深入解析:数字和字节:Linux 中的内存如何工作?
大家好!我是大聪明-PLUS!
❯ 第一部分:物理内存
在创建操作系统时,始终要关注内存的使用。内存是计算机中存储程序和数据的组件,没有它,现代计算机就无法运行。内存中数据存储的关键单位是位,它可以取两个值:0 或 1。内存由单元组成,每个单元都有自己的地址。单元可以包含不同数量的位,可寻址单元的数量取决于地址中的位数。
内存还包括随机存取存储器 (RAM),可用于读写信息。静态 RAM (SRAM) 和动态 RAM (DRAM) 的区别在于信息的存储方式。SRAM 可以保留信息直到电源关闭,而 DRAM 使用晶体管和电容器,允许存储数据,但需要定期刷新。不同类型的 RAM 各有优缺点,具体选择取决于具体需求。
了解计算机内存的工作原理对于任何从事硬件和软件工作的人来说都至关重要。了解内存的工作原理、内存的类型以及这些类型如何影响计算机的性能和功能至关重要。
但是,什么是物理内存?它在 Linux 中是如何工作的?什么是分段、内存泄漏和“页面”?
所有你想了解但又不敢问的企鹅内存知识,都可以在这里找到!
❯ 内存在操作系统中起什么作用?
内存是任何操作系统的基础。开发操作系统时,内存至关重要。即使是简单的系统启动,BIOS 也会读取引导加载程序内存的前 512 个字节,如果它们包含一个魔数,系统就会启动。
内存是存储程序和数据的计算机组件。没有内存,现代计算机就不存在了。
内存中数据存储的基本单位是二进制数字,称为位 (bit)。有些计算机被认为同时使用十进制和二进制运算,但事实并非如此。它们使用二进制编码的十进制 (BCD) 码。四位用于存储一位十进制数字。这四位提供 16 种组合,用于存储 10 个不同的值(从 0 到 9)。其余六个值未使用。在 BCD 码中,16 位足以存储从 0 到 9999 的数字,这意味着有 10,000 种组合可用。而如果使用相同的设备存储二进制数,则它们只能包含 16 种组合。
内存地址
内存由多个部分(即单元)组成。每个部分都可以存储一条信息。每个单元都有一个编号,称为地址。程序可以通过地址引用特定的单元。如果内存包含 N 个单元,则它们的地址从 0 到 N-1。所有内存单元都包含相同数量的位数。如果一个单元由 k 位组成,则可以包含 2^k 种组合中的任意一种。
在使用二进制数字系统(包括八进制和十六进制表示)的计算机中,令人惊讶的是,内存地址也以二进制数表示。如果一个地址由 m 位组成,则可寻址单元的最大数量为 2^m。地址中的位数决定了可寻址内存单元的最大数量,而与单元中的位数无关。
单元是内存的最小可寻址单位。近年来,几乎所有制造商都生产带有 8 位单元的计算机,这些单元称为字节(有时称为八位字节)。字节被分组为字。在 32 位计算机中,每个字有 4 个字节,而在 64 位计算机中,每个字有 8 个字节。因此,32 位计算机包含 32 位寄存器和用于操作 32 位字的指令,而 64 位计算机则包含 64 位寄存器和用于操作相应字的指令。
字中的字节可以从左到右编号,反之亦然。从最高位开始编号指的是大端字节序。反之则为小端字节序。
有趣的是:这些术语出自乔纳森·斯威夫特的《格列佛游记》——他当时在讽刺国王们争论该用哪一端打破鸡蛋。这些术语最初是在科恩1981年的文章中引入的。
重要的是要理解,在两个系统中,一个 32 位整数(例如 6)都由110字的最右三位表示,其余 29 位为零。如果字节从左到右编号,则这些位位于110字节 0(或 4、8、16 等)。在两个系统中,包含该整数的字的地址均为 0。
RAM 和 ROM
既能读写信息的存储器称为 RAM(随机存取存储器)。RAM 有两种类型:静态 RAM 和动态 RAM。静态 RAM (SRAM) 由 D 型触发器构成。只要有电源,RAM 中的信息就会保留。它运行速度非常快,可用作二级缓存。
而动态 RAM (DRAM) 则不使用触发器。DRAM 是一个单元阵列,每个单元包含一个晶体管和一个小电容器。电容器可以充电和放电,从而可以存储 0 和 1。由于电荷可能会消失,DRAM 中的每一位每隔几毫秒就会刷新一次;否则,存储器就会泄漏。由于外部逻辑必须处理刷新,DRAM 需要比 SRAM 更复杂的接口。然而,这一缺点被其更大的容量所抵消。DRAM
有几种类型。仍在使用的最古老的类型是 FPM(快速页面模式)。这种 RAM 是一个位矩阵。硬件表示行地址,然后是列地址。
FPM 正逐渐被 EDO(扩展输出存储器)取代,EDO 允许在前一次访问完成之前访问内存。这种流水线模式虽然不会加速内存访问,但却提高了吞吐量,允许每秒传输更多字数。
在内存芯片运行时间不超过 12 纳秒的时代,FPM 和 EDO 内存仍然具有重要意义。随后,对更快内存芯片的需求出现,异步内存模式被 SDRAM(同步动态 RAM)取代。同步动态 RAM 由主系统时钟发生器控制。该设备是静态和动态 RAM 的混合体。SDRAM 的主要优势在于它消除了内存芯片对控制信号的依赖。消除这个问题加快了处理器和内存之间的通信速度。
下一步的发展是 DDR(双倍数据速率)。这项技术可以在脉冲的上升沿和下降沿输出数据。
但 RAM 并非唯一的内存芯片类型。在许多情况下,即使断电,数据也必须保留,这就是 ROM(只读存储器)的作用所在。ROM 不允许修改或擦除数据;它是在制造过程中写入的。
❯ 内存管理
内存管理是 Linux 操作系统的一个重要子系统,用于确保高效利用物理和虚拟内存资源。在 Linux 中,内存管理主要涉及处理来自进程的内存请求、分配和释放内存块,以及确保其高效使用。Linux
中内存管理的关键概念包括:
- 虚拟内存——Linux 使用虚拟内存的概念,这会产生一种错觉,让每个进程都拥有自己的私有内存空间。虚拟内存允许系统使用比物理可用内存更多的内存来执行应用程序代码。这是通过将未使用的应用程序内存块刷新到磁盘来实现的。
- 分页系统:物理内存和虚拟内存被划分为固定大小的块,称为页面。分页系统可以实现高效的内存管理,并支持 RAM 和磁盘(交换)之间的数据交换。
- 内存分配:进程执行命令时需要内存。相应的内存管理器负责为进程分配合适的内存块。内存从可用的物理内存中分配。如有必要,会通过将非活动页面刷新到磁盘来释放物理内存。
- 内核空间和用户空间——Linux 中的内存分为内核空间和用户空间。内核空间保留用于执行内核代码、内核扩展和大多数设备驱动程序。用户空间是所有用户应用程序访问的内存区域。
- 缓存——Linux 使用多种缓存机制来提高系统性能。例如,页面缓存用于缓存从磁盘读取的文件,缓冲区缓存用于管理磁盘写入操作。
- 内存过量使用:Linux 允许进程分配超过实际可用内存的内存。这个概念称为内存过量使用。它允许更多进程同时运行,前提是它们不会耗尽所有分配的内存。默认情况下,vm.overcommit_ratio 为 50,这意味着进程不能消耗(或实际物理消耗)超过 50% 的内存。
在程序之间分配资源的任务落到了我们操作系统(在本例中为 Linux)的内核身上。为了营造完全独立的假象,内核为每个程序提供了各自的虚拟地址空间和一个与之协作的低级接口。这样一来,每个程序就无需了解彼此、内存大小以及其他不必要的步骤。进程虚拟空间中的地址称为逻辑地址。
为了跟踪物理内存和虚拟内存之间的映射,Linux 内核在其物理内存服务区(内核唯一直接访问的区域)中使用了一组分层的数据结构,以及称为 MMU 的专用硬件电路。Linux
实现了分页内存,因为单独跟踪每个字节过于复杂繁琐。内核以 4 KB 大小的内存块(即页面)为单位进行操作。
但内核使用页面并非因为跟踪每个字节很困难,而是因为内存管理单元 (MMU) 最终使用页面(而不是单个字节)将虚拟地址映射到实际地址。顺便说一句,页面大小不一定非得是 4 KB——它至少取决于硬件的性能。
然而,在硬件层面,通常支持以 RAM“段”形式存在的额外抽象级别,可用于将程序划分为多个部分。与其他操作系统不同,Linux 很少使用这种技术——逻辑地址始终与线性地址(段内的地址)匹配。
然而,有两点需要注意:
首先,分段是 IA-32(又名 x86)架构的一个显著特性,在 16 位和 32 位模式下可用,但在 64 位模式下被移除。由于向后兼容,其他架构的遗留问题较少。
其次,自 80386 出现以来,分段几乎从未被使用过。具体来说,它从未在 32 位版本的 Windows 中使用过。
正如您所知,虚拟内存是存在的——它是操作系统为程序创建的,包括 RAM(我们上面讨论过)和所有交换分区。分配给进程的内存可以是常驻内存,也可以是虚拟内存。下面,我运行了命令ps,它允许您分析正在运行的进程。列表显示进程具有常驻内存 (rss) 和虚拟内存 (vsz)。这些内存以 KB 为单位显示。
$ ps -C gnome-shell -o pid,user,rss,vsz,commPID USER RSS VSZ COMMAND941 alexeev 147252 4197004 gnome-shell
例如,我使用的是 Gnome Shell v46.0。gnome-shell 占用的常驻内存约为 147 MB。而虚拟内存已经约为 4197 MB。真是个大问题!
- 虚拟内存 (VSZ) 是已分配给进程的内存,但事实上进程并未设法向该内存写入任何内容。
- 驻留内存 (RSS) 是指进程已分配的内存,这意味着它已将一些内存保存到虚拟内存中。驻留内存用于衡量进程消耗的物理内存量。
应用程序可能会请求大量内存,但只使用其中的一小部分。因此,RSS 几乎总是比 VZZ 小。
交换分区 (SWAP) 是硬盘上的一个分区,用于存储:
- 常驻内存中很少使用的数据;
- 当物理内存不足时,任何数据。
如果 rss 中的任何数据被刷新到交换分区,rss 会被释放,但 vsz 不会被释放。这意味着进程存储在交换分区中的数据包含在该进程的虚拟内存中。Linux
不仅可以使用交换分区,还可以使用交换文件。这意味着常驻内存中的数据可以刷新到硬盘驱动器上的特殊文件中。
交换文件和交换分区的格式与 RAM 相同。这意味着 RAM 中的数据以页面形式存储,并以相同的页面形式刷新到交换分区。/proc//status
文件可用于更详细地查看进程的内存使用情况。
页面管理系统
簇(或页)是文件系统级别上可访问的块。读写操作以块为单位进行。正如我之前提到的,默认大小为 4KB。
所有虚拟内存都由这些簇组成。但这些页面不限于 4KB;还有一种“大页面”——大小为 2MB 或 1GB 的块。这用于处理大型数据集,例如数据库(页表结构也会变得更加优化)。
页面分为脏页和干净页。干净页未被修改,而脏页已被修改。例如,如果您加载一个库,它就是一个干净页;它未被修改。但是,如果您加载一个文件,并且该文件随后被修改,那么它就已经是脏页了。需要保存它,否则写入的信息将被擦除。
页面缓存(Page Cache)占用系统中最多的内存。所有对磁盘文件的操作(写入或读取)都是通过页面缓存完成的。在 Linux 中,写入总是比读取快(例如,使用 O_SYNC 时并非总是如此),因为写入操作会先写入页面缓存,然后再写入磁盘。读取时,内核会在页面缓存中查找文件,如果找不到,则从磁盘读取文件。您可以使用 free 命令查看系统当前在页面缓存中使用的内存量:
$ free -htotal used free shared buff/cache available
Mem: 1.5Gi 1.2Gi 34Mi 191Mi 548Mi 362Mi
Swap: 0B 0B 0B
页缓存显示在 buff/cache 列中。我们可以看到,页缓存占用了 548Mi。然而,这不仅仅是页缓存;它还包含缓冲区,该缓冲区也与磁盘文件关联。
您可以在 /proc/meminfo 文件中分别查看有关页缓存和缓冲区的信息:
$ grep "^Cach|^Buff" -E /proc/meminfo
Buffers: 3280 kB
Cached: 518724 kB
创建新文件时,它会被写入缓存,并且该文件的内存页面会被标记为脏页。脏页会定期刷新到磁盘,如果脏页过多,也会被刷新。这可以通过 sysctl 参数(sudo nano /etc/sysctl.conf)进行控制:
- vm.dirty_expire_centisecs — 将脏页刷新到磁盘的间隔,以百分之一秒为单位(100 = 1 秒);
- vm.dirty_ratio — 可分配给页面缓存的 RAM 百分比。
$ sudo sysctl vm.dirty_expire_centisecs
vm.dirty_expire_centisecs = 3000
$ sudo sysctl vm.dirty_ratio
vm.dirty_ratio = 20
您可以从 /proc/meminfo 文件中找出脏页的数量。sync 命令将脏页写入磁盘:
$ grep Dirty /proc/info
Dirty: 864 kB
并且同步命令将数据写入磁盘:
# sync
$ grep Dirty /proc/info
Dirty: 0 kB大页面
良好的内存至关重要。我们来简单聊聊 HugePages。这些页面具有以下特性:
- 此类页面的大小为2MB;
- 应用程序必须能够处理此类页面;
- 这些页面永远不会被刷新以进行交换。
您可以使用 sysctl 参数为 HugePages 页面分配内存:
- vm.nr_hugepages = <页数>(因此,如果您指定 1024,则将分配 1024*2MB=2048MB)。
- vm.hugetlb_shm_group = gid - 只有该组的成员可以使用 HugePages。
编辑 /etc/sysctl.conf 后,需要重新启动并查看 /proc/meminfo 文件中的结果:
$ egrep "HugePages_T|HugePages_F" /proc/meminfo
HugePages_Total: 1024
HugePages_Free: 1024
系统分配了 1024 个页面,所有页面都是空闲的。但是,对于不支持 HugePages 的常规应用程序来说,这 2GB 内存是无法使用的。因此,并非总是需要分配 HugePages。
交换部分
对于基于文件的内存,操作很简单:如果其中的数据没有更改,则无需执行任何特殊操作即可将其逐出——只需擦除即可,并且始终可以从文件系统中恢复。
此技巧不适用于匿名内存:它没有关联的文件,因此为了防止数据永久丢失,需要将其存储在其他地方。可以使用所谓的“交换”分区或文件来实现这一点。这在实践中是可行的,但并非必要。如果禁用交换,匿名内存将变为不可逐出,从而使访问时间可预测。
禁用交换似乎有一个缺点,例如,如果应用程序发生内存泄漏,则必然会浪费物理内存(泄漏的内存无法被逐出)。但最好从以下角度来看待这个问题:它实际上有助于更早地检测和修复错误。
锁
默认情况下,所有文件内存都是可抢占的,但 Linux 内核提供了禁用抢占的功能,不仅可以按文件禁用,还可以按页面禁用。
这是通过 mmap 映射的虚拟内存区域上的 mlock 系统调用来实现的。如果您不想深入研究系统调用,我建议您使用 vmtouch 命令行实用程序,它可以执行相同的操作,但在外部执行。
以下是一些可能有用的示例:
- 应用程序有一个很大的可执行文件,其中包含许多分支,其中一些分支执行频率不高,但执行频率较高。出于其他原因,也应该避免这种情况,但如果没有其他办法,为了避免在这些罕见的代码分支上产生不必要的等待,您可以阻止它们被抢占。
- 数据库中的索引通常在物理上是一个通过 mmap 访问的文件,并且需要 mlock 来最大限度地减少延迟和已加载磁盘上的 I/O 操作次数。
- 应用程序使用某种静态字典,例如,将 IP 地址子网映射到其所属的国家/地区的字典。如果在单个服务器上运行多个访问此字典的进程,这一点就显得尤为重要。
OOM killer
如果过度使用不可抢占内存,最终可能会导致内存已满且无法抢占的情况。但是,您可以释放它,而不是抢占它。
这是通过一种相当激进的方法实现的:赋予此部分名称的机制使用一种特定的算法来选择当前最适合牺牲的进程。当一个进程被终止时,它正在使用的内存会被释放,这些内存可以在幸存的进程之间重新分配。此选择的主要标准是当前物理内存和其他资源的消耗情况。此外,您可以手动将进程标记为更有价值或更不值钱,甚至可以将它们完全排除在考虑范围之外。如果您完全禁用 OOM 终止程序,系统在内存耗尽时将别无选择,只能重新启动。
cgroups
默认情况下,所有用户进程会平等地占用单台服务器上几乎所有可用的物理内存。这种行为几乎是不可接受的。即使服务器相对单任务运行,例如,仅使用 nginx 通过 HTTP 提供静态文件,也总会有一些服务进程,例如 syslog 或用户运行的某些临时命令。如果服务器上同时运行多个生产进程,例如,一个常用的选项是将 memcached 挂接到 Web 服务器,那么在内存不足的情况下,防止它们相互“争夺”内存就显得尤为重要。
为了隔离重要进程,现代内核提供了 cgroups 机制。它允许您将进程划分为逻辑组,并静态配置可分配给每个组的物理内存量。每个组都会拥有自己的、几乎独立的内存子系统,并配备各自的驱逐跟踪、OOM 终止程序和其他功能。cgroups
机制远比简单地监控内存消耗要全面得多。它可以用于分配计算资源、将组分配给处理器核心、限制 I/O 等等。这些组本身可以组织成一个层次结构,并且 cgroups 是许多轻量级虚拟化系统和流行的 Docker 容器的基础。
非易失性存储器
在多处理器系统中,并非所有内存都生来平等。如果主板上有 N 个处理器(例如 2 个或 4 个),则通常所有 RAM 插槽都会被物理分成 N 组,每组都更靠近其对应的处理器——这种布局称为 NUMA。
这意味着每个处理器访问特定 1/N 部分的物理内存的速度(大约是访问剩余 (N-1)/N 部分的 1.5 倍)更快。Linux
内核可以自动检测到这种情况,并在调度处理器和为其分配内存时默认智能地考虑到这一点。您可以使用 numactl 实用程序和一些可用的系统调用(特别是 get_mempolicy/set_mempolicy)来查看和调整此信息。
在 Linux 中使用内存
内存管理子系统是最重要的子系统之一。所有其他子系统都依赖于它的性能以及它管理 RAM 的效率。
在研究内存子系统时,了解并理解可用的不同类型的内存以及我们所讨论的内容非常重要。下面我们将讨论两种类型的内存:
- 物理 - RAM
- 线性 - 虚拟内存,它可以大于您实际拥有的物理内存。
所有物理内存都被划分为页框。页框的大小取决于平台;对于 x86 系统,页框通常为 4 KB,但最大可达 4 MB。每个物理页框都由一个基本数据结构 struct page ( include/linux/mm_types.h ) 描述。该结构用于跟踪页框的状态:它是空闲的还是已分配的,它的所有者,以及它存储的内容:数据、代码等。struct page 被组织成双字块,以执行原子双字操作。让我们来描述一下 struct page 的一些重要字段:
- atomic_t _refcount — 指向页面结构的引用数量。根据 init_free_pfn_range() 函数(mm/init.c)可知,如果 _refcount 为 0,则表示该页面框架空闲;如果 _refcount > 0,则表示该页面框架已被占用。
- 无符号长整型 flags — 包含描述页框状态的标志。所有标志均在
文件 ( include/linux/page-flags.h) 中描述。
32位Linux机器的物理内存分为3个部分——区域:
- ZONE_DMA — 前 16 MB 物理内存,
- ZONE_NORMAL — 占用 16 MB 到 896 MB 的地址,
- ZONE_HIGHMEM — 包含大于 896 MB 的页面帧
32 位系统中物理内存的这种划分是由于只能寻址 4 GB 的线性内存,而进程必须同时在用户模式和内核模式下运行(例如,为了执行系统调用)。因此,进程的线性地址空间被划分为几个部分:3 GB 用于用户模式,1 GB 用于内核模式。在前 3 GB(地址最高为 0xC0000000)中,进程在普通用户模式下运行,而 0xC0000000 以上的地址则用于超级用户模式。NORMAL 区域和 DMA 区域直接映射到第 4 GB 的线性地址空间。位于这些区域中的对象始终可以访问,因为它们具有线性地址。但是,HIGHMEM 区域包含内核无法轻松访问的帧。这是因为 HIGHMEM 包含的帧的线性地址在 32 位系统中根本不存在。因此,页框分配函数 alloc_page() 返回的不是指向第一个页框的指针(线性地址),而是指向描述该页框的第一个页描述符。所有页框描述符都位于 NORMAL 区域,因此它们始终存在一个线性地址。NORMAL 地址的高 128 MB 用于映射线性地址空间中的高位地址。映射 HIGHMEM 有几种技术:
- 持续显示,
- 临时展示,
- 使用非连续的内存区域。
Linux 是一个现代跨平台操作系统,这样的系统必须能够有效地与多处理器系统协同工作。在这样的系统中,有几种实现计算机内存的方法。第一种是统一内存访问 (UMA)。在这种方案中,访问所有物理内存的时间大致相等,因此访问的地址之间操作系统性能绝对没有差异。需要注意的是,并非所有计算系统都支持统一内存访问,因此 Linux 支持非统一内存访问 (NUMA) 作为基本模型。在此模型中,系统的物理内存被划分为多个节点。每个节点由 pg_data_t 结构体 ( include/linux/mmzone.h ) 描述。每个节点都可能包含任何内存区域,因此 pg_data_t 结构体包含它们的描述符。所有节点的页框描述符都存储在全局 zone_mem_map 数组中,该数组位于相应区域的描述符中:
pg_data_t|________________node_zones_______________/ | \
ZONE_DMA ZONE_NORMAL ZONE_HIGHMEM| | |
zone_mem_map zone_mem_map zone_mem_map
这种内存管理方法的优点在于,UMA 可以简单地表示为单节点 NUMA,从而允许在任何地方使用相同的方法——可以说是普遍适用。
在 64 位机器上,物理内存也分为三部分,但由于客观原因,真正的 64 位机器目前无法支持全部 2^64 字节内存。例如,在 x86 中,最多仅支持 2^48 字节 = 256 TB 的内存,您一定会同意,这已经相当大了。由于实际物理内存远小于线性内存,因此 64 位系统目前不需要 HIGHMEM 区域;它为零,所有内存都划分为 DMA 和 NORMAL 两种模式。
现在我们已经了解了 Linux 如何描述可用的物理内存,接下来是时候研究内核如何处理内存了。为此,了解 Linux 如何分配内存(或者换句话说,分配器如何工作)至关重要。
引导内存
内核可用的第一个内存分配器是 bootmem ( mm/bootmem.c )。bootmem 分配器仅在内核启动时使用,用于在内存管理子系统可用之前初始分配物理内存。bootmem 的运行方式非常简单,它使用首次适应算法——搜索第一个空闲的物理内存块(页面)并进行分配。它使用位图来表示物理内存;如果位图为 1,则表示页面已被占用;如果位图为 0,则表示页面空闲。为了分配小于页面的内存,它会记录上一次此类分配的 PFN,并且下一个较小的分配(如果可能)将驻留在同一个物理页面上。分配器使用首次适应算法,该算法不受碎片的显著影响,但由于使用位图,因此速度非常慢。
/include/linux/bootmem.h
/** node_bootmem_map is a map pointer - the bits represent all physical* memory pages (including holes) on the node.*/
typedef struct bootmem_data {unsigned long node_min_pfn;unsigned long node_low_pfn;void *node_bootmem_map;unsigned long last_end_off;unsigned long hint_idx;struct list_head list;
} bootmem_data_t;
启动和内存初始化后,其他分配器可供内核使用:
---------------
| kmalloc |
------------------------
| kmemcache | vmalloc|
------------------------
| buddy |
------------------------Buddy
Buddy 是用于连续页框(而非线性页面)的分配器。某些任务(例如 DMA)需要连续的物理页面,因为 DMA 设备直接访问内存。采用这种方法的另一个原因是它避免了触及内核页表,从而加快了内存访问速度。连续页面分配器的问题是外部碎片,因此 Linux 中的 buddy 分配器使用标准方法:将所有可用页框按 2 的幂数分成列表:1、2、4、8、16、...、1024。1024 * 4096 = 4MB。块中第一个页框的物理地址是组大小的倍数。算法:我们要分配 256 个页框。分配器将检查列表 256;如果没有,它将在 512 中查找。如果有,它将取出 256 个帧并将其余的帧放入列表 256 中。如果 512 不可用,它将检查 1024。如果有,它将返回 256 个帧给请求者并将剩余的 768 个帧分成两个列表:512 和 256。如果 1024 不可用,它将发出错误信号。伙伴系统有一个全局对象,用于存储所有可用帧的描述符,每个处理器都有自己的可用帧的本地列表。如果本地列表内存不足,它将从全局对象中提取帧,如果本地列表可用,它将返回帧。每个区域都有自己的伙伴分配器。要使用伙伴分配器,必须使用 alloc_page/__rmqueue() ( mm/page_alloc.c ) 函数进行分配,使用 __free_pages() 进行释放。使用这些功能时,必须禁用中断并采用 zone->lock 自旋锁。
buddy的优点:
- 更快的 bootmem(不使用位图)。
- 您可以连续选择多个页框。
buddy的缺点:
- 分配小于页面框架的容量是不可能的,它总是分配>= PAGESIZE。
- 它仅分配队列中物理内存中的内存,但这仍然会导致碎片化。
VMALLOC
使用连续的物理区域有其优点,例如快速的内存访问,但也有其缺点,例如外部碎片。Linux 支持使用非连续的物理内存区域,这些区域可以通过连续的线性空间区域进行访问。非连续物理区域映射到的线性空间区域的起始位置可以通过 VMALLOC_START 宏获取,结束位置通过 VMALLOC_END 获取。每个非连续的内存区域都由一个结构体 ( include/linux/vmalloc.h) 描述。
struct vm_struct {struct vm_struct *next;void *addr;unsigned long size;unsigned long flags;struct page **pages;unsigned int nr_pages;phys_addr_t phys_addr;const void *caller;
};页面分配由 void *vmalloc(unsigned long size) 函数( mm/vmalloc.c ) 执行。size 是所请求内存区域的大小。内存以页面的倍数分配,因此它首先将 size 四舍五入为页面大小的倍数。它会分配连续的页面,但在虚拟地址空间中。vmalloc 会按页框从伙伴中获取物理页面。可以使用 vfree() 释放内存。缺点是会产生碎片,但在虚拟内存中,并且需要访问页表,这非常耗时。因此,vmalloc 很少被调用。它用于模块、I/O 缓冲区、防火墙和高端内存映射。
内核内存缓存
显然,buddy 和 vmalloc 都不适合处理任意长度的小内存区域,因为它们会造成浪费。因此,Linux 提供了另一个内存系统 kmemcache,它允许在页框内为小对象分配内存。但是,此处需要谨慎,因为可能会产生内部碎片。一般来说,kmemcache 包含三种不同的系统:SLAB/SLUB/SLOB。这些系统本质上相似,但也存在显著差异:
- SLOB 是为嵌入式子系统设计的,这意味着它使用最少的内存并且性能较差,并且容易受到内部碎片的影响。
- SLAB 是在 Solaris 中引入的,最初它是唯一的,但随着系统变得越来越大,SLAB 在具有大量处理器的系统中开始表现不佳。
- SLUB 是 SLAB 的进化版——更快、更高、更强。
首先,我们来描述一下 SLAB 接口。SLAB 基于以下几点观察。首先,内核会频繁地为各种结构请求并返回相同大小的内存区域。因此,为了加快速度,与其释放这些区域,不如将它们保留在缓存中供自己使用,稍后再重复使用,这样可以节省时间。最好尽可能少地访问伙伴对象,因为每次访问都会污染硬件缓存。如果对象访问频繁,还可以创建大小不是 2 的倍数的对象,这可以进一步提高硬件缓存的性能。SLAB 将对象分组到缓存中。每个缓存存储相同类型(大小)的对象。缓存包含多个 slab 列表:包含完全空闲的对象、部分空闲的对象和完全占用的对象。缓存的粒度分别为 1、2、4 和 8 页。
kmem_cache slab - список
________
| |——————> | | - | | - | |
| |
| |
| |——————> | | - | | - | |
| |
| |——————> | | - | | - | |
| |
要使用 struct kmem_cache,您需要通过以下函数获取句柄:
struct kmem_cache *kmem_cache_create(size);
size 是我们想要获取的固定大小。然后我们可以使用以下命令分配内存:
void kmem_cache_alloc(kc, flags);
并发布:
void kmem_cache_free(kc);
您可以使用以下方法销毁缓存:
kmem_cache_destroy()
所有关于 SLAB 的信息都可以在 /proc/slabinfo 中获取。SLAB
也需要内存分配,描述 SLAB 的描述符可以位于:另一个 kmem_cache 位于 slab 之外。slab 描述符可以位于 buddy 发出的页面(即 slab 上)的头部。但是 buddy 发出了一个大小与 slab 匹配的页面和 struct page,因此可以从系统中检索 struct page 并将其用于 slab。这就是 slab 的由来。SLAB 分配器的缺点是它分配的对象大小是常量,尽管我们并不总是知道需要分配内存的对象的大小。
更高级的分配器是 kmalloc/kfree ( include/linux/slab.h )。它访问所需的 kmem_cache,并通过静态函数 kmalloc_index(size) 获取它。在静态函数中,如果在编译时已知大小,编译器将用得到的索引替换函数调用:
static __always_inline int kmalloc_index(size_t size)
{
...
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)return 2;
if (size <= 8)return 3;
...
}- 0 = 零分配
- 1 = 65…96字节
- 2 = 129…192字节
- n = (2$^{n-1}$+1)… 2$^n$
缓存大小为 0/8/16/32/64/96/128/192/256 …/2$^{26}$。96 和 192 是启发式计算的频繁访问值。
所有分配器都使用 gfp_flags 标志组(include/linux/gfp.h)——获取空闲页面标志。它们最初出现在 buddy 中,然后逐渐向下传递到更高级别。
FLAG种类
分配位置:__GFP_DMA(获取可用页面)、__GFP_HIGHMEM、__GFP_DMA32。默认情况下,系统会尝试在 ZONE_NORMAL 中分配内存。
低内存行为是我们实际操作的上下文。如果没有内存,则需要找到它,例如:
- 在磁盘缓存中 - 必须采用互斥锁;
- 核缓存 - 需要使用互斥锁;
- 释放脏磁盘缓存需要获取互斥锁并访问文件系统和块;
- 交换需要获取互斥锁并访问块;
例如:__GFP_ATOMIC — 什么都做不了,伙伴会返回 NULL。__GFP_NOFS — 缓存和缓冲区使用它来确保它们不会被递归调用。__GFP_NOIO。
其他所有 — __GFP_ZERO — 分配器分配的内存应该用零填充。__GFP_TEMPORARY — 我需要分配一个页面,保留一段时间,然后返回它。(路径)GFP_NORETRY GFP_NOFAIL。
用户内存管理
内核内存分配请求 alloc_pages() 和 kmalloc() 如果能够满足,则会导致立即分配内存。这是合理的,因为:
- 内核是系统中优先级最高的组件,它的请求至关重要。
- 内核信任自己,假设内核中没有错误。
对于在用户模式下运行的进程,情况有所不同:
- 进程的内存请求可以被推迟。
- 用户代码可能包含错误,因此您需要做好处理这些错误的准备。当进程请求内存时,它不会获得新的页框,而是获得访问新线性地址的权限。
进程地址空间
进程地址空间是进程可以访问的线性地址。内核可以通过添加或删除内存区域 (vm_area_struct) 来动态修改进程地址空间。
进程可以获取新的内存区域,例如,调用 malloc()、calloc()、mmap()、brk()、shmget() + shmat()、posix_memalign()、mmap() 等函数。所有这些调用都基于 void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);:
- addr — 分配内存的地址。
- 标志:
- NULL — 内存分配位置无关紧要。addr 参数仅供参考。
- MAP_FIXED - 恰好位于 addr 中指定的位置。
- MAP_ANON(MAP_ANONYMOUS)-更改在任何文件中都不会显示。
- MAP_FILE — 来自文件或设备的映射。
- 保护执行
- 保护读取
- 保护写入
- 保护_无
内存描述符
有关进程地址空间的所有信息都存储在task_struct中的mm字段指向的mm_struct(内存描述符)中。
task_struct
_________
| … | mm_struct
--------- _________
| mm | -> | … |
--------- ---------
| … | | mmap | -> vm_area_struct * (VMA)
--------- ---------| pgd |---------
mm_struct 和 vm_area_struct 结构的描述可以在 /include/linux/mm_types.h 中找到。
内存区域
struct vm_area_struct {/* The first cache line has the info for VMA tree walking. */unsigned long vm_start; /* Our start address within vm_mm. */unsigned long vm_end; /* The first byte after our end addresswithin vm_mm. *//* linked list of VM areas per task, sorted by address */struct vm_area_struct *vm_next, *vm_prev;...................struct rb_node vm_rb;………../* Function pointers to deal with this struct. */const struct vm_operations_struct *vm_ops;
}
内存区域有两个字段:vm_start 和 vm_end,分别表示分配区域的起始地址和结束位置后的第一位。如果 mmap() 使用相同的参数,内核不会创建新的 VMA,而只是修改现有 VMA 的 vm_end。
所有内存区域被组合成一个双向链表,按地址升序排序。为了避免在分配、回收或查找拥有该地址的 VMA 时遍历整个列表,所有 VMA 也被组合成一棵红黑树。
struct rb_node {unsigned long __rb_parent_color;struct rb_node *rb_right;struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));/* The alignment might seem pointless, but allegedly CRIS needs it */
struct rb_root {struct rb_node *rb_node;
};
mm_struct -> pgd — 指向每个进程全局页目录的指针。在 x86 平台上,进程切换时,mm_struct -> pgd 会被放置在 cr3 中。更改 cr3 的值会导致 TLB 刷新。但是,两个 task_struct 可以具有相同的内存地址(例如,两个线程),在这种情况下 cr3 的值不会更改,从而显著加快内存访问速度。
除了线程之外,kernel_threads 也不会发生 cr3 切换。它们根本不需要内存区域,因为它们始终访问 TASK_SIZE = PAGE_OFFSET = 0xffff880000000000 (x86_64) 以上的固定线性地址。因此,task_struct 中 kernel_thread 自身的内存地址完全没有必要;它为 NULL。但是,task_struct 中存在 active_mm,它等于被抢占进程的 active_mm。
VMA 中另一个有趣的字段是 vm_ops,它决定了可以对特定内存区域执行的操作。
使用内存区域
功能描述:
- do_mmap() (/mm/mmap.c) – 分配新的内存区域
- do_munmap() (/mm/mmap.c) – 返回内存区域
- find_vma()(/mm/mmap.c) – 搜索距离给定地址最近的区域
- find_vma_intersection() (/include/linux/mm.h) – 查找包含地址的区域。
- get_unmapped_area() (/mm/mmap.c) — 查找未映射区域
- insert_vm_struct() (/mm/mmap.c) – 将区域添加到描述符列表中
线性地址间隔的分配
分配的线性地址可以与文件关联(FILE),也可以不关联(ANON)。请求内存的进程可以共享(MAP_SHARED)或独占(MAP_PRIVATE)。
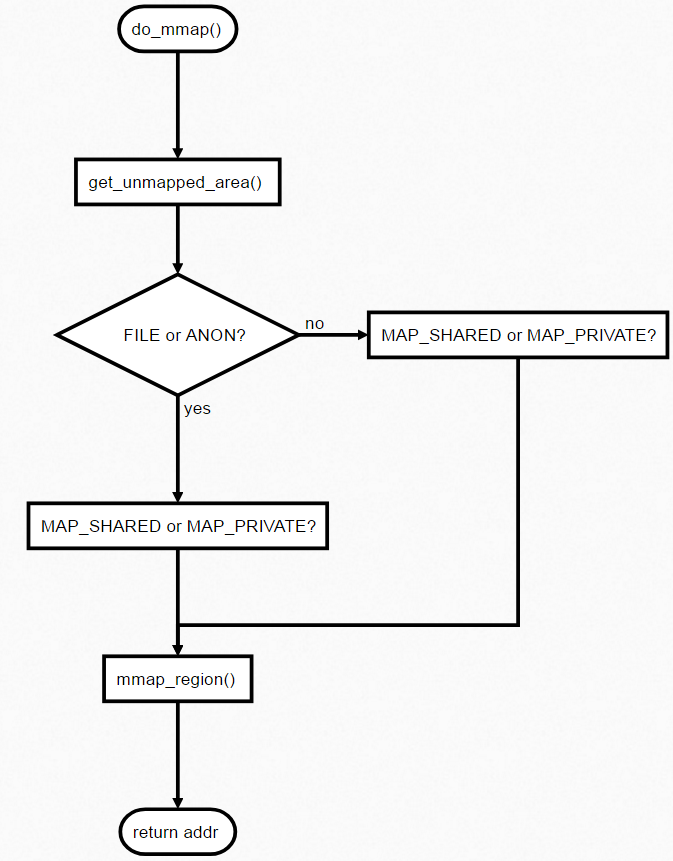
延期分配
如上所述,用户进程的内存请求可以延迟到实际需要内存时才进行。这是通过处理页面错误异常(表示页面缺失)来实现的。
在 x86 中,每个页表条目对齐到 4096(2^12),因此前 12 位包含页面相关信息,例如:
- 0 位 - P(当前)标志
- 1 位 - R/W(读/写)标志
- 2 位 - U/S(用户/管理员)标志
因此,如果 P 位设置为零,则访问该内存区域时将引发异常。异常发生时,引发异常的地址将被存储在 cr2 寄存器中。最终的算法可以用图表表示。
如果访问发生在堆栈 VMA 附近(使用 MAP_GROWDOWN 标志创建的区域),则该区域会扩大。
❯ 提高记忆力
内存不足是一个常见问题。系统开始变慢——Windows 冻结,性能变得迟钝。为什么会发生这种情况?因为 Linux 内核调度程序在获得对 RAM 的访问权限之前无法满足正在运行的程序中的操作请求。它也无法执行下一个操作,从而创建磁盘读取请求队列,并且由于队列处理速度较慢,系统开始运行缓慢。
如果此时运行 htop,平均负载 (LA) 指标可能会很高。
网站通常建议将 vm.swappines 参数从 60 设置为 10。实际上,这并不总是能提高性能。此控件用于确定内核使用内存分页的积极程度。较高的值会增加积极性,而较低的值会减少分页量。值为 0 表示内核在可用页面和文件支持页面的数量低于区域中的最大值之前不要开始分页。更详细地说,这个介于 0 到 100 之间的值决定了系统优先使用匿名内存还是页面缓存的程度。较高的值可以提高文件系统性能,同时会降低从物理内存中驱逐活动进程的积极性。较低的值可以防止进程因内存不足而过载,从而降低 I/O 性能。这提高了应用程序数据的优先级,但会以 I/O 缓存为代价。
您还可以启用 zram,这是一个内置的 Linux 内核模块,它通过增加 CPU 负载来压缩 RAM。
它通过阻止页面交换到磁盘来提高性能,在 RAM 中使用压缩的块设备,直到需要硬盘的交换文件为止。
要启用 zram,您需要加载内核模块:
$ modprobe zram num_devices=2
还编辑 /etc/default/grub:
GRUB_CMDLINE_LINUX_DEFAULT="... zram.num_devices=2 ..."
num_devices 指定要创建的压缩块设备的数量。为了实现最佳 CPU 利用率,应根据核心数量创建压缩块设备。
之后,您可以根据需要使用这些设备,甚至可以创建 SWAP 分区:
echo '1024M' > /sys/block/zram0/disksizeecho '1024M' > /sys/block/zram1/disksizemkswap /dev/zram0mkswap /dev/zram1swapon /dev/zram0 -p 10swapon /dev/zram1 -p 10
此模块的工作原理类似于 tmpfs——它代表内核占用一块内存。此块设备像 SSD 一样处理丢弃/修剪命令。
❯ 结论
Linux 中的内存是一个非常有趣的机制。了解内存的工作原理将有助于您的 Linux 开发。