新手入门,不在于“掌握多种”大模型,而在于“掌握一类”大模型的用法,并理解其背后的原理。
你不需要像背单词一样去学习几十种模型,关键在于建立正确的认知和方法论。下图清晰地展示了你的学习路径与目标:
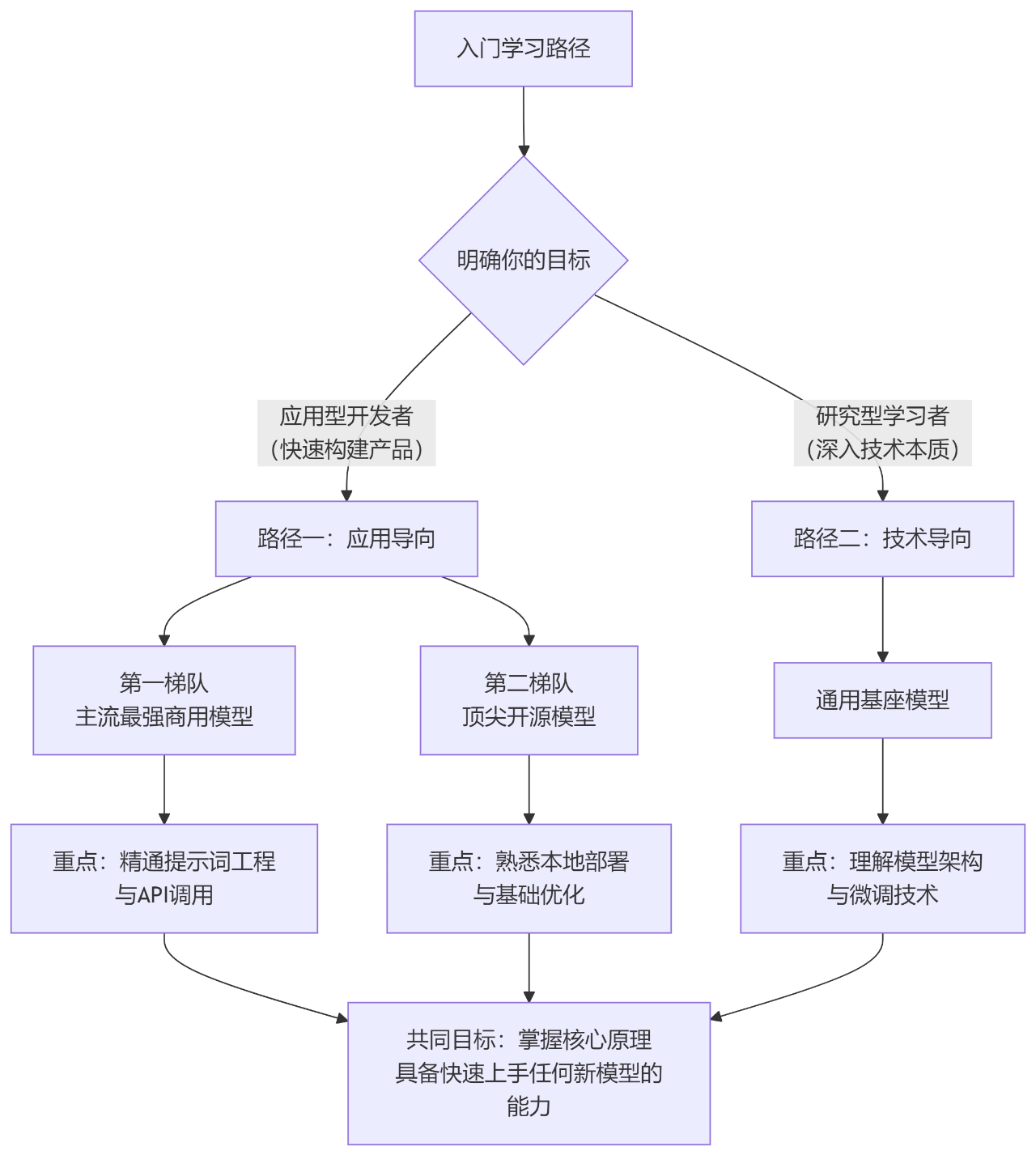
接下来,我们为你详细拆解这张学习地图。
核心原则:模型是工具,思维是关键
你的目标不是成为“模型博物馆的馆长”,而是成为“会选用最合适工具的木匠”。你需要培养的是:
通用技能: 提示词工程、思维链、Function Calling等技能,在所有模型上是相通的。
评估能力: 学会判断一个模型在特定任务上的能力强弱。
快速上手能力: 知道如何快速查阅文档,测试一个陌生模型的基本能力。
你的学习路径:由目标决定
你需要接触的模型类型和数量,完全取决于你的目标。
路径一:如果你想成为“应用型开发者”(快速构建AI应用)
你的重点是使用模型,而不是创造模型。建议你深入接触2个梯队的模型即可:
第一梯队:主流闭源/商用模型(选1-2个)
代表: OpenAI的GPT-4o/GPT-3.5-Turbo、Anthropic的Claude 3(如Sonnet)、Google的Gemini 1.5 Pro。
为什么: 它们是当前能力的顶峰,非常智能和可靠。通过它们的API,你可以构建出最强大的应用。
怎么做:精通其中一个的API调用和提示词编写。比如,深入研究OpenAI的ChatCompletions API的各种参数,知道如何用System Prompt精确控制模型行为。这个技能可以轻松迁移到其他闭源模型上。
第二梯队:顶尖开源模型(选1个系列)
代表:Llama 3 系列(Meta发布)、Qwen 2 系列(阿里发布)。
为什么:
免费可商用: 可以免费下载,在自有服务器上部署。
数据隐私: 数据完全掌握在自己手中。
可定制: 可以进行微调,适应特定业务。
怎么做:选择一个系列(如Llama 3),学习如何在本地用Ollama或vLLM等工具运行它,体验其能力边界。了解不同参数规模(如8B、70B)的区别。
对于应用开发者,掌握“1个闭源模型” + “1个开源模型系列”已经完全足够让你起步并构建出优秀应用。
路径二:如果你想成为“研究型学习者”(深入技术本质)
你的目标是理解模型如何工作,未来可能参与微调甚至训练。那么你需要接触的是:
“基座模型”的概念
代表: Llama 3、Qwen 2、ChatGLM-4、Baichuan。
为什么: 你需要理解什么是“预训练”得到的“基座模型”,以及如何通过“指令微调”和“人类反馈强化学习”将其变成能对话的“聊天模型”。
怎么做: 不需要掌握每一个,但应该选择一个开源系列(如Llama 3)作为你的学习样板。深入理解它的技术报告、Tokenizer、模型结构(如Transformer的变体)。尝试用Hugging Face Transformers库加载它的基座模型和聊天模型,比较两者的区别。
少即是多,深度优于广度
给新手的最终建议:
不要贪多! 不要试图同时学习GPT-4、Claude、Gemini、Llama、Qwen……这会让你精力分散,无法深入。
聚焦一个,触类旁通:
首选推荐: 从 OpenAI的GPT API 开始,因为它生态最完善、文档最友好。彻底掌握它。
然后: 用 Ollama 在本地跑通 Llama 3 8B 模型,体验开源模型。
关注抽象层框架: 学习 LangChain/LlamaIndex 这样的框架,它们的设计理念就是让你用一套代码轻松切换不同的模型。当你用LangChain写应用时,从一个模型切换到另一个模型,可能只需要修改一行配置。
记住,你的目标是学会“开车”,而不是学会修理世界上所有品牌的发动机。先开好一辆车,你就能很快上手其他车。
人工智能测试开发技术学习交流群

推荐学习
行业首个「知识图谱+测试开发」深度整合课程【人工智能测试开发训练营】,赠送智能体工具。提供企业级解决方案,人工智能的管理平台部署,实现智能化测试,落地大模型,实现从传统手工转向用AI和自动化来实现测试,提升效率和质量。
