1.介绍
本文主要以github上的stable diffusion开源项目中的layout2img-openimages256为例,以图片形式详细介绍stable diffusion模型中使用的神经网络结构,关于潜在扩散模型思想以及扩散模型训练和采样算法,目前中文互联网上也已有很多的学习资料,因此在此不做赘述。
2.VAE网络结构
VAE的主要作用是将输入图片压缩为一个固定大小的特征空间,以减小后面Unet参数。
其整体模块框图如下:

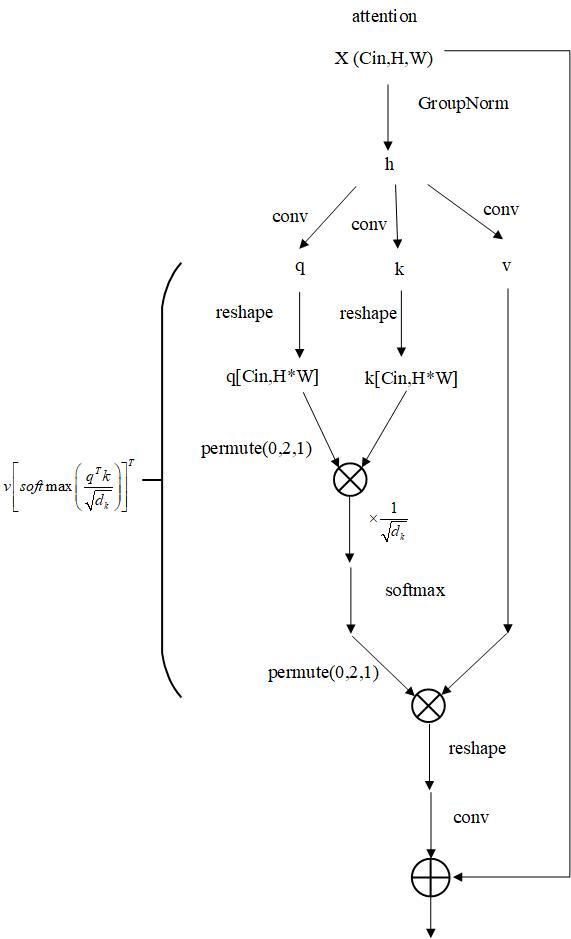
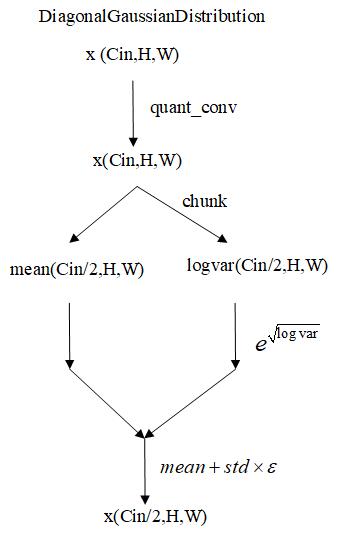
前面的down sample模块、mid模块、end模块为编码器,中间的DiagGaussianDistribution为高斯加噪、后面的mid模块、Up Sample模块、end模块为解码器,可以看到编解码器主要由Resblock、attention和Downsample/Upsample组成,其中Downsample/Upsample结构比较简单,Downsample就是用一个卷积层实现H,W减半,Upsample是先插值使H,W乘2,然后通过一个卷积层,所以本文就没有画它们的结构。
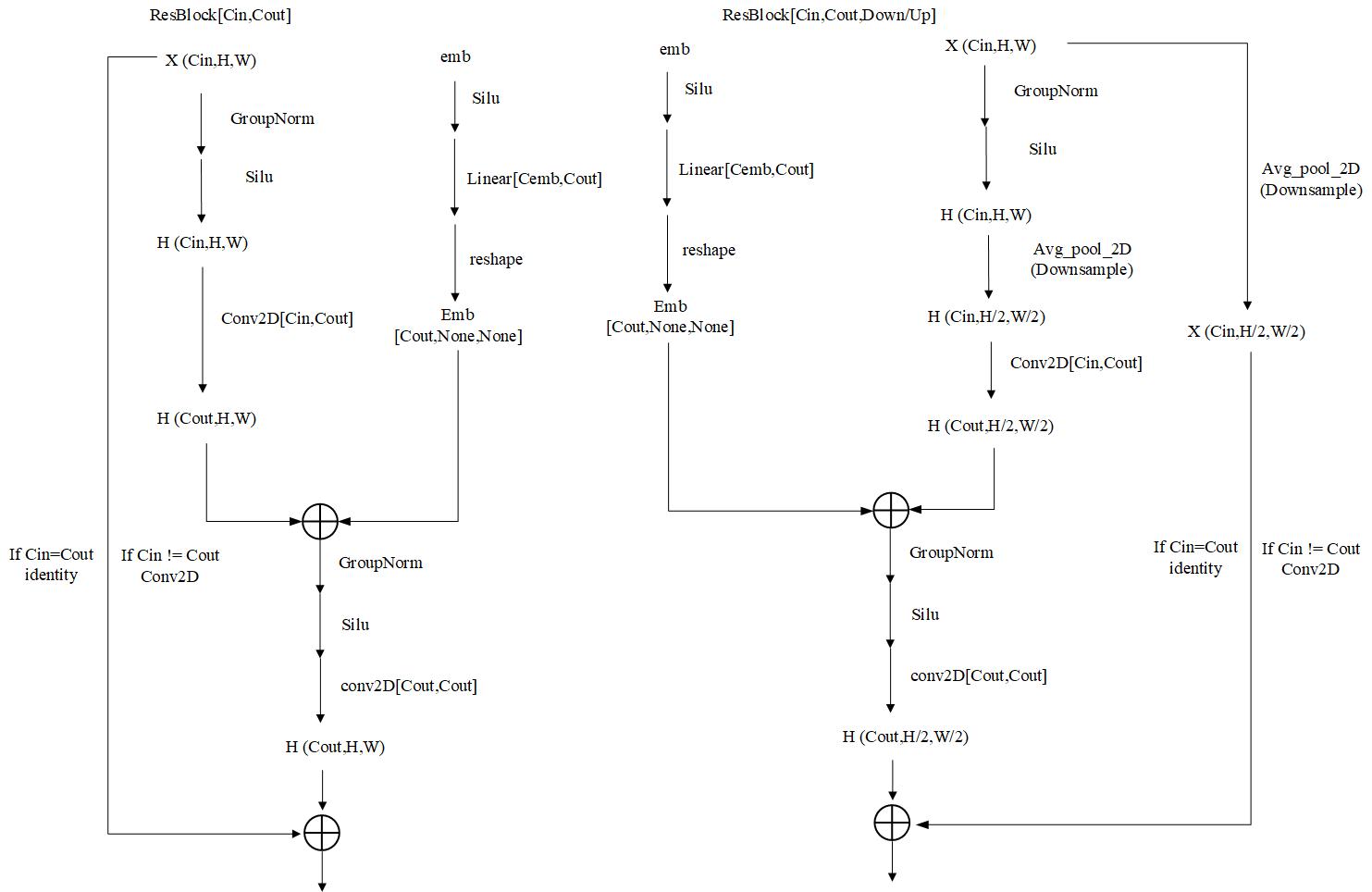
2.1 ResBlock的计算结构图

2.2 attention的计算结构图
 c
c
2.3 DiagGaussianDistribution的计算结构图
2.4 VAE损失函数
stable diffusion中训练VAE的损失函数设计来自于论文:[https://arxiv.org/pdf/2012.09841](Taming Transformers for High-Resolution Image Synthesis)。使用类似GAN的对抗思想,在VAE的输出后面加一个判别器(\(D(\cdot)\)),其中生成器损失函数为:
\(L_{\text {total }}=\underbrace{L_1 \text { loss }+L_2 \text { loss }+w_{\text {perceptual }} L_{\text {perceptual }}(\text { LPIPS loss })}_{n \text { ll loss }}+w_{k l} L_{k l}+\lambda L_G\)
其中\(\lambda\)为:
\(\lambda=\frac{L_2\left(\frac{\text { dnll_loss }}{\text { dlast_layer.weight }}\right)}{L_2\left(\frac{\partial L_G}{\text { dlast_layer.weight }}+10^{-4}\right)}\)
\(w_{k l}\)通常取\(10^{-6}\), \(w_{perceptual}\) 通常取1。
\(L_D\)与GAN中判别器损失函数一致,训练方法也与GAN中训练方法一致。
3.Unet网络结构
扩散模型中Unet主要用来预测第t步噪声(\(pred-\epsilon\))或预测原始无噪声样本(\(pred-x_0\))。使用的Unet是项目中的ldm.modules.diffusionmodules.openaimodel.UNetModel模型
其整体模块框图如下:

(由于网络规模过大,图片中的字可能在网站上看不清,可以将图片保存下来放大查看网络中每个模块参数超参数设置。)
从上图中可见Unet网络编码器有4层,相应的解码器也有4层。编码器和解码器都主要由Resblock模块,SpatialTransformer模块和上/下采样模块组成,其中上下采样模块结构很简单,下采样模块就是用一个卷积层实现H,W减半,上采样模块是先插值使H,W乘2,然后通过一个卷积层,所以本文就没有画它们的结构。
3.1 Resblock计算结构图
3.2 SpatialTransformer计算结构图

其中的BasicTransformerBlock的结构如下:
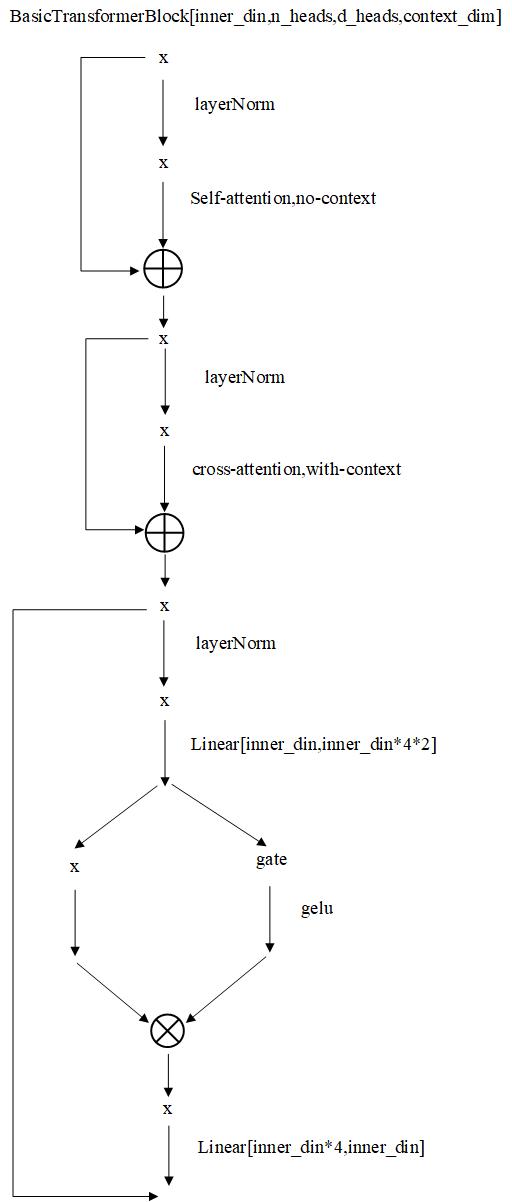
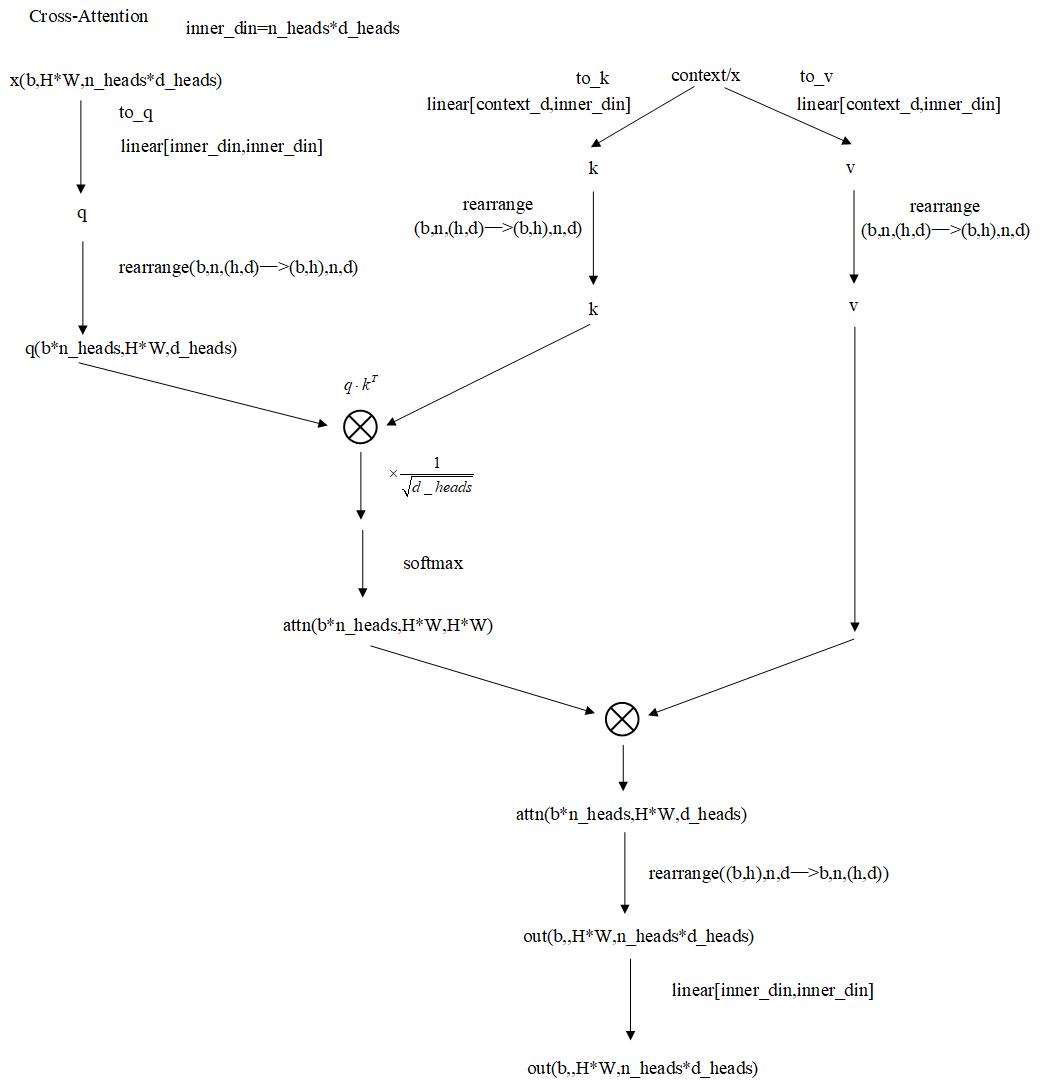
BasicTransformerBlock中的注意力层在有context时是交叉注意力,在没有context时是自注意力,context是条件经过条件网络编码后embedding。
crossattention结构如下: