0 序
Power BI
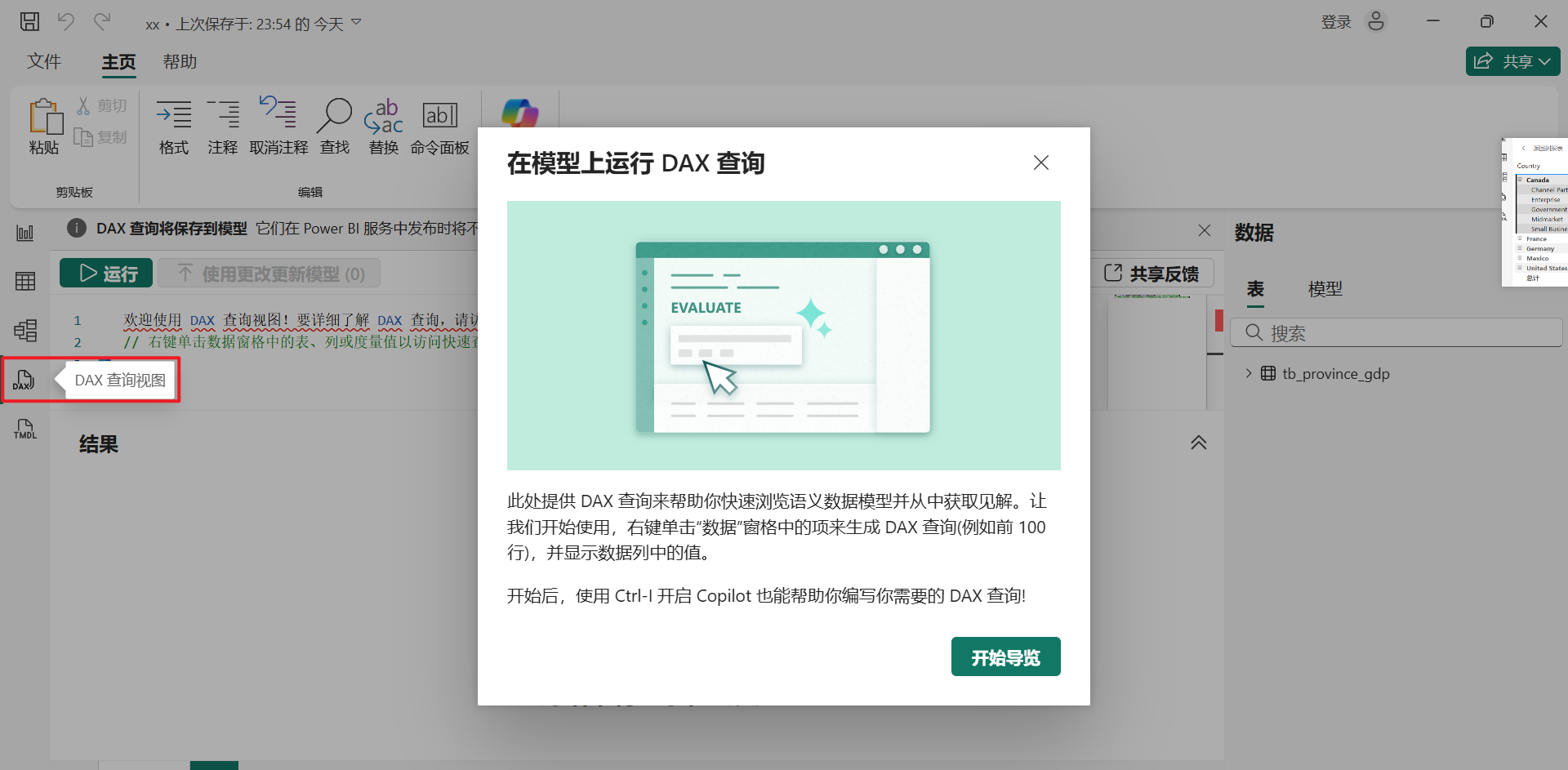
1 概述:DAX 查询视图语言 = Data Analysis eXpressions(数据分析表达式) = 编程式数据分析语言 for Power BI / SSAS / ...
DAX是什么?
DAX全称Data Analysis eXpressions(数据分析表达式);
其是面向Microsoft Power BI、Microsoft SQL Server Analysis Services(SSAS)和Microsoft Power Pivot for Excel的编程式数据分析语言。
它创建于 2010 年,随Power Pivot的第一个版本PowerPivot for Excel 2010一起发布。
随着时间的推移,DAX 已经在商业智能和Excel社区中逐渐流行起来。
图: DAX 适用范围
DAX 的简单和复杂
- 微软在官方的介绍中称
DAX是一种简单的语言。
也就是说,
DAX的基本知识简单易学:你可以在几小时内开始使用。
这确实是事实,微软在开发DAX的时候从 Excel 中移植了很多函数,它们名称相同,参数用法也类似。
但我想告诉你的是,这种简单仅限于起步阶段。
DAX和大多数编程语言不同,它有很多独特且重要的理论,一旦涉及到这些概念,比如计值上下文、迭代和上下文转换,一切都将变得复杂起来。
但不要放弃!请保持耐心。
一旦你的大脑开始理解这些概念,你就会发现 DAX 确实是一种简单的语言,只是需要时间去适应。
学习 DAX 的误区
- 不同于其他语言,
DAX需要你理解它的原理之后才能熟练使用,如果你习惯于通过学习具体的函数建立起一门语言的知识体系(比如 Excel 函数),请千万不要将这种习惯带入到DAX的学习中。
因为它的一些原理很难通过归纳法(从具体实例推导出普遍规律的一种方法)来理解。
例如,对计值上下文(The Evaluation Context)的理解需要用到演绎推理:先接触理论本身,然后通过案例加深对理论的理解。
我知道许多人不习惯这种学习方式,他们更喜欢在实践中学习,先研究如何解决具体问题,然后通过不断的练习和积累,归纳出公式背后的原理。
如果你使用这种方式学习,会常常发现写出的公式能得出正确结果,但自己却不明白为什么。
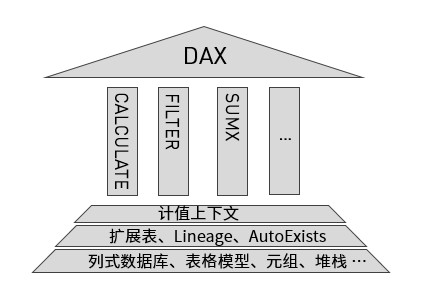
图: DAX 的理论基石
DAX 的优势
- 前文我们提到过,
DAX可以运行在Power BI、SQL Server Analysis Services(SSAS)和Power Pivot for Excel中,本质上它们都是SSAS的表格模型,只是形式略有不同。
Power Pivot for Excel运行了一个SSAS表格模型的本地实例,而Power BI使用一个单独的进程运行一个特殊的表格模型实例。
这是一个基于内存的列式数据库分析引擎。
DAX 引擎 = VertiPaq 引擎 = 基于内存的列式数据库引擎
-
DAX的能力蕴含在SSAS表格模型的引擎,我们称之为VertiPaq引擎,这是它在开发阶段的工程名称,大家已经习惯用这个名称代替它的官方用名「xVelocity内存分析引擎」。 -
Vertipaq是基于内存的列式数据库引擎,模型的所有数据都驻留在【内存】中。
在 Vertipaq 引擎内部,数据以列式存储,而传统的 SQL 数据库引擎通常使用行式存储。
简单的说,行式存储适合进行事务处理(OLTP),比如增删改查;而列式存储则适合分析决策(OLAP),比如多维分析。
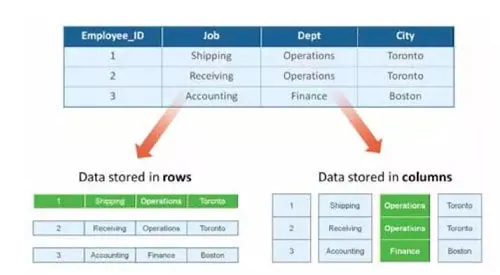
图: 行式存储和列式存储
- 列式数据库的优点:
- 高效的压缩比
- 不靠索引来优化查询
- 更适合大量的数据
- 天生适合聚合运算
在这个基础上,基于内存的列式数据库还有比硬盘快 10 倍左右的数据读取速度。
这也是为什么当今主流的BI工具和大数据分析工具全部采用【内存式数据库】的原因。
所以,DAX是非常适合计算的语言,我曾经在Excel Power Pivot里测试过装载并分析一亿行数据,理论上完全没有问题。
关于 DAX 引擎,后面会有专门的章节详细分析,这里我们只做最简单的介绍。
DAX 能分析多少数据
你已经了解了这颗引擎的强大之处,它绝不是吃素的,它带给你的一个直观感受就是数据处理能力的飞跃。
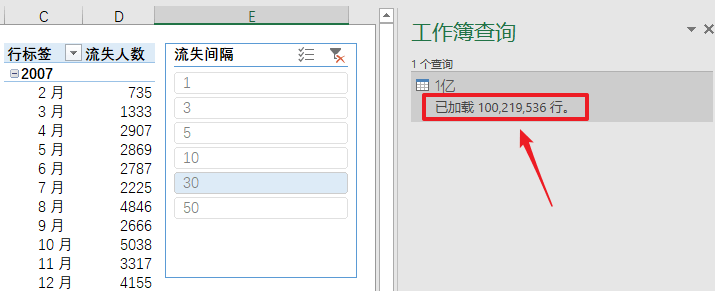
图: Excel 加载一亿行数据
Excel:
将 Excel自身的数据处理能力提升到了前所未有的高度,复杂公式几千行数据就跑不动?
vlookup几万条就开始卡顿?不存在的,Power Pivot让你可以轻松处理几百万乃至上千万的数据,即使一些复杂的计算逻辑,DAX引擎也能在眨眼间完成计算。
Power BI Desktop:
DAX 引擎版本比 Power Pivot 更高,性能也有所提升,不过这种提升不太容易被量化。一般来说,处理相同数据量级和复杂度的分析,比 Excel 表现要好。
与其他 BI 工具相比,
Power BI的一大特点就是拥有自己的数据引擎和分析语言,靠的是微软在数据库领域深厚的积累,绝非一日之功。
SSAS:
具备完整的 DAX 引擎,处理能力最强,可以参考下面这张表

图: SSAS 可以处理的数据量及建议
动态计算的能力
- 除了能分析大量的数据,
DAX还可以根据计值环境(筛选上下文)的变化,【自动重新计算】。
这是商业分析一项非常重要的能力,在解读数据报告的时候,我们需要基于业务特点不断的提出新的问题,并且这些问题需要立即得到回答,这样才能最大程度挖掘数据的价值,而不是像过去那样,分析师重新写 SQL,重新运行,然后所有人等待结果。
这也是
DAX和 Excel 公式、VBA 或者 PQ 的一个最大的不同,这些语言都没法做到 DAX 一样的灵活性,它们必须重新编辑公式、再次点击运行然后等待结果产生,而DAX 可以默默帮你完成所有步骤。允许你以思维的速度展开分析。
- 这种动态计算的能力也是所有
BI工具的标配,并非 Power BI 独有。
值得一提的是很多分析语言,比如 SQL,Python,R 也可以实现类似的灵活性,比如 R 的 Shiny 可以动态计算。但需要做二次开发,不适合没有技术背景的普通业务人员。
DAX可以根据环境的变化【自动重新计算】,但严格来说,它不是动态语言,后者编程语言中的一个专有名词:动态类型语言,是指数据类型的检查是在计算时进行的。用动态类型语言编程时,不用给变量指定【数据类型】,语言会在你第一次赋值给【变量】时,在内部记录【数据类型】。
2 DAQ 基础知识
数据模型 – Power BI的灵魂
从本节开始,我们进入 DAX 基础知识章节。
Power BI是由模型驱动的工具,合理的模型结构可以简化日后编写公式和维护报告的工作量,失败的模型结构会让一切变的复杂
为什么使用数据模型 ——> Power BI 作为基于模型驱动的 BI 工具
- 在对
Power BI的错误认识中,认为它是一个数据可视化工具的大有人在,实际上Power BI是一个基于数据模型的工具。
它使用独有的语言(
DAX)在语义层(Semantic layer)定义度量值的业务逻辑,并允许使用两种语言查询数据模型:DAX和MDX,后者已经成为行业标准语言。
- 之所以选择
DAX和MDX,而不是更常见的SQL,是因为SQL不适合用于语义层。
在企业 BI 工具的漫长历史中,即使工具生成
SQL查询,也不可能在SQL中定义通用业务规则,除非是在数据源的行级别进行非常简单的计算。
例如,假设计算利润率%需要用到两张表, 在 SQL 中定义除以两个聚合结果的通用计算是一项复杂的任务。
每个工具都发明了自己的方法来解决这一问题。
用SQL表示这种计算需要一个非常具体的查询,并且不具有足够的通用性,不能与同一查询中的任何筛选器、聚合或其他度量值的组合一起使用。
- 备注
我们使用的
BI工具要么是基于报表的(Report-Based),要么是基于模型的(Model-Based),前者的代表是Tableau,后者包括Qlik、BO等工具。
Tableau在报表级别的计算上拥有很好的灵活性和用户体验,官方建议使用【宽表】作为数据源,即便通过数据融合可以执行跨表计算,但出于性能考虑,需要谨慎评估。
数据模型是什么
- 模型对于
Excel用户和数据分析的新手可能是个比较陌生的概念,但我想大部分人应该都听说过以下这些模型:回归模型、分类模型、决策树模型、朴素贝叶斯模型。
图: 算法模型示例
它们都属于算法模型的范畴,实现了 输入- 处理 – 输出 这样一个过程。
算法模型用途广泛,但不是这里要讨论的内容,我们介绍的是另一种模型:数据模型,【数据模型】是【现实世界的抽象】。举个例子:超市昨天一共产生多少笔订单,每笔订单包含哪些商品,每种商品又由哪些原材料构成。
我们把这些数据记录到表中,再导入数据库。这个时候你通过查询数据库就可以掌握超市的运营情况,【单表】可以视为结构简单的模型,通常我们研究的是基于多张表的模型,这时就引入了现实世界中的一个重要概念:关系。一旦【表】和【表】之间建立了【关系】,我们就摆脱了【单表】的束缚,可以在不同的表之间进行查询。
你可以把【关系】想象成 Excel 中的 VLOOKUP,实际上【关系】要灵活和强大的多。
“烂程序员关心的是代码,好程序员关心的是数据结构和他们之间的关系” —— Linux 创始人 Torvalds
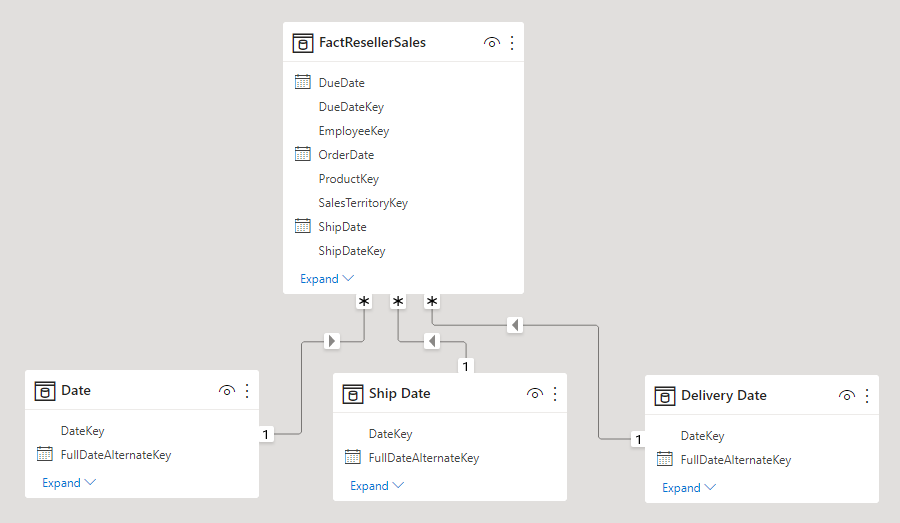
图: 数据模型示意图
有哪些常用的数据模型
数据模型,对于数据库使用者是一个很重要的概念,普通 BI 用户不必了解背后的所有内容,只需要掌握一些基本知识即可。
ER 模型(Entity Relationship Model)
- 实体关系模型,用实体加关系构成的数据模型描述企业业务架构,在【范式理论】上符合三范式,是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系抽象,它更多是面向数据的整合和一致性治理,为基础数据仓库建设服务。
维度建模
- 星型模型和雪花模型都是【维度建模】中的常用模型
【维度建模】以【分析决策的需求】出发构建模型,构建的数据模型为分析需求服务。
因此,它的【重点】是:解决用户如何更快速完成分析,同时还有较好的大规模复杂查询的响应性能,更直接面向业务。
- 【维度模型】最基本的两个要素是【事实表(明细表)】和【维度表】:
- 事实表:一般由两部分组成,维度和度量,通俗的理解为“某人在某个时间什么条件下做了什么事情”的事实记录,它拥有最大的数据量,储存了大部分定量数据,是业务流程的核心体现。
- 维度表:对事实表的补充说明,描述和还原事实发生时的场景,包含产品、人员、地点等定性数据,也包括时间数据(比如日期维度表)。
在星型架构中,最一致的表是日期维度表。 维度表包含用作唯一标识符的键列(一列或多列)以及描述性的列。
- 通常情况下,【维度表】包含的行数相对较少,更新频率较低。而【事实数据表】可能包含非常多的行,并且行数会随着时间的推移不断增长。
星型模型:事实表位于中心,维度表直接与事实表建立关系
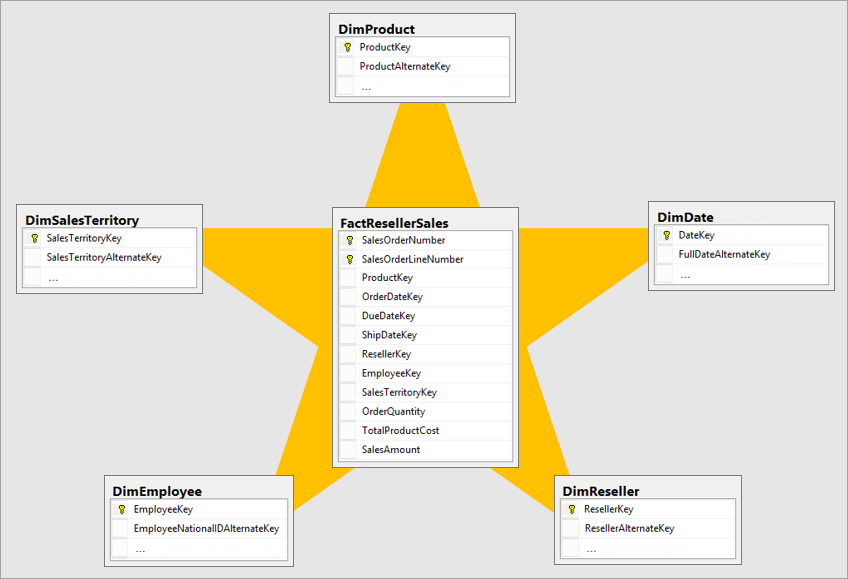
图: 星型模型示意图(来自官方文档)
雪花模型:经过规范化存储的维度表,多张维度表连接在一起,单表没有冗余
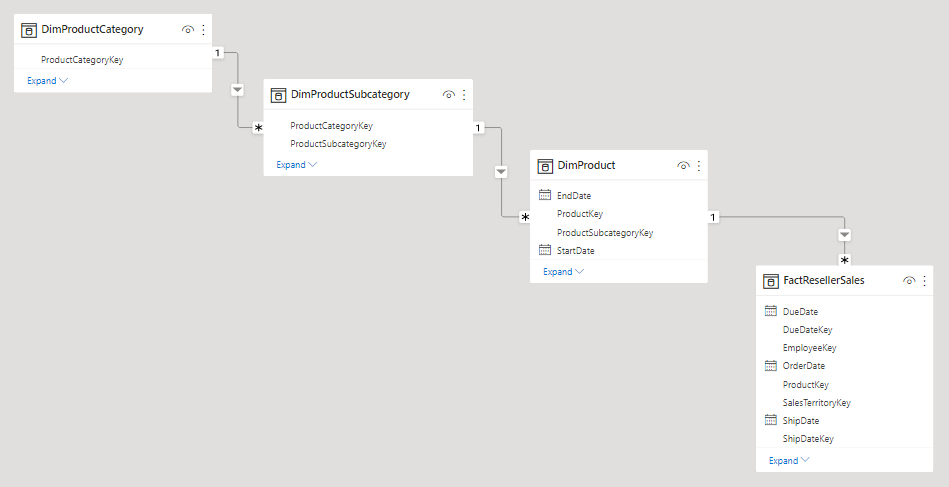
图: 雪花模型局部示意图(来自官方文档)
- 备注
模型的设计和优化是一门科学,也是一门艺术。
如果你想深入学习这部分内容,还需要接触类似【缓慢变化维】、【代理键】这些专业词汇,Power BI官方文档中对这部分内容有比较详细的介绍,可以参考文末的扩展阅读链接,作为基础章节,这里不对星型模型和雪花模型做深入介绍,但仍有一点值得指出:星型模型是更适合Power BI建模使用的结构
理解 Power BI 中的数据模型
DAX是一种专门为计算数据模型中的商业逻辑而设计的语言。
看完前面的介绍,你已经对数据模型有了一个初步的认识,如果你还不熟悉它,那么花些时间来介绍数据模型和关系是很有必要的,因为这些概念是你建立
DAX知识的基石。
数据模型是一组通过关系连接到一起的表
- 我们都知道什么是表:一组包含数据的行,每一行被列分割,每列都有指定的数据类型,并且只包含一种信息。
我们通常将表中的一行称为【记录】。
【表】是管理数据的一种简便方法,【表】的本身已经是一个【数据模型】,尽管这是最简单的形式。因此,当你在
Excel【工作簿】中填写名称和数字时,你正在创建一个【数据模型】。
【备注】
此处的表对应 Excel 中的智能表格(Excel Table),又叫超级表,是从 Excel 2013 出现的功能。
智能表格拥有自己的名称,具备自动填充、自动扩展的特性,并不是普通的工作表或工作表中存放数据的普通区域。
智能表经常作为 Power Query 的数据源。
图: Excel 智能表示例(来自官方文档)
- 如果数据模型包含许多【表】,通常它们是通过【关系】连接的。
【关系】建立在两个表之间。当两个【表】通过【关系】连接在一起时,我们说它们是【相关联的】。
从【图形】上看,【关系】由【连接】两个【表】的直线表示。下图显示了一个数据模型的示例。
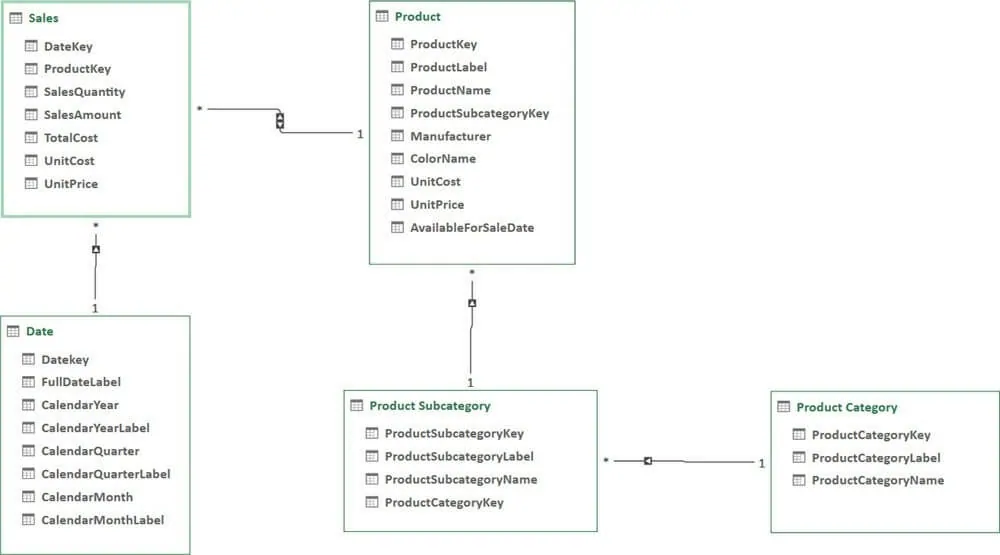
图: 由五张表组成的数据模型示意图
- 学习【关系】你需要了解的重要知识点:
- 【关系】中的两个表承担不同的角色,他们被称为【关系】的【一端】和【多端】。
在图 1-1 中,注意 Product 表和 Product Subcategory 表之间的关系。一个子类别中包含许多产品,而单个产品只能有一个子类别。因此,Product Subcategory 表位于关系的“一”端(每行有一个子类),而 Product 位于“多”端(对应了很多产品)。
- 用于创建关系的列(通常在两个表中具有相同的名称)称为关系的键。在关系的一端,列的每一行需要有唯一的值。在关系的多端,相同的值通常在不同的行重复出现。如果列的每一行都是唯一值,则该列被称为表的键。通常情况下,表有一个列是键列。
- 【关系】可以形成链条。每个产品都有一个子类别,每个子类别都有一个类别。因此,每个产品都有一个类别。为了检索产品的类别,你需要遍历两个关系链。图 1-1 包含一个由三个关系组成的关系链的示例,从销售表开始,一直到产品类别表。
- 在每个【关系】中,可以有一个或两个小箭头。在上图中,你可以看到销售表和产品表之间的关系中有两个箭头,而其他所有关系都只有一个箭头,箭头表示关系将沿着此方向自动筛选。我们会在后面的文章中会更详细地讨论这个问题,因为确定正确的筛选方向是最重要的技能之一。
在表格数据模型中,关系只能在单个列上创建。引擎不支持建立在多个列上的关系
为什么说星型模型是 Power BI 的最佳模型结构
上文中我们提到了一个很重要的信息:【星型模型】是更适合
Power BI建模使用的结构。
这不仅是出于减少数据冗余的考虑,因为对于列式数据库来说,即使有一定的冗余也可以被引擎很好的压缩,更主要的原因是从计算准确性角度给出的建议。
虽然【宽表】形式(所有的维度和指标都汇总到一张表)被很多 BI 工具或者分析系统采用,但是在 Power BI 中使用这种结构,在某些计算时可能导致异常结果。
使用【宽表】做数据源的报表可能计算出不准确的数字,而【星型模型】是一种更为可靠的分析系统
- 我用一个简单的例子来说明这个问题,在介绍自动匹配(
Auto-Exists)的文章中,你将详细了解背后的原因。案例使用一张三行两列的表构造一个矩阵视图:
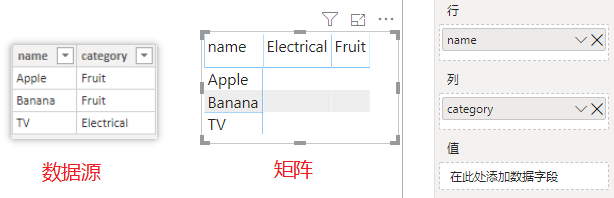
图:矩阵视图的度量值留空
- 定义如下两个度量值分别放入矩阵中,现在请你思考一下,它们各自会得到什么结果?
CountA = COUNTROWS('Table')
CountB = CALCULATE(COUNTROWS('Table'),'Table'[name]="TV")

图: 两个度量值结果对比
CountA 计算表的行数,只对数据源存在的组合返回记录,所以类似这样的搭配属于无效组合,返回空值。
CountB 度量值在前者基础上增加一个内部筛选器参数,将 name 值修改为 TV,根据** CALCULATE 计值流规则**,这种写法无论外部上下文中的 name 列使用哪个值,都将被 CALCULATE 替换为 TV。
如果你从这个角度思考,会发现右边的结果似乎并不正确,因为它只保留一行记录,如果替换发生,那么的组合将在内部被替换为后返回 1,但结果并非如此。
不合理的模型结构带来的其他问题
- 单纯强调模型结构的重要性可能没法让你产生直观感受,这里我用反面案例来说明,一个糟糕的模型可能给你带来哪些问题,如果你过去习惯于在 Excel 里分析数据,那这部分内容是你需要特别关注的,很多使用者在切换到 Power BI 后,由于没有真正理解模型结构的重要性,在这上面走了很多弯路。
DAX 原理
度量值、计算列和查询
- 编写 DAX 有三种场景:度量值、计算列和查询。
现在你需要学习 DAX 中非常重要的一个概念:计算列和度量值的区别。
尽管它们乍一看很相似,因为某些情况下你可以用两种方式得到相同的结果,但实际上它们存在显著的区别,理解这种区别是解锁 DAX 能力的关键之一。
计算列
- 例如,如果你想在 Excel 中创建一个计算列,你可以简单地移动到表的最后一列,即添加列,然后开始编写公式。其他工具可能有不同的用户界面,但操作类似。
图: 在 Power Pivot 中创建计算列
- 计算列与表中的任何其他列一样,你可以在数据透视表或其他报表的行、列、筛选器或值中使用它。
如果需要,还可以使用【计算列】来【定义关系】。
定义计算列的 DAX 表达式在它所属表的当前行上下文中计值。
任何对列的引用都会返回当前行中该列的值,你不能直接访问其他行的值。
- 后面你将看到,聚合函数可以为整张表聚合列值。
想要获取行子集的值,唯一方法是使用可以返回表的
DAX函数,然后对其进行操作。
通过这种方式,你可以为特定范围的行聚合列值,并可以通过过滤仅由一行组成的表格来操作不同的行。
在关于计值上下文的文章中,你将继续了解这部分内容。
- 提示
关于计算列,需要记住的一个重要概念是,它在内存数据库刷新时计算,然后存储在模型中,报表中的筛选器无法影响它的计算过程。
如果你习惯于 SQL 的计算列(非持久化的)可能会觉得有些奇怪,因为后者在【查询时计算】,只在计算时消耗内存,计算完成后释放。
然而,在【表格模型】中,所有计算列常驻内存,并在【表刷新】时才进行计算。
- 当你创建非常复杂的【计算列】时,了解这种行为是有帮助的。
- 【计算列】占用模型加载的时间而不是查询时间,以获得更好的用户体验。
- 不过,你必须始终记住,计算列使用的是电脑的内存(通常是有限的)。
例如,如果计算列使用了一个复杂的公式,你可能会尝试将计算步骤分离到不同的中间列中。
虽然这种技术在项目开发中很有用,但在实际应用的时候不是一个好习惯,因为每个【中间计算】都存储在 RAM 中,占用了较多的【内存】。
度量值
-
在
DAX模型中还有一种定义计算的方法,当你不想沿着表格逐行计算,而是想在上下文环境中对表的多行进行聚合计算时,这种方法非常有用。我们称这些计算为【度量值】。 -
度量值使用的表达式通常利用聚合函数(如 SUM、MIN、MAX、AVERAGE 等)生成标量结果,并且结果永远不会存储在模型中。
度量值的使用非常广泛,从简单的列聚合到更复杂的公式(覆盖筛选上下文和/或关系传播的公式)应有尽有。
- 例如:你可以在销售表中定义名为 GrossMargin 的列来计算毛利:
Sales[GrossMargin] = Sales[SalesAmount] – Sales[TotalProductCost]
- 但如果你想显示毛利占销售额的百分比会怎样呢?你可以使用以下公式创建一个计算列:
Sales[GrossMarginPct] = Sales[GrossMargin] / Sales[SalesAmount]
正如你在下图中看到的,公式在行级别的计算结果是正确的
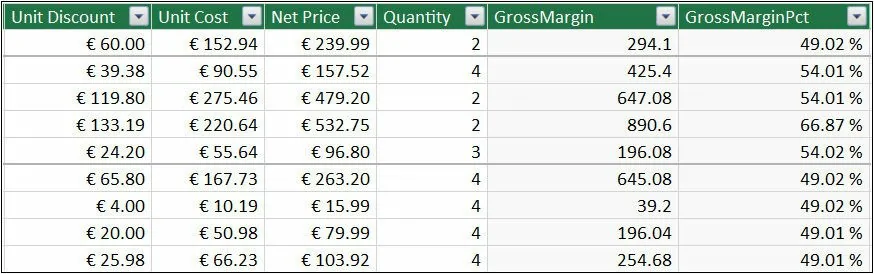
图: GrossMarginPct 列以百分比显示毛利率,逐行计算
然而,当你计算某个百分比的总值时,你不能依赖于计算列。实际上,你需要用毛利之和除以销售额之和。因此,在这种情况下,需要基于聚合的结果计算比率;而不能直接使用计算列的加总。换句话说,你计算的是和的比率,而不是比率的和。计算 GrossMarginPct 的正确的方式是使用度量值:
GrossMarginPct:=SUM ( Sales[GrossMargin] ) / SUM (Sales[SalesAmount] )
然而,正如我们已经说过的,你不能将其输入到计算列中。如果操作的对象是聚合值而不是逐行,则必须创建度量值。
- 提示
在 Excel 中我们使用“
:=”来定义一个度量值,而不是等号(=),以便更容易区分代码中的度量值和列。而在Power BI Desktop创建【度量值】和【计算列】都可以直接输入“=”开始
- 度量值和计算列都使用
DAX表达式;区别在于【计值上下文】。
- 【度量值】是在透视表或报表所在的上下文环境中计算的,而【计算列】是在它所在表的行级别计算的。
- 单元格的筛选上下文取决于用户对透视表的选择或者 DAX 查询的形态。
因此,当你在度量值中使用 SUM(Sales[SalesAmount])时,公式将在该单元格的上下文环境中计算 SalesAmount 列的总和,而当你在计算列中使用 Sales[SalesAmount]时,指的是 SalesAmount 列在当前行的值。
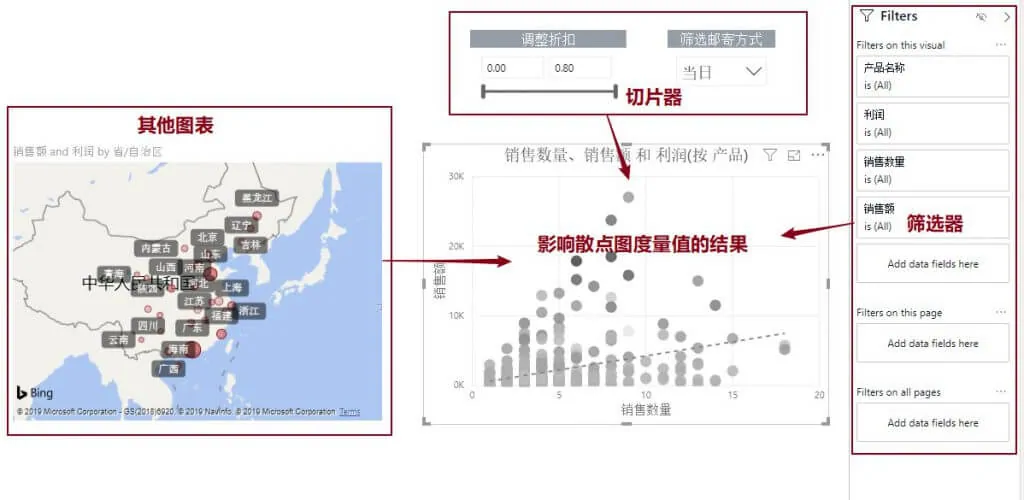
图: 以散点图为例,报表层度量值的计值环境
- 度量值需要定义在表中,这是
DAX语言的要求之一。然而,【度量值】并不真正属于任何表。
事实上,你可以将【度量值】从一个表移动到另一个表,而不影响正常使用,比如你在 Power BI Desktop 中选择任意度量值,在建模选项卡下可以切换它所在的表。
- 提示
虽然【度量值】和【列】在书写的时候对是否添加【表名】并无强制要求;
但从【易用性】出发,【强烈建议】你只在【列引用】的时候添加【表名】,【度量值】则无需添加【表名】,这会减少代码阅读时的歧义。
自动生成的度量值 //TODO
https://www.powerbigeek.com/calculated-column-and-measures/
Y 推荐文献
- [数据分析/BI] Microsoft Power BI 使用指南 - 博客园/千千寰宇
X 参考文献
- DAX是什么 - Power BI 极客 2019-09-01 【推荐】(待续)
