01 论文概述

论文名称:
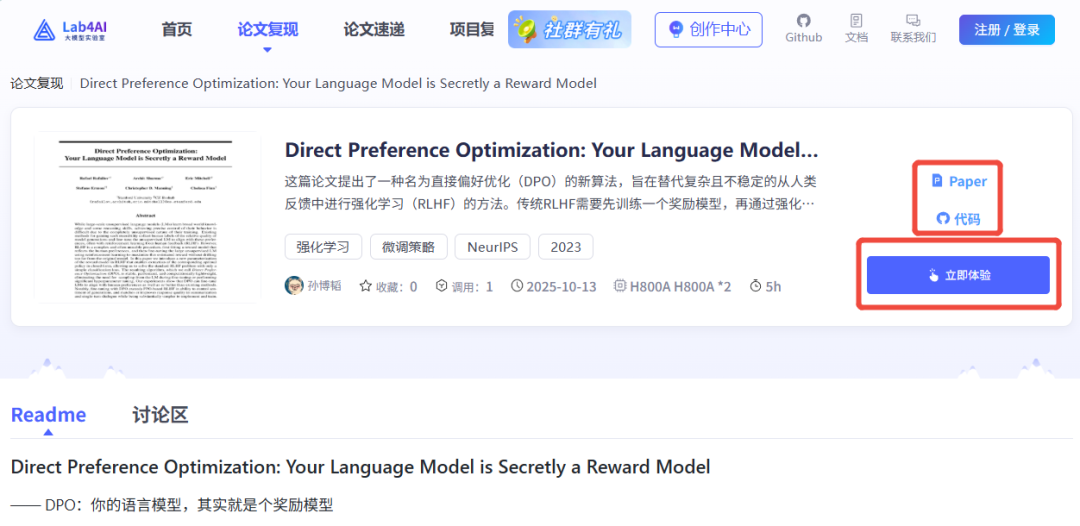
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
—— DPO:你的语言模型,其实就是个奖励模型
论文链接:https://arxiv.org/pdf/2305.18290
👉Lab4AI 链接:
https://www.lab4ai.cn/paper/detail?utm_source=jssq_bky&id=b7f869b397904e6a95f01b7e3ad6f044&type=paper
🌟 简介
在大型语言模型(LLM)的对齐技术中,基于人类反馈的强化学习(RLHF)曾是黄金标准。然而,RLHF 流程极其复杂:它需要先训练一个独立的奖励模型(Reward Model)来学习人类偏好,然后再使用强化学习(如 PPO)来微调语言模型以最大化这个奖励。这个过程不仅计算昂贵,而且训练过程极不稳定。
于 2023 年发布的 "直接偏好优化" (Direct Preference Optimization, DPO) 论文提出了一种颠覆性的、更简单的对齐范式。DPO 的核心洞见是:我们完全不需要一个显式的奖励模型,也不需要强化学习。通过一个精妙的数学推导,作者证明了可以直接利用人类偏好数据(即“选择的”和“拒绝的”回答对),通过一个简单的分类损失函数来直接优化语言模型本身。这篇论文揭示了,在优化的过程中,语言模型自身就隐式地充当了奖励模型的角色,从而极大地简化了对齐过程。
🔍 优势
- 极致简化DPO 将 RLHF 复杂的“奖励建模 -> 强化学习”两阶段流程,简化为一步式的、类似监督微调(SFT)的直接优化过程。
- 稳定高效完全摒弃了强化学习,从而避免了其训练不稳定、超参数敏感等问题。DPO 的训练过程像常规微调一样稳定,且计算成本更低。
- 性能卓越实验证明,DPO 不仅在实现上更简单,其最终模型的性能通常能与甚至超越经过复杂 RLHF 调优的模型。
- 理论优雅为偏好学习提供了坚实的理论基础,清晰地揭示了语言模型策略与隐式奖励函数之间的直接关系。
🛠️ 核心技术
- 偏好模型的重新参数化 (Reparameterization of the Reward Model)DPO 的理论基石。它首先基于 Bradley-Terry 等偏好模型建立奖励函数与最优策略(LLM)之间的关系。
- 从奖励优化到直接偏好优化通过数学推导,DPO 将最大化奖励的目标函数,巧妙地转换为了一个直接在偏好数据上进行优化的损失函数。这个损失函数的形式类似于一个简单的二元分类任务。
- 隐式奖励函数 (Implicit Reward Function)推导出的 DPO 损失函数表明,优化过程实际上是在最大化一个由当前策略(被优化的 LLM)和参考策略(初始 SFT 模型)的比值所定义的隐式奖励。这意味着语言模型自身的变化直接反映了奖励的变化,无需外部奖励模型。
- 类似 SFT 的实现 (SFT-like Implementation)DPO 的最终损失函数非常简洁,可以直接用于微调语言模型。训练数据是
(prompt, chosen_response, rejected_response)三元组,模型的目标是最大化chosen_response的概率,同时最小化rejected_response的概率。
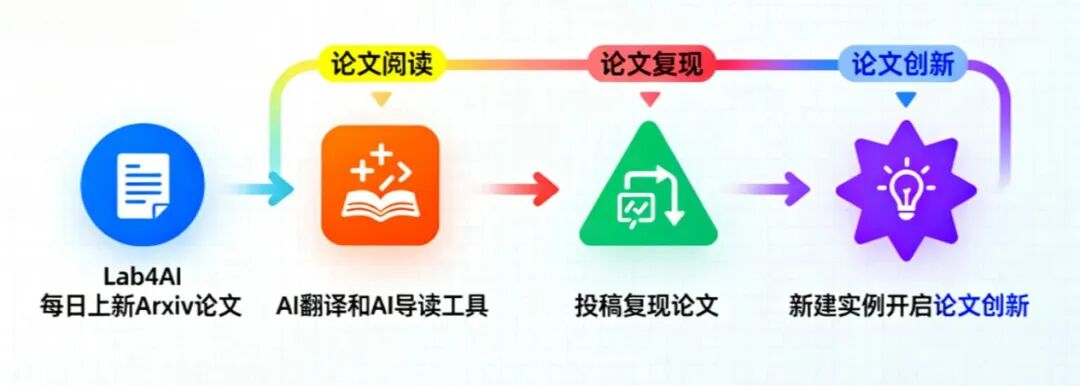
02 论文原文阅读
您可以跳转到Lab4AI.cn上进行查看。👉 文末点击阅读原文,即可跳转至对应论文页面~
-
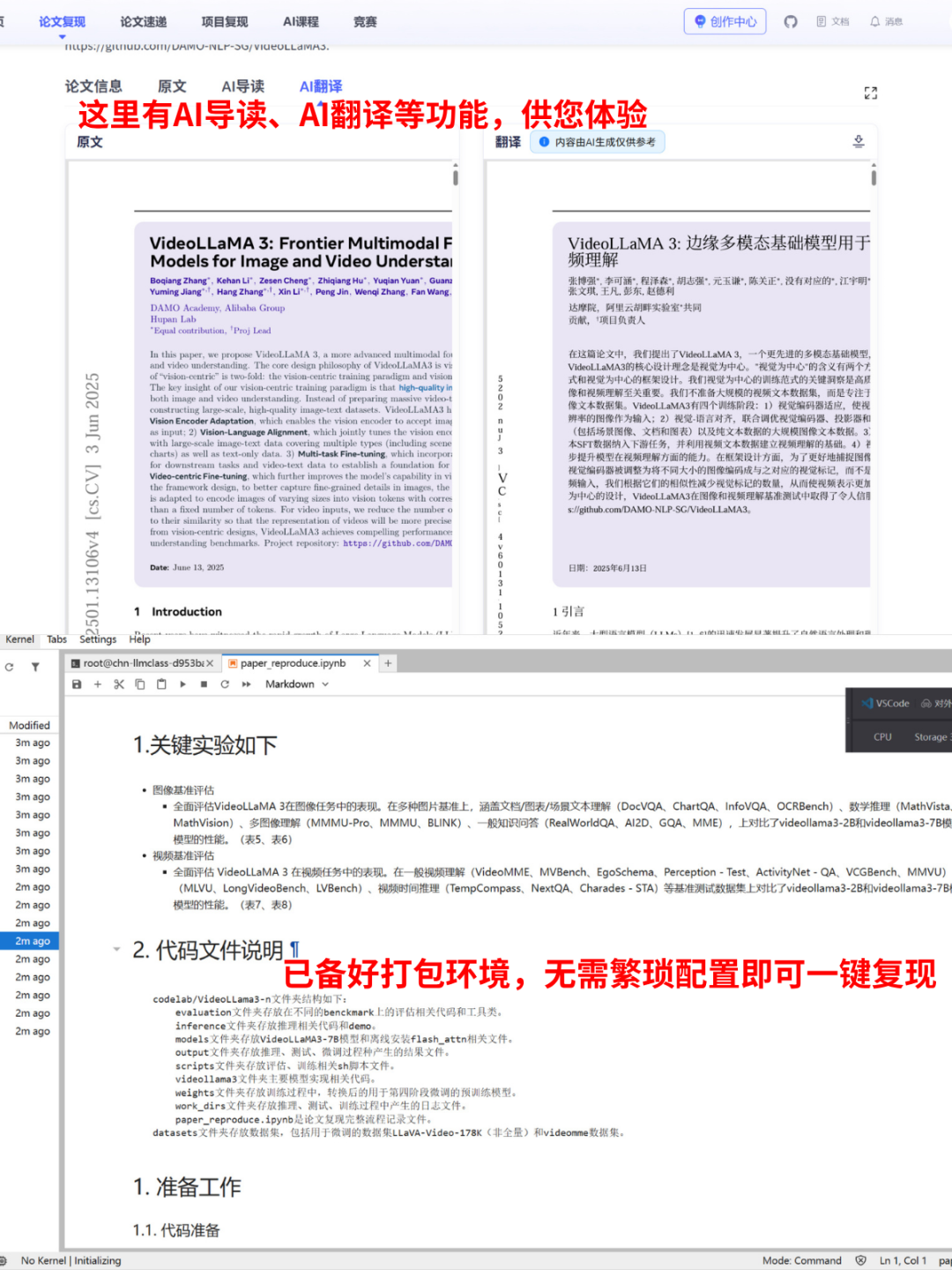
Lab4AI.cn 提供免费的AI 翻译和AI 导读工具辅助论文阅读;
-
支持投稿复现,动手复现感兴趣的论文;
-
论文复现完成后,您可基于您的思路和想法,开启论文创新。
![3.jpg]()
![4.png]()

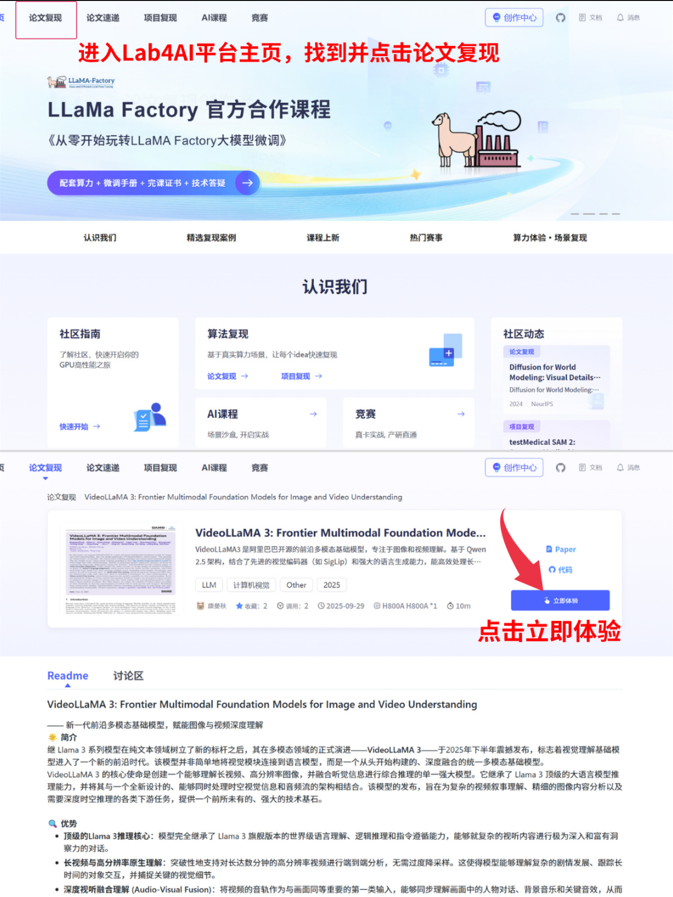
03 一键式论文复现
Lab4AI.cn上已上架了此篇复现案例,【登录平台】即可体验论文复现。
👉Lab4AI 平台复现链接(或者点击阅读原文):
https://www.lab4ai.cn/paper/detail?utm_source=jssq/_bky&id=5ff4513f94e1408aae0afd05f797d242&type=paper
🛠️ 实验部署
本实验环境已为您精心配置,开箱即用。
- 💻 代码获取:项目复现代码已存放于
/codelab/direct-preference-optimization/code文件夹中。 - 🧠 模型说明:
/codelab/direct-preference-optimization/model文件夹中存放了用于 DPO 训练的初始 SFT 模型。 - 📊 数据说明:
/codelab/direct-preference-optimization/dataset文件夹中包含了用于实验的人类偏好数据集(如 Anthropic HH-RLHF)。 - 🌐 环境说明:运行所需的所有依赖已预安装在
/envs/dpo/环境中,您无需进行任何额外的环境配置。
🚀 环境与内核配置
请在终端中执行以下步骤,以确保您的开发环境(如 Jupyter 或 VS Code)能够正确使用预设的 Conda 环境。
1. 在 Jupyter Notebook/Lab 中使用您的环境
- 为了让 Jupyter 能够识别并使用您刚刚创建的 Conda 环境,您需要为其注册一个“内核”。
- 首先,在您已激活的 Conda 环境中,安装
ipykernel包:conda activate dpopip install ipykernel - 然后,执行内核注册命令。
# 为名为 dpo 的环境注册一个名为 "Python(dpo)" 的内核kernel_install --name dpo --display-name "Python(dpo)" - 完成以上操作后,刷新您项目中的 Jupyter Notebook 页面。在右上角的内核选择区域,您现在应该就能看到并选择您刚刚创建的
"Python(dpo)"内核了。
2. 在 VS Code 中使用您的环境
- VS Code 可以自动检测到您新创建的 Conda 环境,切换过程非常快捷。
- 第一步: 选择 Python 解释器
- 确保 VS Code 中已经安装了官方的 Python 扩展。
- 使用快捷键
Ctrl+Shift+P(Windows/Linux) 或Cmd+Shift+P(macOS) 打开命令面板。 - 输入并选择
Python: Select Interpreter。
- 第二步: 选择您的 Conda 环境
- 在弹出的列表中,找到并点击您刚刚创建的环境(名为
dpo的 Conda 环境)。 - 选择后,VS Code 窗口右下角的状态栏会显示
dpo,表示切换成功。此后,当您在 VS Code 中打开 Jupyter Notebook (.ipynb) 文件时,它会自动或推荐您使用此环境的内核。
- 在弹出的列表中,找到并点击您刚刚创建的环境(名为
Lab4AI.cn 来送礼啦~
✅ 注册有礼,注册即送 30 元代金券
https://www.lab4ai.cn/register?utm_source=jssq/_bky立即体验
✅ 入群有礼,入群即送 20 元代金券
👇
