2015年DQN在Atari游戏上取得突破性进展,从此以后强化学习终于能处理复杂环境了,但没多久研究者就注意到一些奇怪的现象:
Q值会莫名其妙地增长到很大,智能体变得异常自信,坚信某些动作价值极高。实际跑起来却发现这些"黄金动作"根本靠不住,部分游戏的表现甚至开始崩盘。
问题出在哪?答案是DQN更新机制里隐藏的最大化偏差(maximization bias),这是个很微妙的统计学陷阱。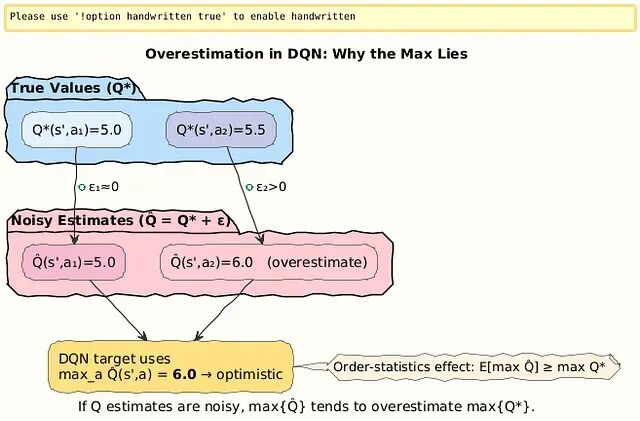
https://avoid.overfit.cn/post/e2a851720eb448f1a07d46808555496c