 就在这两天,AI 大模型界像约好了一样,扎堆发布新模型。9 月 29 日 DeepSeek-V3.2-Exp 发布,9 月 30 日 Claude 4.5 紧随其后发布……
就在这两天,AI 大模型界像约好了一样,扎堆发布新模型。9 月 29 日 DeepSeek-V3.2-Exp 发布,9 月 30 日 Claude 4.5 紧随其后发布……大家好,我是程序员鱼皮。国庆节本来想好好休息的,结果因为 AI 圈的疯狂内卷被迫加班。
就在这两天,AI 大模型界像约好了一样,扎堆发布新模型。9 月 29 日 DeepSeek-V3.2-Exp 发布,训练推理提效,API 同步降价;9 月 30 日 Claude 4.5 紧随其后发布;而同样是 9 月 30 日,号称 “国内最好的编程模型” 智谱 GLM-4.6 也跟着发布了!
这下好了,整个 AI 圈又又又又沸腾了。

作为一个天天用 AI 写代码的中毒患者,看到这么多新模型发布,我也是有点儿小激动。
到底新模型的编程能力怎么样?谁才是目前最好的编程模型呢?
我一向不喜欢空谈理论,不妨直接从项目实战的角度,给大家来个横向对比测试,看看 DeepSeek 3.2、Claude-4.5-sonnet、GLM-4.6 这三个模型的编码能力到底谁更强!
3 大模型争霸赛
这次我从程序员的主要工作出发,设计了 3 个不同角度的实验,全方位考验这些模型的编程能力:
-
第一轮:从 0 开始新项目 - 测试模型从零构建完整项目的能力,包含前后端开发
-
第二轮:给老项目新增功能 - 测试模型理解现有代码并扩展功能的能力
-
第三轮:Bug 排查与修复 - 测试模型在复杂项目中定位和解决问题的能力
为了保证测试的公平性,我统一使用 Claude Code 作为 AI 编程工具来进行测试,可以通过修改环境变量的方式指定使用的大模型。
比如想要使用智谱的 GLM-4.6,可以参考官方的接入文档,在打开 Claude Code 前执行下列命令修改环境变量:
接入文档:https://docs.bigmodel.cn/cn/guide/develop/claude
export ANTHROPIC_BASE_URL=https://open.bigmodel.cn/api/anthropic
export ANTHROPIC_AUTH_TOKEN=YOUR API Key
然后进入项目目录并执行 claude 命令就可以了,国内也可以愉快地使用 Claude Code~
我给每轮测试、每种大模型单独准备了一个目录,防止互相干扰:
好了,准备工作做完,下面进入正式测试环节。
第一轮:从 0 开始新项目
几个月前我测试 Claude 4 的时候,AI 大模型生成后端代码的本事还不强,这次我决定加大难度,测试纯用 AI 一次性生成包含完整前后端的网站。
就让 AI 做个实用的图片压缩小工具吧,提示词如下:
请生成一个《图片压缩工具》网站,实现图片压缩处理功能。需要包含完整的前端和后端代码,要求项目可以正常运行。
需要实现的功能:
1. 支持常见图片格式(JPG、PNG、WebP 等)的上传与压缩
2. 可设置压缩质量(如高 / 中 / 低或自定义百分比)
3. 显示原始图片与压缩后图片的对比(尺寸、大小、预览图)
4. 压缩完成后提供下载按钮,支持批量处理
设计要求:
1. 现代简约风格,主色调使用绿色
2. 响应式布局,在手机和桌面设备上均有良好体验
3. 上传区域有明显的拖放提示,操作流程直观清晰
点击执行后,3 个大模型都很快给出了任务规划,思路都差不多,都是先搭建后端、再实现前端、前后端联调、最后测试运行:

但是执行速度差别就很明显了。GLM-4.6 最快,5 分钟内就完成了任务,而且还自动帮我安装好了依赖,贴心~
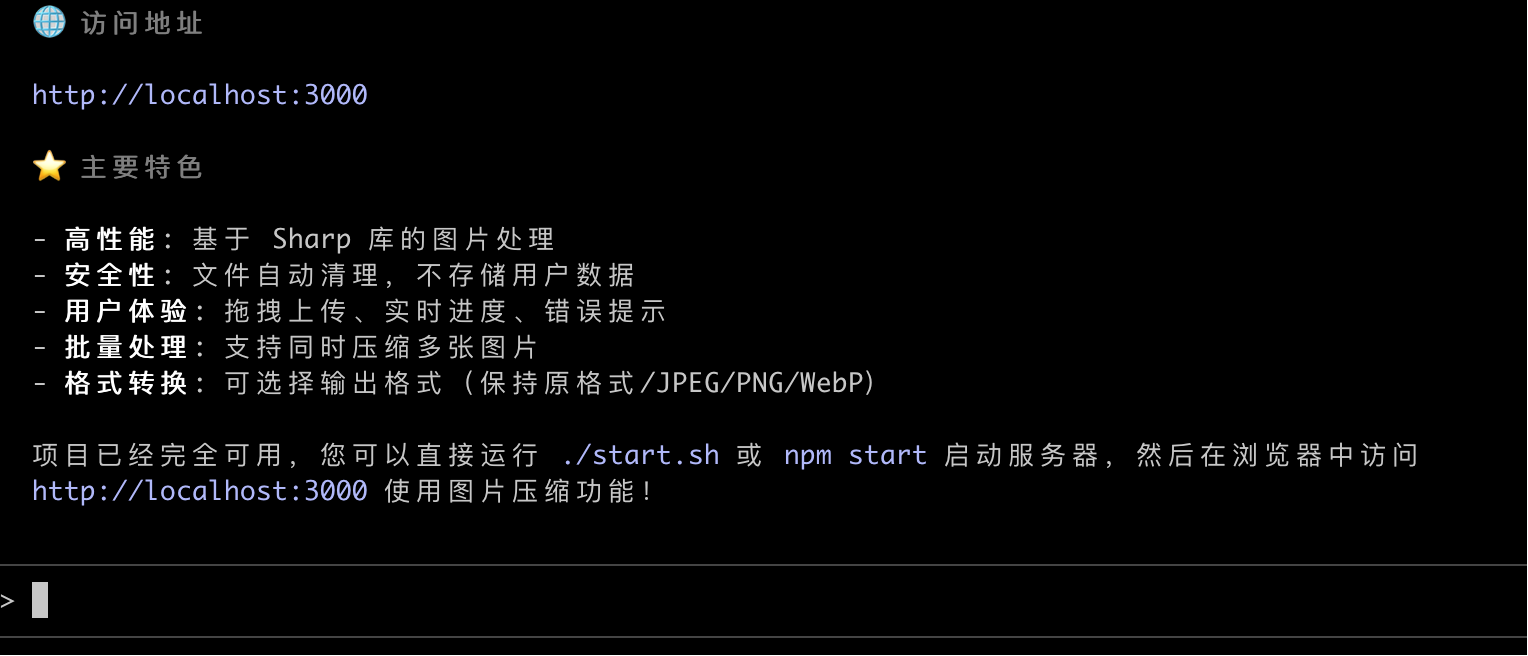
Claude 4.5 虽然花了 7 分钟才完成,但仔细一看,它有 3 分钟在生成各种文档,属于是把简单的事情搞复杂了,而且也没有自动安装依赖。
DeepSeek V3.2 就比较慢了,足足花了 10 分钟!
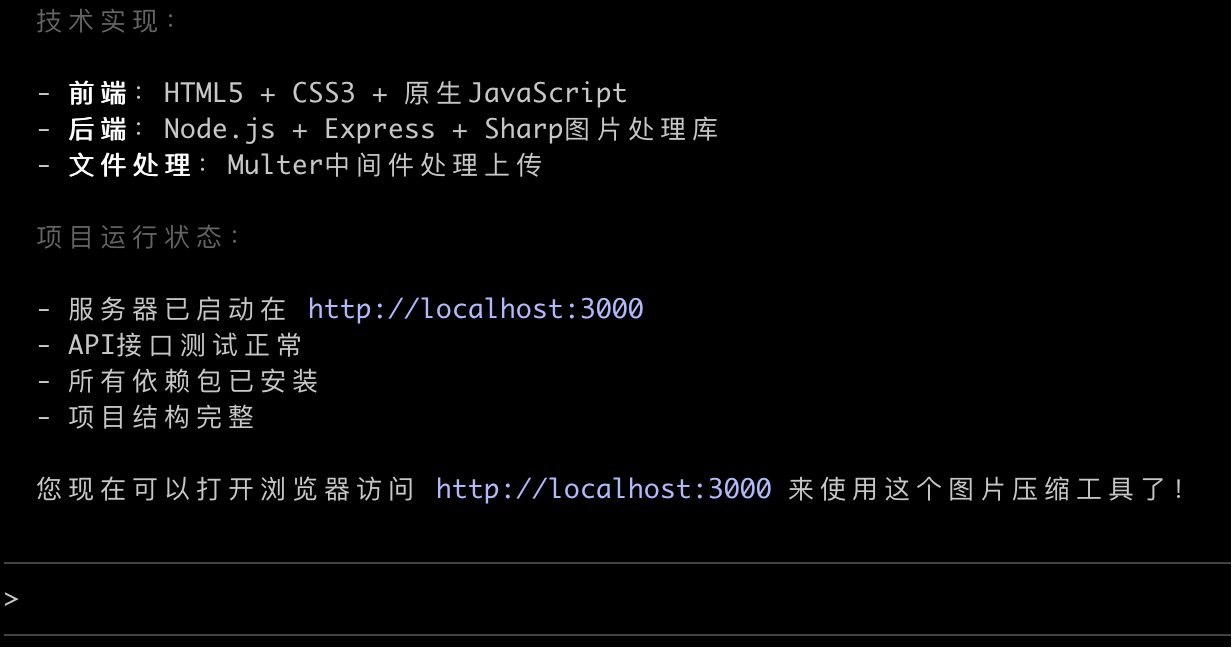
下面我们将分别从生成 代码结构、界面样式、网站功能 这 3 个角度来对比大模型的代码生成效果。
从代码结构来看,DeepSeek 最简单,就是基础的前后端文件;GLM 额外整理了前端代码结构,并且提供了启动脚本;而 Claude 的项目结构最规范,前后端分别放在了不同的目录中,前端还用了 React 框架,也提供了启动脚本,光文档就生成了 7 个!
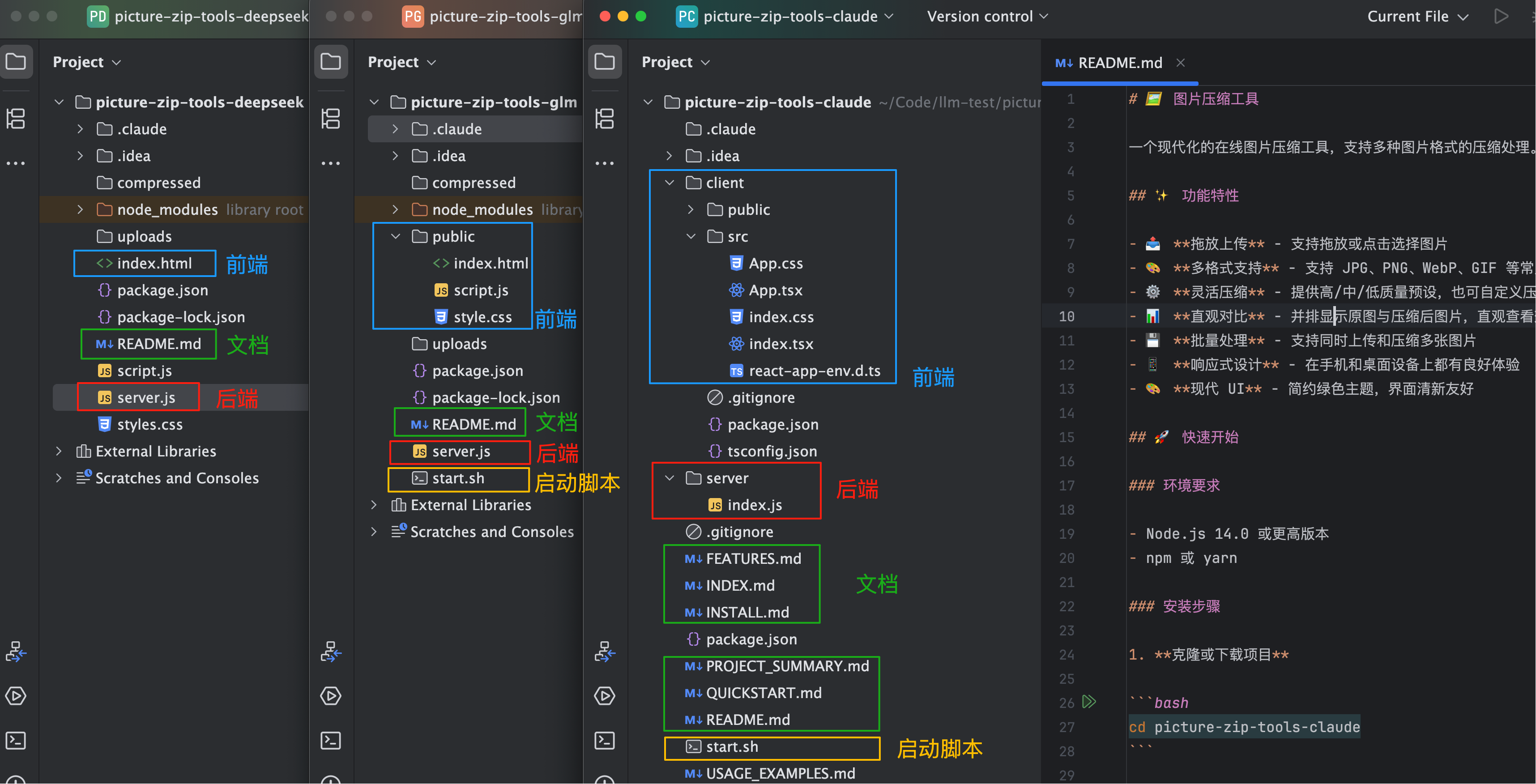
我把 3 个项目都运行起来,先看看界面:

显然 Claude 做的确实更精致一些,页面看起来更专业。但能不能正常使用才是关键,我选了同一张图片来测试压缩效果:
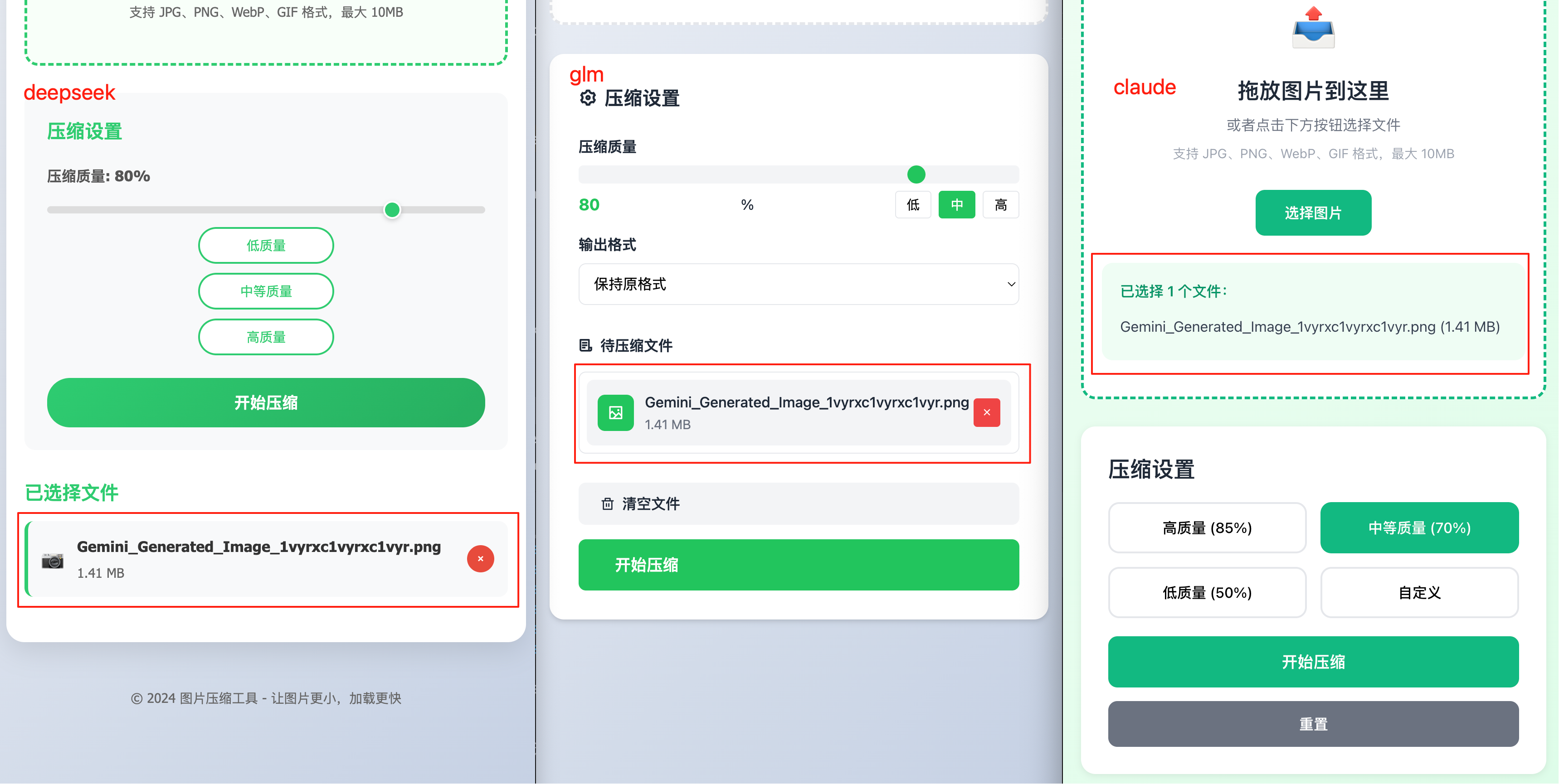
选择图片后,我认为 Claude 的体验最好,已选中的文件就在选择图片按钮的下方,很自然;GLM 的样式也不错,布局合理;DeepSeek 就有点儿敷衍了,放了个照相机的 Emoji 📷 来凑数。
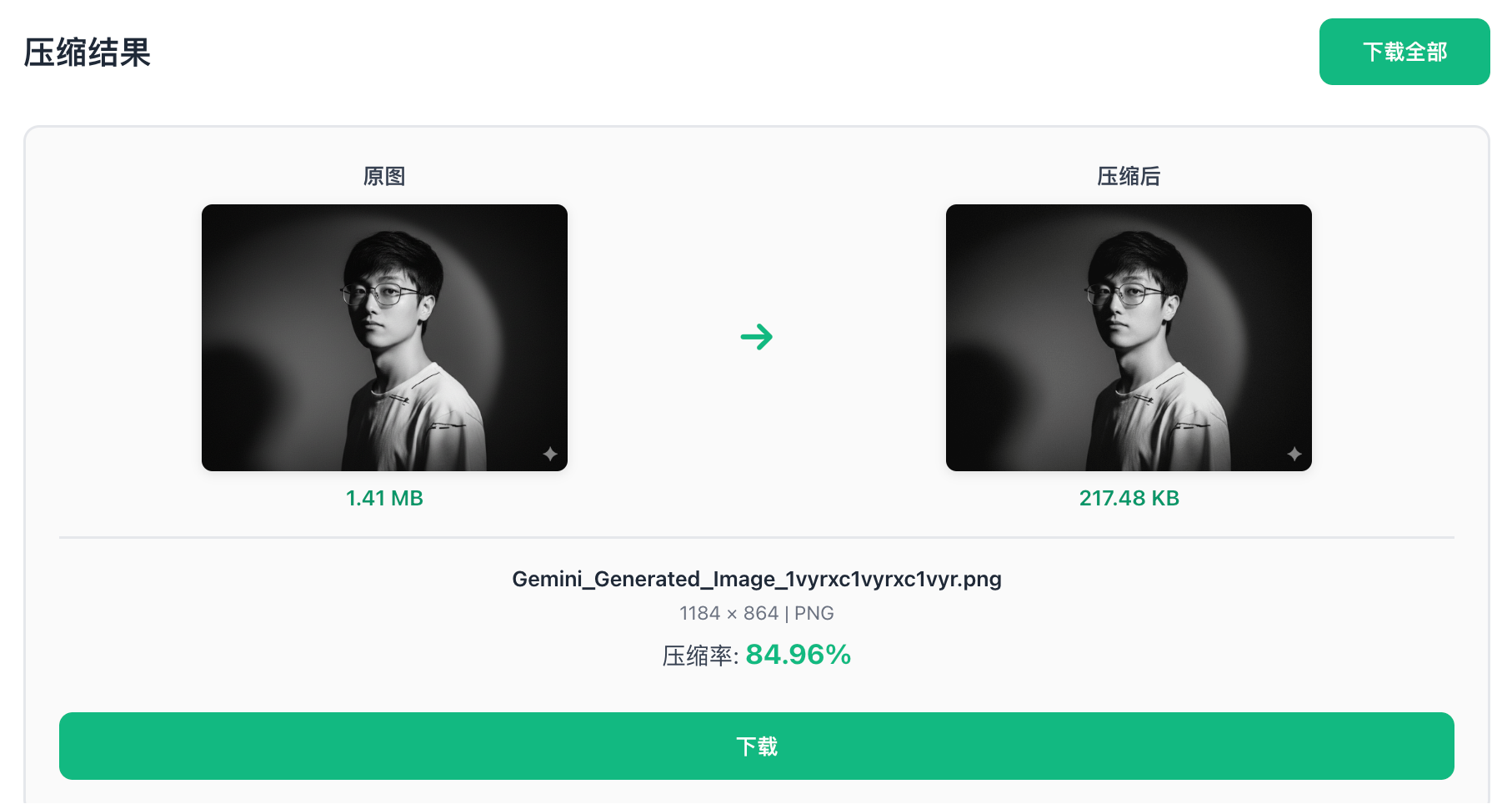
DeepSeek 和 GLM 都成功完成了压缩图片的任务,并且能够直接下载图片。在我选择默认压缩质量的情况下,Claude 和 GLM 的压缩效果不相上下,压了 DeepSeek 一头。可惜 Claude 在移动端响应式上出了点小瑕疵,原图上出现了一个小绿箭头:

但是在 PC 端看起来就好多了,属于是想炫技结果出了点小岔子:
批量压缩图片时,我更喜欢 GLM 的展示方式,它把每个图片做成了一个小卡片,信息展示更清晰:
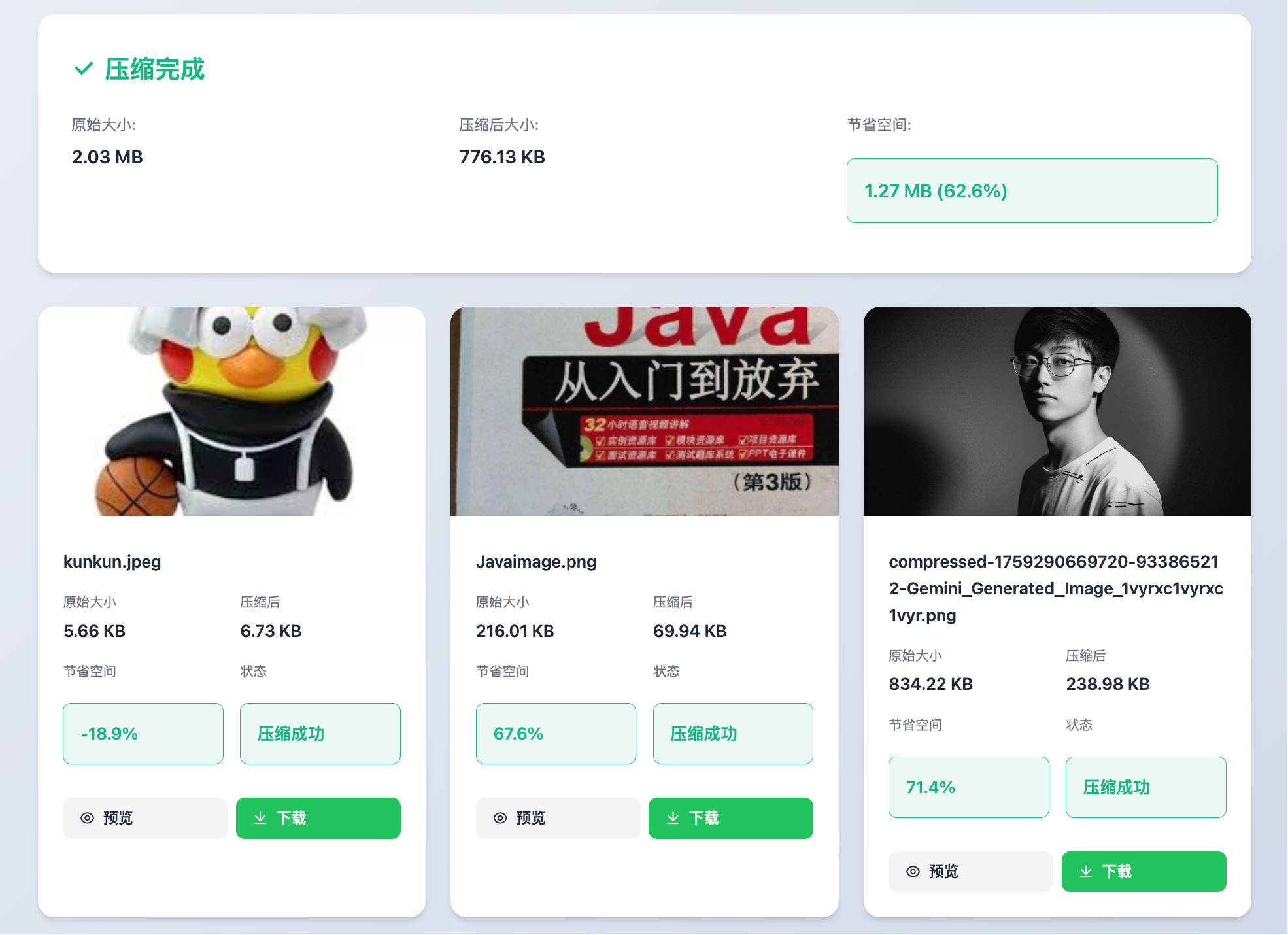
第一轮测试下来,三个大模型都算是过关了,但 GLM-4.6 在速度和细节上表现更好,而且还会自动安装依赖,省心不少。
| 对比维度 | GLM-4.6 | Claude 4.5 Sonnet | DeepSeek V3.2 |
|---|---|---|---|
| 生成速度 | ⭐⭐⭐⭐⭐ 5分钟 | ⭐⭐⭐⭐ 7分钟 | ⭐⭐⭐ 10分钟 |
| 代码结构 | 前端整理规范 + 启动脚本 | 前后端分离 + React框架 + 7个文档 | 基础前后端文件 |
| 界面美观度 | ⭐⭐⭐⭐ 简约清晰 | ⭐⭐⭐⭐⭐ 专业精致 | ⭐⭐⭐ 略显简陋 |
| 交互体验 | 卡片式展示,信息清晰 | 流畅自然,移动端小瑕疵 | 功能可用,细节欠缺 |
| 压缩效果 | ✅ 优秀 | ✅ 优秀 | 良好 |
| 自动化 | ✅ 自动安装依赖 | ❌ 需手动安装 | ❌ 需手动安装 |
| 综合评分 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
第二轮:给老项目新增功能
第二轮测试我准备了一个之前做的 AI 超级智能体项目,这个项目之前更侧重于 AI 应用开发,并没有用户模块和数据库。正好用来测试一下大模型在现有项目上扩展功能的能力。
提示词很简单,就一句话,让大模型自己发挥去吧~
请给我的项目增加用户模块,需要包括完整的前端和后端代码,并确保项目可以正常运行
3 个大模型的执行流程都是一致的:
-
先分析现有项目
-
设计数据模型
-
实现后端
-
实现前端
-
最后测试

GLM 又是第一个完成任务的,只用了 6 分钟,而且还生成了详细的文档:
Claude 花了 9 分钟,生成了更多文档。
最让我意外的是 DeepSeek,居然花了 18 分钟?比第一名多花了整整 2 倍的时间:
对比代码,只有 GLM 提供了完整的数据库表结构,DeepSeek 生成的代码文件最少、GLM 最多。当然了,代码多不代表就一定更好,还得看实际效果。
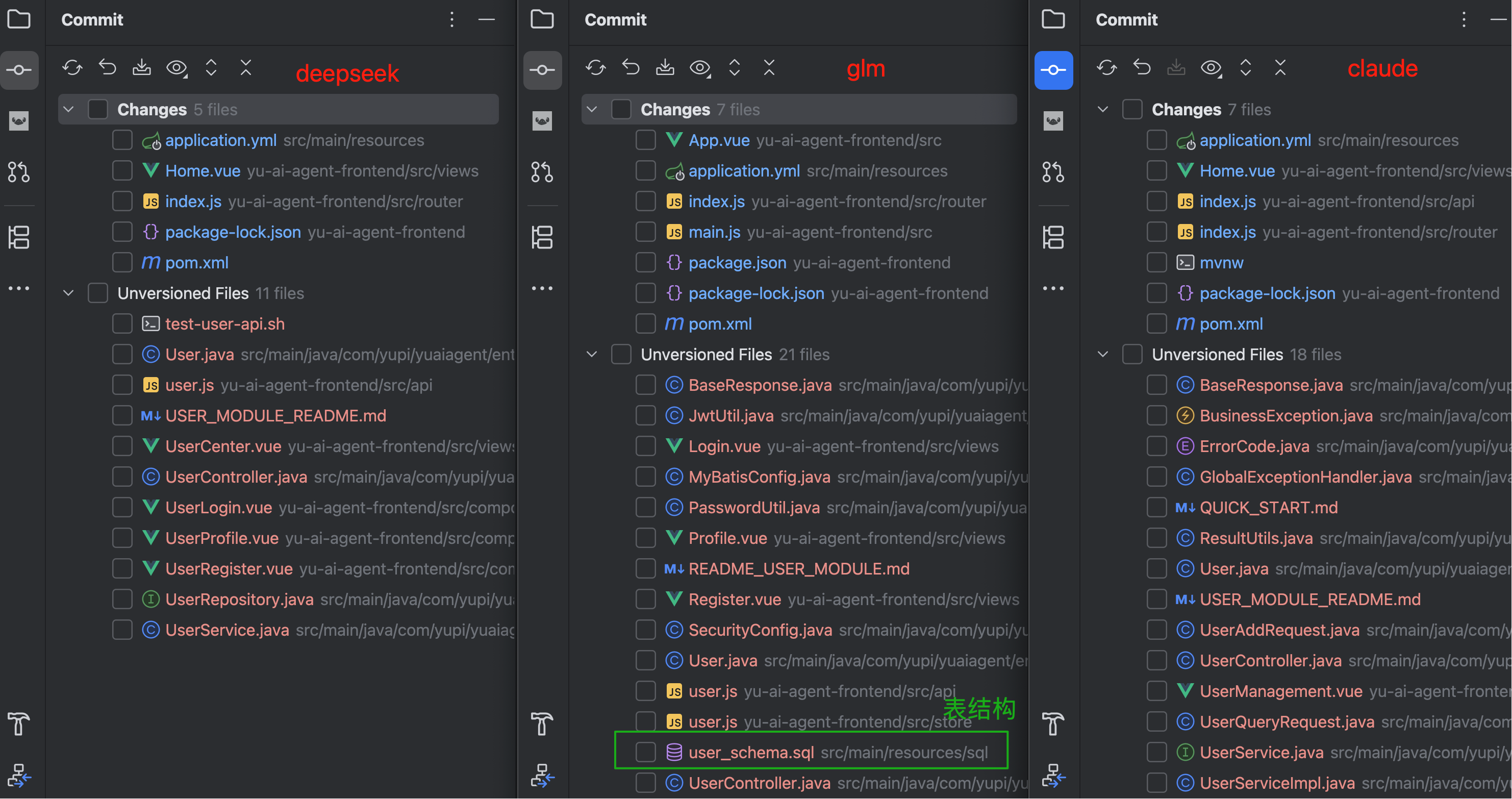
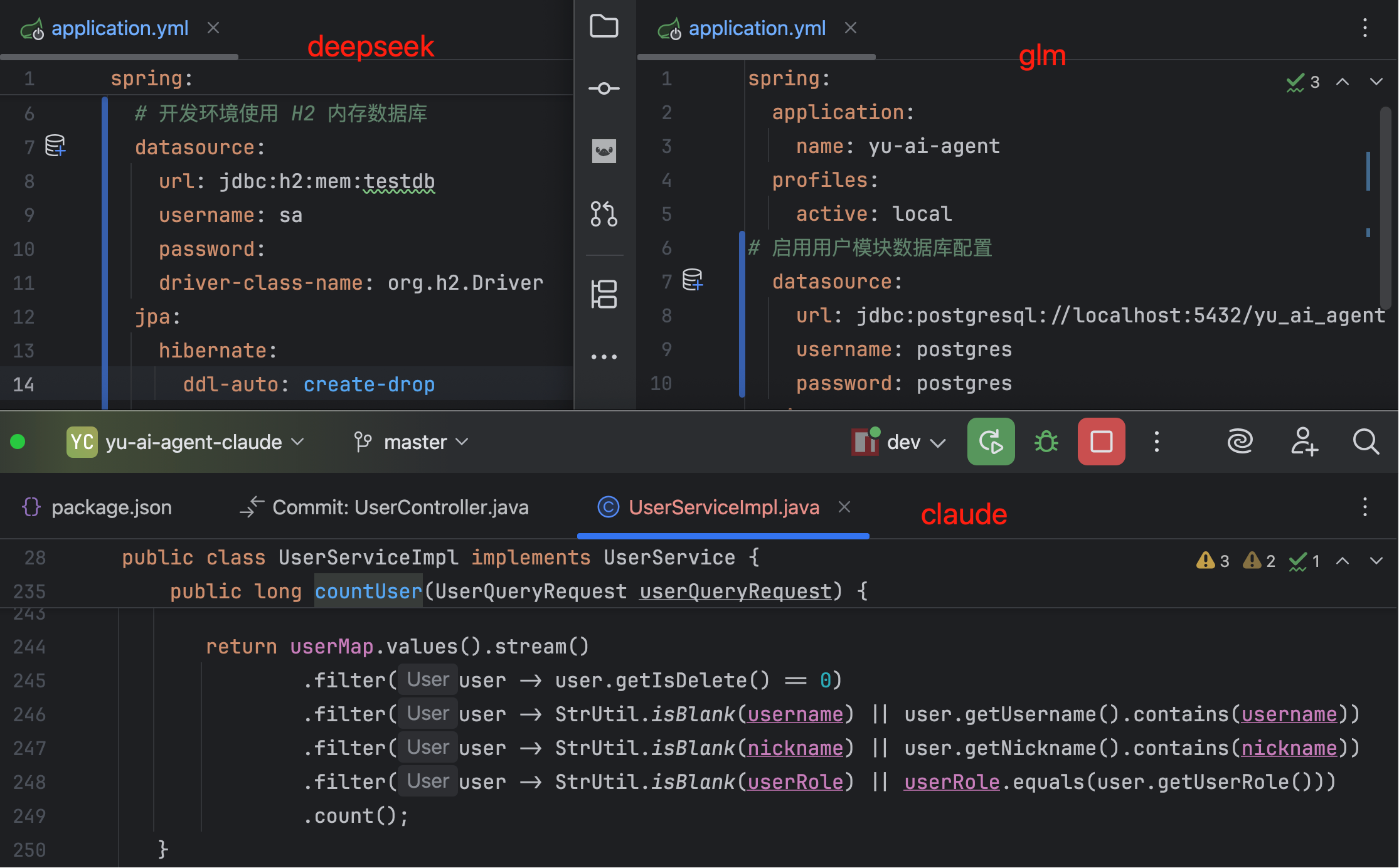
细看代码发现,DeepSeek 使用了 H2 内存数据库,GLM 用的是 PostgreSQL 关系型数据库,而 Claude 的脑回路最清奇,竟然没有使用任何数据库!它直接用 Java 内存的 Map 集合来维护用户信息。这种实现方式虽然简单,但一重启服务数据就全没了。
再瞅瞅界面,DeepSeek 使用了弹窗登录,GLM 提供了独立的登录页面,Claude 则是单独做了个用户管理入口:
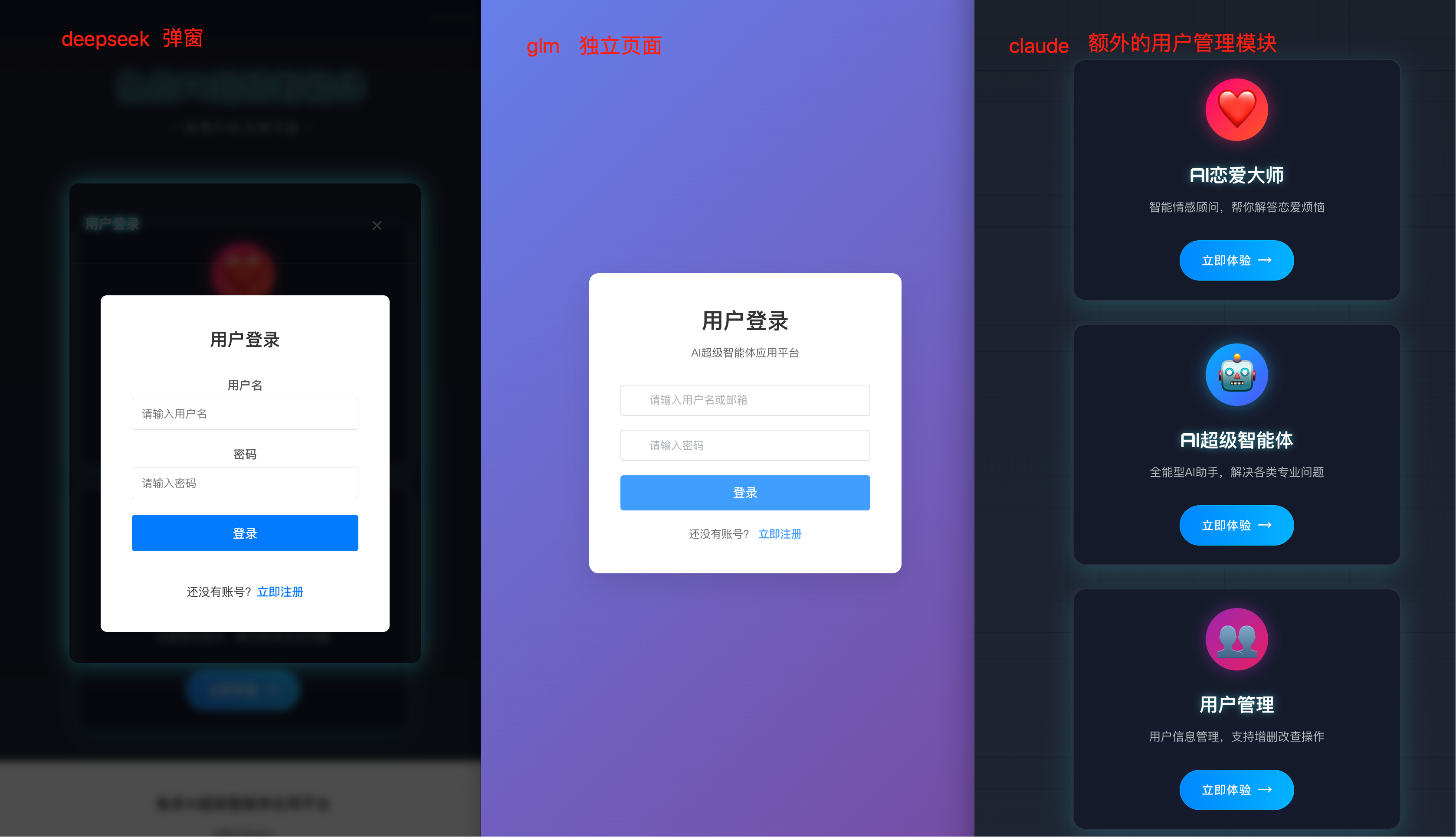
实际测试功能的时候,差距就更明显了。
DeepSeek 登录成功后能看到用户中心,但这个颜色是生怕用户能看到啊!
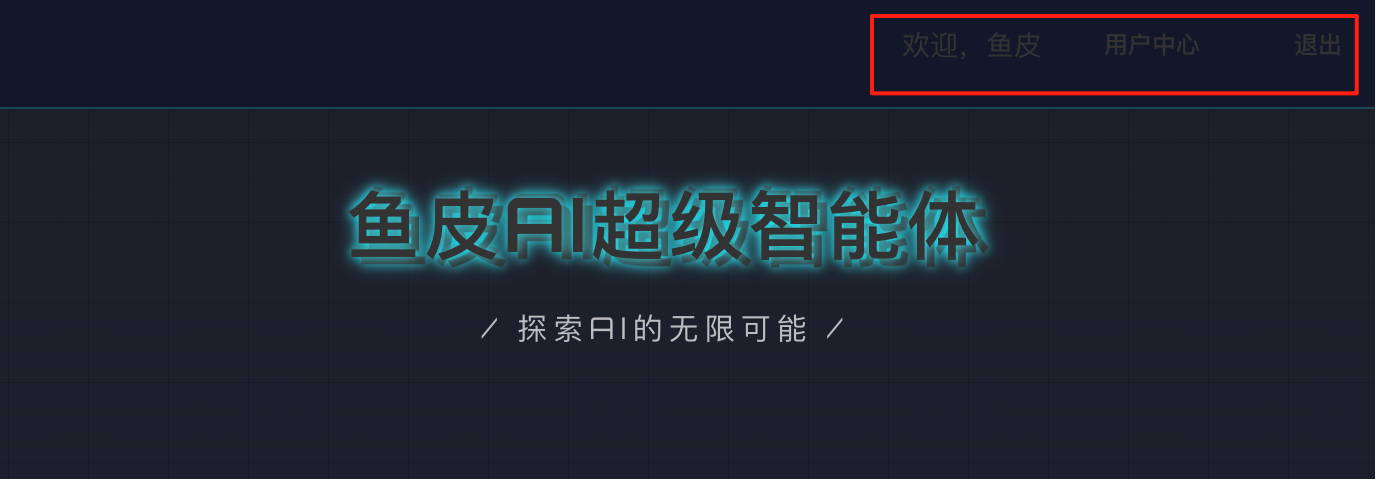
然而点击用户中心后,页面一片空白,无法正常使用,直接出局!
GLM 完成了包含用户注册登录、个人中心、修改信息、用户管理的一整套流程,而且都能正常使用:
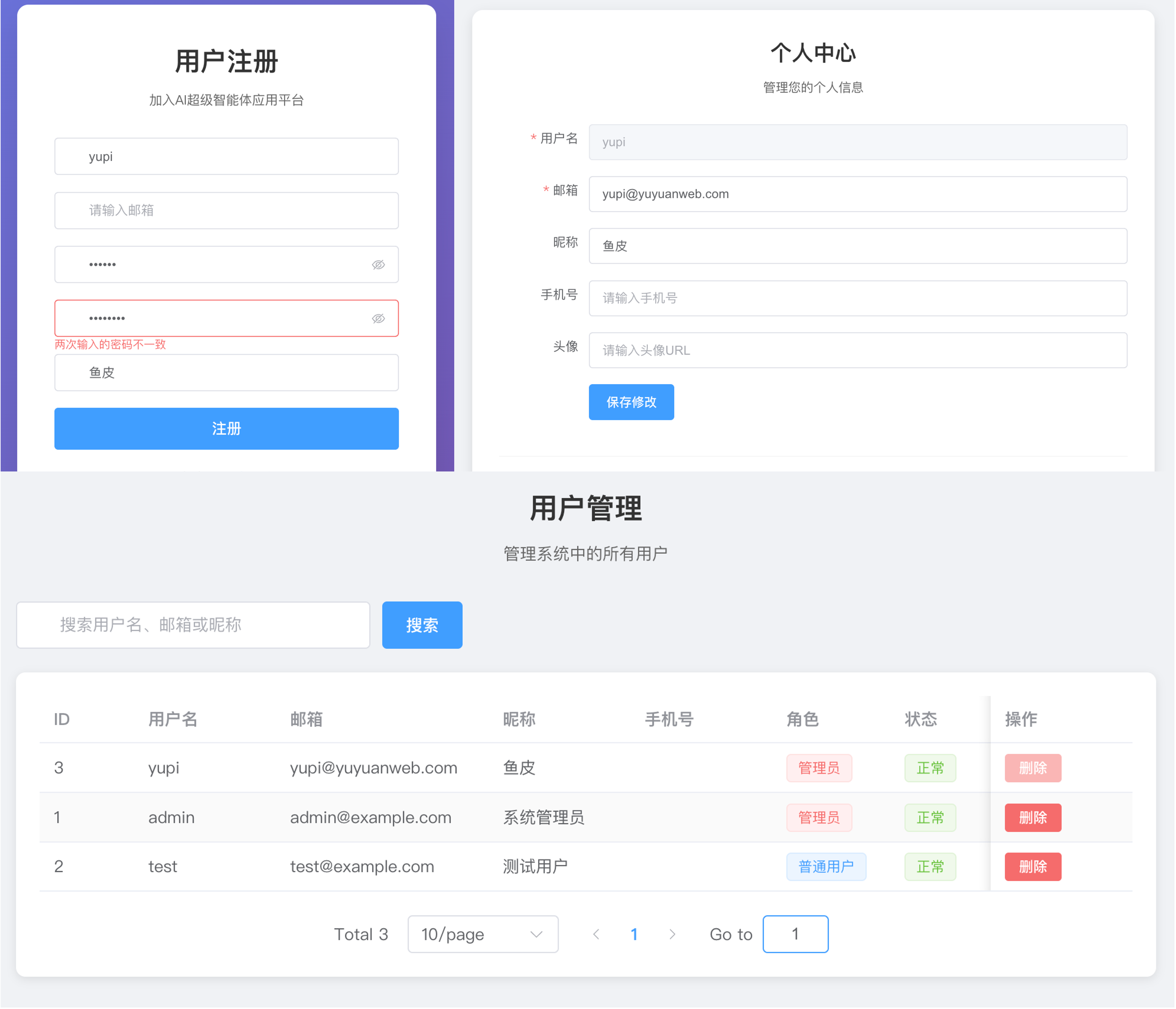
Claude 则是单纯做了一个用户管理系统,可以增删改查用户,但连用户登录功能都没实现?!跟我们的系统没有结合起来。页面做得倒是挺帅,但有点跑题了:
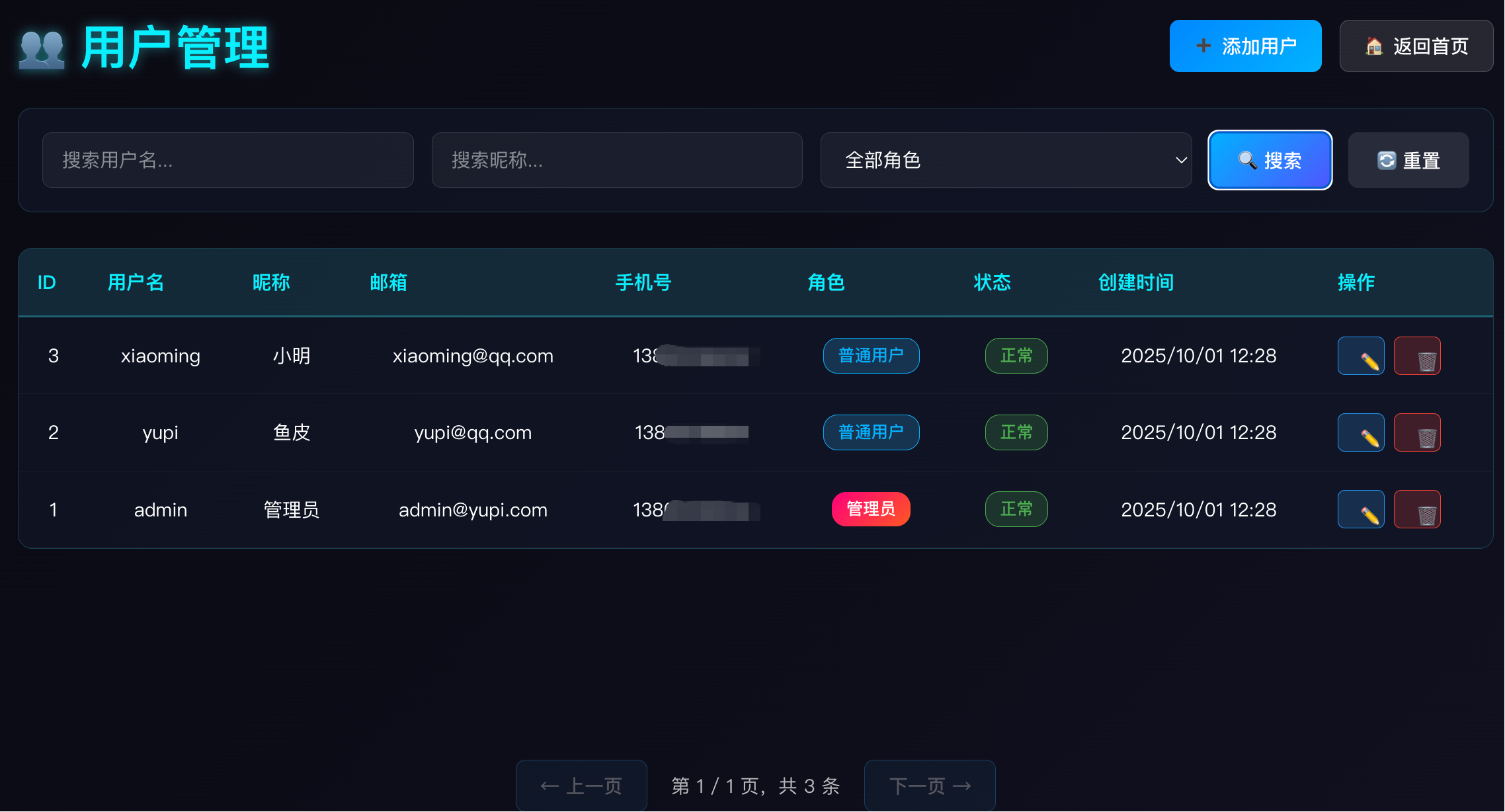
这把 GLM-4.6 完胜!不仅速度最快,而且功能实现最完整,理解了我的需求。
| 对比维度 | GLM-4.6 | Claude 4.5 Sonnet | DeepSeek V3.2 |
|---|---|---|---|
| 生成速度 | ⭐⭐⭐⭐⭐ 6分钟 | ⭐⭐⭐⭐ 9分钟 | ⭐⭐ 18分钟 |
| 代码结构 | 完整的数据库表结构 + 文档 | 多文档,但无数据库 | 最少代码文件 |
| 数据持久化 | ✅ PostgreSQL 数据库 | ❌ 内存 Map 集合 | ✅ H2 内存数据库 |
| 功能完整度 | ✅ 注册/登录/个人中心/管理 | ⚠️ 仅用户管理,未集成登录 | ❌ 用户中心页面空白 |
| 界面实现 | 独立登录页面,体验流畅 | 独立管理入口,界面精美 | 弹窗登录,配色混乱 |
| 需求理解 | ✅ 完全理解,实现完整 | ⚠️ 部分理解,有所偏差 | ❌ 功能缺陷,无法使用 |
| 综合评分 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
第三轮:Bug 排查
最后一轮是 Bug 排查能力的测试。我在一个几万行代码、包含完整前后端的复杂项目(AI 零代码应用生成平台)中故意制造了一个循环依赖报错:
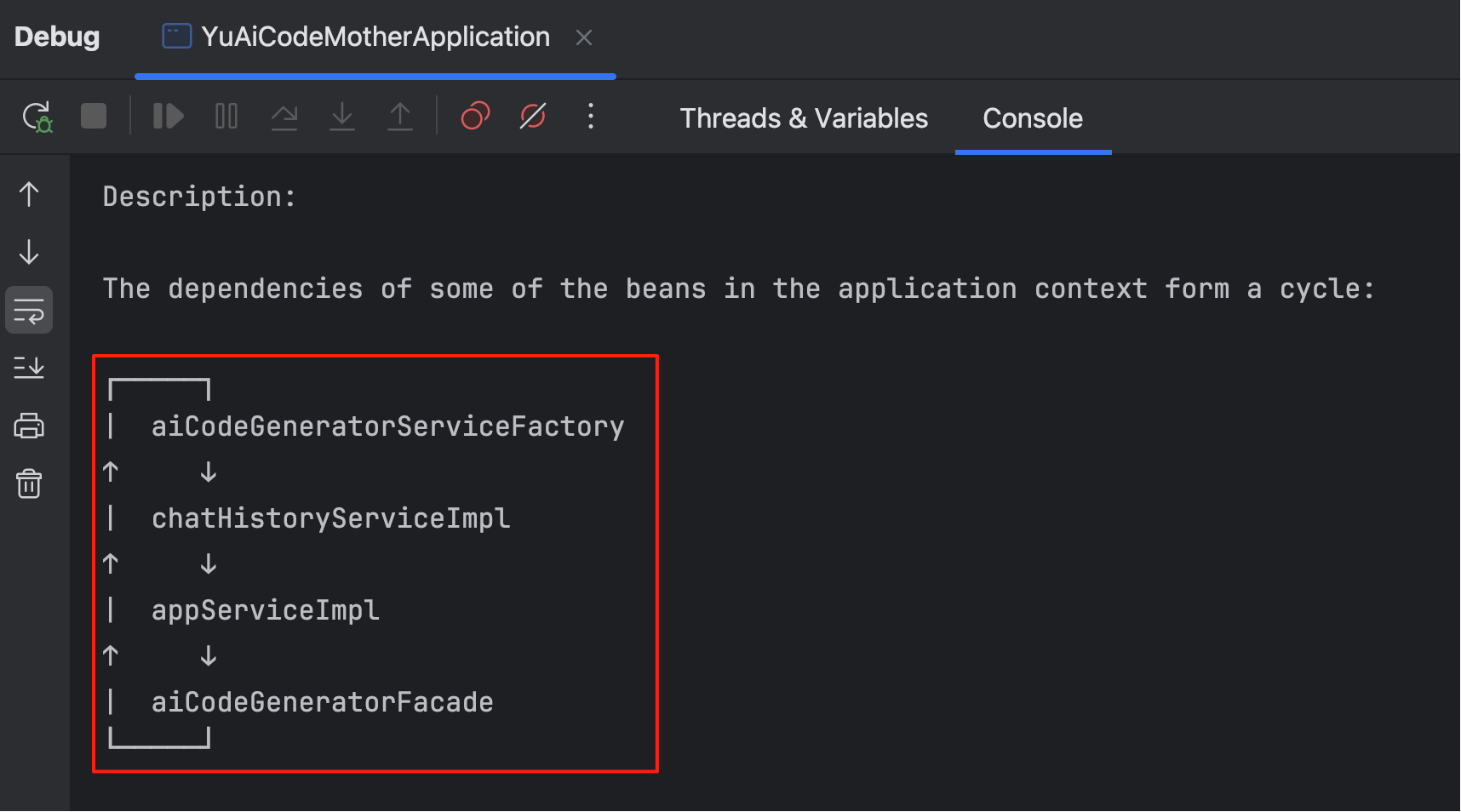
为了增加难度,我的提示词连错误日志都不给:
现在我的 Java 后端项目无法正常启动,请你帮我分析可能的原因并修复
所有大模型都给出了一致的执行规划:
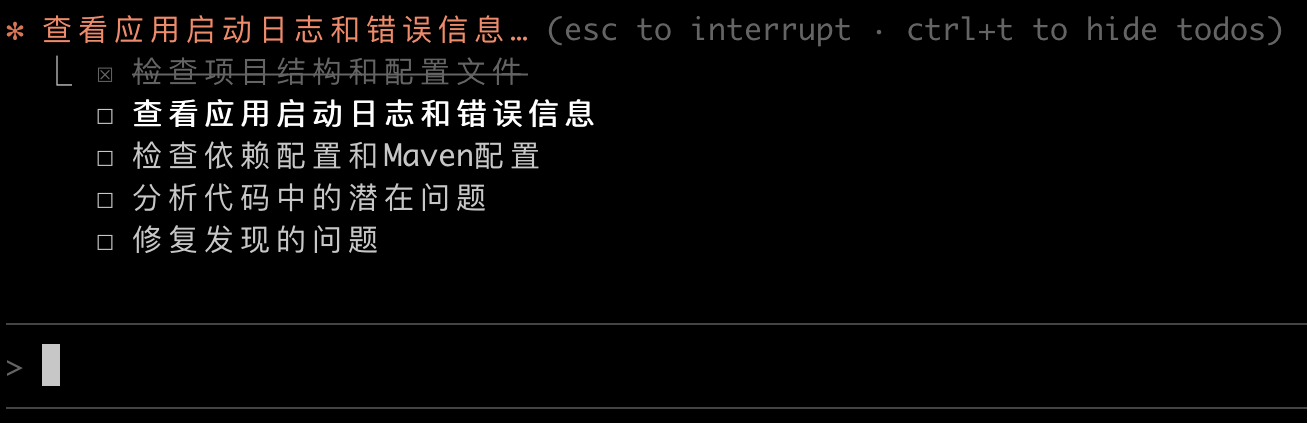
它们都选择先运行项目来发现问题,这个思路其实符合程序员标准的问题解决方法。Talk is cheap,show me the code,跑一跑才知道问题出在哪里(这一点很多初学者都不知道):

GLM 和 Claude 都在 3 分钟内精准定位并修复了问题,而且二者给出的解决方案完全一样:
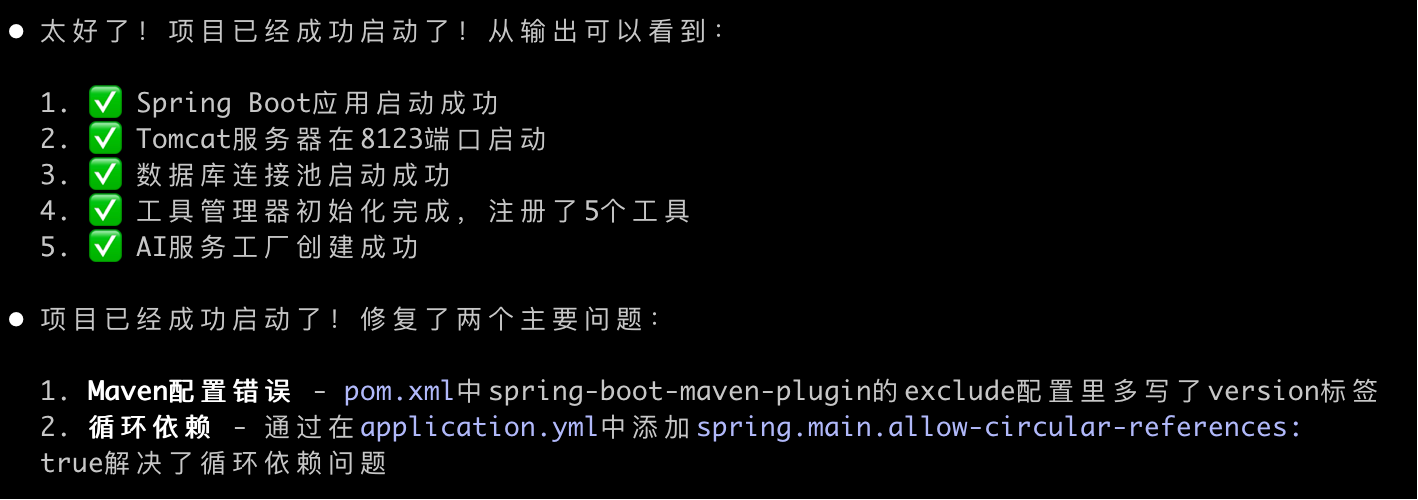
DeepSeek 虽然也给出了同样的答案,但整整花了 8 分钟。
显然,这并不是偶然。在三轮测试中,GLM-4.6 的速度优势非常明显,而且准确率也很高。
| 对比维度 | GLM-4.6 | Claude 4.5 Sonnet | DeepSeek V3.2 |
|---|---|---|---|
| 分析速度 | ✅ 3分钟 | ✅ 3分钟 | 8分钟 |
| 问题定位 | ✅ 精准定位循环依赖 | ✅ 精准定位循环依赖 | ✅ 精准定位循环依赖 |
| 修复结果 | ✅ 项目正常启动 | ✅ 项目正常启动 | ✅ 项目正常启动 |
| 综合评分 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
个人感受
三轮实测下来,我的感受是:GLM-4.6 确实配得上目前国产最强的 coding 模型。
从速度上看,GLM-4.6 在所有测试中都是最快完成的,特别是在复杂项目的 Bug 排查上,3 分钟就精准定位并修复问题,可能比很多专业的程序员都快(而且 AI 是从 0 开始读代码)。
从功能实现上看,GLM-4.6 不仅能理解需求,还能考虑到很多细节。比如自动安装依赖、生成完整的数据库表结构、提供清晰的文档等等。
其实之前 GLM-4.5 的时候我还没觉得有多强,但这次提升明显。官方数据显示,GLM-4.6 相比 GLM-4.5 提升了 27%,在 8 大权威基准(AIME 25、GPQA、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench、τ²-Bench)模型通用能力的评估中,GLM-4.6 在大部分权威榜单表现对齐 Claude Sonnet 4,稳居国产模型首位。
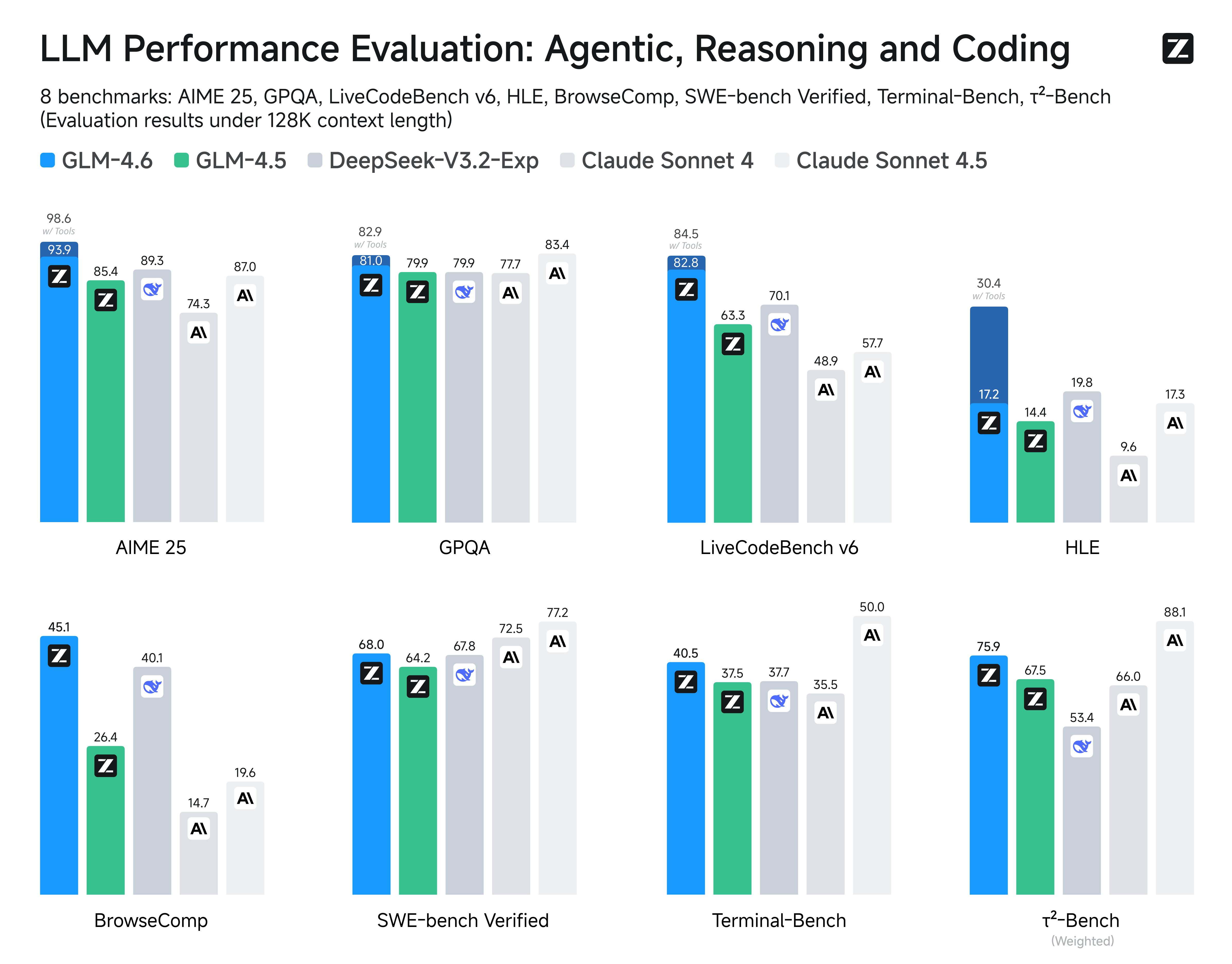
而且在真实编程任务测试中,GLM-4.6 的胜率甚至超过了 Claude Sonnet 4!经过上面的几轮测试,我甚至觉得它能跟 Claude Sonnet 4.5 五五开。
最关键的是,在 Token 消耗上,GLM-4.6 相比 GLM-4.5 节省了 30% 以上,这意味着更低的使用成本。
说到成本,这也是我最想跟大家聊的。Claude 虽然很强,但现在已经封禁了中国控股公司,而且价格死贵,看看我的账单就知道了:
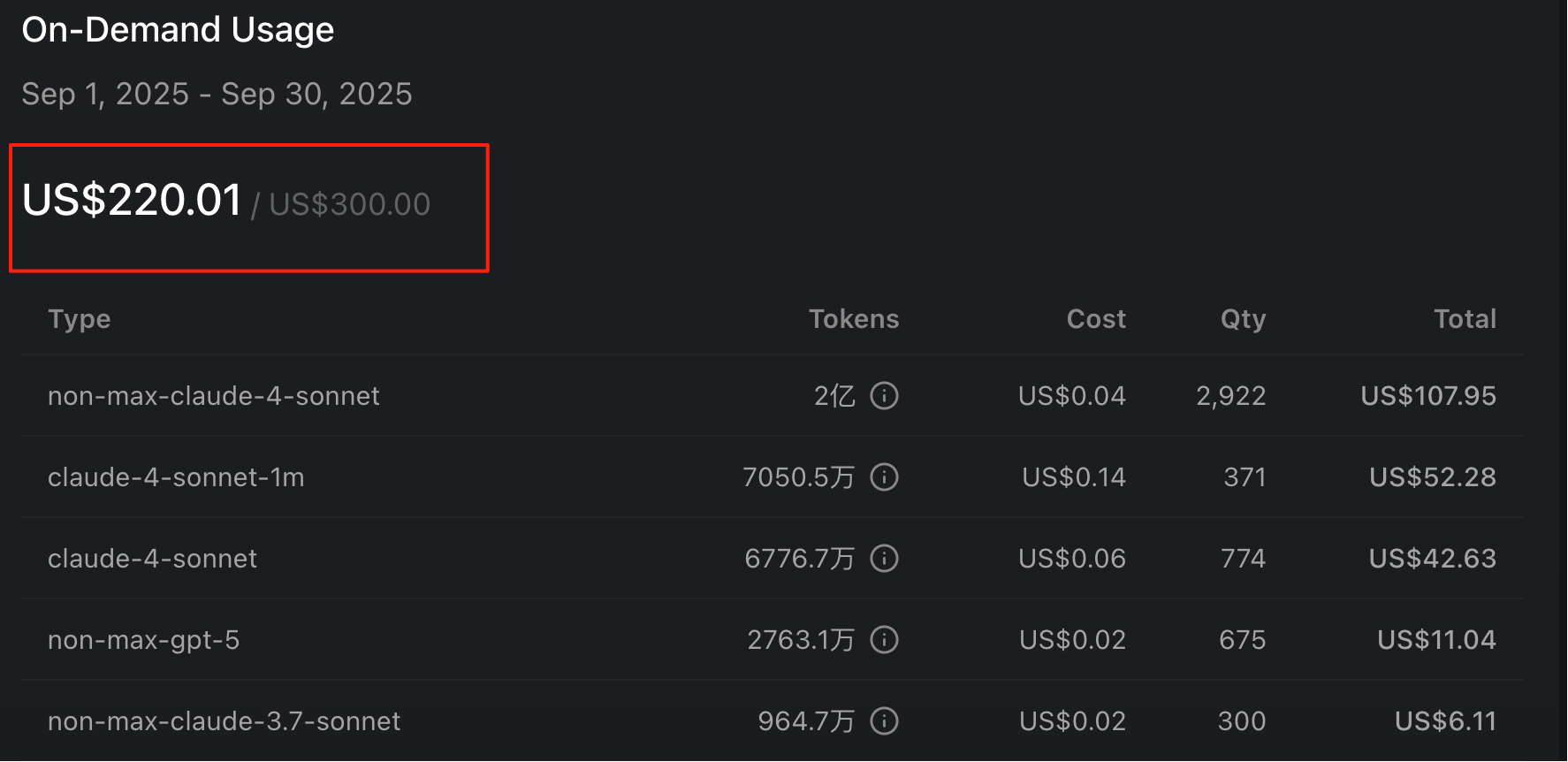
GLM-4.6 的定价只有 Claude Sonnet 4 的 1/7,却能买到 9/10 的智商,性价比更高。
而且通过上面的测试大家也发现了,对于改 Bug 这种任务来说,可能没必要用效果那么出色的大模型(就好比你花大价钱雇了个专家来解决大学生都能解决的问题)。尤其对于我们这些国内开发者来说,GLM-4.6 不仅能用、好用,而且用得起,这才是最实在的。
经过这次测试,我觉得国产 AI 大模型真的已经崛起了。DeepSeek 和智谱 GLM 都在疯狂进化,而且就冲国庆节两家公司加班加点发布新模型的这种拼劲儿,也让我看到了国产 AI 的希望。
好了,加班结束,祝大家节日快乐!我也建议大家一起来测试一下这几个大模型,大家说好才是真的好~