、部门编码(关联表2的“部门编码”)
- 表2:部门信息表(主键:部门编码)
- 字段:部门编码、部门经理
范式设计的目标
关系型数据库设计的理想目标是遵循规范化原则,最终实现:
- 消除数据冗余:避免同一信息在多个表中重复存储(如“部门经理”仅在部门表中存储一次)。
- 避免更新异常:修改数据时仅需更新一处,防止多表同步更新遗漏(如修改“部门经理”仅需更新部门表)。
- 避免插入异常:无需依赖其他表的非必要数据即可插入记录(如新增员工时,无需提前填写“部门经理”)。
- 避免删除异常:删除某条记录时,不影响其他无关数据(如删除员工记录,不会删除部门信息)。