DDoS 攻击
DDoS 的前身是 DoS(Denail of Service),即拒绝服务攻击,指利用大量的合理请求, 来占用过多的目标资源,从而使目标服务无法响应正常请求。
DDoS(Distributed Denial of Service) 则是在 DoS 的基础上,采用了分布式架构,利用多台主机同时攻击目标主机。这样,即使目标服务部署了网络防御设备,面对大量网络请 求时,还是无力应对。
DDoS 类型
- 耗尽带宽。无论是服务器还是路由器、交换机等网络设备,带宽都有固定的上限。 带宽耗尽后,就会发生网络拥堵,从而无法传输其他正常的网络报文。
- 耗尽操作系统的资源。网络服务的正常运行,都需要一定的系统资源,像是 CPU、内存等物理资源,以及连接表等软件资源。一旦资源耗尽,系统就不能处理其他正 常的网络连接。
- 消耗应用程序的运行资源。应用程序的运行,通常还需要跟其他的资源或系统交互。如果应用程序一直忙于处理无效请求,也会导致正常请求的处理变慢,甚至得不到响 应。
构造大量不同的域名来攻击 DNS 服务器,就会导致 DNS 服务器不停执行迭代查询,并更新缓存。这会极大地消耗 DNS 服务器的资源,使 DNS 的响应变慢。
hping3 模拟攻击
hping3 可以构造 TCP/IP 协议数据包,对系统进行安全审计、防火墙测试、DoS 攻击测试等:
- Web 服务器;
- DoS 攻击,
- 正常的客户端
只使用了一台机器作为攻击源,实际上还是传统 的 DoS ,而非 DDoS。
-w 表示只输出 HTTP 状态码及总时间,-o 表示将响应重定向到 /dev/null
curl -s -w 'Http code: %{http_code}\nTotal time:%{time_total}s\n' -o /dev/null http://ip:port
运行 hping3 命令,来模拟 DoS 攻击:
-S 参数表示设置 TCP 协议的 SYN(同步序列号),
-p 表示目的端口为 80
-i u10 表示每隔 10 微秒发送一个网络帧
hping3 -S -p 80 -i u10 192.168.0.30
如果你的现象不那么明显,那么请尝试把参数里面的 u10 调小(比如调成 u1),或者加 上-flood 选项;
服务器使用 sar 检测请求情况以及tcpdump 抓包分析
sar -n DEV 1
既可以观察 PPS(每秒收发的报文数),还可以观察 BPS(每秒收发的字节 数)。
sar 的输出中,你可以看到,网络接收的 PPS 已经达到了 20000 多,但是 BPS 却 只有 1174 kB,这样每个包的大小就只有 54B(1174*1024/22274=54)。这明显就是个小包了,不过具体是个什么样的包呢?那我们就用 tcpdump 抓包:
-i eth0 只抓取 eth0 网卡,
-n 不解析协议名和主机名
tcp port 80 表示只抓取 tcp 协议并且端口号为 80 的网络帧
tcpdump -i eth0 -n tcp port 80
输出中,Flags [S] 表示这是一个 SYN 包。
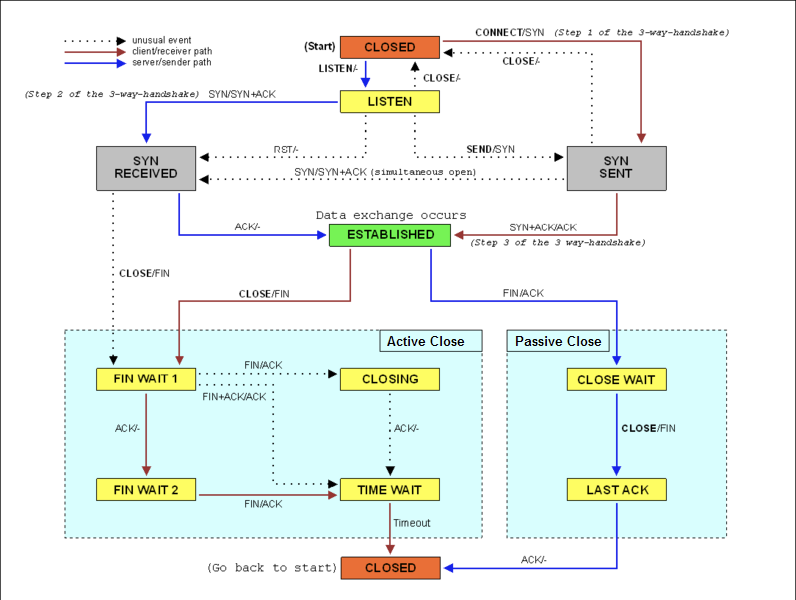
SYN 攻击
大量的 SYN 包表明,这是一个 SYN Flood 攻击。实际上,SYN Flood 正是互联网中最经典的 DDoS 攻击方式。客户端构造大量的 SYN 包,请求建立 TCP 连接;而服务器收到包后,会向源 IP 发送 SYN+ACK 报文,并等待三次握手的最后一次 ACK 报文,直到超时。

这种等待状态的 TCP 连接,通常也称为半开连接。
由于连接表的大小有限,大量的半开连接就会导致连接表迅速占满,从而无法建立新的 TCP 连接。
服务器端的 TCP 连接,会处于 SYN_RECEIVED 状态
使用 netstat ,来查看所有连接的状态,SYN_REVEIVED 的状态, 通常被缩写为 SYN_RECV。
-n 表示不解析名字,-p 表示显示连接所属进程
netstat -n -p | grep SYN_REC
从结果中,你可以发现大量 SYN_RECV 状态的连接,并且源 IP 地址为 192.168.0.2。
通过 wc 工具,来统计所有 SYN_RECV 状态的连接数:
netstat -n -p | grep SYN_REC | wc -l
解决 SYN 攻击
限制某个IP的SYN的包的速率
找出源 IP 后,要解决 SYN 攻击的问题,只要丢掉相关的包就可以。
iptables -I INPUT -s 192.168.0.2 -p tcp -j REJECT
以下两种方法,来限制 syn 包的速率:
限制 syn 并发数为每秒 1 次
iptables -A INPUT -p tcp --syn -m limit --limit 1/s -j ACCEPT
限制单个 IP 在 60 秒新建立的连接数为 10
iptables -I INPUT -p tcp --dport 80 --syn -m recent --name SYN_FLOOD --update --second
增加半连接的容量 tcp_max_syn_backlog
SYN Flood 会导致 SYN_RECV 状态的连接急剧增大。不过,半开状态的连接数是有限制的,执行下面的命令,你就可以看到,默认的半连接容量 只有 256:
sysctl net.ipv4.tcp_max_syn_backlog
net.ipv4.tcp_max_syn_backlog = 256
SYN 包数再稍微增大一些,就不能 SSH 登录机器了。 所以,你还应该增大半连接的容量
sysctl -w net.ipv4.tcp_max_syn_backlog=1024
减少SYNACK重试的重试次数
连接每个 SYN_RECV 时,如果失败的话,内核还会自动重试,并且默认的重试次数 是 5 次。你可以执行下面的命令,将其减小为 1 次:
sysctl -w net.ipv4.tcp_synack_retries=1
TCP SYN Cookies
SYN Cookies 基于连接信息(包括源地址、源端口、目的地址、目的端口等)以及一个加密种子(如系统 启动时间),计算出一个哈希值(SHA1),这个哈希值称为 cookie。这个 cookie 就被用作序列号,来应答 SYN+ACK 包,并释放连接状态。当客户端 发送完三次握手的最后一次 ACK 后,服务器就会再次计算这个哈希值,确认是上次返回的 SYN+ACK 的返回包,才会进入 TCP 的连接状态。
开启 SYN Cookies 后,就不需要维护半开连接状态了,进而也就没有了半连接数的 限制。内核选项 net.ipv4.tcp_max_syn_backlog 也就无效了。
sysctl -w net.ipv4.tcp_syncookies=1
重启后这些配置就会丢失。
写入 /etc/sysctl.conf 文件中
cat /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_max_syn_backlog = 1024
执行sysctl -p命令后,才会动态生效。
DDoS 防御
当 DDoS 报文到达服务器后,Linux 提供的机制只能缓解,而无法彻底解决。即使像是 SYN Flood 这样的小包攻击,其巨大的 PPS ,也会导致 Linux 内核消耗大量资 源,进而导致其他网络报文的处理缓慢。
- 跳过内核协议栈,来识别并丢弃 DDoS 报文,避免 DDoS 对系统其他资源的消耗。
- 在服务器外部的网络设备中,设法识别并阻断流量(当然前提是网络设备 要能扛住流量攻击)。比如,购置专业的入侵检测和防御设备,配置流量清洗设备阻断恶意 流量等。
- 因为 DDoS 并不一定是因为大流量或者大 PPS,有时候,慢速的请求也会带来巨大的性能下降(这种情况称为慢速 DDoS)。比如,很多针对应用程序的攻击,都会伪装成正常用户来请求资源。这种情况下,请求流量可能本身并不大,但响应流量却可能很大,并且应用程序内部也很可能要耗费大量资源处 理。需要应用程序考虑识别,并尽早拒绝掉这些恶意流量,比如合理利用缓存、增加 WAF(Web Application Firewall)、使用 CDN 等等。
网络延迟:B/S网络参数不合理
服务器端开启 TCP 的 Nagle 算法,而客户端却开启了延迟确认所导 致的。
网络数据传输所用的时间。可能是单向的,也可能是双向 的,往返全程所用的时间。更常用的是双向的往返通信延迟,比如 ping 测试的结果,就是往返延时 RTT(Round-Trip Time)。
应用程序延迟也指的是往返延迟,是网络数据传输时间加上数据处理时间的和。
无法使用ping怎么办
ping 基于 ICMP 协议,它通过计算 ICMP 回显响应报文与 ICMP 回显请求报文的时间差,来获得往返延时。不需要特殊认证,常被很多网络攻击利用,比如端口扫描工具 nmap、组包工具 hping3 等等。**为了避免这些问题,很多网络服务会把 ICMP 禁止掉,这也就导致我们无法用 ping **,来测试网络服务的可用性和往返延时。
可以用 traceroute 或 hping3 的 TCP 和 UDP 模式,来获取网络延迟。
-c 表示发送 3 次请求,-S 表示设置 TCP SYN,-p 表示端口号为 80
hping3 -c 3 -S -p 80 baidu.com
--tcp 表示使用 TCP 协议,-p 表示端口号,-n 表示不对结果中的 IP 地址执行反向域名解析
traceroute --tcp -p 80 -n baidu.com
traceroute 会在路由的每一跳发送三个包,并在收到响应后,输出往返延时。如果无响应 或者响应超时(默认 5s),就会输出一个星号。
案例
测试 80 端口延迟
hping3 -c 3 -S -p 80 192.168.0.30
测试 8080 端口延迟
hping3 -c 3 -S -p 8080 192.168.0.30
分别测试案例机器并发 100 时, 80 端口和 8080 端口的性能:
测试 80 端口性能
wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30/
测试 8080 端口性能
wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
抓包
案例 Nginx 在并发请求下的延迟增大了很多,使用 tcpdump 抓取收发的网络包,分析网络 的收发过程有没有问题。
tcpdump 命令,抓取 8080 端口上收发的网络包, 并保存到 nginx.pcap 文件:
tcpdump -nn tcp port 8080 -w nginx.pcap
wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
wireShark
用 Wireshark 打开,由于网络包的数量比较多,先过滤一下。在选择一个包后右键 并选择 “Follow” -> “TCP Stream”,然后,关闭弹出来的对话框,回到 Wireshark 主窗口。这时候,你会发现 Wireshark 已经 自动帮你设置了一个过滤表达式 tcp.stream eq 24,可以看到这个 TCP 连接从三次握手开始的每个请求和响应情况。点击菜单栏里的 Statics -> Flow Graph,选中 “Limit to display filter” 并设置 Flow type 为 “TCP Flows”:

图的左边是客户端,而右边是 Nginx 服务器。
为什么40S :ACK 延迟确认
通过这个图就可以看出,前面三次握手,以及第一次 HTTP 请求和响应还是挺快的,但第二次 HTTP 请求就比较慢了,特 别是客户端在收到服务器第一个分组后,40ms 后才发出了 ACK 响应(图中蓝色行)。**** 40ms 这个值实际上是 TCP 延迟确认(Delayed ACK)的最小超时时间。
延迟确认。针对 TCP ACK 的一种优化机制,不用每次请求 都发送一个 ACK,而是先等一会儿(比如 40ms),看看有没有“顺风车”。如果这段时 间内,正好有其他包需要发送,那就捎带着 ACK 一起发送过去。当然,如果一直等不到其 他包,那就超时后单独发送 ACK。40ms 发生在客户端上,是客户端wrk开启了延迟确认机制。 只有 TCP 套接字专门设置了 TCP_QUICKACK ,才会开启快速确认模式;否则,默认情况下,采用的就是延迟确认机制
用 strace ,来观察 wrk 为套接字设置 了哪些 TCP 选项。
strace -f wrk --latency -c 100 -t 2 --timeout 2 http://192.168.0.30:8080/
wrk 只设置了 TCP_NODELAY 选项,而没有设置 TCP_QUICKACK。 这说明 wrk 采用的正是延迟确认,也就解释了上面这个 40ms 的问题。
为什么第二个分组要等第一个ACK--Nagle 算法(纳格算法)
仔细观察 Wireshark 的界面,其中, 1173 号包,就是刚才说到的延迟 ACK 包;下一行的 1175 ,则是 Nginx 发送的第二个分组包,它跟 697 号包组合起来,构成一个完整的 HTTP 响应(ACK 号都是 85)。
第二个分组没跟前一个分组(697 号)一起发送,而是等到客户端对第一个分组的 ACK 后 (1173 号)才发送,只不过,这儿不再是 ACK,而是发送数 据。
Nagle 算法,是 TCP 协议中用于减少小包发送数量的一种优化算法,目的是为了提高实际 带宽的利用率。当有效负载只有 1 字节时,再加上 TCP 头部和 IP 头部分别占用的 20 字节,整个网络包就是 41 字节,这样实际带宽的利用率只有 2.4%(1/41)。往大了说,如果整个 网络带宽都被这种小包占满,那整个网络的有效利用率就太低了。 Nagle 算法正是为了解决这个问题。它通过合并 TCP 小包,提高网络带宽的利用率。 Nagle 算法规定,一个 TCP 连接上,最多只能有一个未被确认的未完成分组;在收到这个 分组的 ACK 前,不发送其他分组。****这些小分组会被组合起来,并在收到 ACK 后,用同一 个分组发送出去。
Linux 默认的延迟确认机制一起使用时,网络延迟会明显。当 Sever 发送了第一个分组后,由于 Client 开启了延迟确认,就需要等待 40ms 后才会 回复 ACK。 同时,由于 Server 端开启了 Nagle,而这时还没收到第一个分组的 ACK,Server 也会 在这里一直等着。直到 40ms 超时后,Client 才会回复 ACK,然后,Server 才会继续发送第二个分组。
禁用纳格算法:tcp_nodelay 开启
查询 tcp 的文档知道,只有设置了 TCP_NODELAY 后,Nagle 算法才会禁用。 Nginx 的 tcp_nodelay 选项
TCP_NODELAY
If set, disable the Nagle algorithm. This means that segments are always if there is only a small amount of data. When not set, data is buffered u amount to send out, thereby avoiding the frequent sending of small packe lization of the network. This option is overridden by TCP_CORK; however, explicit flush of pending output, even if TCP_CORK is currently set.
docker exec nginx cat /etc/nginx/nginx.conf | grep tcp_nodelay
tcp_nodelay off;
Nginx 的 tcp_nodelay 是关闭的,将其设置为 on ,应该就可以 解决了。测试的官方 Nginx 镜像是一样的(Nginx 默认 就是开启 tcp_nodelay 的) 。
由于 Nginx 不用再等 ACK,536 和 540 两个分组是连续发送的;客户端虽然仍开启了延迟确认,但这时收到了两个需要回复 ACK 的包,所以也不用等 40ms,可以直接合并回复 ACK。
流程总结
- 使用 hping3 以及 wrk 等工具,确认单次请求和并发请求情况的网络延迟是否正常。
- 使用 traceroute,确认路由是否正确,并查看路由中每一跳网关的延迟。
- 使用 tcpdump 和 Wireshark,确认网络包的收发是否正常。
- 使用 strace 等,观察应用程序对网络套接字的调用情况是否正常。
- 依次从路由、网络包的收发、再到应用程序等,逐层排查,直到定位问题根源。
网络请求吞吐量下降
案例复现
docker run --name nginx --network host --privileged -itd feisky/nginx-tp
docker run --name phpfpm --network host --privileged -itd feisky/php-fpm-tp
# 执行 wrk 命令,来测试 Nginx 的性能:
wrk --latency -c 1000 http://10.211.55.66
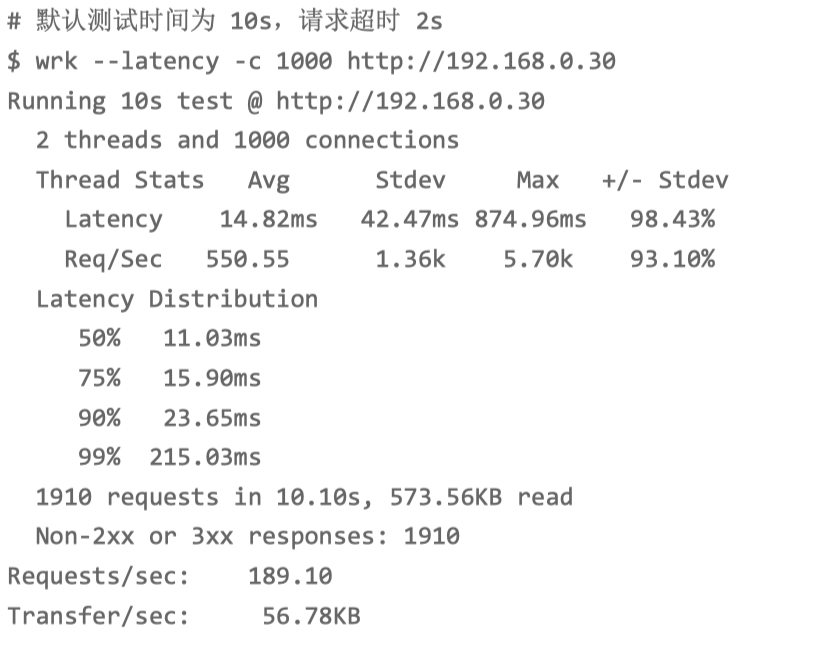
吞吐量(也就是每秒请求数)只有 189,并且所有 1910 个 请求收到的都是异常响应(非 2xx 或 3xx)。这些数据显然表明,吞吐量太低了,并且请 求处理都失败了。总共传输的数据量只有 573 KB,那就肯定不会是带宽受限导致的。所以,我们应该从请求数的角度来分析。从 TCP 连接数入手。
连接数优化--Docker 的NAT使用连接追踪管理。内核连接追踪数限制
总的测试时间延长到 30 分钟:
wrk --latency -c 1000 -d 1800 http://192.168.0.30
查看 TCP 连接数的汇总情况,
ss -s 2
wrk 并发 1000 请求时,建立连接数只有 5,而 closed 和 timewait 状态的 连接则有 1100 多
- 一个是建立连接数太少了;
- 另一个是 timewait 状态连接太多了。
- 内核中的连接跟踪模块,有可能会导致 timewait 问题。 Docker 使用的 iptables ,就会使用连接跟踪 模块来管理 NAT。那么,怎么确认是不是连接跟踪导致的问题呢?通过 dmesg 查看系统日志,如果有连接跟踪出了问题,应该会看到 nf_conntrack 相关的日志。
dmesg | tail - 从日志中,看到 nf_conntrack: table full, dropping packet 的错误日志。这说明, 正是连接跟踪导致的问题。连接跟踪数的最大限制 nf_conntrack_max ,以及当前的连接跟踪数 nf_conntrack_count
sysctl net.netfilter.nf_conntrack_maxsysctl net.netfilter.nf_conntrack_count- 看到最大的连接跟踪限制只有 200,并且全部被占用了。200 的限 制显然太小,将连接跟踪限制增大
sysctl -w net.netfilter.nf_conntrack_max=1048576- 10s 内的总请求数虽然增大到了 5 万, 但是有 4 万多响应异常,说白了,真正成功的只有 8000 多个(54221-45577=8644)。
- 内核中的连接跟踪模块,有可能会导致 timewait 问题。 Docker 使用的 iptables ,就会使用连接跟踪 模块来管理 NAT。那么,怎么确认是不是连接跟踪导致的问题呢?通过 dmesg 查看系统日志,如果有连接跟踪出了问题,应该会看到 nf_conntrack 相关的日志。
工作进程优化
由于这些响应并非 Socket error,说明 Nginx 已经收到了请求,只不过,响应的状态码并 不是我们期望的 2xx (表示成功)或 3xx(表示重定向)
docker logs nginx --tail 3
从 Nginx 的日志中,我们可以看到,响应状态码为 499。 499 并非标准的 HTTP 状态码,而是由 Nginx 扩展而来,表示服务器端还没来得及响应 时,客户端就已经关闭连接了。换句话说,问题在于服务器端处理太慢,客户端因为超时 (wrk 超时时间为 2s),主动断开了连接。
docker logs phpfpm --tail 5
两条警告信息,server reached max_children setting (5), 并建议增大 max_children。
max_children 表示 php-fpm 子进程的最大数量,当然是数值越大,可以同时处理的请求 数就越多。不过由于这是进程问题,数量增大,也会导致更多的内存和 CPU 占用。所以, 我们还不能设置得过大。
一般来说,每个 php-fpm 子进程可能会占用 20 MB 左右的内存。所以,你可以根据内存 和 CPU 个数,估算一个合理的值。虽然性能有所提升,可 4000 多的吞吐量显然还是比较差的,并且大部分请求的响应 依然还是异常。
套接字优化--进一步提升 Nginx 的吞吐量
Linux 协议栈的原理,我们可以从从套接字、TCP 协 议等逐层分析。而分析的第一步,自然还是要观察有没有发生丢包现象。
测试时间 30 分钟
wrk --latency -c 1000 -d 1800 http://192.168.0.30
只关注套接字统计
netstat -s | grep socket
稍等一会,再次运行
netstat -s | grep socket
根据两次统计结果中 socket overflowed 和 sockets dropped 的变化,有大 量的套接字丢包,并且丢包都是套接字队列溢出导致的。分析连接队列的大小是不是有异常。
队列长度的优化
查看套接字的队列大小
ss -ltnp

监听队列 (Send-Q)只有 10,而 nginx 的当前监 听队列长度 (Recv-Q)已经达到了最大值,php-fpm 也已经接近了最大值。很明显,套 接字监听队列的长度太小了,需要增大。
套接字监听队列长度的设置,既可以在应用程序中,通过套接字接口调整,也支持通过内核选项来配置。
查询 nginx 监听队列长度配置
docker exec nginx cat /etc/nginx/nginx.conf | grep backlog
查询 php-fpm 监听队列长度
docker exec phpfpm cat /opt/bitnami/php/etc/php-fpm.d/www.conf | grep backlog
somaxconn 是系统级套接字监听队列上限
sysctl net.core.somaxconn
从输出中可以看到,Nginx 和 somaxconn 的配置都是 10,而 php-fpm 的配置也只有 511,显然都太小了。
那么,优化方法就是增大这三个配置,比如,可以把 Nginx 和 phpfpm 的队列长度增大到 8192,而把 somaxconn 增大到 65536。
现在的吞吐量已经增大到了 6185,并且在测试的时候,如果你在终端一中重新执行 netstat -s | grep socket,还会发现,现在已经没有套接字丢包问题了。 不过,这次 Nginx 的响应,再一次全部失败了,都是 Non-2xx or 3xx。
docker logs nginx --tail 10
你可以看到,Nginx 报出了无法连接 fastcgi 的错误,错误消息是 Connect 时, Cannot assign requested address。这个错误消息对应的错误代码为 EADDRNOTAVAIL,表示 IP 地址或者端口号不可用。
端口号优化
客户端连接服务器端时,需要分配一个临时端口号,而 Nginx 正是 PHP-FPM 的客户端。端口号的范围并不是无限的,最多也只有 6 万多。
查询系统配置的临时端口号范围:
sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range=20000 20050
临时端口的范围只有 50 个,显然太小了 。
sysctl -w net.ipv4.ip_local_port_range="10000 65535"
这次,异常的响应少多了 ,不过,吞吐量也下降到了 3208。并且,这次还出现了很多 Socket read errors。显然,还得进一步优化。
火焰图
配置在优化网络的同时,却也会带来其他资源使用的上 升。这样来看,是不是说明其他资源遇到瓶颈了呢?
测试时间 30 分钟
wrk --latency -c 1000 -d 1800 http://192.168.0.30
从 top 的结果中可以看到,可用内存还是很充足的,但系统 CPU 使用率(sy)比较高,两 个 CPU 的系统 CPU 使用率都接近 50%,且空闲 CPU 使用率只有 2%。再看进程部分, CPU 主要被两个 Nginx 进程和两个 docker 相关的进程占用,使用率都是 30% 左右。
perf,火焰图,很容易就能找到系统中的热点函数。
我们保持终端二中的 wrk 继续运行;在终端一中,执行 perf 和 flamegraph 脚本,生成火 焰图:
执行 perf 记录事件
perf record -g
切换到 FlameGraph 安装路径执行下面的命令生成火焰图
perf script -i ~/perf.data | ./stackcollapse-perf.pl --all | ./flamegraph.pl > nginx.svg
使用浏览器打开生成的 nginx.svg ,应该从下往上、沿着调用栈中最宽的函数,来分析执行次数最多的函数。中间的 do_syscall_64、tcp_v4_connect、inet_hash_connect 这个堆栈,inet_hash_connect() 是 Linux 内核中负责分配临时端口号的函数。 所以,这个瓶颈应该还在临时端口的分配上。
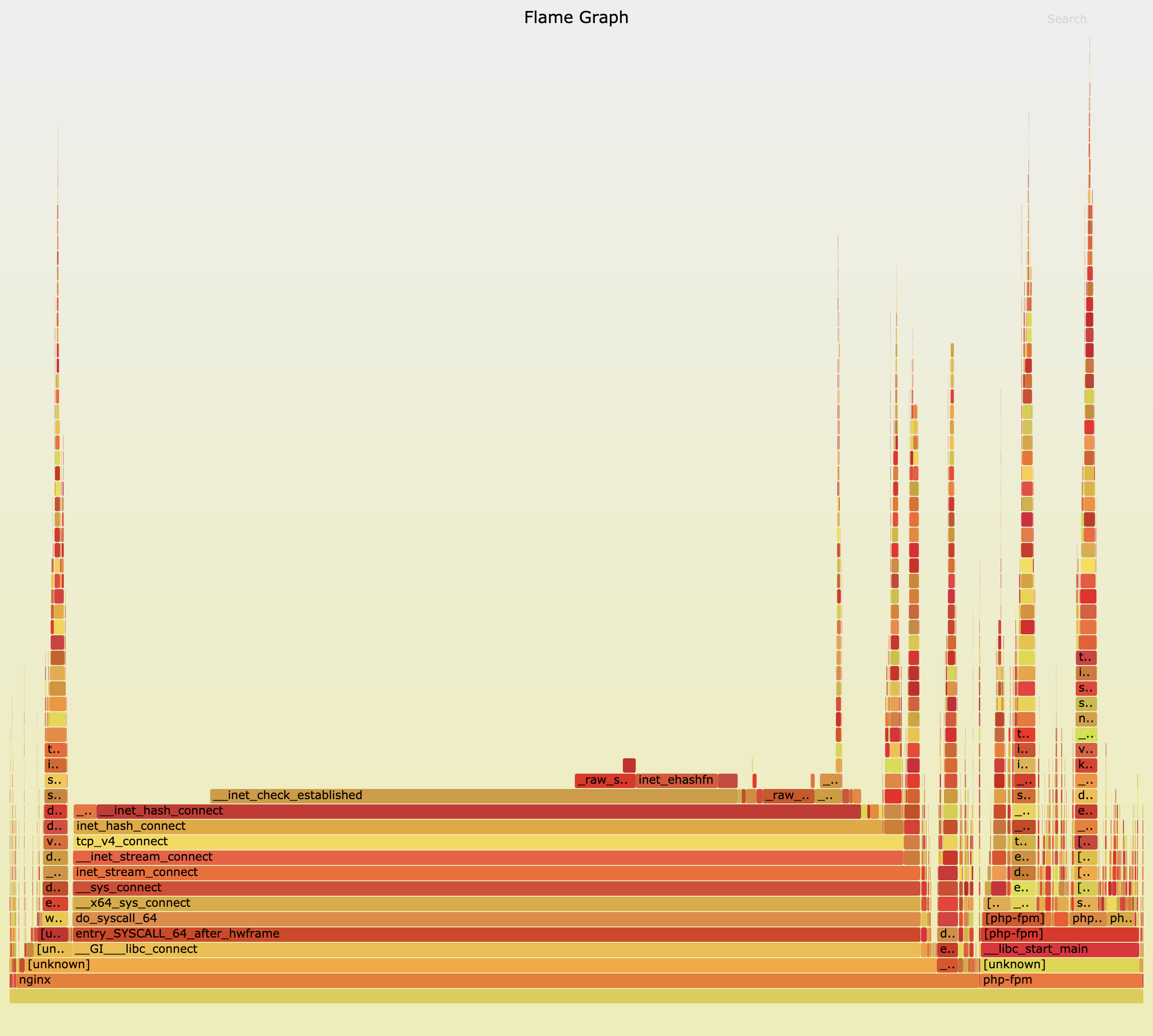
顺着 inet_hash_connect 往堆栈上面查看,下一个热点是 __init_check_established 函数。而 这个函数的目的,是检查端口号是否可用。
如果有大量连接 占用着端口,那么检查端口号可用的函数,不就会消耗更多的 CPU 吗?
ss -s

有大量连接(这儿是 32768)处于 timewait 状态,而 timewait 状态的连 接,本身会继续占用端口号。如果这些端口号可以重用,那么自然就可以缩短 __init_check_established 的过程。
sysctl net.ipv4.tcp_tw_reuse
tcp_tw_reuse 是 0,也就是禁止状态。为什么临时端口号的分配会是系统运行的热点了.。设置为1
现在的吞吐量已经达到了 5000 多,并且只有少量的 Socket errors,也不再有 Non-2xx or 3xx 的响应了。说明一切终于正常了。
总结
- 首先,利用各种性能工具,收集想要的性能指标,从而清楚系统和应用程序的运行状态;
- 其次,拿目前状态跟系统原理进行比较,不一致的地方,就是我们要重点分析的对象。
- 从这个角度出发,再进一步借助 perf、火焰图、bcc 等动态追踪工具,找出热点函数,就 可以定位瓶颈的来源,确定相应的优化方法。
NAT延迟
网络地址转换(Network Address Translation)
NAT 原理
NAT 技术可以重写 IP 数据包的源 IP 或者目的 IP,被普遍地用来解决公网 IP 地址短缺的 问题。
网络中的多台主机,通过共享同一个公网 IP 地址,来访问外网资源。同时,由于 NAT 屏蔽了内网网络,自然也就为局域网中的机器提供了安全隔离。
- 在支持网络地址转换的路由器(称为 NAT 网关)中配置 NAT
- 在 Linux 服务器中配置 NAT,Linux 服务器实际上充当的是“软”路由器的 角色。
NAT 实现方式:
- 静态 NAT,即内网 IP 与公网 IP 是一对一的永久映射关系;
- 动态 NAT,即内网 IP 从公网 IP 池中,动态选择一个进行映射;
- 网络地址端口转换 NAPT(Network Address and Port Translation),即把内网 IP 映射到公网 IP 的不同端口上,让多个内网 IP 可以共享同一个公网 IP 地址。在 Linux 中配置的 NAT 也是这种类型。根据转 换方式的不同,把 NAPT 分为三类。
- 源地址转换 SNAT,即目的地址不变,只替换源 IP 或源端口。SNAT 主要用于,多个内网 IP 共享同一个公网 IP ,来访问外网资源的场景。
- 目的地址转换 DNAT,即源 IP 保持不变,只替换目的 IP 或者目的端口。DNAT 主要通过公网 IP 的不同端口号,来访问内网的多种服务,同时会隐藏后端服务器的真实 IP 地址。
- 双向地址转换,即同时使用 SNAT 和 DNAT。当接收到网络包时,执行 DNAT, 把目的 IP 转换为内网 IP;而在发送网络包时,执行 SNAT,把源 IP 替换为外部 IP。 双向地址转换,其实就是外网 IP 与内网 IP 的一对一映射关系,所以常用在虚拟化环境中, 为虚拟机分配浮动的公网 IP 地址。
Linux 中NAT
Linux 内核提供的 Netfilter 框架,允许对网络数据包进行修改(比如 NAT)和过滤(比如 防火墙)。在这个基础上,iptables、ip6tables、ebtables 等工具,又提供了更易用的命令行接口,以便系统管理员配置和管理 NAT、防火墙的规则。
数据包通过 Netfilter 时的工作流向:
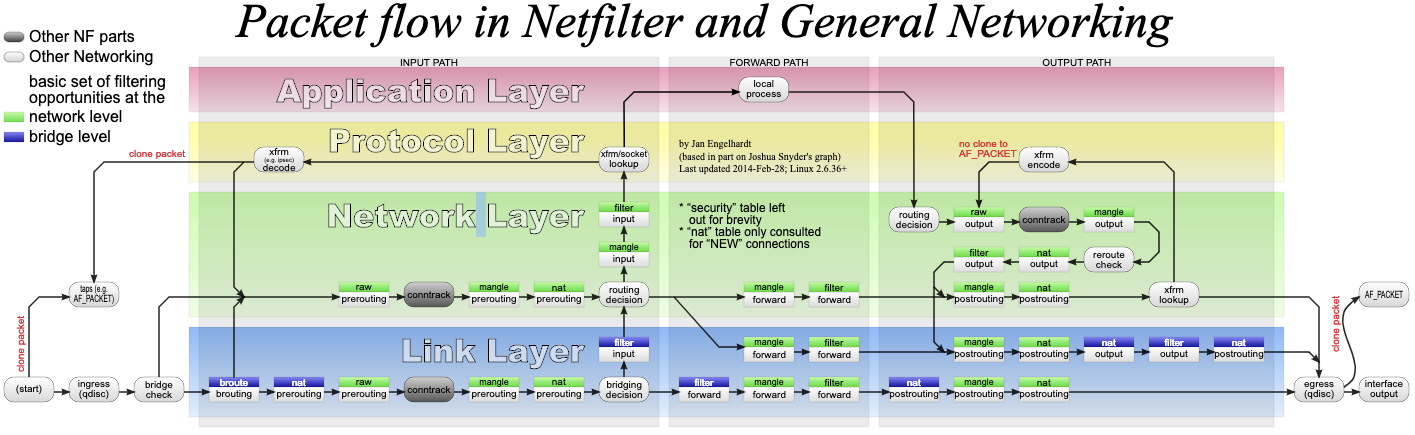
绿色背景的方框,表示表(table),用来管理链。Linux 支持 4 种表,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原 始数据包)等。
跟 table 一起的白色背景方框,则表示链(chain),用来管理具体的 iptables 规则。每个 表中可以包含多条链,比如:filter 表中,内置 INPUT、OUTPUT 和 FORWARD 链;nat 表中,内置 PREROUTING、POSTROUTING、OUTPUT 等。 当然,你也可以根据需要,创建你自己的链。
灰色的 conntrack,表示连接跟踪模块。它通过内核中的连接跟踪表(也就是哈希表), 记录网络连接的状态,是 iptables 状态过滤(-m state)和 NAT 的实现基础。
iptables 的所有规则,就会放到这些表和链中,并按照图中顺序和规则的优先级顺序来执 行。
要实现 NAT 功能,主要是在 nat 表进行操作。而 nat 表内置了三个链:
- PREROUTING,用于路由判断前所执行的规则,比如,对接收到的数据包进行 DNAT。
- POSTROUTING,用于路由判断后所执行的规则,比如,对发送或转发的数据包进行 SNAT 或 MASQUERADE。
- OUTPUT,类似于 PREROUTING,但只处理从本机发送出去的包。
配置 源地址转换 SNAT
SNAT 需要在 nat 表的 POSTROUTING 链中配置。
- 第一种方法,是为一个子网统一配置 SNAT,并由 Linux 选择默认的出口 IP。这实际上就 是经常说的 MASQUERADE:
iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE
- 第二种方法,是为具体的 IP 地址配置 SNAT,并指定转换后的源地址:
iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100 DNAT
配置 目的地址转换 DNAT
DNAT 需要在 nat 表的 PREROUTING 或者 OUTPUT 链中配置, 其中, PREROUTING 链更常用一些(因为它还可以用于转发的包)。
iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
配置 双向地址转换
双向地址转换,就是同时添加 SNAT 和 DNAT 规则,为公网 IP 和内网 IP 实现一对一的映 射关系,即:
iptables -t nat -A POSTROUTING -s 192.168.0.2 -j SNAT --to-source 100.100.100.100 2 $ iptables -t nat -A PREROUTING -d 100.100.100.100 -j DNAT --to-destination 192.168.0.2
在使用 iptables 配置 NAT 规则时,Linux 需要转发来自其他 IP 的网络包,所以你千万不 要忘记开启 Linux 的 IP 转发功能。
查看这一功能是否开启。如果输出的结果是 1,就表示已经开启了 IP 转发:
sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
手动开启:
sysctl -w net.ipv4.ip_forward=1
写入 /etc/sysctl.conf 文件中:
cat /etc/sysctl.conf | grep ip_forward
Linux 中的 NAT ,基于内核的连接跟踪模块实现。它维护每个连接状态的同时,也会带来很高的性能成本。
案例
SystemTap 是 Linux 的一种动态追踪框架,它把用户提供的脚本,转换为内核模块来执行,用来监测和跟踪内核的行为
yum install systemtap kernel-devel yum-utils kernel
stab-prep
基准指标:ab测试不用 NAT 的 Nginx 服务
在终端一中,执行下面的命令,启动 Nginx,注意选项 --network=host ,表示容器使用 Host 网络模式,即不使用 NAT:
docker run --name nginx-hostnet --privileged --network=host -itd feisky/nginx:80
ab 命令,对 Nginx 进行压力测试
Linux 默认允许打开的文件描述数比较小:1024
ulimit -n
临时增大当前会话的最大文件描述符数
ulimit -n 65536
-c 表示并发请求数为 5000,-n 表示总的请求数为 10 万
-r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s
ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/
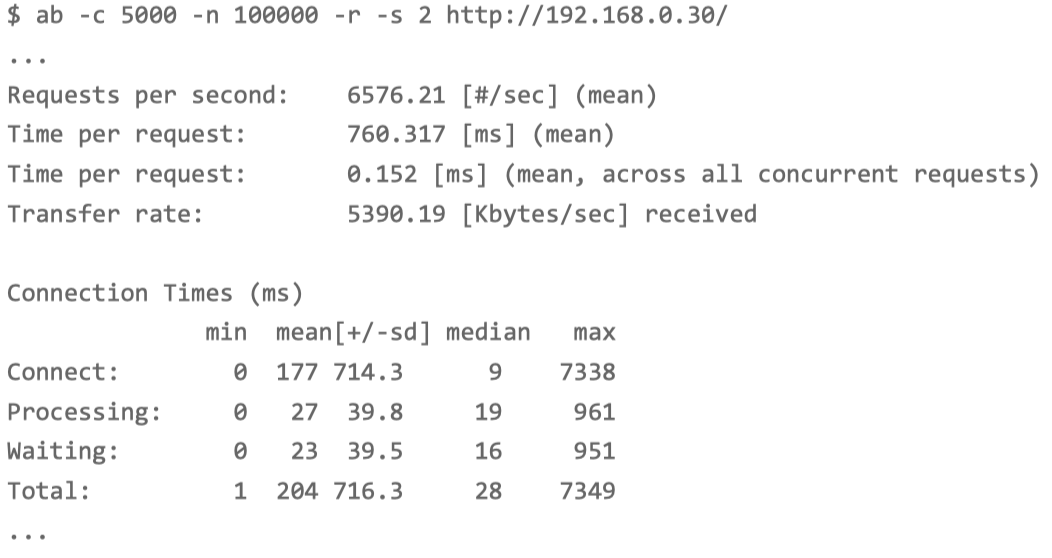
每秒请求数(Requests per second)为 6576; 每个请求的平均延迟(Time per request)为 760ms; 建立连接的平均延迟(Connect)为 177ms。
使用 DNAT
docker run --name nginx --privileged -p 8080:8080 -itd feisky/nginx:nat
iptables -nL -t nat

在 PREROUTING 链中,目的为本地的请求,会转到 DOCKER 链;而在 DOCKER 链中,目的端口为 8080 的 tcp 请求,会被 DNAT 到 172.17.0.2 的 8080 端 口。其中,172.17.0.2 就是 Nginx 容器的 IP 地址。
-c 表示并发请求数为 5000,-n 表示总的请求数为 10 万
-r 表示套接字接收错误时仍然继续执行,-s 表示设置每个请求的超时时间为 2s
ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/
设置了每个请求的超时时间为 2s,这次只完成了 5602 个请求。延长到 30s。延迟增大意味着要等更长时间,同时把总测试次数,也减少到 10000:
ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
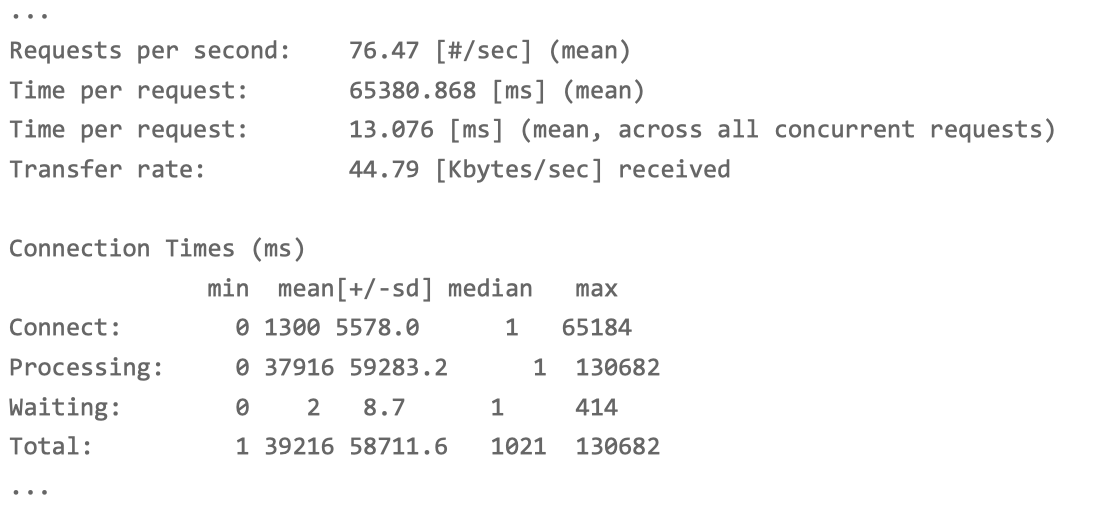
每秒请求数(Requests per second)为 76;
每个请求的延迟(Time per request)为 65s; 建立连接的延迟(Connect)为 1300ms。
显然,每个指标都比前面差了很多。
SystemTap 编译内核脚本 检测NAT出问题的位置
使用 tcpdump 抓包的方法,找出延迟增大的根源。
换个思路,Netfilter 中,网络包的流向以及 NAT 的原理,要保证 NAT 正常工 作,就至少需要两个步骤:
- 第一,利用 Netfilter 中的钩子函数(Hook),修改源地址或者目的地址。
- 第二,利用连接跟踪模块 conntrack ,关联同一个连接的请求和响应。
是不是这两个地方出现了问题呢?我们用前面提到的动态追踪工具 SystemTap 来试试。在压测场景下,并发请求数大大降低,并且我们清楚知道 NAT 是罪魁祸 首。所以有理由怀疑,内核中发生了丢包现象。
服务器创建一个 dropwatch.stp 的脚本文件,并写入下面的内容:
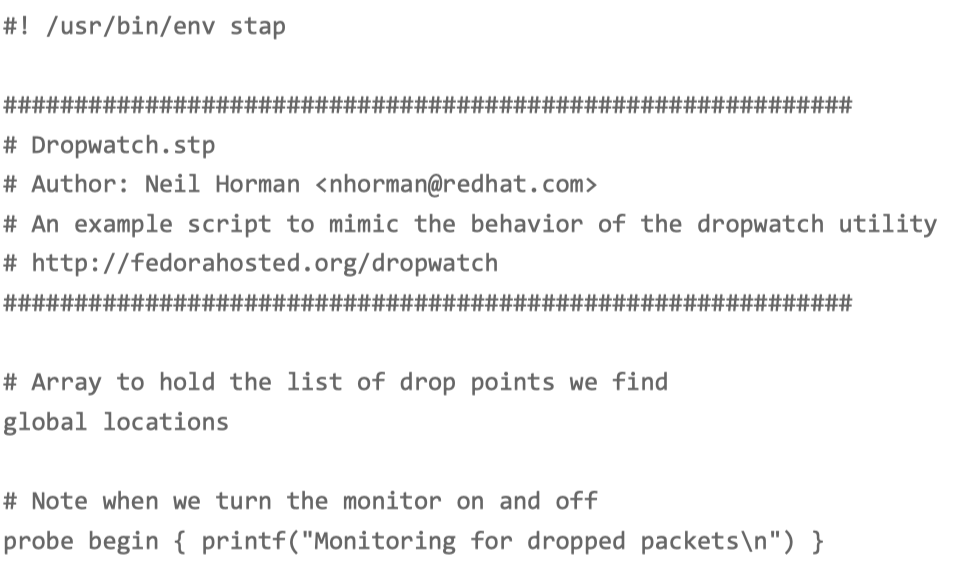

这个脚本,跟踪内核函数 kfree_skb() 的调用,并统计丢包的位置。文件保存好后,执行下 面的 stap 命令,就可以运行丢包跟踪脚本。这里的 stap,是 SystemTap 的命令行工具:
stap --all-modules dropwatch.stp
Monitoring for dropped packets
当你看到 probe begin 输出的 “Monitoring for dropped packets” 时,表明 SystemTap 已经将脚本编译为内核模块,并启动运行了。
再次执行 ab 命令,观察 stap 命令的输出:

大量丢包都发生在 nf_hook_slow 位置。这是 在 Netfilter Hook 的钩子函数中,出现丢包问题了。但是不是 NAT,还不能确定
perf 检测是否是NAT的调用
再跟踪 nf_hook_slow 的执行过程,这一步可以通过 perf 来完成。
记录一会(比如 30s)后按 Ctrl+C 结束
perf record -a -g -- sleep 30
perf report -g graph,0
在 perf report 界面中,输入查找命令 / 然后,在弹出的对话框中,输入 nf_hook_slow; 最后再展开调用栈,就可以得到下面这个调用图: 从这个图我们可以看到,nf_hook_slow 调用最多的有三个地方,分别是 ipv4_conntrack_in、br_nf_pre_routing 以及 iptable_nat_ipv4_in。换言之, nf_hook_slow 主要在执行三个动作。
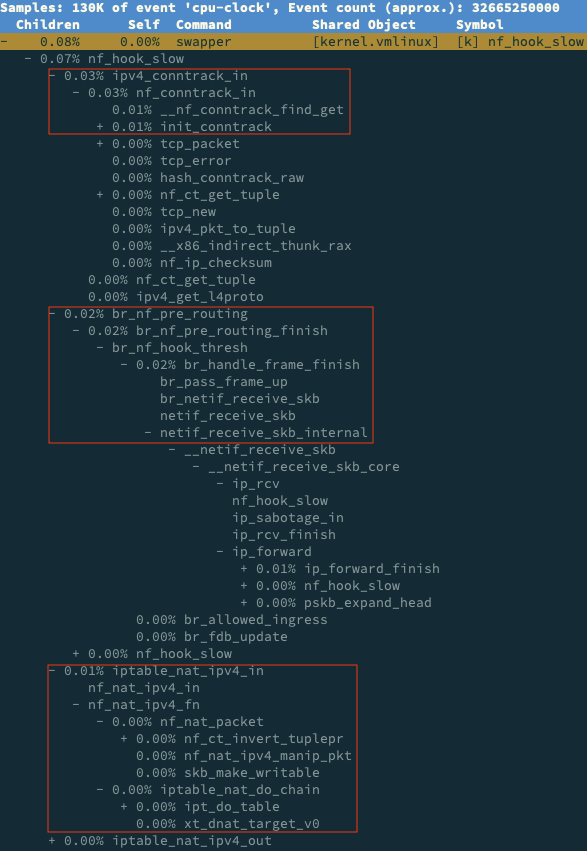
第一,接收网络包时,在连接跟踪表中查找连接,并为新的连接分配跟踪对象 (Bucket)。
第二,在 Linux 网桥中转发包。这是因为案例 Nginx 是一个 Docker 容器,而容器的网 络通过网桥来实现;
第三,接收网络包时,执行 DNAT,即把 8080 端口收到的包转发给容器。
连接跟踪表 conntrack 内核参数优化
到这里,我们其实就找到了性能下降的三个来源。这三个来源,都是 Linux 的内核机制, 所以接下来的优化,自然也是要从内核入手。
DNAT 的基础是 conntrack,所以我们可以先看看, 内核提供了哪些 conntrack 的配置选项。
sysctl -a | grep conntrack

net.netfilter.nf_conntrack_count,表示当前连接跟踪数;
net.netfilter.nf_conntrack_max,表示最大连接跟踪数;
net.netfilter.nf_conntrack_buckets,表示连接跟踪表的大小。
当前连接跟踪数是 180,最大连接跟踪数是 1000,连接跟踪表 的大小,则是 65536。
ab 命令,并发请求数是 5000,而请求数是 100000。跟踪表设置成1000 个连接,是远远不够的。
内核在工作异常时,会把异常信息记录到日志中。比如前面的 ab 测试,内核已经 在日志中报出了 “nf_conntrack: table full” 的错误。
dmesg 命令查看内核异常

net_ratelimit 表示有大量的日志被压缩掉了,这是内核预防日志攻击的一种措施。
“nf_conntrack: table full” 表明 nf_conntrack_max 太小了。
连接跟踪表,实际上 是内存中的一个哈希表。如果连接跟踪数过大,也会耗费大量内存。
nf_conntrack_buckets,就是哈希表的大小。哈希表中的每一项,都是一个链表(称为 Bucket),而链表长度,就等于 nf_conntrack_max 除以 nf_conntrack_buckets。
估算 连接跟踪表占用的内存大小:
连接跟踪对象大小为 376,链表项大小为 16
nf_conntrack_max* 连接跟踪对象大小 +nf_conntrack_buckets* 链表项大小= 1000376+6553616 B = 1.4 MB
修改内核参数
将 nf_conntrack_max 改大一些,比如改成 131072(即 nf_conntrack_buckets 的 2 倍):
sysctl -w net.netfilter.nf_conntrack_max=131072
sysctl -w net.netfilter.nf_conntrack_buckets=65536
已经基本正常
用 conntrack 查看连接跟踪表的内容

连接跟踪表里的对象,包括了协议、连接状态、源 IP、源端口、目的 IP、目的端口、跟踪状态等。由于这个格式是固定的,所以我们可以用 awk、sort 等工 具,对其进行统计分析。
大部分 TCP 的连接跟踪,都处于 TIME_WAIT 状态,并且它们大都来自 于 192.168.0.2 这个 IP 地址(也就是运行 ab 命令的 VM2)。 这些处于 TIME_WAIT 的连接跟踪记录,会在超时后清理,而默认的超时时间是 120s。所以,如果你的连接数非常大,确实也应该考虑,适当减小超时时间。
总结排查和优化 NAT 带来的性能问题
由于 NAT 基于 Linux 内核的连接跟踪机制来实现。可以先从 conntrack 角度来分析,比如用 systemtap、perf 等,分析内核中 conntrack 的行文;然后,通过调整 netfilter 内核选项的参数,来进行优化。
Linux 通过连接跟踪机制实现的 NAT,也常被称为有状态的 NAT,而维护状态,也带来了很高的性能成本。
除了调整内核行为外,在不需要状态跟踪的场景下(比如只需要按预定的 IP 和端口 进行映射,而不需要动态映射),也可以使用无状态的 NAT (比如用 tc 或基于 DPDK 开发),来进一步提升性能。