Text-to-SQL模型能够将自然语言问题转换为可执行的 SQL 语句,让用户更便捷地与数据库交互。尽管目前该技术在较简单的数据库和问题上已取得一定成效,但现有Text-to- SQL 方法在工业级数据库以及涉及特定领域业务逻辑的复杂问题上,执行准确率仍有待提高。本文提出 PaVeRL - SQL 框架,该框架结合部分匹配奖励(Partial - Match Rewards)与语言强化学习(Verbal Reinforcement Learning),推动推理语言模型(Reasoning Language Models, RLMs)在Text-to-SQL 任务中实现自我优化。为满足实际应用场景需求,我们设计了两条技术流程:(1)一种新的、带有组内自我评估(语言强化学习)的上下文学习框架,以性能优异的开源和闭源大型语言模型(Large Language Models, LLMs)为基础模型;(2)基于小基础模型(OmniSQL - 7B)的思维链(Chain - of - Thought, CoT)强化学习流程,该模型通过特定设计的奖励函数和两阶段强化学习进行训练。这两条流程在主流Text-to-SQL 基准测试集 ——Spider、Spider 2.0 和 BIRD 上均取得了当前最优(State - of - the - Art, SOTA)的结果。在工业级基准测试集 Spider 2.0 - SQLite 上,语言强化学习流程的执行准确率比现有最优结果高出 7.4%,思维链流程则高出 1.4%。使用混合 SQL 方言进行强化学习训练,尤其对于训练数据有限的方言,能带来显著提升,准确率可达原来的 3 倍。总体而言,在实际工业环境约束下,PaVeRL - SQL 为Text-to-SQL 任务提供了可靠且性能最优的解决方案。相关代码可在https://github.com/PaVeRL-SQL/PaVeRL-SQL 获取。
结构化查询语言(Structured Query Language, SQL)是操作关系型数据的通用接口。Text-to-SQL 模型能将自然语言问题转化为可执行的 SQL 语句,使非专业人员也能查询复杂数据库。随着各行业中大型异构数据库模式不断增多,且 SQL 方言存在差异,可靠的Text-to-SQL 系统的潜在应用价值持续提升。近年来,相关系统通过结构偏差与解码约束(如 RAT - SQL、PICARD)或提示词 / 工作流设计(如 DIN - SQL、CHESS)等方式,推动该技术不断发展。
尽管在 Spider、BIRD 等学术基准测试集上取得了不错的进展,但在工业级数据库以及需要多步推理和涉及特定领域业务逻辑的复杂查询中,执行准确率(Execution Accuracy, EX)仍不稳定。新版基准测试集 Spider 2.0 进一步凸显了这一差距,该测试集更注重真实数据库模式的复杂性和更严格的评估标准。
从基准测试环境转向实际生产环境,会面临一系列反复出现的挑战:(1)复杂性:目标查询语句冗长、结构复杂且逻辑密集(涉及多表连接、嵌套子查询、窗口函数 / 聚合函数),再加上公用表表达式(Common Table Expressions, CTEs)、别名和数据库模式约束的影响,容易导致错误传播;(2)不确定性:用户问题可能存在歧义或信息不完整,同时推理过程中涉及的数据库模式 / 上下文可能不完整、存在噪声或过时,这就需要模型具备强大的意图推理和数据库模式关联能力(例如,模式链接和上下文感知提示词技术);(3)数据稀疏性:高质量的 “问题 - SQL” 配对数据稀缺,且在不同领域和方言间分布不均,导致一些不常用的操作符和罕见的连接模式在训练数据中代表性不足;(4)泛化能力:有监督微调(Supervised Fine - Tuning, SFT)和启发式数据增强方法往往会导致模型过拟合,在数据分布发生变化(如遇到新的数据库模式、新领域)时性能下降;此外,合成数据的生成不仅耗时费力,且对提示词或数据库模式的变化较为敏感,鲁棒性较差;(5)资源约束:考虑到延迟、成本和治理等因素,实际应用更倾向于使用轻量级的本地部署模型,而非大型通用模型,这就要求模型具备高效、可审计的流程,以满足服务级别协议(Service - Level Agreements, SLAs)和合规要求。此外,在实际场景中,精确匹配和执行匹配等评估指标可能无法提供充足的有效信息,甚至会产生误导性信号。
近年来,基于强化学习(Reinforcement Learning, RL)训练的推理语言模型(如 o1、DeepSeek - R1)取得了新的突破,研究表明,可验证的反馈能显著提升模型的多步推理能力,这与思维链证据以及 “有监督微调侧重记忆,强化学习侧重泛化” 的观点相符。在Text-to-SQL 任务中,通过执行信号可自然地为模型提供此类反馈(早期基于执行的强化学习在 Seq2SQL 中已有应用),但目前奖励信号仍存在稀疏性(仅为二元的成功 / 失败信号)且方言覆盖范围有限的问题,给模型训练和部署带来了困难。在本研究中,我们基于组相对策略优化(Group - Relative Policy Optimization, GRPO) 实现强化学习,并通过更密集的部分匹配信号解决奖励稀疏性问题。
研究贡献
本文提出 PaVeRL - SQL(用于Text-to-SQL 的部分匹配奖励与语言强化学习框架),该强化学习框架的贡献如下:
设计、构建并评估了两条互补的技术流程,以适应不同的部署约束条件:(1)一种语言自我评估的上下文工作流,该工作流会为每个查询采样可执行的候选 SQL 语句,直至收集到 10 个有效 SQL 语句,然后利用基础大型语言模型对这些候选语句进行排序并选择最终查询语句;(2)一条思维链强化学习流程,该流程以轻量级本地部署模型(OmniSQL - 7B)为基础,通过执行反馈对模型进行端到端训练。这两条流程在 Spider、Spider 2.0 - SQLite 和 BIRD 基准测试集上均取得了当前最优结果。
引入了新的评估指标和奖励塑造方法,除了二元执行准确率EXb外,还加入了列级部分执行准确率EXf来衡量部分正确性。与传统的 0/1 精确匹配指标相比,这些新指标能提供更密集、更丰富的信号,有助于提升训练稳定性。
提出了一种经济高效的两阶段组相对策略优化(GRPO)调度方案:先从最优检查点重启训练,再采用余弦衰减策略。该方案在不使用二阶方法的情况下,仅需较少的训练轮次(如≤20 轮),就能提升训练稳定性和样本 / 计算效率,使模型达到较高的准确率。
验证了混合方言训练的有效性,该方法能够在不同 SQL 方言间实现知识迁移,尤其对数据资源有限的方言,能显著提升模型性能,从而增强模型在实际工业环境约束下的跨方言泛化能力。
相关工作
从提示词与微调技术到Text-to-SQL 中的强化学习
Text-to-SQL 系统的发展主要围绕两个方向:(1)模型适配;(2)提示词工程。在微调方法方面,RATSQL、PICARD、RESDSQL、CodeS和 PSM - SQL 等模型通过融入数据库模式结构并强化解码约束来提升性能。在基于提示词的方法中,ACT - SQL、DIN - SQL、CHESS、CHASE - SQL等通过精心设计的指令实现零样本 / 少样本泛化。其他创新技术还包括语义模式链接、上下文感知提示词、模块化查询分解、基于记忆的自我修正 以及置信度校准等。这些技术在 Spider和 BIRD基准测试集上表现出色,但要应对 Spider 2.0的复杂性仍面临挑战,这也促使研究者将强化学习应用于复杂工业级数据库和涉及特定领域业务逻辑的复杂用户问题场景。
以推理语言模型为基础的强化学习
经过强化学习训练的推理语言模型(RLMs)能够生成有条理的思维链(CoT)轨迹,从而提升多步推理能力。实证研究表明,有监督微调(SFT)侧重记忆,强化学习(RL)侧重泛化,且大规模强化学习能提升模型在数学和代码任务上的性能。强化学习的效果对基础模型的性能较为敏感:初始性能较弱的模型会降低强化学习的效率。近年来性能优异的基础模型(如 o1、DeepSeek R1、Qwen3、Phi - 4)为Text-to-SQL 任务中更可靠的强化学习应用提供了可能。两阶段训练(如 DeepSeekLLM)也能增强模型的推理能力,但目前两阶段强化学习在Text-to-SQL 任务中的应用尚未得到充分探索。
Text-to-SQL 中的强化学习应用
将强化学习应用于 SQL 生成的相关研究日益增多。SEQ2SQL采用策略梯度方法,结合执行反馈对 SQL 子句进行优化。ICRL提出了基于检索的上下文学习方法,并引入奖励信号。SQL - RL - GEN和 STAR - SQL分别探索了进化搜索和奖励塑造技术。DEEPSQL - R1通过低秩适配(LoRA)和量化技术提升模型效率。REASONING - RL结合基于相似度的奖励机制,增强模式链接能力。SQL - R1利用动态奖励机制改进多表查询和嵌套查询性能,ARCTIC - TEXT - TOSQL - R1则着重关注执行正确性和语法有效性。
奖励函数设计
在Text-to-SQL 任务中,执行准确率是一种天然的奖励信号,但存在稀疏性问题,可能会阻碍策略优化。已有研究提出了复合奖励机制:如利用大型语言模型作为评判者(LLM - as - a - Judge)、语法检查、模式链接和 n - 元语法相似度等;以及包含格式、执行、结果和长度等多个维度的奖励组件。近期的简化方法则聚焦于执行和语法有效性。然而,大多数现有方法将正确性等同于与真实 SQL 的精确匹配,忽略了结果中部分正确性的程度差异。本研究提出一种部分匹配执行奖励机制,能提供更密集、更丰富的信号,有助于稳定强化学习过程并提升学习效率。此外,我们在单一强化学习流程中实现了多方言训练,而以往的强化学习方法通常针对单一方言设计,限制了模型的跨方言泛化能力。
以智能体与工作流为基础的强化学习框架
智能编码系统将推理、工具使用和迭代修正相结合。ReAct将推理与动作集成;Spider Agent则将该方法适配到数据库任务中。多智能体 / 工作流策略有助于复杂规划任务的完成,但特定领域的方法往往比通用智能体表现更优。ReFoRCE通过迭代探索和模式压缩技术,在 Spider 2.0 基准测试集上实现了性能提升。在本研究场景中,此类智能体架构具有互补作用:它为经过强化学习训练的Text-to-SQL 策略提供了执行环境,使其能够获取反馈并实现自我优化。但本研究的核心贡献在于以模型为中心的强化学习训练,而非流程编排逻辑。
方法
本文提出 PaVeRL - SQL(用于Text-to-SQL 的部分匹配奖励与语言强化学习框架),该框架采用双轨方法,在部署可行性和准确率之间取得平衡:一条是将基础大型语言模型同时作为生成器和评判者的语言自我评估工作流;另一条是基于组相对策略优化(GRPO)训练的思维链(CoT)强化学习流程。两条技术路线均借鉴了近期推理系统的思路,利用可验证的执行反馈,并结合更密集的部分匹配评估标准,以补充精确匹配 / 执行匹配等传统评估指标。
针对Text-to-SQL 任务的不同应用场景,我们设计并评估了两条特定的技术流程,以便根据可用资源优化性能和成本。
语言强化学习(Verbal RL)
应用场景 1:目标数据库与公开数据中的通用数据库高度相似,或由于硬件限制、成本原因,无法在本地训练Text-to-SQL 模型。
我们借鉴组相对策略优化(GRPO)的训练过程、Reflexion 和 ReAct 的思想,设计了一条语言自我评估强化学习流程。在无法在本地训练模型或目标数据库模式与公开数据分布相近的场景中,我们采用该语言自我评估流程,该流程能够模拟 GRPO 的组内偏好信号以及自我反思 / 动作机制。
具体流程如下:对于每个用户问题,首先利用基础大型语言模型,通过提示词 1(Prompt 1)采样生成 SQL 候选语句。然后执行每个候选语句以验证其有效性,并重复采样过程,直至收集到 10 个可执行的 SQL 语句,或达到 200 次采样尝试的上限。若经过 200 次尝试后,收集到的可执行候选语句仍少于 10 个,则使用已收集到的候选语句继续后续流程。接着,让同一个大型语言模型通过评分提示词(详见附录 A)对这些候选语句进行评分,每个 SQL 候选语句会生成 20 个评分,最终该 SQL 的得分为这 20 个评分的平均值。最后,选择得分最高的 SQL 语句作为最终输出;若存在多个得分相同的候选语句,则通过均匀随机的方式打破平局。
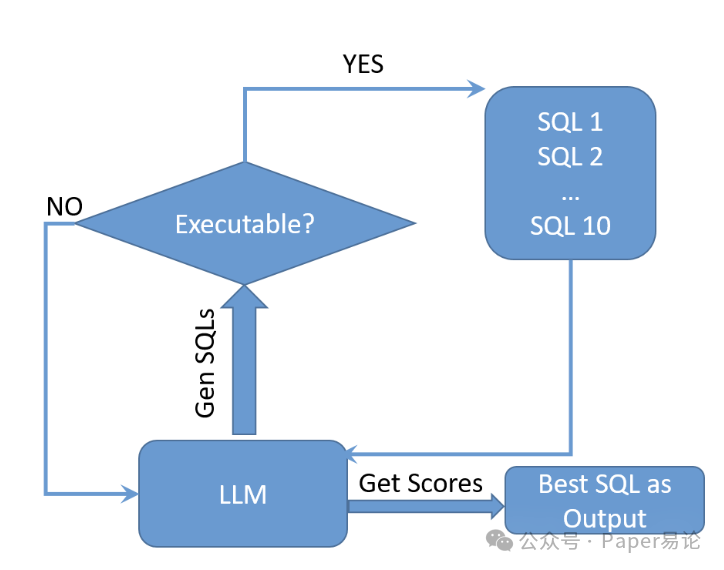
图 1. 语言强化学习(Verbal RL)流程:一种通过 “生成 - 判断”(generate-and-judge)实现梯度更新无关的多智能体生成式重排序(mates GRPO)的工作流。
对于每个自然语言问题,该流程的步骤如下:(1) 利用主语言模型(backbone LLM),通过生成式提示词(generation prompt)采样 SQL 候选语句,直至收集到 10 条可执行 SQL 语句(\(K=10\))或达到 200 次尝试上限;(2) 执行每条候选语句,验证其有效性;(3) 通过评分提示词(scoring prompt)对所有可执行候选语句进行评分;(4)选择得分最高的 SQL 作为最终输出结果。
这种 “生成 - 评判” 循环无需进行梯度更新,就能模拟组相对信号,且相比零样本提示词方法,性能有显著提升。整个流程如图 1 所示。
思维链强化学习(CoT RL)
应用场景 2:要求使用轻量级本地部署的Text-to-SQL 模型,且具备训练模型所需的计算资源。若因数据安全原因限制对数据库的访问,或因数据库的速度、规模等因素导致访问成本过高,建议基于带有可验证输出奖励模型(ORM)的思维链强化学习训练,构建一个单步 SQL 生成模型。
当需要本地推理且对模型鲁棒性有更高要求时,我们利用可验证的执行奖励,通过 GRPO 对轻量级基础模型进行训练。
强化学习方法
在思维链强化学习训练中,我们采用 GRPO 算法。该算法在许多带有可验证奖励的任务(如数学和代码任务)中表现出色,因此非常适合扩展应用到Text-to-SQL 任务。为达到最佳训练效果,通常建议先进行有监督微调(SFT)预热。OmniSQL 模型是以 Qwen2.5 - coder 模型为基础,使用 SynSQL2.5M数据进行有监督微调训练得到的,因此,经过有监督微调预热后,OmniSQL 模型是 GRPO 训练的理想初始基础模型。我们以 OmniSQL - 7B为初始模型,该模型是经过有监督微调的编码模型,适用于 SQL 生成任务。训练时,输入提示词 1(Prompt 1)中包含方言、数据库模式、可选上下文和问题等信息。
两阶段训练调度
受 DeepSeekLLM [28] 的启发,我们采用两阶段训练策略,旨在用较少的训练轮次(即较低的训练成本)实现最优的强化学习训练效果。但我们对该策略进行了如下改进:
第一阶段:在前 10 轮训练中,采用常用的学习率调度方案。训练初期,前 3% 的训练步骤采用较低的固定学习率进行预热;在 3% 到 10% 的训练步骤中,学习率线性增加到预先设定的最大学习率;剩余训练步骤则采用缓慢的余弦衰减策略降低学习率。
第二阶段:始终从第一阶段训练得到的最优模型(即贪心解码准确率最高的模型)开始训练。第一阶段的最优模型可能出现在训练过程的任意步骤(初期、中期或末期),与典型的两阶段训练不同,第二阶段的起始点不受限于第一阶段的最终模型。此外,还需观察第一阶段模型的准确率变化曲线:
若准确率曲线先上升,之后出现平台期迹象,则将第二阶段的初始学习率提高到预先设定的最大学习率,随后采用缓慢的余弦衰减策略;
若准确率曲线波动较大,无明显趋势,则将第二阶段的初始学习率降低至第一阶段最优模型学习率的一半,之后采用缓慢的余弦衰减策略。
采用上述训练策略,模型在 20 轮训练内即可达到理想的准确率,大幅缩短了训练时间并降低了训练成本。
奖励函数
我们设计的奖励函数旨在提升部分执行准确率EXf(即结果表中正确列的比例)。为在保持可验证性的同时减少奖励稀疏性,我们根据执行结果给予奖励,并根据部分正确性调整奖励大小。为节省训练时间,在 GRPO 训练开始前,我们先执行所有真实 SQL 语句,得到真实结果表。训练过程中,只需将采样生成的 SQL 语句的执行结果表与真实结果表进行比较即可。
数据集与预处理
为便于比较,我们首先聚焦于 SQLite 方言,并后文中呈现针对其他方言的实验结果。
Spider、Spider 2.0 - SQLite 和 BIRD 数据集
- Spider 数据集
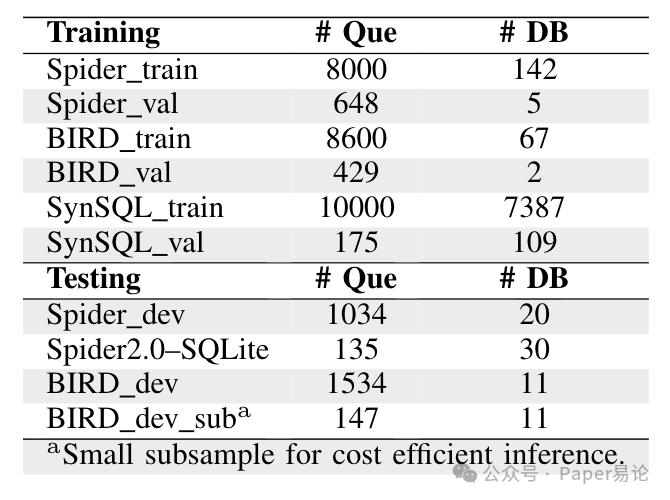
包含来自 146 个数据库的 8659 个训练用 “问题 - SQL” 配对数据。我们过滤掉列信息缺失和 SQL 语句错误(通常是表别名使用不当)的样本,最终得到 8648 个配对样本。将这些样本分为两部分:8000 个用于强化学习训练,648 个用于验证。训练后的模型在开发集(来自 20 个数据库的 1034 个 “问题 - SQL” 配对样本)上进行评估。
- BIRD 数据集
包含来自 69 个数据库的 9428 个训练用 “问题 - SQL” 配对数据。剔除列 / 表信息缺失或 SQL 语句错误的样本后,得到来自 68 个数据库的 9029 个配对样本,将其分为 8600 个训练样本和 429 个验证样本。BIRD 开发集包含来自 11 个数据库的 1534 个 “问题 - SQL” 配对样本。为提高成本效率,参考 CHESS 的方法,我们选取了一个具有代表性的子集(来自 11 个数据库的 147 个 “问题 - SQL” 配对样本)进行实验。
- Spider 2.0 数据集
在 SQLite 方言下,包含来自 30 个数据库的 135 个问题,我们仅将该数据集用于模型评估。
为构建不受领域或难度限制的通用Text-to-SQL 模型,我们补充了第三个训练集 ——SynSQL - 2.5M。从该数据集中随机选取 10000 个 “问题 - SQL” 配对样本,这些样本难度分布均衡,覆盖 7387 个数据库。由于单步思维链强化学习不太适合多轮对话场景,因此我们排除了多轮对话式问题,多轮对话场景的建模将在未来研究中开展。同时,从 109 个数据库中选取 175 个 “问题 - SQL” 配对样本作为验证集。对于该数据集,我们忽略提供的真实思维链,让强化学习模型自主探索解决方案。各数据集的详细信息汇总于表 1。
表 1 PaVeRL-SQL 实验的训练与评估数据集统计信息,注:a 为用于低成本推理的小子集。
数据库模式细节与上下文信息
实验过程中我们发现,为数据库模式补充轻量级数据概况(如主键 / 外键、数值列的最小值 / 最大值、文本列的前 3 个高频值),能显著提升 SQL 生成性能,尤其是在过滤和连接操作中。因此,我们整理并使用了包含这些信息的增强元数据,以补充标准模式信息。附录 B 中给出了一个模式字符串示例。
对于 BIRD 数据集,OmniSQL 将长文本上下文拆分为列级描述,并将其嵌入到模式字符串中。我们采用了相同的方法,并观察到模型性能有明显提升。由于部分 BIRD 数据库结构极为复杂,完整的模式信息无法在强化学习训练过程中全部放入模型的上下文窗口。因此,参考 OmniSQL 的做法,我们在训练时仅包含以下信息:(1)真实 SQL 中涉及的所有列;(2)所有主键和外键列;(3)随机采样的少量额外列。在 Spider 和 SynSQL10K 训练样本中,我们直接包含了上述所有数据库模式字符串信息。对于部分包含上下文信息的 SynSQL10K 样本,我们将上下文作为单独段落加入提示词中。测试时,始终使用完整的数据库模式字符串。生成 SQL 所用的提示词如提示词 1(Prompt 1)所示。

语言强化学习流程实验如图1所示,我们以近年来的多个开源和闭源大型语言模型为基础模型,对语言强化学习流程进行了评估,所用基础模型包括:GPT - 5 mini²(版本为“gpt - 5 - mini - 2025 - 08 - 07”)、gpt - oss - 20B、gpt - oss - 120B、Qwen3 - 30B - A3B - Instruct - 2507以及Qwen3 - Coder - 30B - A3B - Instruct。实验在Spider 2.0 SQLite子集(135个样本)和BIRD开发集子集(147个样本)上进行。出于时间和成本考虑,未在完整的BIRD开发集上进行评估。为进行比较,我们还报告了零样本推理结果以及可复现代码的当前最优流程(CHESS和SpiderAgent)的性能,评估指标包括3.1节中定义的官方执行准确率(EX)、二元执行准确率EXb和部分执行准确率EXf。在Spider2.0 - SQLite基准测试集上,我们提出的简单语言强化学习流程在GPT - 5 mini基础模型上的执行准确率(EX)达到37%,相比SpiderAgent高出12.6个百分点,相比使用相同基础模型(GPT - 5 mini)的CHESS流程高出7.4个百分点。总体而言,在所有基础模型上,该流程的性能均显著优于普通零样本提示词方法。相关提示词详见附录A,详细实验结果如表2所示。表2 语言强化学习流程的执行准确率(%)与零样本方法及其他流程的比较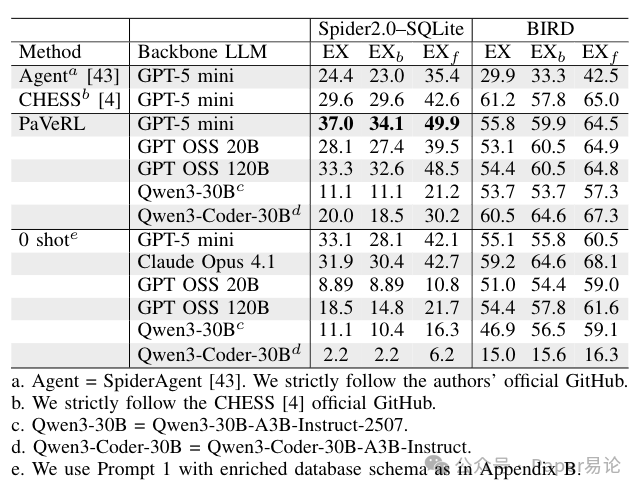
我们在Spider、BIRD和SynSQL10K数据集上训练模型,并分别在这三个数据集以及Spider2.0 - SQLite数据集上进行评估。训练在8块H100 GPU(每块显存96GB)上进行。实验使用VERL工具包,批次大小设为1024,温度参数为0.8,采样轮数为10。在第一阶段训练中,预热学习率为1e - 7或5e - 7;最大学习率为1e - 5或5e - 5(具体数值根据实验设置而定)。图2展示了在两阶段GRPO训练过程中,贪心执行准确率(Greedy EX)、学习率调度以及平均奖励的变化情况(蓝色曲线代表第一阶段,绿色曲线代表第二阶段)。由于SynSQL10K是通用公开数据集,我们还在Spider和BIRD数据集上评估了基于该数据集训练的模型性能。表3汇总了最优检查点模型与近期Text-to-SQL强化学习系统(SQL - R1、Arctic - Text2SQL - R1)的执行准确率(为简洁起见,仅展示官方执行准确率EX)。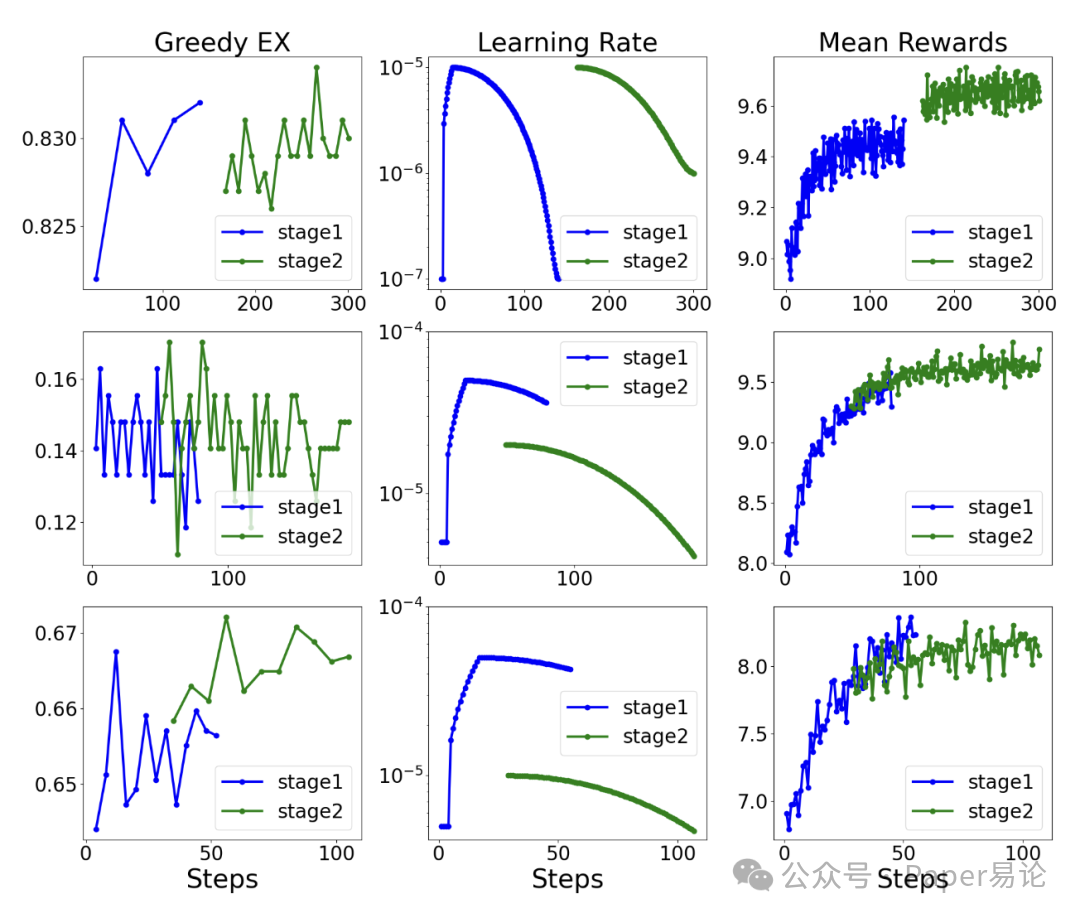
图 2. 两阶段 GRPO 优化下的思维链强化学习(CoT RL)训练动态
- 左侧图
:贪心解码执行准确率(EX)变化曲线,反映模型性能的演进过程。
- 中间图
:学习率调度曲线。第一阶段(stage 1)采用 “预热 - 线性增长 - 余弦衰减”(warm up-linear-cosine decay)的学习率策略;第二阶段(stage 2)从第一阶段的最优检查点(best stage 1 checkpoint)重启,并根据收敛模式调整学习率。
- 右侧图
:采用部分匹配奖励函数(partial-match reward function)的平均奖励变化曲线,体现出相比二元奖励(binary rewards),该奖励函数的信号密度显著提升。
蓝色曲线代表第一阶段训练过程,绿色曲线代表第二阶段训练过程。从上到下,三张子图分别对应 Spider 开发集(Spider dev)、Spider2.0–SQLite 数据集和 BIRD 开发集(BIRD dev)。实验表明,这种两阶段训练方法能在 20 个训练轮次(epochs)内实现模型收敛,同时保持训练稳定性。
表3 思维链强化学习流程的执行准确率(EX)结果(%)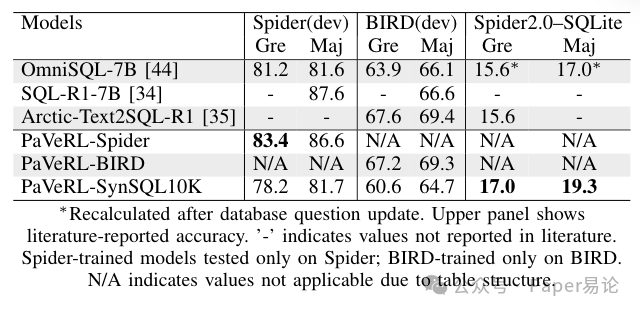
注:∗为数据库问题更新后重新计算的结果;上方区域为文献中报道的准确率;“ - ”表示文献中未报道该数值;在Spider数据集上训练的模型仅在Spider上测试,在BIRD数据集上训练的模型仅在BIRD上测试;“N/A”表示因表格结构原因该数值不适用。总体而言,PaVeRL思维链强化学习流程的性能达到或超过了当前最优的强化学习系统,尤其在更贴近工业场景的Spider2.0 - SQLite基准测试集上,性能提升显著。此外,我们还研究了多数投票所用样本数量对模型准确率的影响。测试了样本数量为8、16、32、64和128的情况,结果发现,样本数量并非越多越好,通常样本数量为32时效果最佳(如图3所示)。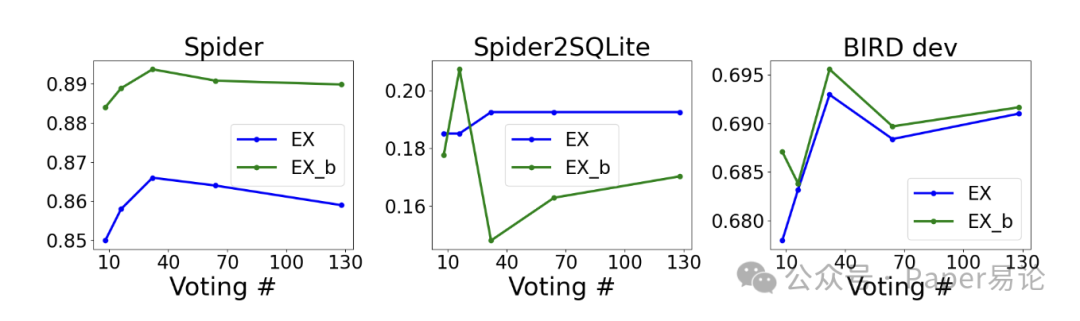
图 3. 多数投票集成规模对思维链强化学习(CoT RL)模型执行准确率的影响
实验结果展示了官方执行准确率(EX,蓝色曲线)和二元执行准确率EXb,绿色曲线)随集成规模(8、16、32、64、128 个样本)变化的关系。从左到右,三张子图分别对应 Spider 开发集(Spider dev)、Spider2.0–SQLite 数据集和 BIRD 开发测试集(BIRD dev test set)。需注意不同数据集的 y 轴刻度存在差异,这反映了各数据集基准难度水平的不同。每个数据集均选取多数投票执行准确率(EX)最高的模型作为最优性能模型。
混合方言思维链强化学习训练实验部分SQL方言的训练数据往往较为有限。尽管不同方言在函数和数据类型上存在差异,但它们的底层推理逻辑是相通的。因此,我们测试了在数据丰富的方言上训练的模型,是否能将知识迁移到数据稀缺的方言上。具体而言,我们从SynSQL10K的SQLite样本中随机选取6000个,与2000个专有MariaDB/MySQL样本组合(共8000个样本),并按照3.3节中的方法进行思维链强化学习训练。表4对比了训练前后模型在Spider2.0 - SQLite和内部MySQL测试集上的性能。结果显示,在数据丰富的SQLite测试集上,模型性能未下降;而在数据稀缺的MySQL测试集上,模型执行准确率提升了约3倍。表4 采用混合方言训练的PaVeRL模型执行准确率(%)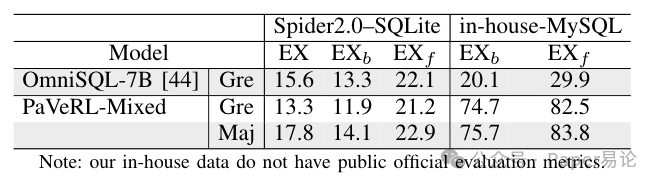
注:内部数据集无公开的官方评估指标。结论本文提出了PaVeRL - SQL,这是一个实用的Text-to-SQL框架,它将部分匹配奖励与两条互补的技术路线相结合:一条是轻量级的语言自我评估工作流,另一条是轻量级的思维链强化学习流程。通过利用可验证的执行反馈以及