垃圾收集器G1&ZGC详解
一、G1 收集器(-XX:+UseG1GC)
G1(Garbage-First)是面向多处理器、大内存的服务器级收集器,核心目标是可预测的 GC 停顿时间与高吞吐量平衡。
1. 核心特性
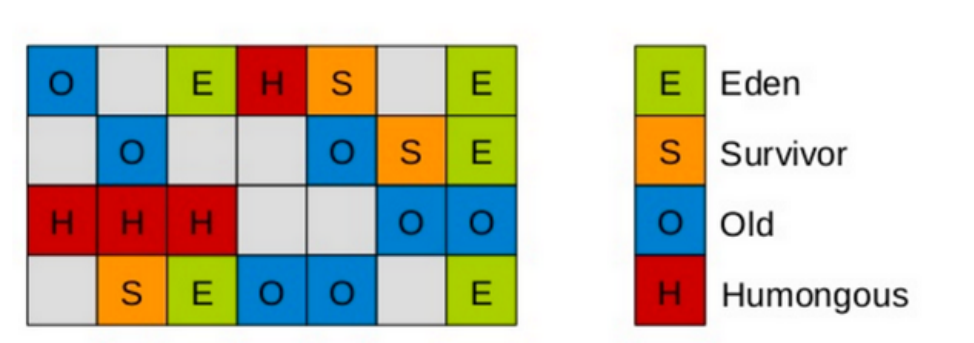
- Region 划分:将 Java 堆划分为最多 2048 个大小相等的 Region,Region 大小默认 = 堆大小 / 2048(1MB~32MB,需为 2 的 N 次幂,可通过
-XX:G1HeapRegionSize手动指定)。 - 动态分代:保留年轻代、老年代概念,但非物理隔离,而是由不连续的 Region 组成:
- 年轻代初始占比5%,最大可扩展至堆的60%(分别通过
-XX:G1NewSizePercent和-XX:G1MaxNewSizePercent控制),Eden:Survivor 默认 =8:1:1。 - 老年代:由长期存活的对象组成,Region 功能可动态切换(如年轻代 Region 回收后可变为老年代)。
- 年轻代初始占比5%,最大可扩展至堆的60%(分别通过
- Humongous 区:专门存储大对象,判定标准为 “对象大小> 1 个 Region 的50%”(如 Region=2MB 时,>1MB 的对象进入 Humongous 区),大对象可横跨多个 Region,FullGC 时会一并回收。
- 算法特性:整体基于 **“标记 - 整理” 算法 **(无内存碎片),局部基于 “复制算法”(Region 间复制存活对象)。
- 可预测停顿:通过
-XX:MaxGCPauseMillis(默认 200ms)指定目标停顿时间,后台维护优先列表,优先回收 “回收价值最高” 的 Region(如 50ms 回收 20MB 的 Region 优先于 200ms 回收 10MB 的 Region)。
2. 收集流程
G1 的 GC 分为三类,优先级从高到低为:YoungGC → MixedGC → FullGC。
| GC 类型 | 触发条件 | 回收范围 | 执行特点 |
|---|---|---|---|
| YoungGC | Eden 区满,且计算回收时间接近MaxGCPauseMillis |
仅年轻代(Eden+Survivor) | 采用复制算法,STW 时间短,优先保证停顿目标 |
| MixedGC | 老年代占堆内存比例达-XX:InitiatingHeapOccupancyPercent(默认 45%) |
年轻代 + 部分老年代 + Humongous 区 | 非 FullGC,按停顿目标筛选回收老年代 Region,复制算法 |
| FullGC | MixedGC 时无足够空 Region 承载存活对象 | 年轻代 + 老年代 + Humongous 区 | 单线程标记 - 清理 - 压缩,STW 时间极长(需避免) |
G1 单次完整收集(如 MixedGC)的四步流程:
- 初始标记(STW):暂停用户线程,标记 GC Roots 直接引用的对象,耗时极短。
- 并发标记:与用户线程并发,遍历对象图做可达性分析,耗时久但无 STW。
- 最终标记(STW):修正并发标记期间的漏标,耗时短于并发标记。
- 筛选回收(STW):按
MaxGCPauseMillis筛选回收价值最高的 Region,复制存活对象,无碎片。
3. 核心参数
| 参数名称 | 作用 | 默认值 |
|---|---|---|
-XX:+UseG1GC |
启用 G1 收集器 | 未启用 |
-XX:ParallelGCThreads |
指定 GC 工作线程数 | CPU 核数相关 |
-XX:G1HeapRegionSize |
指定 Region 大小(1MB~32MB,2 的 N 次幂) | 堆大小 / 2048 |
| -XX:MaxGCPauseMillis | 目标 GC 停顿时间 | 200ms |
-XX:G1NewSizePercent |
年轻代初始占堆比例 | 5% |
-XX:G1MaxNewSizePercent |
年轻代最大占堆比例 | 60% |
-XX:InitiatingHeapOccupancyPercent |
触发 MixedGC 的老年代占堆阈值 | 45% |
-XX:G1MixedGCLiveThresholdPercent |
Region 存活对象低于该值才回收 | 85% |
-XX:MaxTenuringThreshold |
对象晋升老年代的最大年龄阈值 | 15 |
4. 优化建议与适用场景
- 优化核心:合理设置
-XX:MaxGCPauseMillis,避免值过大导致年轻代占比过高(达 60%),存活对象过多进入老年代,触发频繁 MixedGC;也避免值过小导致回收效率低于分配效率,堆内存堆积引发 FullGC。 - 适用场景:
- 堆内存8GB 以上(建议值)。
- GC 停顿需求在500ms 以内。
- 对象分配 / 晋升速度波动大,或垃圾回收时间超过 1 秒(如高并发消息系统 Kafka)。
二、ZGC 收集器(-XX:+UseZGC)
ZGC 是 JDK 11 引入的实验性低延迟收集器,源自 Azul C4,核心目标是极致低停顿与超大堆支持。
1. 核心目标
| 目标内容 | 具体指标 |
|---|---|
| 停顿时间 | 最大≤10ms,且不随堆大小增长而增加 |
| 堆内存支持 | 最大16TB(JDK13 前为 4TB) |
| 吞吐量影响 | 最糟糕情况下降低≤15% |
| 扩展性 | 奠定未来 GC 特性基础 |
| 分代支持 | 暂时不分代(未来计划引入) |
2. 内存布局
ZGC 基于 Region 划分堆,Region 分为三类,无分代概念:
| Region 类型 | 容量固定值 | 存储对象大小范围 | 特点 |
|---|---|---|---|
| 小型 Region | 2MB | <256KB | 固定容量,存储小对象 |
| 中型 Region | 32MB | ≥256KB 且 < 4MB | 固定容量,存储中对象 |
| 大型 Region | 2MB 的整数倍 | ≥4MB | 动态容量,仅存 1 个大对象,不重分配 |
- NUMA 感知:自动适配 NUMA 架构(每个 CPU 对应专属内存),优先访问本地内存,提升效率。
3. 关键技术
-
1. 颜色指针(Colored Pointers)
ZGC 的核心设计,将 GC 信息存储在64 位对象指针中(而非对象头),指针结构划分如下:
-
18 位:预留给未来扩展;
-
4 位标志位:
Finalizable(1 位,与 finalizer 相关)、Remapped(1 位,对象是否在重分配集)、Marked1/Marked0(各 1 位,标记 GC 周期); -
42 位:对象地址(支持 2^42=4TB 内存,JDK13 扩展为 44 位地址,支持 16TB)。
-
核心优势:
- Region 存活对象移走后可立即释放,无需等待所有引用修正;
- 仅需读屏障,大幅减少内存屏障数量;
- 扩展性强,可记录更多 GC 相关数据。
-
2. 读屏障(Load Barrier)
ZGC 唯一使用的内存屏障,触发时机为 “从堆中读取对象引用时”,作用是修正移动对象的指针(实现 “自愈”):
- 当读取的指针为 “Bad Color”(对象已移动),进入慢路径,通过 Region 转发表找到新对象地址,修正指针;
- 当指针为 “Good Color”,正常执行;
- 额外开销:官方测试约4%(SPECjbb 2015 基准)。
4. 运作过程(四阶段)
- 并发标记(Concurrent Mark):
- 含短暂 STW(初始标记 Mark Start、最终标记 Mark End),通过颜色指针的
Marked0/Marked1位标记对象可达性,无 FullGC。
- 含短暂 STW(初始标记 Mark Start、最终标记 Mark End),通过颜色指针的
- 并发预备重分配(Concurrent Prepare for Relocate):
- 扫描所有 Region,筛选需回收的 Region 组成重分配集,省去 G1 中记忆集的维护成本。
- 并发重分配(Concurrent Relocate):
- 复制重分配集中的存活对象到新 Region,维护转发表(旧→新对象映射);
- 用户线程访问旧对象时,读屏障触发 “自愈”,修正指针为新地址,Region 可立即释放(转发表保留)。
- 并发重映射(Concurrent Remap):
- 修正堆中指向旧对象的引用,合并到下次并发标记阶段(避免重复遍历对象图),转发表在所有指针修正后释放。
5. 核心参数与问题
-
核心参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC:启用 ZGC(JDK11+,实验性);-XX:ZCollectionInterval:定时触发 GC 的间隔(默认不启用);-XX:ZProactive:是否主动触发 GC(默认开启)。
-
问题与解决方案:
问题描述 原因 解决方案 浮动垃圾多 ZGC 执行周期长(如 10 分钟),期间新增对象无法回收 增大堆容量(治标);未来引入分代(治本) “朝生夕死” 对象未及时回收 无分代,每次全堆扫描 引入分代收集,专门回收新生对象
6. 适用场景
- 堆内存几百 GB 以上(如 TB 级);
- GC 停顿需求严格(≤10ms),响应时间优先(如金融高频交易、大型实时数据处理);
- 可接受 15% 以内的吞吐量降低。
三、安全点与安全区域
GC 需在 “线程状态确定” 时执行,安全点与安全区域是保障 GC 安全的核心机制。
- 安全点(Safe Point)
- 定义:线程运行过程中状态确定的特定位置,GC 需等待所有线程到达安全点后才能触发。
- 关键位置:
- 方法返回之前;
- 调用方法之后;
- 抛出异常的位置;
- 循环的末尾。
- 实现逻辑:GC 触发时设置 “中断标志”,线程主动轮询标志,到达安全点后自行挂起。
- 安全区域(Safe Region)
- 定义:引用关系不会变化的代码片段,在区域内任意位置触发 GC 均安全。
- 作用:应对线程处于
Sleep或中断状态(无法响应 GC 中断请求,无法到达安全点),确保此类线程不影响 GC 执行。
关键问题
问题 1:G1 收集器的 MixedGC 与 FullGC 有何本质区别?分别在什么场景下触发?
答案:两者在触发条件、回收范围、执行效率上存在本质区别,核心差异如下:
- 触发条件:
- MixedGC:老年代占堆内存比例达到
-XX:InitiatingHeapOccupancyPercent(默认 45%),或动态年龄判断导致部分对象提前进入老年代,此时堆仍有足够空 Region 承载存活对象。 - FullGC:MixedGC 执行过程中,复制存活对象时发现无足够空 Region,无法完成 Region 间复制,触发 “兜底” 的 FullGC。
- MixedGC:老年代占堆内存比例达到
- 回收范围:
- MixedGC:回收年轻代(Eden+Survivor)+ 部分老年代 + Humongous 区,仅筛选 “回收价值高” 的老年代 Region(基于
MaxGCPauseMillis)。 - FullGC:回收年轻代 + 全部老年代 + Humongous 区,无筛选过程,全量回收。
- MixedGC:回收年轻代(Eden+Survivor)+ 部分老年代 + Humongous 区,仅筛选 “回收价值高” 的老年代 Region(基于
- 执行效率:
- MixedGC:采用多线程复制算法,STW 时间可控(符合
MaxGCPauseMillis),无内存碎片。 - FullGC:采用单线程标记 - 清理 - 压缩,STW 时间极长(如 GB 级堆可能达秒级),严重影响用户体验,需尽量避免。
- MixedGC:采用多线程复制算法,STW 时间可控(符合
总结:MixedGC 是 G1 的常规 GC,优先保障低停顿;FullGC 是 “异常兜底” GC,需通过优化参数(如合理设置MaxGCPauseMillis、增大年轻代)减少触发。
问题 2:ZGC 的 “颜色指针” 技术相比传统 GC(如 CMS、G1)的 “对象头标记”,有哪些不可替代的核心优势?
答案:颜色指针将 GC 信息存储在指针中,而非对象头,相比传统对象头标记,核心优势有三点:
-
Region 即时释放,提升内存利用率:
传统 GC 中,Region 的存活对象移走后,需等待堆中所有指向该 Region 的引用修正完毕才能释放 Region;而颜色指针通过 “转发表” 和 “读屏障自愈”,只要存活对象复制到新 Region,旧 Region 可立即释放(无需等待引用修正),理论上 “只要有 1 个空 Region 就能完成收集”,内存利用率更高。
-
大幅减少内存屏障数量,降低开销:
传统 GC(如 CMS 用写屏障、G1 用写屏障维护卡表)需在 “对象引用赋值” 时插入写屏障,高频赋值场景下屏障开销大;ZGC 仅需读屏障(仅在 “读取对象引用” 时触发),且读屏障逻辑简单(仅判断指针颜色),官方测试额外开销仅 4%,远低于传统 GC 的屏障开销。
-
扩展性强,支持更多 GC 特性:
颜色指针的 64 位结构中预留 18 位空间,可扩展存储更多 GC 相关数据(如对象存活时间、跨 Region 引用标记),为未来 GC 特性(如更精细的分代、动态 Region 大小)奠定基础;而对象头空间有限(如 HotSpot 的 Mark Word 仅 8 字节),扩展能力受限。
问题 3:在大内存场景(如堆内存 64GB),如何根据业务需求选择 G1 和 ZGC 收集器?需结合两者的核心特性分析。
答案:需从 “停顿需求”“吞吐量容忍度”“堆内存规模” 三个维度结合业务需求选择,具体决策逻辑如下:
- 优先选 G1 的场景:
- 业务需求:GC 停顿可接受500ms 以内,更关注吞吐量(如电商订单系统、大数据离线计算),堆内存 64GB 属于 “中大型” 但未达 TB 级。
- 核心依据:
- G1 支持通过
-XX:MaxGCPauseMillis(如设置 200ms)平衡停顿与吞吐量,64GB 堆下 MixedGC 的 STW 时间可控制在 200ms 内,满足多数业务需求; - G1 有成熟的分代机制,可快速回收 “朝生夕死” 的对象(如订单对象),吞吐量降低仅 5%~10%,优于 ZGC 的 15% 上限;
- ZGC 在 64GB 堆下的 “低停顿优势”(≤10ms)无法充分体现,反而因读屏障带来 4% 额外开销,性价比低于 G1。
- G1 支持通过
- 优先选 ZGC 的场景:
- 业务需求:GC 停顿需严格≤10ms(如金融高频交易、实时直播弹幕推送),响应时间优先级高于吞吐量,堆内存 64GB 未来可能扩容至 TB 级。
- 核心依据:
- ZGC 的停顿时间不随堆大小增长而增加,64GB 堆与 TB 级堆的停顿均≤10ms,可满足严格的低停顿需求;
- 若未来堆扩容至 TB 级,ZGC 无需重构参数即可支持,而 G1 在 TB 级堆下会因 Region 数量过多(2048 个 Region 需每个≥512MB)导致筛选回收时间超出目标停顿;
- 业务可接受 15% 以内的吞吐量降低,读屏障的 4% 额外开销在可容忍范围内。
总结:64GB 堆下,若停顿需求宽松(≥100ms)选 G1;若停顿需求严格(≤10ms)或未来扩容至 TB 级,选 ZGC。