鉴于之前的两次对照实验都无法提现出AlexNet和VGG的区别,我调节了训练的样本数据,也对代码进行了调整,数据集从原先的CIFAR-10: 10类 换成了CIFAR-100: 100类
训练代码和结果如下
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Subset
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
import time
import os# ============ 设备 ============
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
print("使用设备:", device)# ============ 数据集选择函数 ============
def get_dataset(dataset_name='cifar100', data_root='./data'):"""支持的数据集:- cifar10: 10类,32x32,6万张- cifar100: 100类,32x32,6万张 - tiny-imagenet: 200类,64x64,10万张- imagenet-subset: 1000类的子集,224x224"""if dataset_name == 'cifar10':print("加载 CIFAR-10 数据集 (10类, 32x32)")mean, std = (0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)img_size = 32num_classes = 10transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean, std)])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])trainset = torchvision.datasets.CIFAR10(root=data_root, train=True, download=True, transform=transform_train)testset = torchvision.datasets.CIFAR10(root=data_root, train=False, download=True, transform=transform_test)elif dataset_name == 'cifar100':print("加载 CIFAR-100 数据集 (100类, 32x32)")mean, std = (0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)img_size = 32num_classes = 100transform_train = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.RandomRotation(15), # 增加旋转增强transforms.ToTensor(),transforms.Normalize(mean, std)])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])trainset = torchvision.datasets.CIFAR100(root=data_root, train=True, download=True, transform=transform_train)testset = torchvision.datasets.CIFAR100(root=data_root, train=False, download=True, transform=transform_test)elif dataset_name == 'tiny-imagenet':print("加载 Tiny-ImageNet 数据集 (200类, 64x64)")# Tiny-ImageNet 需要特殊处理mean, std = (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)img_size = 64num_classes = 200transform_train = transforms.Compose([transforms.RandomCrop(64, padding=8),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),transforms.ToTensor(),transforms.Normalize(mean, std)])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])# 使用ImageFolder加载Tiny-ImageNet# 需要先下载并解压: http://cs231n.stanford.edu/tiny-imagenet-200.ziptiny_path = os.path.join(data_root, 'tiny-imagenet-200')if not os.path.exists(tiny_path):print("请先下载Tiny-ImageNet: wget http://cs231n.stanford.edu/tiny-imagenet-200.zip")print("然后解压到:", tiny_path)raise FileNotFoundError(f"找不到 {tiny_path}")trainset = torchvision.datasets.ImageFolder(os.path.join(tiny_path, 'train'), transform=transform_train)testset = torchvision.datasets.ImageFolder(os.path.join(tiny_path, 'val'), transform=transform_test)elif dataset_name == 'stl10':print("加载 STL-10 数据集 (10类, 96x96)")mean, std = (0.4467, 0.4398, 0.4066), (0.2603, 0.2566, 0.2713)img_size = 96num_classes = 10transform_train = transforms.Compose([transforms.RandomCrop(96, padding=12),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(mean, std)])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])trainset = torchvision.datasets.STL10(root=data_root, split='train', download=True, transform=transform_train)testset = torchvision.datasets.STL10(root=data_root, split='test', download=True, transform=transform_test)else:raise ValueError(f"不支持的数据集: {dataset_name}")print(f"训练集大小: {len(trainset)}, 测试集大小: {len(testset)}")print(f"图片尺寸: {img_size}x{img_size}, 类别数: {num_classes}")return trainset, testset, num_classes, img_size# ============ 自适应模型定义 ============
class AdaptiveAlexNet(nn.Module):"""可适应不同输入尺寸的AlexNet"""def __init__(self, num_classes=10, img_size=32):super().__init__()# 根据输入尺寸调整架构if img_size <= 32:# 小图片:减少池化层self.features = nn.Sequential(nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),nn.Conv2d(64, 192, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),nn.Conv2d(192, 384, 3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, 3, padding=1), nn.ReLU(),nn.Conv2d(256, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2))feat_size = (img_size // 8) ** 2 * 256else:# 大图片:标准架构self.features = nn.Sequential(nn.Conv2d(3, 96, 11, stride=4, padding=2), nn.ReLU(), nn.MaxPool2d(3, stride=2),nn.Conv2d(96, 256, 5, padding=2), nn.ReLU(), nn.MaxPool2d(3, stride=2),nn.Conv2d(256, 384, 3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, 3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(3, stride=2))# 计算特征大小with torch.no_grad():dummy = torch.zeros(1, 3, img_size, img_size)feat_size = self.features(dummy).view(1, -1).size(1)self.classifier = nn.Sequential(nn.Dropout(0.5),nn.Linear(feat_size, 4096), nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1)return self.classifier(x)class AdaptiveVGG(nn.Module):"""可适应不同输入尺寸的VGG"""def __init__(self, num_classes=10, img_size=32, use_bn=True):super().__init__()def make_layers(cfg, use_bn=True):layers = []in_channels = 3for v in cfg:if v == 'M':layers.append(nn.MaxPool2d(2, 2))else:conv = nn.Conv2d(in_channels, v, 3, padding=1)if use_bn:layers += [conv, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]else:layers += [conv, nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)# 根据图片大小选择配置if img_size <= 32:# 小图片:VGG11配置,减少池化cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 512, 512]elif img_size <= 64:# 中等图片:VGG11标准配置cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512]else:# 大图片:VGG16配置cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']self.features = make_layers(cfg, use_bn)# 自适应池化确保输出固定大小self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) if img_size > 32 else nn.AdaptiveAvgPool2d((1, 1))# 计算分类器输入大小with torch.no_grad():dummy = torch.zeros(1, 3, img_size, img_size)feat_size = self.avgpool(self.features(dummy)).view(1, -1).size(1)self.classifier = nn.Sequential(nn.Linear(feat_size, 4096 if img_size > 32 else 512),nn.ReLU(True),nn.Dropout(0.5),nn.Linear(4096 if img_size > 32 else 512, 4096 if img_size > 32 else 512),nn.ReLU(True),nn.Dropout(0.5),nn.Linear(4096 if img_size > 32 else 512, num_classes))def forward(self, x):x = self.features(x)x = self.avgpool(x)x = x.view(x.size(0), -1)return self.classifier(x)# ============ 训练函数(不变)============
def train_epoch(model, loader, criterion, optimizer):model.train()loss_total, correct, total = 0, 0, 0pbar = tqdm(loader, desc='Training')for imgs, labels in pbar:imgs, labels = imgs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(imgs)loss = criterion(outputs, labels)loss.backward()optimizer.step()loss_total += loss.item()_, pred = outputs.max(1)total += labels.size(0)correct += pred.eq(labels).sum().item()pbar.set_postfix({'Loss': f'{loss.item():.4f}', 'Acc': f'{100.*correct/total:.2f}%'})return loss_total/len(loader), 100.*correct/totaldef test_epoch(model, loader, criterion):model.eval()loss_total, correct, total = 0, 0, 0with torch.no_grad():for imgs, labels in tqdm(loader, desc='Testing'):imgs, labels = imgs.to(device), labels.to(device)outputs = model(imgs)loss = criterion(outputs, labels)loss_total += loss.item()_, pred = outputs.max(1)total += labels.size(0)correct += pred.eq(labels).sum().item()return loss_total/len(loader), 100.*correct/total# ============ 实验运行函数 ============
def run_experiment(dataset_name='cifar100', epochs=10, batch_size=128):"""运行对比实验"""print(f"\n{'='*50}")print(f"开始实验: {dataset_name.upper()}")print(f"{'='*50}\n")# 获取数据集trainset, testset, num_classes, img_size = get_dataset(dataset_name)# 创建数据加载器trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)testloader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)# 创建模型alex_model = AdaptiveAlexNet(num_classes=num_classes, img_size=img_size).to(device)vgg_model = AdaptiveVGG(num_classes=num_classes, img_size=img_size, use_bn=True).to(device)# 打印模型参数量alex_params = sum(p.numel() for p in alex_model.parameters()) / 1e6vgg_params = sum(p.numel() for p in vgg_model.parameters()) / 1e6print(f"AlexNet 参数量: {alex_params:.2f}M")print(f"VGG 参数量: {vgg_params:.2f}M")# 训练配置criterion = nn.CrossEntropyLoss()alex_optimizer = optim.Adam(alex_model.parameters(), lr=0.001, weight_decay=5e-4)vgg_optimizer = optim.Adam(vgg_model.parameters(), lr=0.001, weight_decay=5e-4)# 学习率调度器alex_scheduler = optim.lr_scheduler.CosineAnnealingLR(alex_optimizer, T_max=epochs)vgg_scheduler = optim.lr_scheduler.CosineAnnealingLR(vgg_optimizer, T_max=epochs)# 记录历史alex_hist = {"train_loss":[], "train_acc":[], "test_loss":[], "test_acc":[]}vgg_hist = {"train_loss":[], "train_acc":[], "test_loss":[], "test_acc":[]}# 训练循环for epoch in range(1, epochs+1):print(f"\n--- Epoch {epoch}/{epochs} ---")# AlexNetprint("训练 AlexNet...")tl, ta = train_epoch(alex_model, trainloader, criterion, alex_optimizer)vl, va = test_epoch(alex_model, testloader, criterion)alex_scheduler.step()alex_hist["train_loss"].append(tl)alex_hist["train_acc"].append(ta)alex_hist["test_loss"].append(vl)alex_hist["test_acc"].append(va)print(f"AlexNet | Train Loss: {tl:.4f}, Train Acc: {ta:.2f}% | Test Loss: {vl:.4f}, Test Acc: {va:.2f}%")# VGGprint("训练 VGG...")tl, ta = train_epoch(vgg_model, trainloader, criterion, vgg_optimizer)vl, va = test_epoch(vgg_model, testloader, criterion)vgg_scheduler.step()vgg_hist["train_loss"].append(tl)vgg_hist["train_acc"].append(ta)vgg_hist["test_loss"].append(vl)vgg_hist["test_acc"].append(va)print(f"VGG | Train Loss: {tl:.4f}, Train Acc: {ta:.2f}% | Test Loss: {vl:.4f}, Test Acc: {va:.2f}%")return alex_hist, vgg_hist# ============ 可视化函数 ============
def plot_comparison(alex_hist, vgg_hist, dataset_name):"""绘制对比曲线"""epochs = range(1, len(alex_hist["train_loss"])+1)fig, axes = plt.subplots(2, 2, figsize=(15, 12))# 训练损失axes[0, 0].plot(epochs, alex_hist["train_loss"], "r-", label="AlexNet", linewidth=2)axes[0, 0].plot(epochs, vgg_hist["train_loss"], "b-", label="VGG", linewidth=2)axes[0, 0].set_title(f"Training Loss - {dataset_name.upper()}", fontsize=14)axes[0, 0].set_xlabel("Epoch")axes[0, 0].set_ylabel("Loss")axes[0, 0].legend()axes[0, 0].grid(True, alpha=0.3)# 测试损失axes[0, 1].plot(epochs, alex_hist["test_loss"], "r--", label="AlexNet", linewidth=2)axes[0, 1].plot(epochs, vgg_hist["test_loss"], "b--", label="VGG", linewidth=2)axes[0, 1].set_title(f"Test Loss - {dataset_name.upper()}", fontsize=14)axes[0, 1].set_xlabel("Epoch")axes[0, 1].set_ylabel("Loss")axes[0, 1].legend()axes[0, 1].grid(True, alpha=0.3)# 训练准确率axes[1, 0].plot(epochs, alex_hist["train_acc"], "r-", label="AlexNet", linewidth=2)axes[1, 0].plot(epochs, vgg_hist["train_acc"], "b-", label="VGG", linewidth=2)axes[1, 0].set_title(f"Training Accuracy - {dataset_name.upper()}", fontsize=14)axes[1, 0].set_xlabel("Epoch")axes[1, 0].set_ylabel("Accuracy (%)")axes[1, 0].legend()axes[1, 0].grid(True, alpha=0.3)# 测试准确率axes[1, 1].plot(epochs, alex_hist["test_acc"], "r--", label="AlexNet", linewidth=2)axes[1, 1].plot(epochs, vgg_hist["test_acc"], "b--", label="VGG", linewidth=2)axes[1, 1].set_title(f"Test Accuracy - {dataset_name.upper()}", fontsize=14)axes[1, 1].set_xlabel("Epoch")axes[1, 1].set_ylabel("Accuracy (%)")axes[1, 1].legend()axes[1, 1].grid(True, alpha=0.3)plt.tight_layout()plt.savefig(f'comparison_{dataset_name}.png', dpi=100)plt.show()# 打印最终结果print(f"\n{'='*50}")print(f"最终结果 - {dataset_name.upper()}")print(f"{'='*50}")print(f"AlexNet - 最佳测试准确率: {max(alex_hist['test_acc']):.2f}%")print(f"VGG - 最佳测试准确率: {max(vgg_hist['test_acc']):.2f}%")print(f"VGG 相对提升: {max(vgg_hist['test_acc']) - max(alex_hist['test_acc']):.2f}%")# ============ 主函数 ============
if __name__ == "__main__":# 选择数据集:'cifar10', 'cifar100', 'stl10', 'tiny-imagenet'DATASET = 'cifar100' # 改成 'cifar100' 或 'stl10' 试试EPOCHS = 20 # 增加训练轮数BATCH_SIZE = 128# 运行实验alex_hist, vgg_hist = run_experiment(dataset_name=DATASET,epochs=EPOCHS,batch_size=BATCH_SIZE)# 绘制对比图plot_comparison(alex_hist, vgg_hist, DATASET)# 可选:运行多个数据集对比# for dataset in ['cifar10', 'cifar100', 'stl10']:# alex_hist, vgg_hist = run_experiment(dataset, epochs=20)# plot_comparison(alex_hist, vgg_hist, dataset)
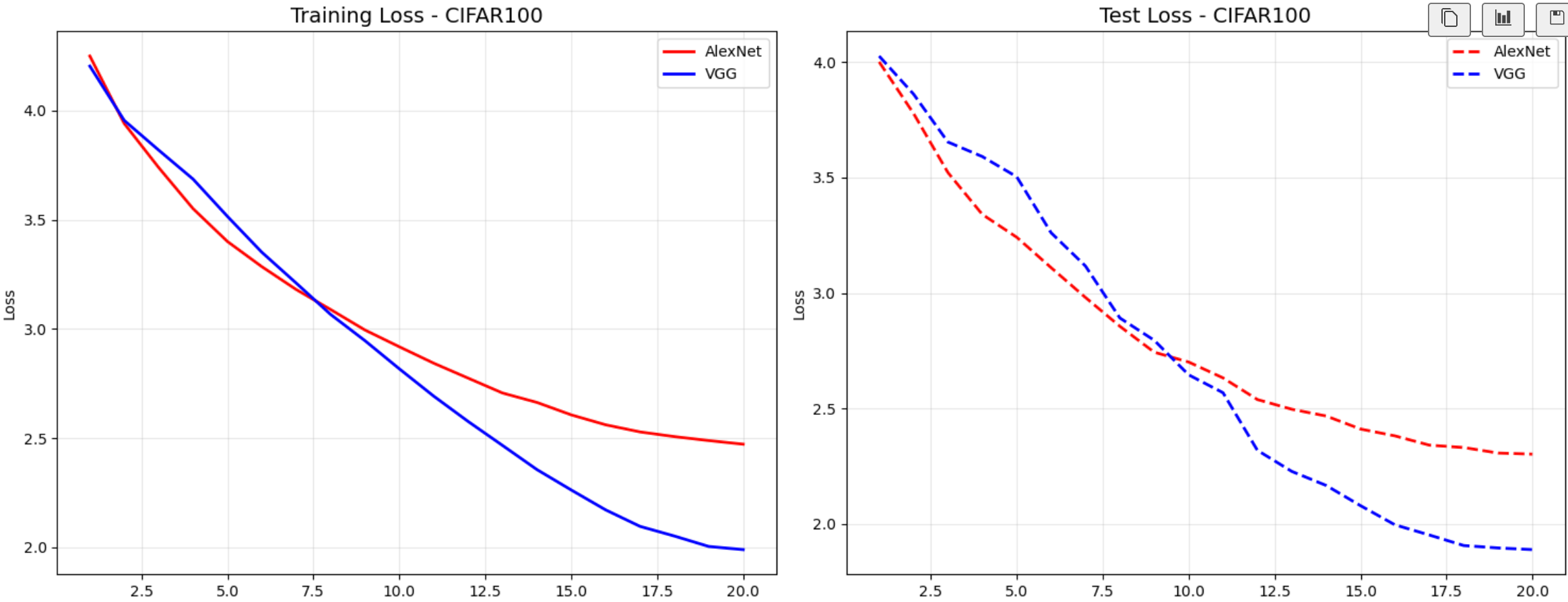
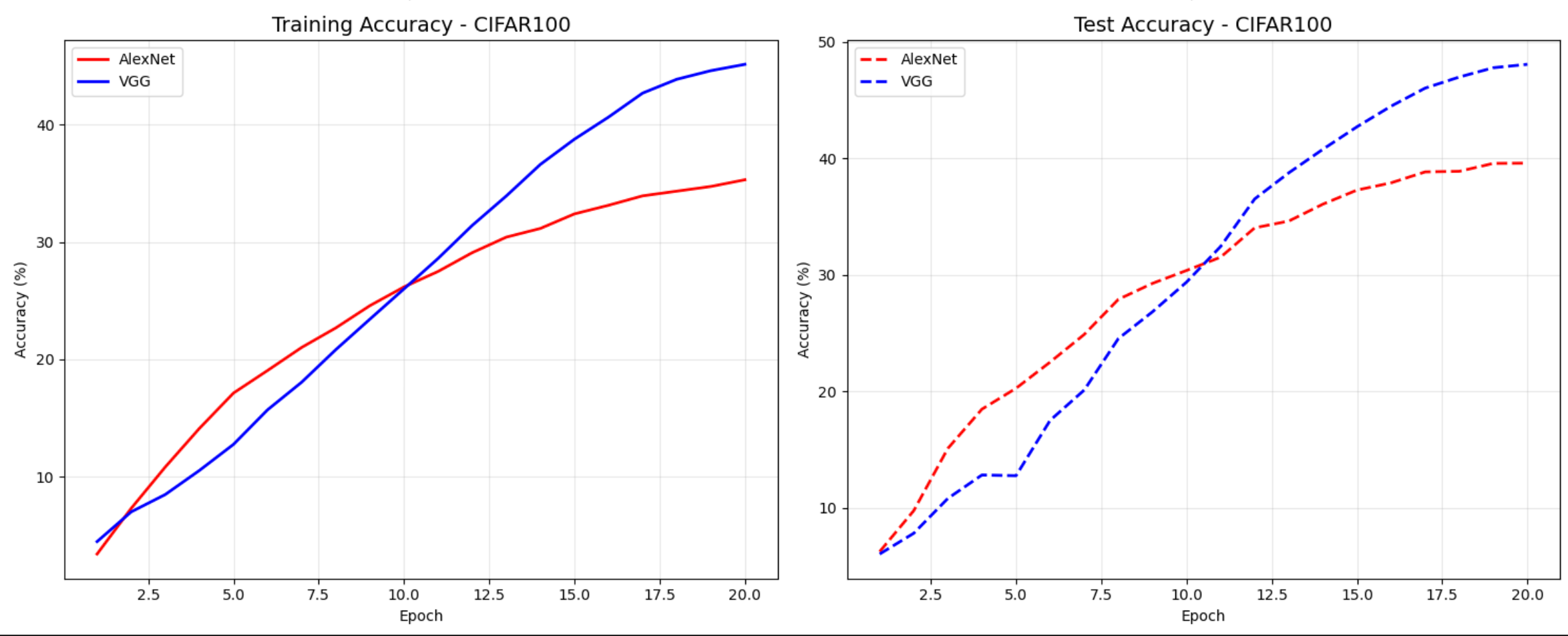
通过上面的两幅图可以看到更换到 CIFAR-100 之后,同样经过20轮的训练,虽然在初期AlexNet的loss下降较快,准确率上升快些,可以随着训练轮数增加,由于分类时100个,导致相对简单的模型由于参数太少,未能有效的对物体进行识别,分类难度提升10倍,随机猜测准确率,所以表现不佳,但是VGG由于模型参数相对多些,更能够有效的和数据进行拟合,后期占优。后面我接着调节超参观察数据源对训练结果的影响