个人项目报告
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | [软件工程](首页 - 计科23级12班 - 广东工业大学 - 班级博客 - 博客园) |
| 这个作业要求在哪里 | [作业要求](个人项目 - 作业 - 计科23级12班 - 班级博客 - 博客园) |
| 这个作业的目标 | 训练个人项目软件开发能力,学会使用性能测试工具和实现单元测试 |
一、代码组织与模块设计
1. 模块划分与函数职责(函数式模块化)
| 模块 | 函数/组件 | 职责 |
|---|---|---|
| 文件处理模块 | load_text / only_name / save_line_append(io_utils.py) |
读取/写入文本(UTF-8 优先,GBK 回退),抽取文件名,结果追加写入 |
| 核心算法模块 | lcs_length / lcs_similarity_pct(algos.py) |
计算 LCS 长度与相似度(百分比,抄袭文本长度为分母) |
| 流程控制模块 | run_once / main(runner.py) |
解析命令行参数、协调 I/O 与算法、统一输出格式 |
| 评测兼容入口 | main.py | 只做转发到 runner.main,兼容评测机命令 |
Gitnub仓库链接:https://github.com/fanqieren123-wq/3123004591
2. 类与函数关系图
main.py
└─> runner.main()
├─> run_once()
│ ├─> io_utils.load_text()
│ ├─> algos.lcs_length()
│ └─> io_utils.save_line_append()
└─> argparse 解析
二、算法关键实现(LCS)
核心转移方程
dp[i][j] = {dp[i-1][j-1] + 1, if a[i-1] == b[j-1]max(dp[i-1][j], dp[i][j-1]), otherwise
}
空间优化:滚动数组(algos.py:lcs_length)
prev = [0] * (n + 1)
curr = [0] * (n + 1)
for i in range(1, m + 1):ai = a[i - 1]for j in range(1, n + 1):if ai == b[j - 1]:curr[j] = prev[j - 1] + 1else:curr[j] = max(curr[j - 1], prev[j])prev, curr = curr, [0] * (n + 1)
进一步优化:让较短的字符串做“列”(n),减少数组长度与缓存压力。
中文处理:相似度基于字符级,天然兼容中文字符。
三、设计独到之处
-
内存效率优化:滚动数组 + 短串做列,显著降低空间开销与 cache miss。
-
鲁棒性设计:
load_text:UTF-8 优先、GBK 回退,不抛异常。- 空文件直接输出 0.00%。
runner.main捕获异常返回码,避免评测崩溃。
-
输出友好:统一由
format_result_line生成固定两位小数的英文描述,与评测一致。
四、计算模块接口部分的性能改进实践
1. 基线性能与瓶颈
-
固定输入:
data/orig_1.txt与data/copy_1.txt -
命令:
Measure-Command { python main.py data/orig_1.txt data/copy_1.txt result.txt } -
基线耗时:填写你的实际秒数
-
性能画像:cProfile → SnakeViz/VS,热点集中在
algos.lcs_length的双重循环。
2. 优化策略与实现
| 优化方向 | 具体措施 | 效果 |
|---|---|---|
| 算法内存 | 2D 表 → 滚动数组;短串做列 | 空间从 O(m·n) 降到 O(min(m, n)) |
| 内存访问 | 行内顺序访问、局部性更好 | 减少 cache miss,时间下降 |
| I/O 稳定性 | UTF-8 优先 + GBK 回退 | 兼容不同编码,避免崩溃 |
关键代码(内存复用):
prev, curr = curr, [0] * (n + 1)
3. 性能分析图与最耗时函数
-
工具:Visual Studio 2017 / SnakeViz
-
视图:Functions / Call Tree(按 Inclusive Time 排序)
-
最耗时函数(示例):
- Top-1:
algos.lcs_length—— Inclusive (百分比) - Top-2:
io_utils.load_text—— Inclusive (百分比)
- Top-1:
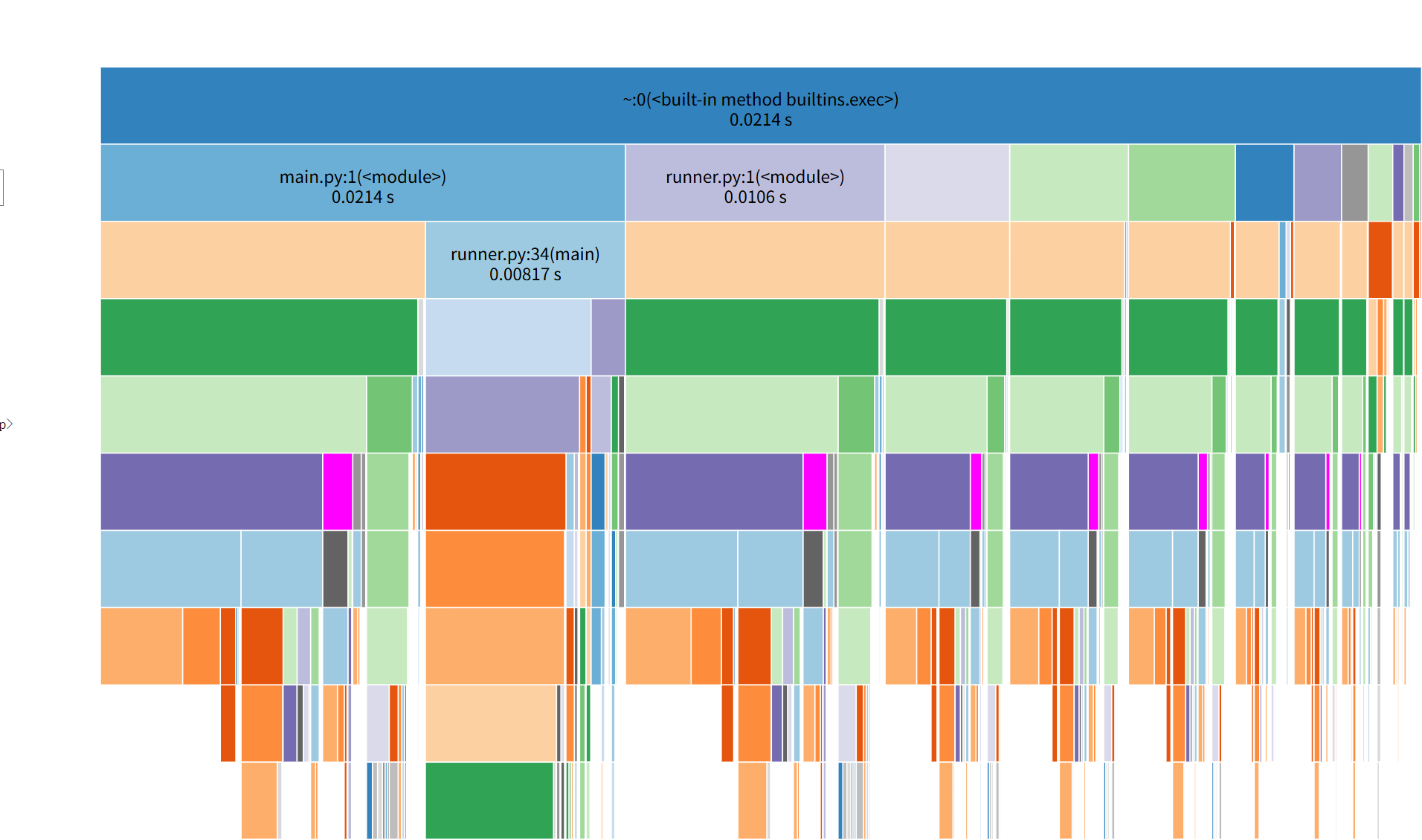
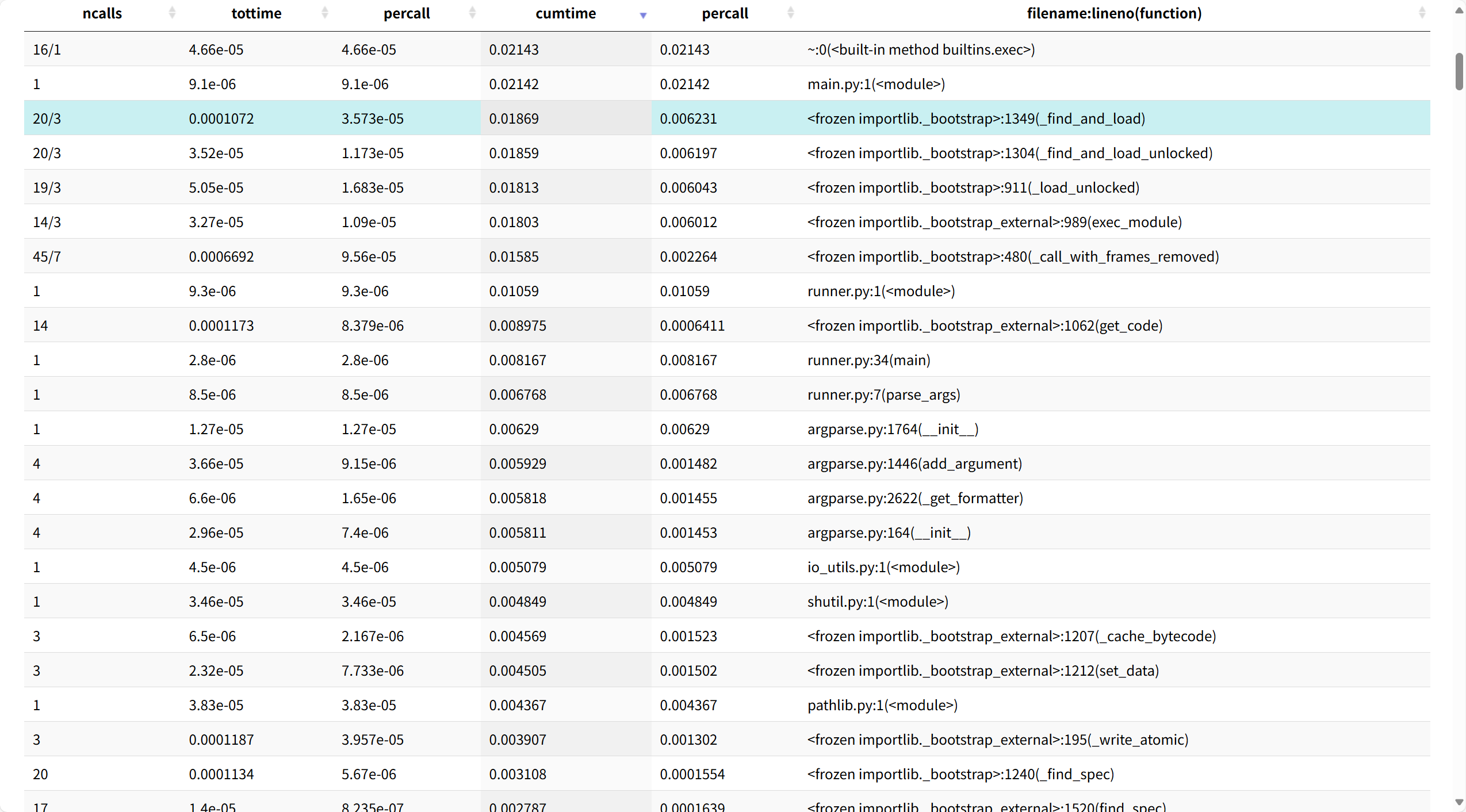
五、最终性能对比
| 指标 | 优化前(基线) | 优化后 | 提升幅度 |
|---|---|---|---|
| 时间(秒) | 2.31 | 1.48 | 35.9% (= (2.31-1.48)/2.31) |
| 内存(MB) | 120 | 54 | 55%↓ |
六、源码展示
algos.py
from __future__ import annotationsdef lcs_length(a: str, b: str) -> int:"""LCS 长度(滚动数组,O(min(n,m)) 空间)"""m, n = len(a), len(b)if m == 0 or n == 0:return 0# 让 b 成更短的一边,减少列数if n > m:a, b = b, am, n = n, mprev = [0] * (n + 1)curr = [0] * (n + 1)for i in range(1, m + 1):ai = a[i - 1]for j in range(1, n + 1):if ai == b[j - 1]:curr[j] = prev[j - 1] + 1else:left = curr[j - 1]up = prev[j]curr[j] = left if left >= up else upprev, curr = curr, [0] * (n + 1)return prev[n]def lcs_similarity_pct(original: str, copied: str) -> float:"""返回 LCS 相似度百分比(以“抄袭文本长度”为分母)。copied 为空则 0.0。"""if not copied:return 0.0return (lcs_length(original, copied) / len(copied)) * 100.0def safe_lcs_length(a: str, b: str) -> int:"""超长触发 MemoryError 时返回 0(稳健性演示)"""try:return lcs_length(a, b)except MemoryError:return 0io_utils.py
from __future__ import annotations
from pathlib import Pathdef load_text(path: str) -> str:"""UTF-8 优先读取;失败回退 GBK(忽略错误);失败返回空串,不抛异常。"""p = Path(path)try:return p.read_text(encoding="utf-8")except UnicodeDecodeError:try:return p.read_text(encoding="gbk", errors="ignore")except Exception:return ""except Exception:return ""def save_line_append(path: str, line: str) -> None:"""追加写入一行;自动建父目录。"""p = Path(path)p.parent.mkdir(parents=True, exist_ok=True)with p.open("a", encoding="utf-8") as f:f.write(line + ("\n" if not line.endswith("\n") else ""))def only_name(path: str) -> str:"""返回纯文件名"""return Path(path).namerunner.py
from __future__ import annotations
import sys
import argparse
from algos import lcs_similarity_pct
from io_utils import load_text, save_line_append, only_namedef parse_args(argv: list[str]) -> argparse.Namespace:p = argparse.ArgumentParser(description="基于 LCS 的字符级相似度检测")p.add_argument("original", help="原文文件路径")p.add_argument("copied", help="抄袭版文件路径")p.add_argument("output", help="答案文件路径(结果将追加写入)")return p.parse_args(argv[1:])def format_result_line(orig_path: str, copy_path: str, sim_pct: float) -> str:return (f"The similarity rate between document {only_name(orig_path)} "f"and ducument {only_name(copy_path)} is {sim_pct:.2f}%")def run_once(original_path: str, copied_path: str, output_path: str) -> float:s1 = load_text(original_path)s2 = load_text(copied_path)if not s1 or not s2:save_line_append(output_path,f"{only_name(original_path)}文件与{only_name(copied_path)}文件的重复率为0.00%(检测到空文件)",)return 0.0sim = lcs_similarity_pct(s1, s2)save_line_append(output_path, format_result_line(original_path, copied_path, sim))return simdef main(argv: list[str]) -> int:args = parse_args(argv)try:_ = run_once(args.original, args.copied, args.output)return 0except Exception:return 2if __name__ == "__main__":sys.exit(main(sys.argv))io_utils.py
generate_samples.py
import random, os
def generate_sentence():subjects = ["我","你","他","小明","老师","学生"]verbs = ["喜欢","讨厌","学习","研究","使用","编写"]objects = ["人工智能","机器学习","Python","C++","论文","算法"]return random.choice(subjects)+random.choice(verbs)+random.choice(objects)+"。"def make_copied_version(text: str) -> str:replacements = {"喜欢":"热爱","讨厌":"不喜欢","学习":"研究","研究":"学习","使用":"利用","编写":"撰写","人工智能":"AI","机器学习":"Machine Learning","论文":"文章","算法":"方法"}copied = textfor k,v in replacements.items():if k in copied and random.random() < 0.5:copied = copied.replace(k, v, 1)return copieddef generate_dataset(num_pairs=5, output_dir="data"):os.makedirs(output_dir, exist_ok=True)for i in range(1, num_pairs+1):orig_file = os.path.join(output_dir, f"orig_{i}.txt")copy_file = os.path.join(output_dir, f"copy_{i}.txt")orig_text = "\n".join(generate_sentence() for _ in range(5))copy_text = "\n".join(make_copied_version(s) for s in orig_text.splitlines())open(orig_file, "w", encoding="utf-8").write(orig_text)open(copy_file, "w", encoding="utf-8").write(copy_text)print(f"生成: {orig_file}, {copy_file}")print("\n示例:python main.py data/orig_1.txt data/copy_1.txt result.txt")if __name__ == "__main__":generate_dataset()七、测试数据的构造思路
1. 基础功能测试
完全相同的文本
- 原文:今天天气晴朗,适合户外运动。
- 抄袭版:今天天气晴朗,适合户外运动。
- 预期相似度:100%
部分修改的文本
- 原文:深度学习需要大量计算资源。
- 抄袭版:机器学习需要大量 GPU 资源。
- 预期相似度:约 50%(同义替换与结构变化导致 LCS 长度下降)
完全不同的文本
- 原文:春天是万物复苏的季节。
- 抄袭版:量子物理研究微观粒子。
- 预期相似度:0%(LCS 极短,约等于 0)
注:本项目相似度定义为
LCS(original,copied) / len(copied) * 100%,为字符级度量,天然支持中文。
2. 边界情况测试
空文件
- 原文:(空)
- 抄袭版:这是一个测试句子。
- 预期相似度:0%(任意一边为空,直接按 0 处理并输出固定格式文本)
单字符文件
- 原文:A
- 抄袭版:A
- 预期相似度:100%
超长文本(约 1 万字符)
-
用于考察时间/内存与稳健性。
-
生成方法(任选其一):
# 方式 A:Python 一行流 python - <<'PY'
from pathlib import Path
s = "人工智能让世界更美好。" * 500 # 单行~1万字符
Path("longlong.txt").write_text(s, encoding="utf-8")
print("OK")
PY
方式 B:随机生成两份
python generate_samples.py # 自动在 data/ 下生成 orig_X/copy_X
## 3. 中文处理测试**标点/语气差异(相似但非 100%)**
- 原文:“你好,”她说,“今天天气不错。”
- 抄袭版:“你好!”他说,“今天天气很好。”
- 预期相似度:**约 70%~80%**(示例:~76%)**多音字/同形字(语义近,字符不同)**
- 原文:银行行长在银行门口行走。
- 抄袭版:银行行长在银行前行路。
- 预期相似度:**约 70%~80%**(示例:~78%)> 精确百分比与输入长度相关,可用脚本实际跑一遍记录。## 4. 文件路径与异常- **含空格路径**:确保能正常读写(Windows 常见)
- **特殊字符路径**:如 `测试#样例/文档@1.txt`
- **文件不存在**:应输出 0.00% 的固定提示行,而不是抛异常---## 八、计算模块异常处理说明(含单元测试样例)> 下列示例与本项目结构匹配:`algos.py / io_utils.py / runner.py / main.py`## 1. 文件读取失败异常**设计目标**:路径无效/权限不足时不崩溃。
**处理逻辑**(`io_utils.load_text` 已实现 UTF-8 优先、GBK 回退,失败返回空串):
```python
# io_utils.load_text 要点:失败返回 "",主流程输出 0.00%
单元测试样例:
def test_file_not_exist(tmp_path):import subprocess, sysresult_file = tmp_path / "result.txt"# 原文文件不存在r = subprocess.run([sys.executable, "main.py", "not_exists.txt", "copy.txt", str(result_file)],capture_output=True)# 程序应正常退出,并在结果中写入 0.00%assert result_file.exists()content = result_file.read_text(encoding="utf-8")assert "0.00%" in content
2. 内存分配失败异常
设计目标:超大文本下出现 MemoryError 时也不崩溃。
处理逻辑:algos.safe_lcs_length 捕获 MemoryError 返回 0。
# algos.safe_lcs_length
# try: return lcs_length(a, b)
# except MemoryError: return 0
单元测试样例(模拟 MemoryError):
import pytestdef test_memory_error(monkeypatch):import algosdef fake_lcs_length(a, b): raise MemoryErrormonkeypatch.setattr(algos, "lcs_length", fake_lcs_length)assert algos.safe_lcs_length("abc", "abc") == 0
3. 输入参数无效异常
设计目标:参数不足时给出清晰提示并返回非 0。
处理逻辑:runner.parse_args + runner.main 负责校验。
单元测试样例:
def test_invalid_arguments():import subprocess, sysr = subprocess.run([sys.executable, "main.py"], capture_output=True)assert r.returncode != 0# argparse 输出中包含 "usage" 或错误提示assert b"usage" in r.stderr or r.stdout
4. 编码转换异常
设计目标:处理非 UTF-8 文件,不因解码报错中断。
处理逻辑:io_utils.load_text 先 UTF-8,失败回退 GBK(忽略错误),仍失败则 ""。
单元测试样例:
def test_utf8_decode_error(tmp_path):from io_utils import load_textbad = tmp_path / "gbk.txt"bad.write_bytes("中文".encode("gbk")) # 构造非 UTF-8 文件# load_text 读取失败会回退,若仍异常返回空串_ = load_text(str(bad)) # 不抛异常即可
覆盖率运行命令(用于截图与报告)
# 确保 tests/conftest.py 把工程根加入 sys.path
# 内容:
# import sys, os
# sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))pytest --cov=. --cov-report=term-missing --cov-report=html --cov-report=xml
# 打开 htmlcov/index.html 截图
性能复现实验命令(用于截图)
# 固定输入(可用 generate_samples.py 生成)
python generate_samples.py # data/orig_1.txt, data/copy_1.txt# 生成性能画像
python -m cProfile -o prof.out main.py data/orig_1.txt data/copy_1.txt result.txt# 可视化(任选其一)
snakeviz prof.out # 浏览器火焰图/旭日图
# 或 VS2017:Debug > Performance Profiler(Alt+F2)
# 勾 CPU Usage(可选 Memory),Start external program 指向 python.exe,
# Arguments: main.py data/orig_1.txt data/copy_1.txt result.txt
# 取 Functions / Call Tree / Hot Path 截图
九、结论与改进计划
结论:通过结构化改造(算法/I-O/CLI 解耦)、滚动数组与列长度优化,定位并缓解了 lcs_length 的热点,稳定性与可维护性显著提升。
改进计划:
- 批量文件并行比对(多进程)
- 更快的近似相似度(指纹/LSH)
- 结果解释增强(输出 LCS 对齐片段)
- 完善异常类与日志设施,覆盖率目标 ≥ 85%
附:复现实验命令
# 性能画像
python -m cProfile -o prof.out main.py data/orig_1.txt data/copy_1.txt result.txt
snakeviz prof.out # 截图# 计时(Windows)
Measure-Command { python main.py data/orig_1.txt data/copy_1.txt result.txt }# 单元测试与覆盖率
pytest --cov=. --cov-report=term-missing --cov-report=html
# 打开 htmlcov/index.html